今年サービス一部 AWS ECS への移行タスクを担当させていただきました、Optimind の Ye です。
ECS は一見簡単な Container Managemant Service で、k8s よりカスタマイズ性が低い分、AWS が裏でいろんなことをやってくれることで、使い勝手のいい簡単なサービスと思っていました。しかし、プロダクトの実運用に入ると、勉強時に考えもしなかった課題がどんどん浮上してきました。特に Auto Scaling まわりの仕様、自分のあまい想像通りになっていませんでした。この前 Udemy などのオンライン授業を受けて AWS Certified の SAP も通ったいささか自惚れにもなった自分に、まだまだ経験足りない素人である事実を改めて痛感していたしました。
ここでいくつか勉強になったことをメモとしてとらせていただきます。
ECS Auto Scaling の仕組み
今まで Auto Scaling の実運用あまりしていなかったので、Auto Scaling は ECS の付属品としてなんでもすぐにやってくれるやつと思いていましたが、実は Application Auto Scaling というサービスでした。
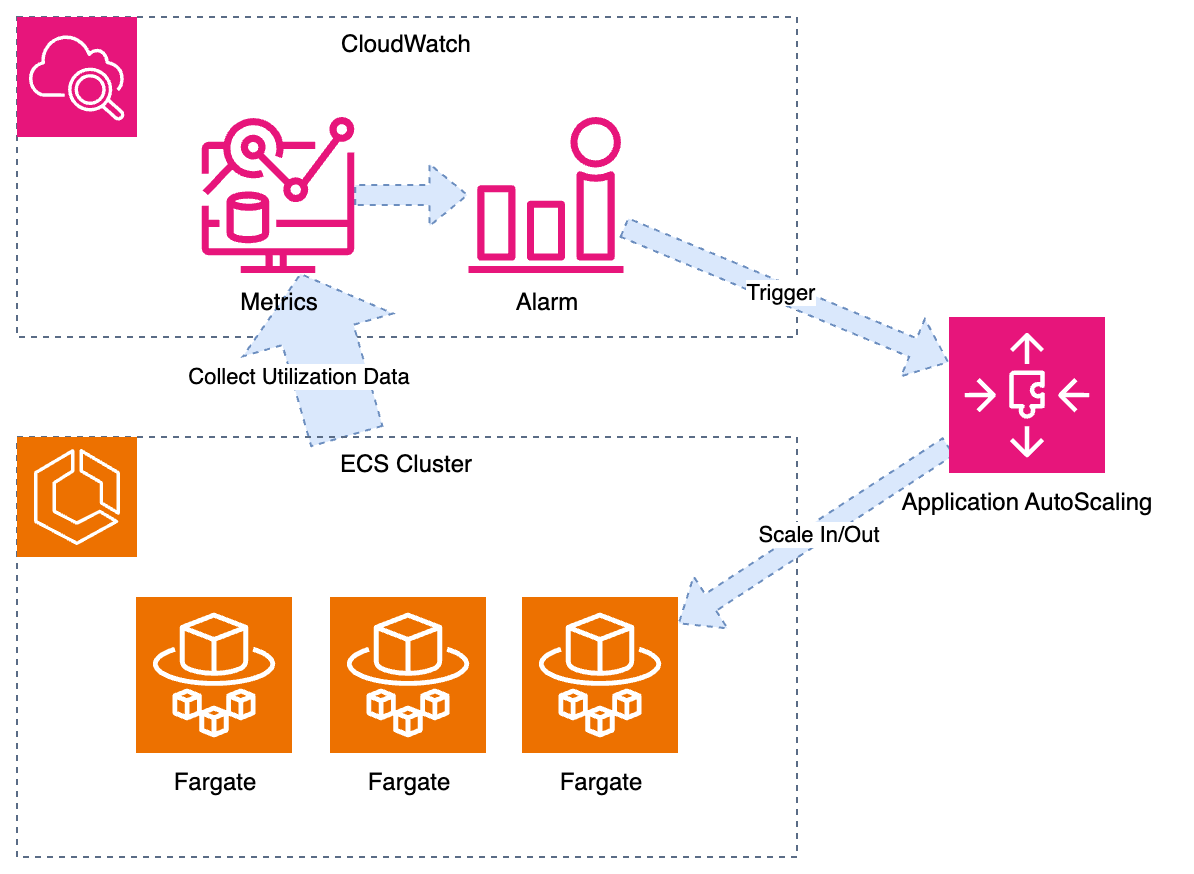
