1. 本記事について
Twitter上では時折、投稿した内容に対して多くの人の非難が集まる
いわゆる"炎上"してしまうケースが起こります。
本記事ではツイートの"文章の特徴"に基づいて、
投稿する内容が炎上するかどうかを機械学習で予測を
行った手法および結果を記載します。
2. 成果物
今回作成した予測モデル(3章以降で説明)については
Webサービスにして利用できるようにしてみました。
RDF 超入門
(いらすとや先生の素材をお借りしました。)
まだβ版的な感じですが良ければ遊んでみてください。鳥が燃えたらクリアです。
・使用イメージ
↓

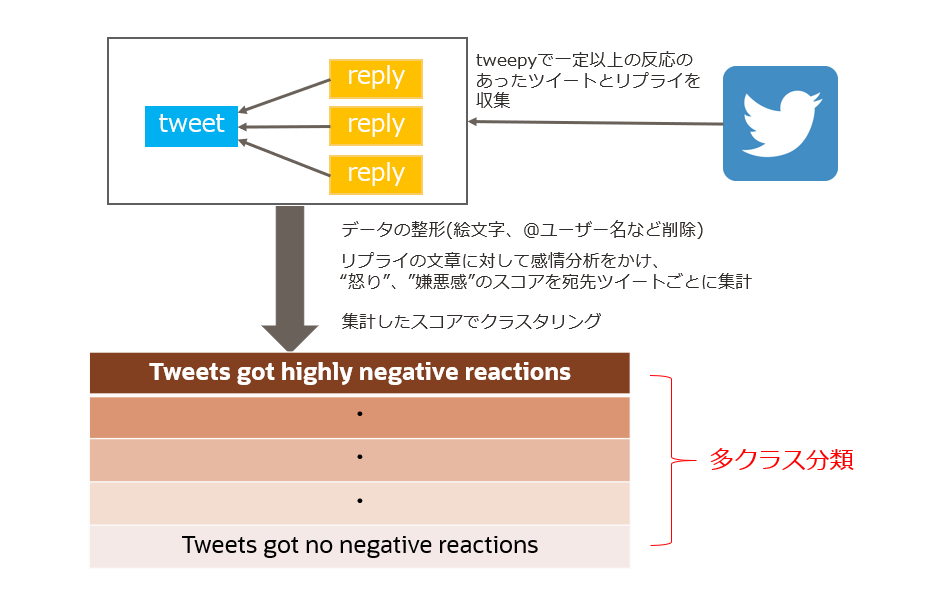
3. 炎上予測モデル作成の流れ
以下の図のようにデータ収集+前処理を実施し、
機械学習を用いたテキストの分類タスクに落とし込んでみます。
ネガティブな反応の多いグループと少ないグループに含まれるツイートでは
文章の特徴に異なった傾向があるのではないか、という仮説です。
2項分類でも良いかもしれないですが、段階的に評価できた方が面白そうなので
このようにしました。
4. モデル作成手順
4.1 データ準備
4.1.1 データ収集
こちらに投稿したコードを使って「一定以上の反応があったツイート」と、
「上記ツイートについたリプライ」のセットをcsvファイルにして収集しました。
今回使用したデータは以下の通りです。
期間:2020/5/20 ~ 2021/4/30
件数:ツイート 約48万件 / リプライ 約1800万件
対象ツイート:
・日本語での投稿
・投稿から2日後時点で、30件以上のリプライがついている
・画像、動画、URLリンク付きでない
以下の検索文字列をtweepyの引数に渡しています。
ツイート収集用:"lang:ja -filter:links exclude:retweets min_replies:30"
リプライ収集用:"lang:ja -filter:links filter:replies exclude:retweets"
なお、Twitter APIの取得上限に引っかかったりしているため、
期間内の条件に当てはまるツイート全てを収集できてはいません。
4.1.2 データロード
収集したcsv群をまとめてDataFrameにします。
ツイート→tweet_df、リプライ→reply_dfにロードします。
import pandas as pd
import csv
import glob
# csvディレクトリのパスを取得
DATA_PATH = "/csv_directory"
All_Files = glob.glob('{}tweet*'.format(DATA_PATH))
# ディレクトリ内の全csvをマージ
tweets = []
for file in All_Files:
tweets.append(pd.read_csv(file,engine='python'))
tweet_df = pd.concat(tweets, sort=False)
DataFrameは以下のカラム構造になっています。
・id (ツイートごとに一意のもの)
・to_id (宛先ツイートID ※リプライのみ)
・created_at (投稿日時)
・user (投稿したユーザー名)
・text (ツイート内容)
4.1.3 データ整形
・欠損値削除
tweet_df.dropna()
・ツイート文章内の絵文字、顔文字、@ユーザー名削除
import emoji
import nagisa
import unicodedata
import re
# 絵文字削除用関数
def remove_emoji(src_str):
return ''.join(c for c in src_str if c not in emoji.UNICODE_EMOJI)
# 顔文字削除関数
def remove_kaomoji(text):
KAOMOJI_LEN = 5
results = nagisa.extract(text, extract_postags=['補助記号'])
words = results.words
kaomoji_words = []
kaomoji_idx = [i for i, w in enumerate(words) if len(w) >= KAOMOJI_LEN]
kaomoji_hands = ['ノ', 'ヽ', '∑', 'm', 'O', 'o', '┐', '/', '\\', '┌']
