VITS JaPros WebUI
Windowsローカル環境(NVIDIAのグラボ)内で完結する、手軽に日本語TTSモデル(VITS)(アクセント指定可能)を学習し音声合成できるWebUIを作りました:
VITS JaPros WebUI
| 音声合成 | 学習 |
|---|---|
 |
 |
音声ファイルからのセリフ自動書き起こし機能も同梱しています。
使い方は上記リポジトリを見れば分かると思います。WSLを導入したり面倒なコマンドを叩いたり自力でテキストを書き起こししたりといった作業は必要ありません。
本記事はこれについての紹介となります。
もうちょっと詳しく
ESPnetという、TTS含む音声関連の機械学習タスクを扱える枠組みがあります。
そこでは性能の良いVITSや、その中でも音素分解の処理方法を指定したりできます。中でも、日本語TTSだと不自然になりがちなアクセント高低の指定ができるpyopenjtalk_prosodyという音素分解の手法の性能がなかなかよいようです。
しかし、ESPnetはシェルスクリプトで動かすなどLinuxでの動作を前提としており、そのままではWindowsで使えず、WSLを介したりいろいろ処理をする必要があります。しかもいろいろコマンドを叩く必要があります。
そこで、ESPnetを改造してシェル部分をPythonコードで無理やり実行することで、そのままのWindowsでも動くようにして、またコマンドを叩かずともWebUIで簡単に音声学習・音声合成をできるようにしようと思って作ったのが上になります。
さらにFaster whisperによる、音声からの自動テキスト書き起こし機能もつけているので、音声ファイルのみから学習を始めることができます。
また、手持ちの「ESPnet2で学習させたVITSでpyopenjtalk_prosodyなモデル」があれば、それとconfig.yamlを持ち込めば、音声合成部分のWebUIのみでもたぶん有用なものとなっている思います。
背景
pyopenjtalk_prosodyについて
TTS学習においては、テキストと音声のペアを学習させるわけですが、日本語テキストそのまま(漢字ひらがなそのまま)を学ばせるわけではなく(もしかしたらそういう方向もあるのかもしれませんが…)、g2p (grapheme-to-phoneme, 書記素から音素への変換)と呼ばれる、テキストを音素記号の列に分解する作業が間に入ります。
ESPnetでは日本語のg2pとしてどれを用いるかを指定することができ、5種類があるようです。
ESPnet内のJSUTレシピファイルから引用して表にしたのが以下のとおりです(pyopenjtalk_prosodyの結果はおそらくレシピファイル内にミスがあるので修正しています)。
入力:「こ、こんにちは」
| g2pの名前 | 結果 |
|---|---|
| pyopenjtalk | k o pau k o N n i ch i w a |
| pyopenjtalk_kana | コ 、 コ ン ニ チ ワ |