ECS の Auto Scaling を簡単に言うと、まずはメトリクスで CPU・メモリなどの使用率を監視して、事前設定した Alarm 条件を満たしら、Alarm が In Alarm 状態に入り、Auto Scaling の動作を動かせます。そして Auto Scaling が 対象となる ECS Service の DesireTask Count を増やし・減らして、Scaling の Cool Down 状態に入ります。Cool Down 期間が終わると、もし Alarm がまだ In Alarm 状態であれば、Auto Scaling が再び ECS Service の DesireTask Count を増やし・減らします。
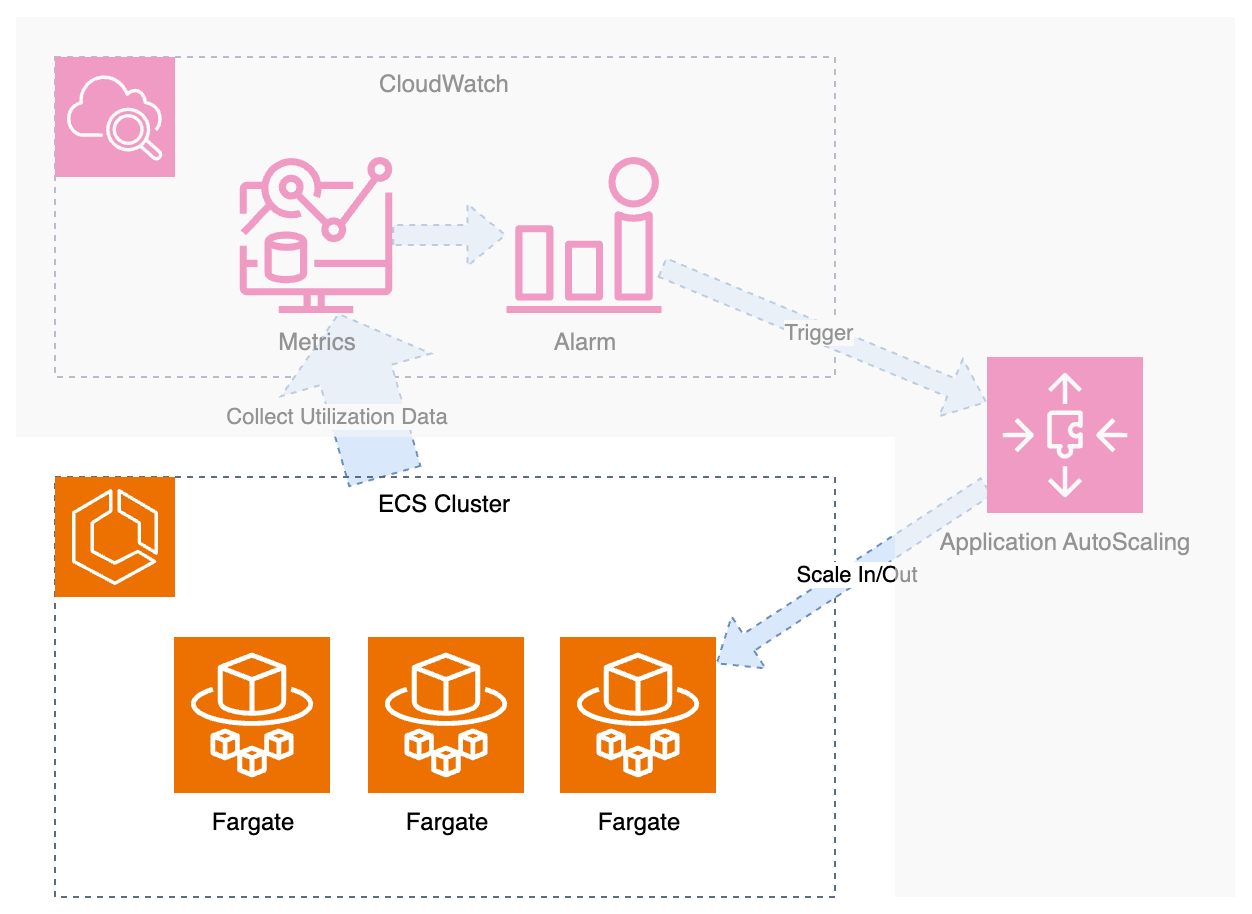
結構複雑に書いてしまいましたが、上の図の中の灰色が被っている部分は、すべて AWS が作ってくれます。

Step Scaling ならもっと細かい粒度で調整できますが、Target Tracking ならダッシュボードで上の図の通り書けば無難に使えます。
もし AWS の CLI で叩くとしたら、2 Steps になります:
-
register-scalable-targetAuto Scaling 機能を Enable にしたい ECS Service を「scalable」な対象であることを提出する -
put-scaling-policyAuto Scaling がどのように動作していくかを指定する
aws application-autoscaling register-scalable-target \
