1.はじめに
個人開発でアプリを作成した時に,「とりあえず動かしたいだけなのに,インフラ構築や権限周りの設定で休日が終わってしまった……」なんて経験はありませんか?私はあります.なんならコードを書くより時間がかかります.インフラ構築自体は割と好きですが,できる限り効率化したいなと思ったので,今回はチャットで指示するだけで GitHub リポジトリを解析し,勝手にAWS環境へデプロイしてくれる自分専用のDeployエージェントを開発してみました.
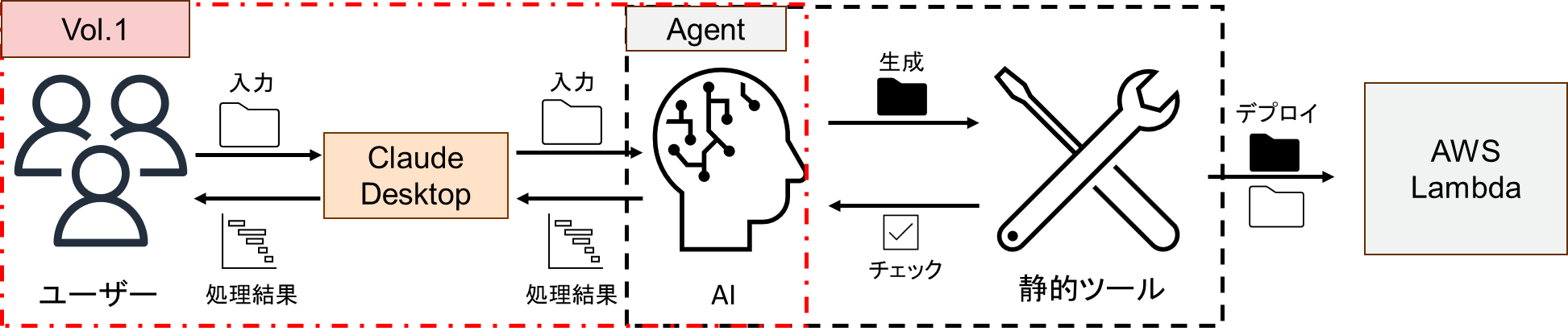
Deployエージェントの開発記事を1枚にまとめて書いていたのですが,長くなりすぎてしまったので3つの記事に分けています.Vol.1 ではエージェントの脳となる FastMCPとAWS Bedrockで「コードとドキュメントを読んで勝手にデプロイ計画を立てるAI」の作成 を行います.
-
Vol.1 の対象読者
- MCPサーバーを構築してみたい方
- AWS Bedrock × LlamaIndex を用いた「コード解析RAG」の実装に興味のある方な方
全記事の内容は以下のようになってます.興味のある方はぜひ読んでみてください!
1.[Deploy-Agent開発 Vol.1] FastMCPとAWS Bedrockで「コードを読んで勝手にデプロイ計画を立てるAI」を作ってみた
2.[Deploy-Agent開発 Vol.2] AI⇔静的ツールでの「自己修正ループ」を作成してみた
3.[Deploy-Agent開発 Vol.3] AWS SAMでエージェントに特定プロジェクトのデプロイ・リソース削除機能を持たせてみた
また,本アプリケーションのコード(Vol.1, Vol.2, Vol.3統合版)は Github にて公開しているので,興味のある方はぜひ使用してみてください!
2.Deploy-Agentの設計方針
本エージェントの概念図,システム全体像と設計方針について説明します.
今回作成するDeploy-Agentは,以下の3つの点を重視して作成します.
-
1. Dockerfile中心のアプローチによる言語非依存性
AWS Lambdaへのデプロイには「Zipアップロード」など様々な方法がありますが,本ツールではあえて 「Dockerfileを作成し,コンテナイメージとしてデプロイする」 手法に統一します.これには AWS SAM の PackageType: Image サポート を活用しています.Dockerfileのような環境依存性を排除した構成定義を通じ,かつSAM がコンテナのビルドからデプロイまでを一元管理してくれるので,Pythonだけでなく Node.js, Go, Ruby などどんな言語であっても「Dockerfileさえ書ければデプロイできる」という一貫性と運用性を両立することが可能となります.