| pyopenjtalk_accent | k 1 0 o 1 0 k 5 -4 o 5 -4 N 5 -3 n 5 -2 i 5 -2 ch 5 -1 i 5 -1 w 5 0 a 5 0 |
| pyopenjtalk_accent_with_pause | k 1 0 o 1 0 pau k 5 -4 o 5 -4 N 5 -3 n 5 -2 i 5 -2 ch 5 -1 i 5 -1 w 5 0 a 5 0 |
| pyopenjtalk_prosody | ^ k o _ k o [ N n i ch i w a $ |
名前から分かる通り、全てpyopenjtalkというライブラリからのフルコンテキスト情報から、ある特定の形式の音素情報へ変換しています。
g2pにどれを使うかによってもちろん性能や使い勝手は変わると思うのですが、どうやら一番最後のpyopenjtalk_prosodyを使うと良さそう&直感的にアクセントの高低が制御できそう&何か質が高いらしいという噂を聞いたので、これを使うことにします。
- 噂参考リンク(YouTube):【OV2L Evolving Summit】セッション6 「ESPNetでVITSのFineTuningしてみた」presented by seichi, とろわーる
- 韻律情報で条件付けされた非自己回帰型End-to-End日本語音声合成の検討
- Prosodic Features Control by Symbols as Input of Sequence-to-Sequence Acoustic Modeling for Neural TTS
このpyopenjtalk_prosodyでは、子音と母音のアルファベットに加えて次の特殊記号を用います。
| 記号 | 意味 |
|---|---|
^ |
文の初め |
$ |
文の終わり |
? |
疑問文の終わり |
_ |
ポーズ(息継ぎ等で発話が止まる箇所) |
[ |
アクセントが上がり始める箇所(例:こんにちは→コ[ンニチワ) |
] |
アクセントが下がり始める箇所(例:京都→キョ]オト) |
# |
アクセント句の区切り |
これらを使うことで、単なる音素の列のみではなく高低アクセントの制御がある程度可能なモデルができ、しかもわりと直感的に指定することができます。
VITSについて
【機械学習】VITSでアニメ声へ変換できるボイスチェンジャー&読み上げ器を作った話
等をご参照ください(機械学習何も分からん)。
そもそもVITSがどういうことをしているかだけを述べると、音素列リストとwavファイルの音声のペアを学習することで、好きな音素列リストから音声波形を生成することができるような機械学習モデル(End-to-EndなTTSモデル)です。
VITS自体が2021年に発表されたものであり、若干古いのかもしれません。最近はVITS2が発表されており、性能がいいのかもしれませんが、まだESPnetでは対応しておりません。
日本語VITS2学習非公式リポジトリもあるようですが、まだあまり実験していません(少し試したけどVITSのほうが効率が良かった印象……)
ESPnetについて