--service-namespace ecs \
--scalable-dimension ecs:service:DesiredCount \
--resource-id service/${ECS_CLUSTERの名前}/${ECS_SERVICEの名前} \
--min-capacity 0 \
--max-capacity 256 \
--suspended-state DynamicScalingInSuspended=false,DynamicScalingOutSuspended=false,ScheduledScalingSuspended=false
aws application-autoscaling put-scaling-policy \
--policy-name ${お好みの名前} \
--service-namespace ecs \
--scalable-dimension ecs:service:DesiredCount \
--resource-id service/${ECS_CLUSTERの名前}/${ECS_SERVICEの名前} \
--policy-type TargetTrackingScaling \
--target-tracking-scaling-policy-configuration file://scaling-policy.json
上2つのコマンドから見て、なんとなく推測できます:
- Scaling Policy が Scaling 動作の起動条件を決める
- Scalable Target がどの Service に、どれぐらい Scale させるかを決める
- 最後に Scale という動作に対して、ECS Service の DesireTaskCount が変わるだけであり、如何に既存する Fargate インスタンスを管理するか、起動・停止するかは ECS Cluster が自分で決める
{
"TargetValue": 5.0,
"PredefinedMetricSpecification": {
"PredefinedMetricType": "ECSServiceAverageCPUUtilization"
},
"ScaleOutCooldown": 60,
"ScaleInCooldown": 60,
"DisableScaleIn": false
}
そして--target-tracking-scaling-policy-configurationを必要に応じて設定すれば、Auto Scaling が働いてくれます。

ちなみにaws application-autoscaling put-scaling-policyのコマンドが実行されると、CloudWatch に新しい Alarm が自動的に追加されます:
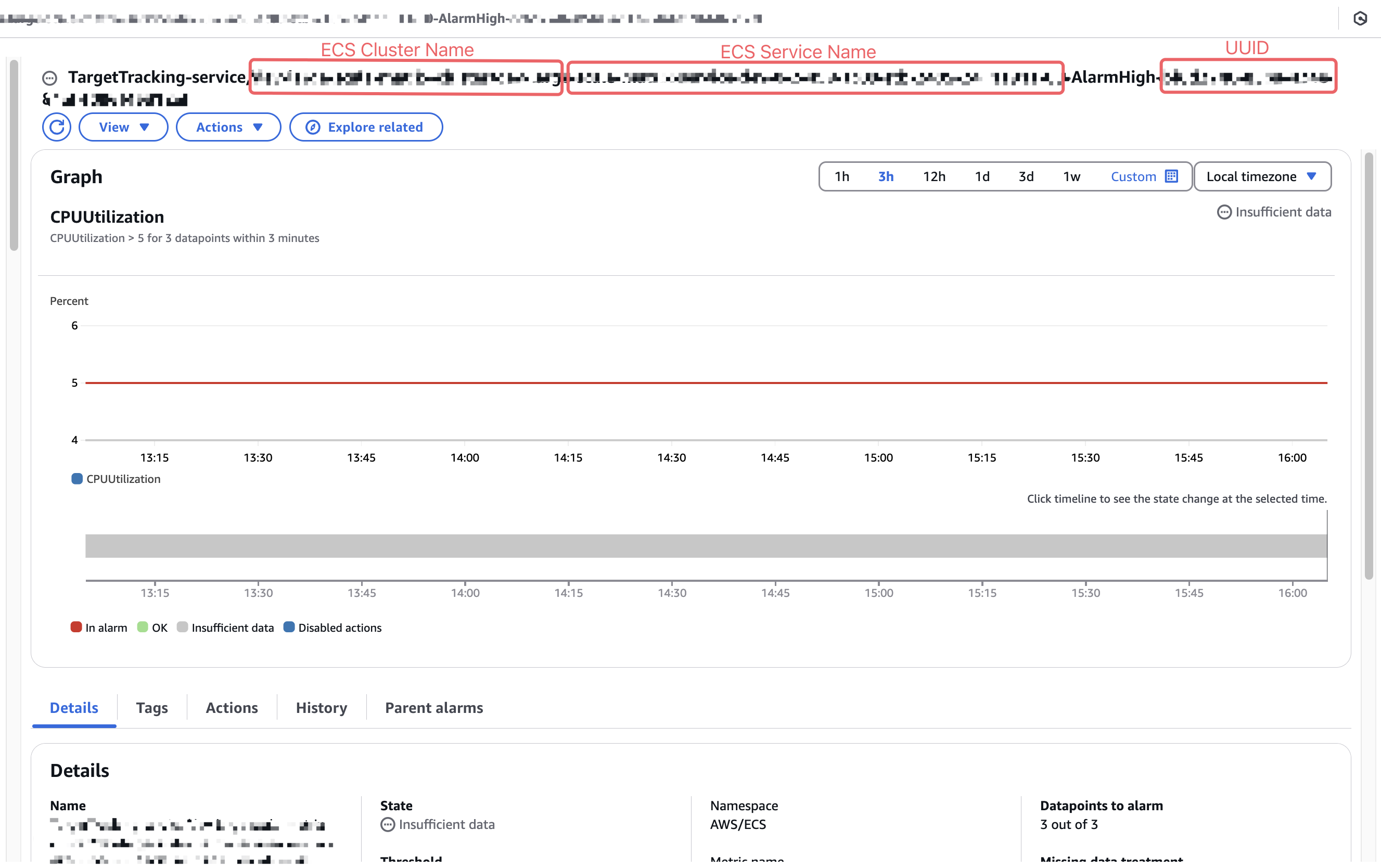