-
2. RAGによるドキュメント類の順守とプログラム参照
LLMの知識だけでなく,RAG(検索拡張生成) の仕組みを取り入れます.
事前に設定したセキュリティ要件や開発チームの独自ルール(例:Builder と Runner を分けて作成し,実行時イメージを軽量にするなど)をドキュメントとして読み込ませることで,プロジェクトのポリシーに沿った安全なコード生成ができるようにしています.
また,デプロイ対象のコードをRAGで参照することができるようにすることで,DockerfileやAWS SAMのテンプレートの生成品質を向上させることも目的としています.
-
3.静的ツールとの疑似対話ループ(Vol.2で実装します)
生成後の Dockerfile を そのまま信じるのではなく,hadolint(Dockerfileを公式ベストプラクティスに基づいて自動的に解析するツール) と trivy(コンテナイメージの脆弱性と秘密情報スキャンツール)といった静的ツールを用いて検査するようにしています.マルチエージェントのような「AI⇔AI」の会話を通して生成品質を向上させるといった方法もありますが,「AI⇔静的ツール」間で対話をすることで確実な判定ができるようになり,かつ導入コスト(例:費用・実装コストなど)を抑えることができるようになります.
上記3つを満たすように設計することで,「どんな言語でも」「安全に」「高品質な」デプロイパイプラインを自動化できるDeploy-Agentを最終的に作ろうと思っています.
3.実装部
3.1.システム構成図
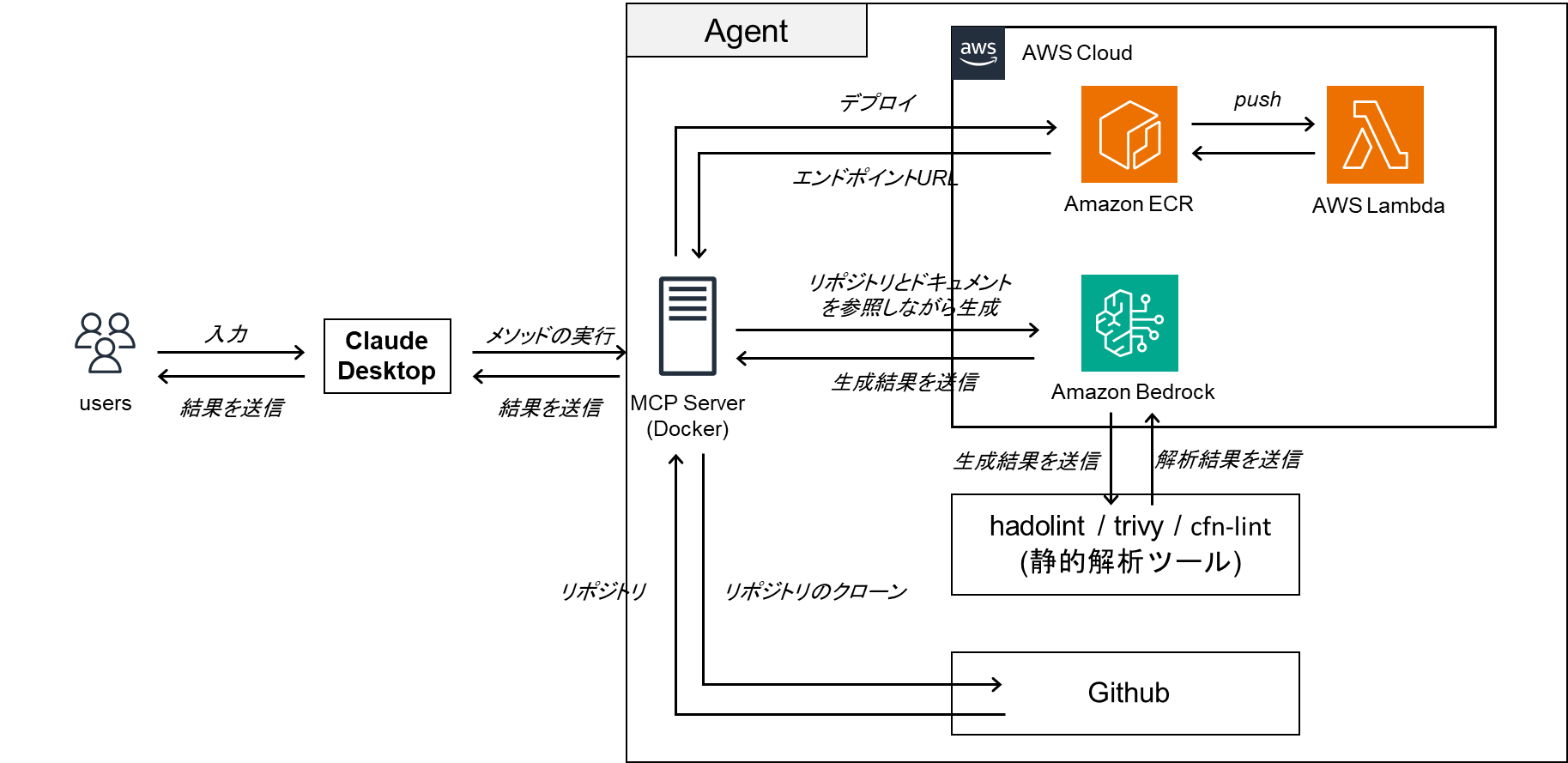
Vol.1では,エージェントの基盤となるMCPサーバーの構築とClaude for Desktopを繋げるところまでを実施しています.
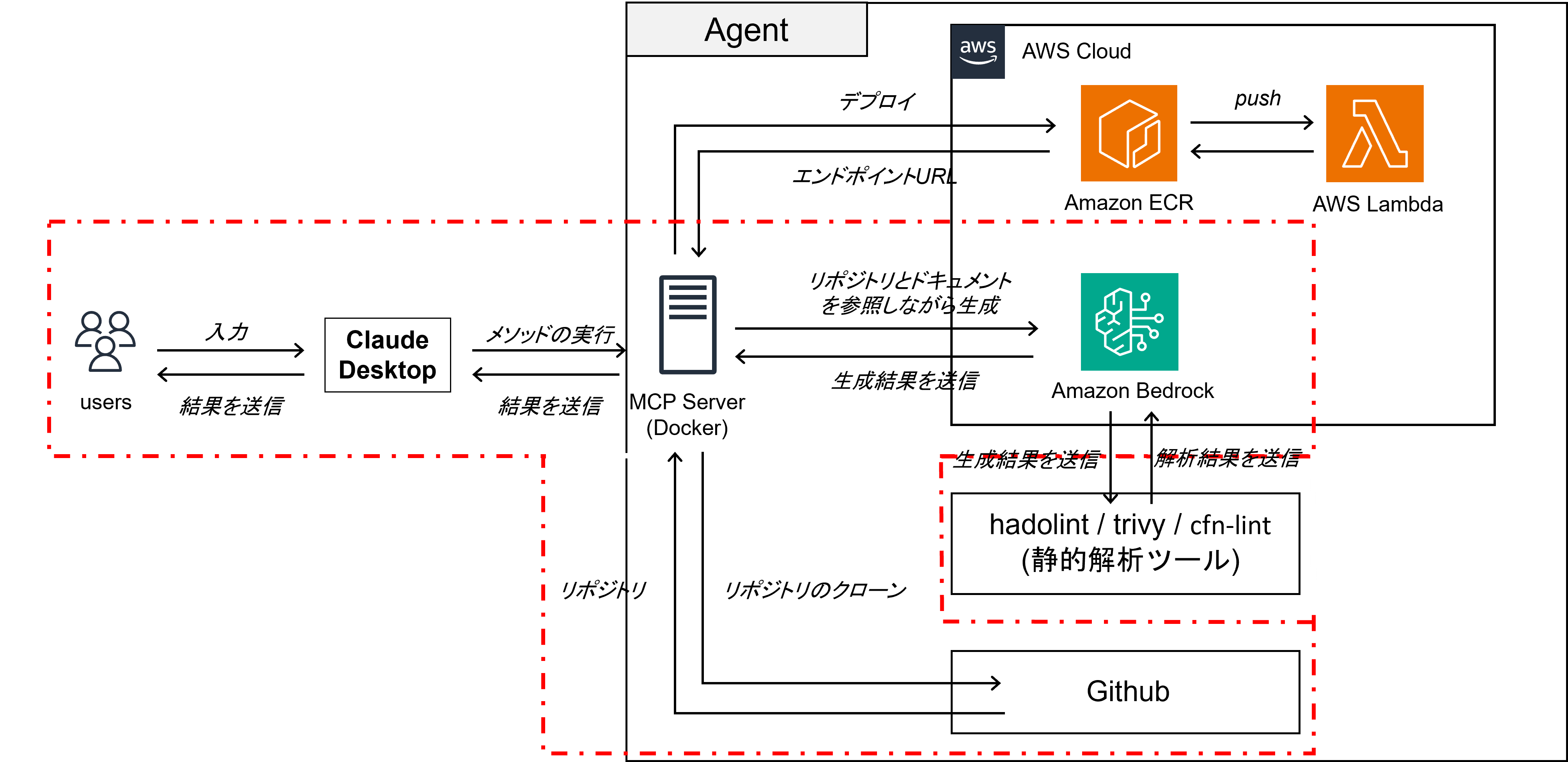
3.2 FastMCPを選定した理由
FastMCPは,PythonでMCPサーバーを迅速に開発するための高レベルSDKです.利点として デコレータ(@mcp.tool)を付与するだけで既存のPython関数をツール化でき,実装時のコードを大幅に削減できる点があります.今回最終的に実装するDeployエージェントは,RAGによるコード解析やDocker・AWS操作などを含んだ複雑なバックエンド処理を伴うので,今回はMCPサーバーを構築するための実装コストが低く,かつPythonとの親和性の高いフレームワークとしてFastMCPを使用しています.