# 顔文字と手を検索
for i in kaomoji_idx:
kaomoji = words[i]
try:
# 顔文字の左手
if words[i-1] in kaomoji_hands and 0 < i:
kaomoji = words[i-1] + kaomoji
# 顔文字の右手
if words[i+1] in kaomoji_hands:
kaomoji = kaomoji + words[i+1]
except IndexError:
pass
finally:
kaomoji_words.append(kaomoji)
# 抽出した顔文字を削除
for j in kaomoji_words:
text = text.replace(j, '')
return text
# 整形したテキストをDataFrameに追加
tweet_text = []
for text in tweet_df["text"]:
text = remove_emoji(text) #絵文字削除
text = remove_kaomoji(text) #顔文字削除
text = re.sub(r'@[0-9a-zA-Z_:]*', "", text) #@ユーザー名削除
tweet_text.append(text)
tweet_df["text_modified"] = tweet_text
※reply_dfにも同じ処理をします。
4.1.4 リプライの感情分析
テキストの感情分析ができるパッケージやAPIは多く存在しますが、
大半がPositive/Negativeの2軸での評価になっています。
しかし、Negativeな感情のうち、"悲しい"などは今回の炎上するか、
という観点からはズレていると考えられます。
※ 例えば著名人の訃報を知らせるツイートに対するリプライは
"悲しい"を中心としたNagativeな感情のスコアが高くなると想定されますが、
炎上とは異なるため
なのでこれらを除外するため、"嬉しい","悲しい","怒り","嫌悪感","驚き","恐怖"の
6種類で感情の評価ができるこちらのパッケージをお借りし、"怒り"と"嫌悪感"のスコアに注目して予測処理を行っていきます。
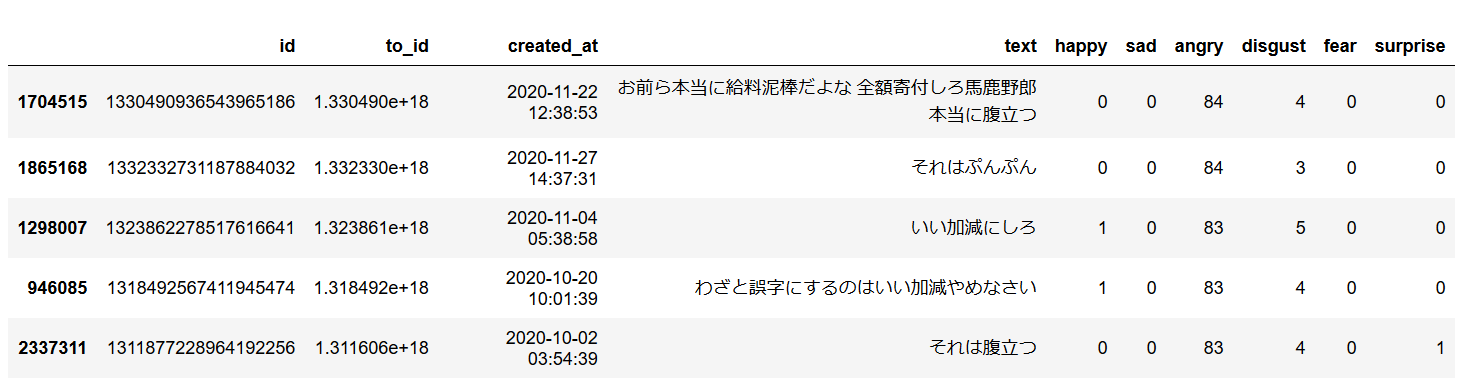
先ほどのデータ整形と同じように感情分析スコアを
"reply_df"に追加していき、以下のようにします。
各感情スコアの取り得る値の幅は0~100です。
宛先ツイートごとに感情分析スコアを集計します。
reply_groupby_df = reply_df.groupby('to_id').sum()
4.1.5 ツイートとリプライデータの結合
ツイートの文章と、集計したリプライの感情スコアがセットになるよう結合します。
tweet_reply_df = pd.merge(tweet_df, reply_groupby_df, left_on='id',right_on='to_id', how='inner')
4.2 データの確認
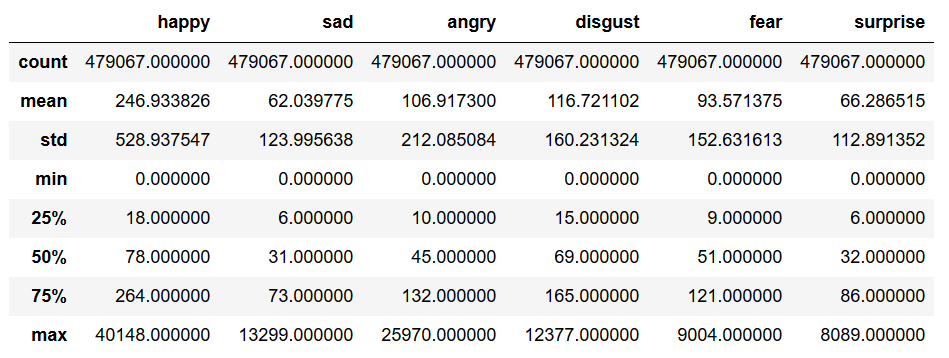
ツイートごとの感情スコアを確認します。
・統計値
・angry, disgustの分布

4.3 クラス分け
ここからangryとdisgustの値に基づいて、ツイートのクラス分けを行います。
angryとdisgustの値の和を取ってパーセントタイルで分けようかと考えていましたが、
先ほどの値の分布を見るとクラスタリングした方が良さそうです。
今回はk-meansでクラスタリングしてみます。
ただ、このままでは右上の外れ値の数件でクラスタが
できてしまいそうなので、min-max normalizationで値の正規化を行います。
tweet_reply_df["angry_mmn"] = (tweet_reply_df["angry"]-tweet_reply_df["angry"].min()) / (tweet_reply_df["angry"].max()-tweet_reply_df["angry"].min())
tweet_reply_df["disgust_mmn"] = (tweet_reply_df["disgust"]-tweet_reply_df["disgust"].min()) / (tweet_reply_df["disgust"].max()-tweet_reply_df["disgust"].min())