TargetTracking-service/<ECS_CLUSTERの名前>/<ECS_SERVICEの名前>-AlarmHigh-<AWSが生成したUUID>TargetTracking-service/<ECS_CLUSTERの名前>/<ECS_SERVICEの名前>-AlarmLow-<AWSが生成したUUID>
名前を見ればわかると思いますが、AlarmHighの文字が付いているヤツが「In Alarm」状態に入ると ECS の DesireTaskCount 数が増えます。逆にAlarmLowの文字が付いているヤツが「In Alarm」状態に入ると ECS の DesireTaskCount 数がその分減っていきます。
ECS Auto Scaling の閾値が難しい

この自動生成された Alarm は、Threshold が決まっている状態です。
Threshold: CPUUtilization > 5 for 3 datapoints within 3 minutes
Statistic: Average
Period: 1 minute
日本語に訳すと:1分ごとに CPU 使用率を集計し、その平均値を計算して、1つの Datapoint とします。そして3分の間に、CPU の平均使用率が5%を超える Datapoint が3つあると、「In Alarm」状態に入ります。
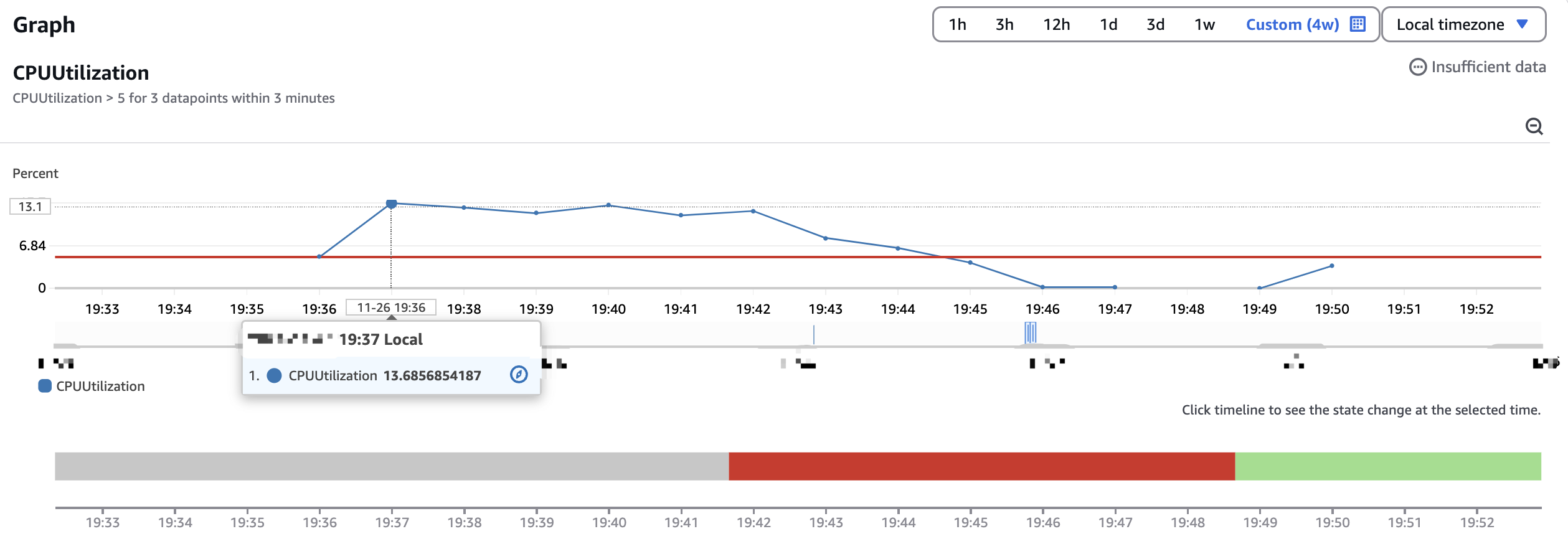
そう書いてもすぐには理解できないかもしれませんが、グラフに戻すと、青い点が「Datapoint」であります。ここの「Datapoint」はあくまでも1分ごとの平均値であり、普段思っている「本当の CPU 使用率」とちょっと違います。