from mcp.server.fastmcp import FastMCP と from fastmcp import FastMCP は全く別ものであり,今回使用しているのは後者の方です.
4.実装
ここからは,実際にエージェントの中身をどのように実装したかについて,ポイントを絞って解説します.
4.1.コードを読むAIを作る (LlamaIndexでのRAG実装)
まずは、ユーザが事前に用意していたドキュメント類(セキュリティ面の規則であったり,環境作成時に考慮してほしい点など...)と GitHub リポジトリの中身 をエージェントが理解できるようにします.これには RAG (Retrieval-Augmented Generation) の技術を使いますが,実装はフレームワークとして LlamaIndex を使うと簡単に実装できます.また今回は,AIエンジンとしてはAWS Bedrockを採用しています.
-
AWS Bedrock の採用理由
今回AIエンジンとしてAWS Bedrockを採用した理由は複数ありますが,一番の理由はシステムのアーキテクチャを綺麗にしたかったらです.今回の開発の最終的な目標となっているDeploy-Agentは,環境を作成した後にAWSにデプロイすることを想定しています.そのため,使用するAIもOpenAIやGoogleが提供しているようなモデルのAPIを直接叩くのではなく,AWS Bedrockを使用したほうが綺麗に実装できます.
また,LlamaIndexでは BedrockConverse や BedrockEmbedding といった専用クラスが用意されているため,数行で実装することが可能です.src/engines/analysis_engine.pydef _initialize_llm(self): """LlamaIndexのGlobal設定をAWS Bedrockに置き換える""" print(f"Initializing AI Brain: [ {settings.LLM_MODEL} ]") try: # LLM: AWS Bedrock LlamaSettings.llm = BedrockConverse( model=settings.LLM_MODEL, # 例: anthropic.claude-3-5-sonnet-20240620-v1:0 region_name=settings.AWS_REGION ) # ベクトル埋め込み: Amazon Titan Embedding v2 LlamaSettings.embed_model = BedrockEmbedding( model_name="amazon.titan-embed-text-v2:0", region_name=settings.AWS_REGION ) except Exception as e: print(f"❌ AI Init Failed: {e}") -