ESPnetについてはQiita等に多くの解説記事が見受けられます:
- ESPnet2で始めるEnd-to-End音声処理
- ESPnet2で始めるEnd-to-Endテキスト音声合成
- ESPNetで作るキャラクター音声合成
- windows10,WSL2でESPNetの環境構築【音声合成】
詳しくはこれらの記事に譲るとして、ポイントは、ESPnetは、
- レシピと呼ばれる、データセット構築から前処理から学習前準備から実際の学習から後処理に至るまでの各ステージを実行するLinux向けシェルスクリプトファイル群と、
- 実際の処理・学習を行うPythonモジュール
からなるということです。
レシピ部分はもちろん、実際のPythonモジュールでもいくつかの箇所でLinuxでの動作を前提としているようで、Windows環境で動かすにはWSL2を使って動かす必要があります。
VITS JaPros WebUIについて
今回紹介するVITS JaPros WebUIでやりたかったことや具体的に何をやったかを紹介します。
JaPros
「日本語TTSモデルでg2pにpyopenjtalk_prosodyを使用したもの」といちいち呼ぶと長いので、JApanese...PROSodyでJaProsと名前を付けました。
やりたかったこと
原理的にはWSL2を導入してがんばればVITS JaProsモデルの学習は可能なのですが、実際にやってみると敷居がいろいろと高く、またつまづきポイントもいくつかありました。
なので、参入障壁を下げるためにも、以下を目指しました。
- Windowsのそのままの環境で(WSLを使用せず)、ESPnetのPythonモジュールをそのまま叩く形でVITS JaProsモデルを学習したい
- 音声部分も、手動でアルファベットで書記素列を打つのは大変なので、カタカナと記号という形で打てるようにしたい
- コマンドを叩くのが面倒なのと参入の敷居を高めているので、学習・音声合成をすべてWebUIで実現したい
- 台本書き起こしファイルがない場合、すべて手動で書き起こしするのが大変なので、AIによる書き起こし機能を同梱したい
つまり、実質新しいことはやっておらず、WebUIとして提供することで、学習・音声合成をする際のハードルを下げて間口を広げることのみを目的としています。
やったこと
Linux部分の必要最低限の置き換え
まずESPnetのシェル部分をPythonで置き換えるために、何をやっているかを実際に理解する必要があったので、目標とするESPnetリポジトリにあるつくよみちゃんさんのファインチューンレシピを動かしながら何をやっているかを観察しました。
ESPnetでは学習データ準備から始まって実際の学習やそのアップロードに至るまで、ステージ1, 2, 3, ...等分けられているのですが、上のレシピの場合に何が起こっているかを追っていくと、結局は、
- データセット(wavファイルと書き起こしテキストファイル)を学習用と少数の検証用に分ける