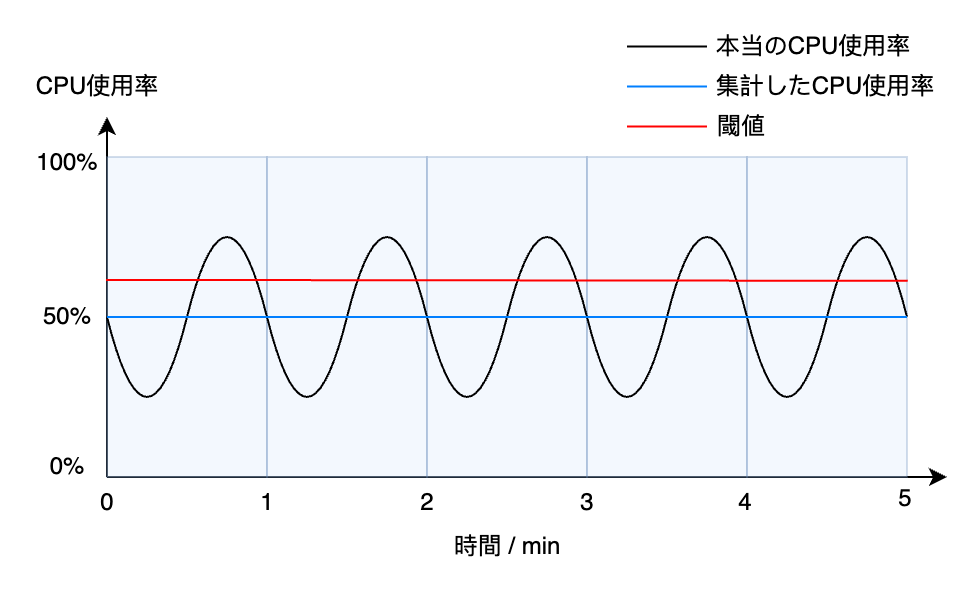
例えば本当の CPU 使用率を黒い波の線にして、1分ごとに集計しているから、グラフから見れば青い直線の方になってしまいます。そうすると本当に CPU 使用率が70%を超えることもありますが、集計値がただの50%になりますから、たとえ閾値が51%であっても Alarm がじっとも動きません。
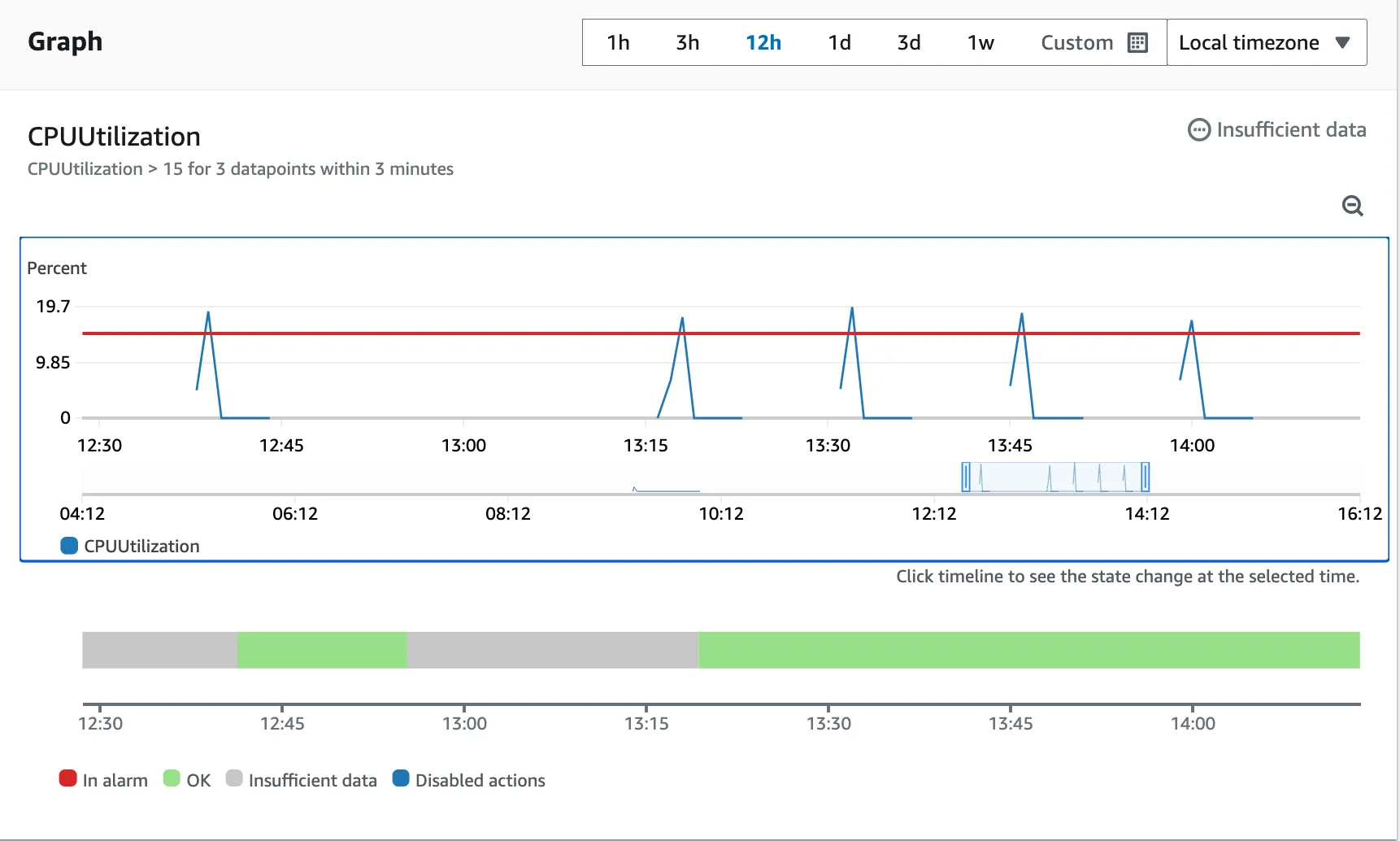
さらに「3 datapoints within 3 minutes」という条件も入っていますから、たった1つの Datapoint だけでは何の意味もありません。結局 Scaling しませんでした。
DO NOT EDIT OR DELETE
Alarm の Description にこういう文字が入ってますが、ルールをやぶる悪者なので、「1 datapoint within 1 minute」にしましたが、下の図の通り、無理でした。
ECS Auto Scaling の動作が遅い
では、3分間に3つの Datapoint が CPU 使用率の閾値を超えたら、その場で「In Alarm」状態に入りますか?
答えは「NO」です。
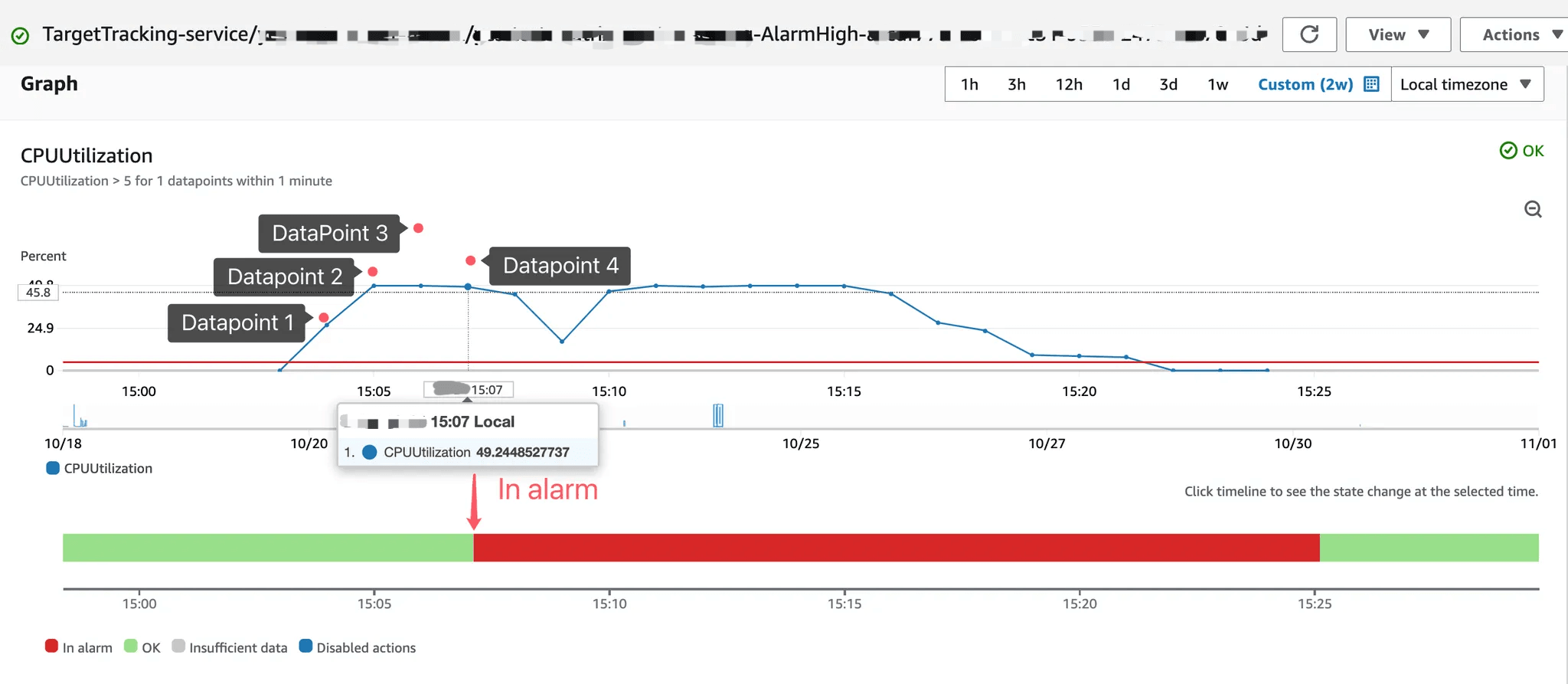