リポジトリ解析の工夫(ノイズ除去)
リポジトリ内のすべてのファイルを読み込む場合,画像ファイルや node_modules などが仮に含まれている場合は巨大な依存ファイルまで含まれてしまい,LLM のコンテキストを圧迫したり,回答精度を下げる要因となります. そこで,SimpleDirectoryReader の exclude オプションを活用し,ソースコードとして意味のあるファイルだけを読み込ませるようにしました.src/engines/analysis_engine.pydef analyze_context(self, project_path: Path) -> dict: print("🧠 Analyzing source code...", file=sys.stderr) # ノイズになるファイル(画像、キャッシュ、ロックファイル等)を除外して読み込み documents = SimpleDirectoryReader( input_dir=str(project_path), recursive=True, exclude=[ "*.git*", "*.lock", "node_modules", "__pycache__", "*.png", "*.jpg", ".DS_Store" ] ).load_data() # ベクトル化してインデックスを作成 index = VectorStoreIndex.from_documents(documents) # クエリエンジンを作成し、技術スタックを特定させる stack_info = str(index.as_query_engine().query( "Identify the programming language, framework, and entry point file. List key dependencies." )) return {"stack_summary": stack_info}
4.2.「デプロイ計画」を立てさせる (Prompt Engineering)
AIがコードを理解したら,次は「どうデプロイするか」を考えさせます.いきなりデプロイを実行するのはユーザーが意図しない挙動であったりセキュリティ面てきなリスクが高いため,まずは「計画 (Plan)」を提示し,ユーザーの承認を得るフローにしました.