- wavとテキストの「長さ」を計算してファイルに書き込む(wavの場合は読み込んだ配列長、テキストの場合はg2pで変換した音素リストの長さ)(このデータはバッチを作るのに使われるようです)
- 2の情報と学習パラメータ設定を引数として渡して、
python -m espnet2.bin.gan_tts_trainを走らせる
ということをやっていることがわかりました(実際にはもっといろいろファイルを作ったりしており、またレシピによって挙動は大きく異なりますが、今回目標とするレシピで3での実際の学習に渡されるパラメータに必要な部分だけ抜き出すとこうなります)。
で、上の1と2はChatGPTに聞けば一瞬でコードを作ってくれる程度のものなので、ChatGPTに投げたものを修正して作りました。
ただこれだけだと、3の実行時にESPnetのPythonモジュール内にLinux依存の箇所でエラーが出たので(os.unameの使用・シンボリックリンクの作成です)、そこのみ修正をしました。
ESPnetモジュール内部を書き換える関係上、リポジトリはESPnetを依存関係に含めるのではなく、リポジトリ内部に修正したESPnetモジュールを含める形にしています。
音声ファイルからの書き起こしの作成
書き起こしファイルの作成は、精度が高いOpenAI社の Whisper の高速軽量版 Faster Whisper を使用しました。
書き起こし方法について、
- wavファイル1つ1つをそのまま音声に書き起こす
- wavファイル1つを書き起こして、文が「。」等で区切れて2文以上の場合は、音声ファイルもテキストも分割する
という2方式を準備しています。実際どうかは分かりませんが、(おそらく)文章が長くて複数の文からなるデータがあると学習に悪影響がありそうなので、2番目のほうがよいのかもしれません。ただWhisperからの句切れ位置は間違っている場合があり、分割された音声ファイルを聞くとたまに発話が途中で切れていたりすることもあるので、結局は手動で全音声を聞きながら確認・修正する気力が大事なのかもしれません。
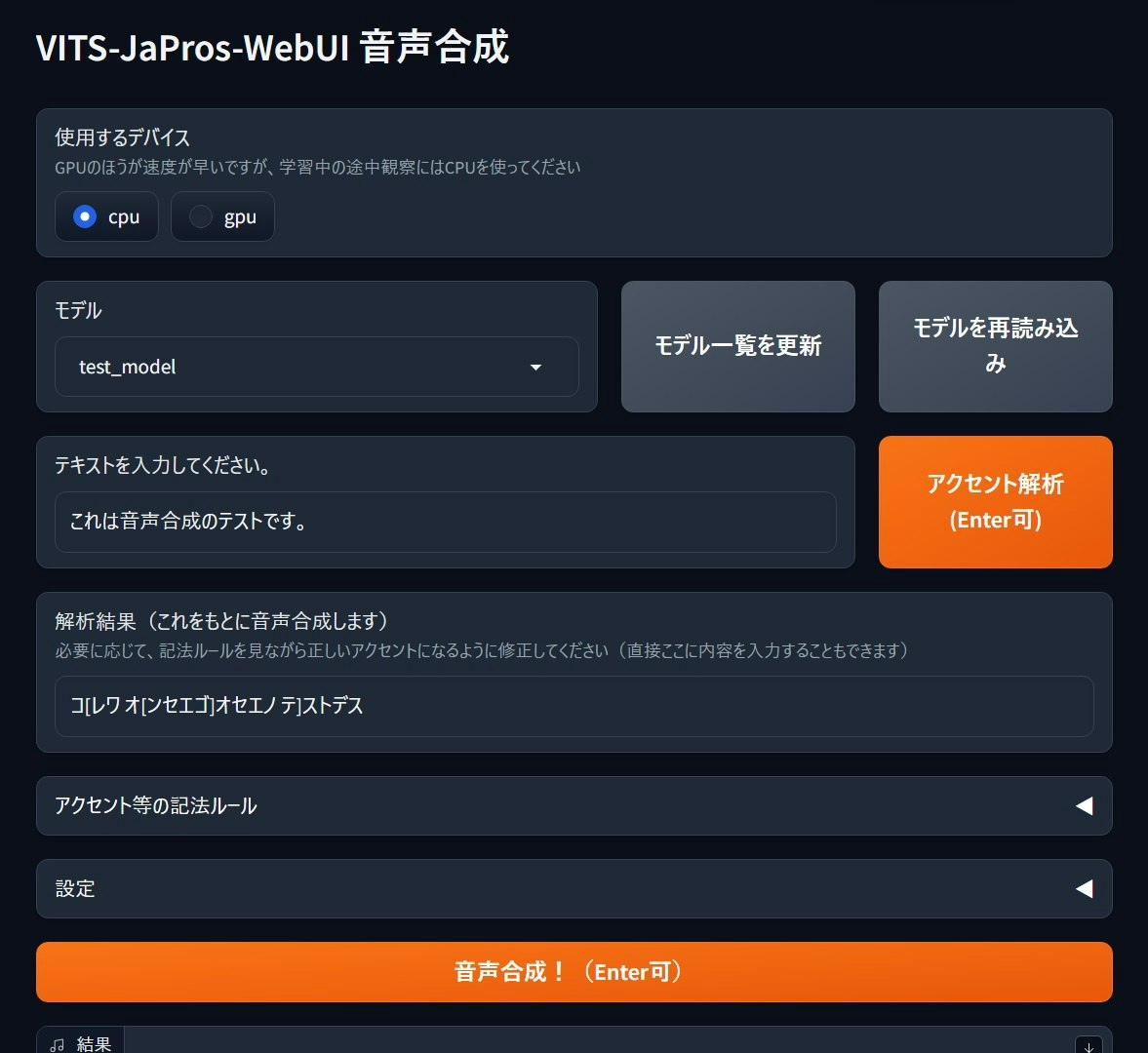
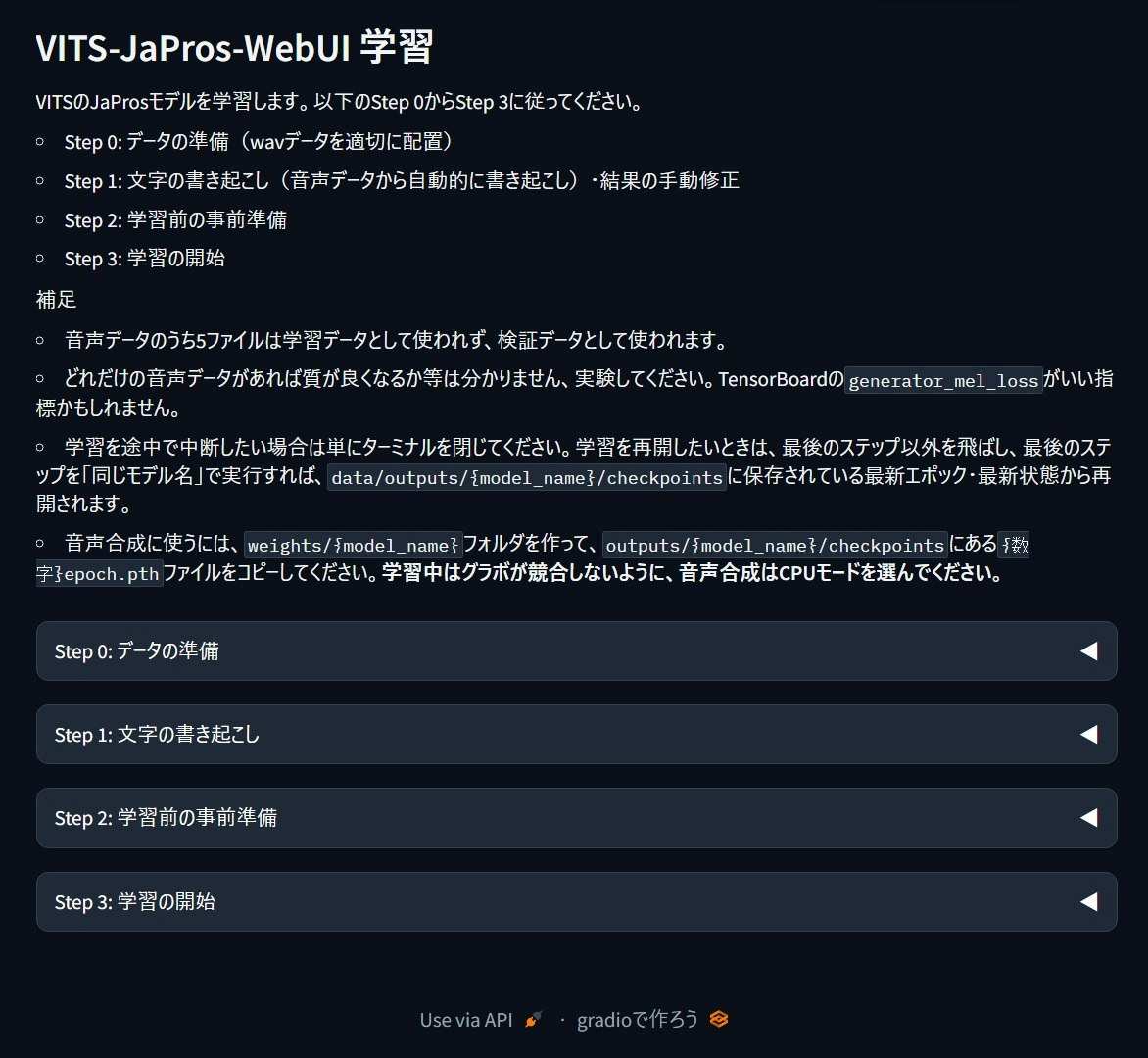
WebUI
Gradioを使って、WebUIのみで学習・合成が完結するように、簡易UIを音声合成用・学習用それぞれで作りました(このページ最初の2枚の画像)。
音声合成用について、そのままpyopenjtalk_prosodyのアルファベット列を修正・入力させるのは少し面倒なので、かわりにカタカナと記号を使って入力できるようにしています(例:これは音声合成のテストです → コ[レワ オ[ンセエゴ]オセエノ テ]ストデス)。
まとめ
ESPnetでのVITS学習自体は昔からできていたので今更感がありますが、このリポジトリでWebUIとして提供し、また自動書き起こし機能も付けることで、気軽にTTS学習・音声合成ができるようになればと願っています。
またTTSやESPnetについても素人であり、Pythonプログラミングの経験もそんなに多くはないため、変な箇所等がありましたらご指摘いただければと思います。