ご覧の通り、Alarm は早くても4番目の Datapoint から「In Alarm」状態変わります。
そして同様に、「In Alarm」状態の解除も条件満たしてすぐに「OK」状態に戻るわけではありません。こちらも早くて4番目の Datapoint からです。
されにデータの集計自体も場合によって、Alarm の遅れの原因にもなります。
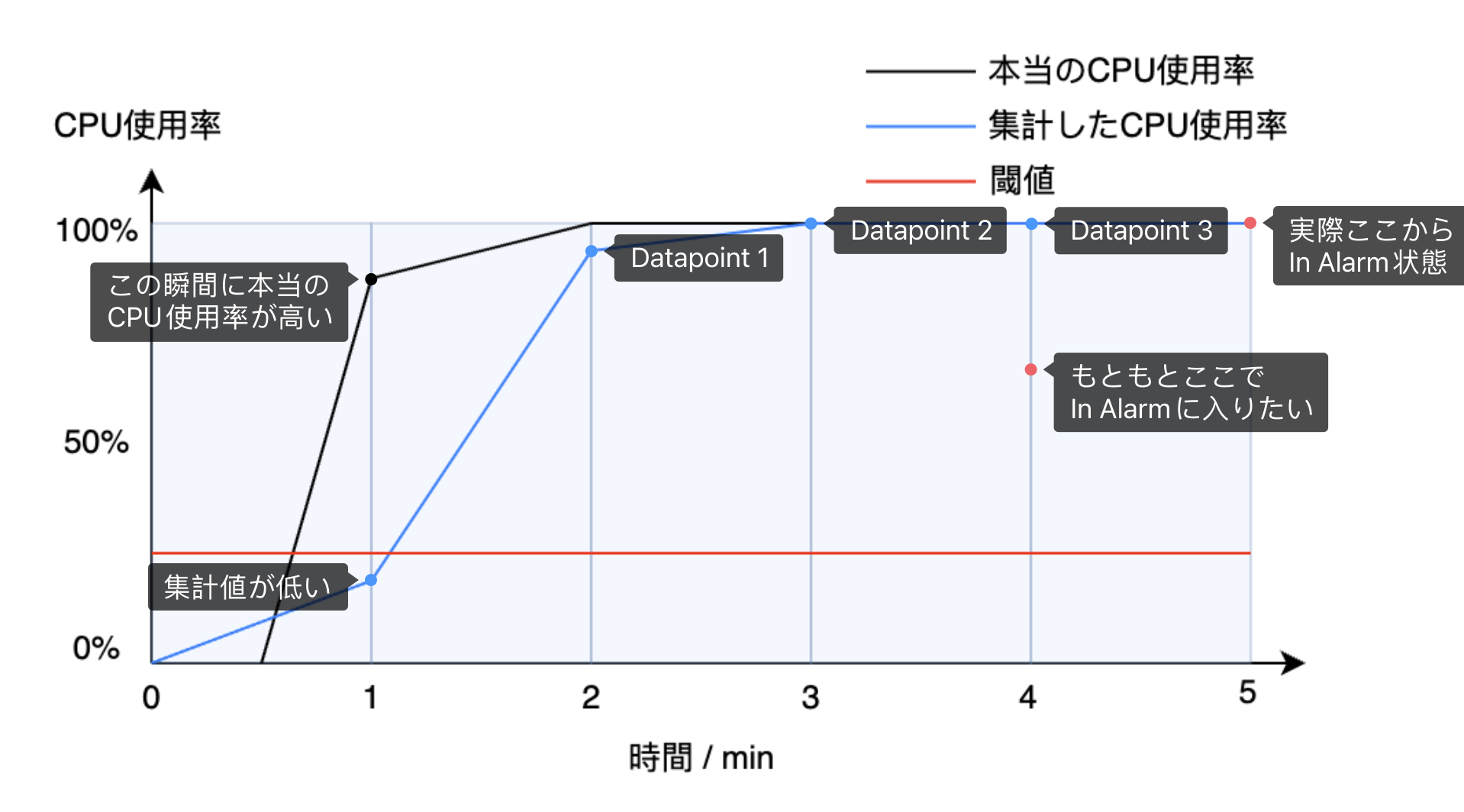
例えばサービスが0分と1分の間に起動して、すぐに CPU 使用率が高く飛んでいくとします。1分の時その瞬間に CPU 使用率がやばくなっているのに、メトリクスの集計で1分間全部のデータを集めて平均を取るから、集計値が低くなっています。そのあと3つの Datapoint を取って、5分になってから「In Alarm」状態に入ります。もともと4分の時に状態が変わると予想していましたが、1分遅れになってしまいます。
これはただの理想的な状況を考えるだけで、実際にデータが集計されたこの1分は果たして00:01:00.000なのか、そもそも分かりません。
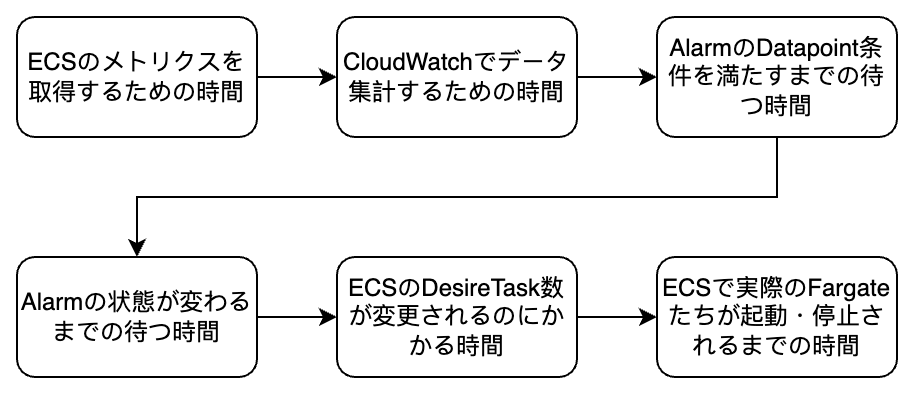
よく考えると、ECS Auto Scaling が動作するまで、いろんなところでタイムラグが発生します。それはどうすればいいでしょうか?
実際に ClassMethod さんへ問い合わせをしたら、こんな回答をいただきました:
Auto Scaling にて Traget Traking スケーリングポリシーを使用した際に、Target Tracking の使用する CloudWatch アラームが状態遷移ぜす、スケーリングが行われるまでに時間を要するとお問い合わせいただきました。
こちらは ECS のメトリクスが登録されるまで時間を要するためとりなります。
ECS がメトリクスを収集・集計するために遅延が発生いたします。
アラームの履歴からも、2024-xx-xx 15:07 JST に 06:04 のデータポイントを使用して評価していることがご確認いただけます。
メトリクス自体は継続して登録されるため、現時点で確認すると添付いただいた画像のように 4つ目のデータポイントの ALARM 状態に遷移したように見られるものと存じます。
また、上記のとおりメトリクスの登録が原因のため、ALARM の状態遷移までの時間を短くすることや、スケーリングまでの時間を短くすることができません。
恐れ入りますが現状の制限としてご承知いただけますようお願いいたします。
なので、我々ユーザにしては、やれることは本当に少ないであります。
なお、ご連絡いただいたアラームは Datapoints to alarm を直接変更されたものと存じます。Target Trucking スケーリングポリシーによって作成されたアラームは alarmDescription にございますように編集や削除を行わないようお願いいたします。
最後はこのように言われました ![]() ごめんなさいです。
ごめんなさいです。