src/engines/decision_engine.py では,解析した技術スタック情報をもとに適切な Dockerfile と AWS SAM CLI を通してデプロイするために必要なSAMテンプレートである template.yaml を生成するようプロンプトを設計しています.さらに、ユーザーが視覚的に理解しやすいように Mermaid 記法でデプロイ時のAWSアーキテクチャ図を出力させる のもポイントです.
def plan_deployment(repo_url: str, target: str = "local") -> str:
"""
【Step 1】デプロイ計画を作成します。
リポジトリを解析し、アーキテクチャ図(Mermaid)を表示します。
"""
# ... (リポジトリの解析処理) ...
# アーキテクチャ図の生成指示
diagram = LlamaSettings.llm.complete(
f"Create a mermaid graph TD for a proposed {target} deployment of {context['stack_summary']}. Return ONLY mermaid code."
).text
return f"""
# 📋 Deployment Plan
コードを分析し,デプロイ環境のアーキテクチャ図を作成しました。
## 🏗 作成したデプロイ環境
```mermaid
{diagram}
```
Target: {target.upper()}
Docker Context: Generated in {work_dir}
❓ 次のステップ: ユーザーに「デプロイを実行してもよろしいですか?」と尋ねてください。
"""
4.3.FastMCPでエージェント化する
最後に,作成したロジックを MCP サーバーとして公開します.ここで FastMCP の出番です.通常はMCP サーバーを構築する際に,通信部分のコードが多くなりがちですが,FastMCP なら @mcp.tool() というデコレータをつけるだけで完了します.
from fastmcp import FastMCP
# サーバーの初期化
mcp = FastMCP("PersonalDevOpsPartner")
# ツールとして公開したい関数にデコレータをつける
@mcp.tool()
def plan_deployment(repo_url: str, target: str = "local") -> str:
"""
【Step 1】デプロイ計画を作成します。
リポジトリを解析し、アーキテクチャ図(Mermaid)を表示します。
Args:
repo_url: GitHubリポジトリURL
target: 'local' (PCで起動) or 'lambda' (AWSサーバーレス)
"""
# ... 実装 ...
@mcp.tool()
def apply_deployment(project_name: str, target: str = "local") -> str:
"""
【Step 2】承認された計画を実行(デプロイ)します。
"""
# ... 実装 ...
if __name__ == "__main__":
mcp.run()
ここで重要になるのが Docstring(関数の説明文) と 型ヒント です.MCP クライアント(今回は Claude for Desktop)は、この Docstring を読んで「どのような時にこのツールを使うべきか」を判断し、型ヒントを見て「どのような引数を渡すべきか」を決定します.
4.4.Claude for Desktop と MCPサーバーを繋げる
先ほど作成したMCPサーバーを Claude for Desktop に接続します.方法としては以下の流れで行います.
1.設定ファイル(claude_desktop_config.json)を開く
2.以下を設定ファイルに追加する
{
"mcpServers": {
"devops-partner": {
"command": "docker",
"args": [
"run",
"-i",
"--rm",
"-v", "/var/run/docker.sock:/var/run/docker.sock",
"--env-file", ".envファイルのある絶対パス",
"smartdeployagent-smart-deploy-agent"
]
}
}
}
今回は,MCPサーバーの実装をDocker上で実施しているため,MCPサーバーの実行ではインタラクティブモード(-i)でDockerを起動させます.また,解析対象とするリポジトリをプライベートのものとするため,envファイルに GITHUB_TOKEN を指定するようにしています.
5.動作確認
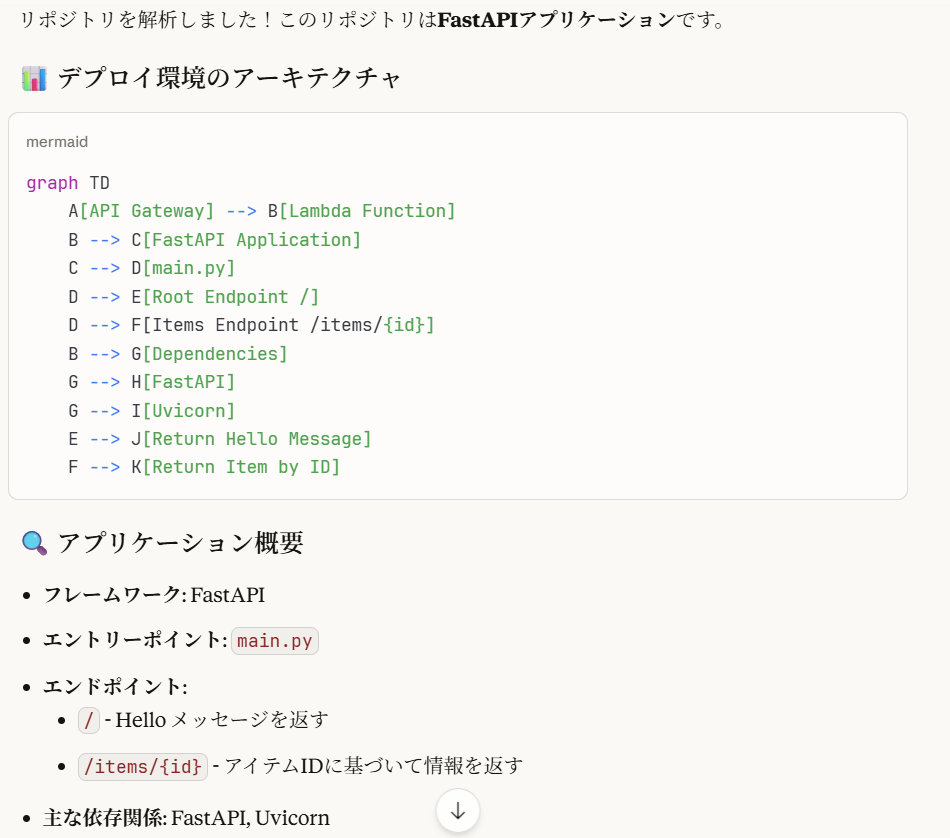
実際に Claude for Desktop からの入力を通してコードを解析し,デプロイ計画を実行してくれるかを確認してみます.解析対象として使用するリポジトリには簡易的なFastAPIサーバー(Helloメッセージを出力するだけ)を指定しています.

エージェントの処理が終わると,しっかりとリポジトリを解析しDockerfileとtemplate.yamlを生成し,かつデプロイ計画まで立ててくれています.
6.おわりに
今回はDeploy-Agent開発 Vol.1として,FastMCPとAWS Bedrockで「コードを読んで勝手にデプロイ計画を立てるAI」を作成してみました.エージェントのひな形となるMCPサーバーもFastMCPを使用することでとても簡単に作成できることが知れたのでとてもよかったです.Vol.2では,静的解析ツール(Lint)に怒られながらAIが自律的にコードを修正する「自己修正ループ」 の実装を実施してみます.興味のある方がいたらこちらも読んでみてください!最後まで読んでいただきありがとうございます!
7.参考文献
LlamaIndexでBedrockConverseを使用する方法
Claude for DesktopでMCPサーバーを使用する方法