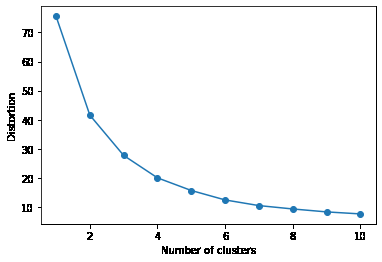
正規化したangry,disgustの値を元に、エルボー法でクラスタ数の見積りを行います。
from sklearn.cluster import KMeans
distortions = []
for i in range(1,11): # 1~10クラスタまで計算
km = KMeans(n_clusters=i,
init='k-means++',
n_init=10,
max_iter=300,
random_state=0)
km.fit(tweet_df[['disgust_mmn', 'angry_mmn']])
distortions.append(km.inertia_)
plt.plot(range(1,11),distortions,marker='o')
plt.xlabel('Number of clusters')
plt.ylabel('Distortion')
plt.show()
以下のような結果になりました。
曲線が急に下るあたりが適切なクラスタ数です。
3くらいが良さそうですが、今回は5で進めてみます。
正規化したangry,disgustの値でクラスタリングします。
# k-meansでdisgust,angryをもとに分類
kmeans_model = KMeans(n_clusters=5, random_state=0).fit(tweet_df[['disgust_mmn', 'angry_mmn']])
# 分類結果のラベルをDataFrameに追加
tweet_df["label"] = kmeans_model.labels_
クラスタリング結果です。
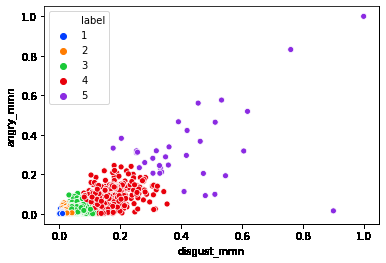
・批判的なリプライの最も多いクラスタのツイートを見てみる (label=5)

・批判的なリプライが最も少ないクラスタのツイートを見てみる (label=1)

目視で確認する限りですが、文章の特徴に有意な差異がありそうな感じがします。
大きく炎上したと思われるツイートには以下のような特徴が見受けられました。
・主語が大きい内容 (日本は~、男は~…etc)
・政治、性差、国民性、コロナ関連への言及
・不祥事についての謝罪
4.4 ツイート文章のベクトル化
ツイートが上記のどのクラスに所属するかを予測するにあたって、
ツイート文章の特徴ベクトルを取得します。
今回はベクトル化の手法としてBERTを使用します。
日本語学習済のBERTを使ったこちらのコードをお借りしました。
※ コード内の"sample_df"を"tweet_df"に置き換えて実行しています。
BSV = BertSequenceVectorizer()
tweet_df['text_feature'] = tweet_df['text_modified'].progress_apply(lambda x: BSV.vectorize(x))
4.5 機械学習モデリング
学習データとテストデータに9:1で分割します。
from sklearn.model_selection import train_test_split
feature_train, feature_test,label_train, label_test, weight_train, weight_test = train_test_split(tweet_df["text_feature"],tweet_df["label"], weight_list, test_size=0.1, shuffle=True)
モデルについてはいくつかアルゴリズムを試してみた中で、
一番精度が良かったXGBoostを使います。
※ クラスごとのサンプルサイズに偏りがあるため、sample_weight=...の箇所で
サンプルサイズに応じた重み付けを行っています。
import xgboost as xgb
from sklearn.model_selection import GridSearchCV
from sklearn.datasets import load_digits
# モデル定義
xgb_mc = xgb.XGBClassifier()
# ハイパーパラメータ探索
xgb_model_cv = GridSearchCV(xgb_mc, {'eta': [0.01,0.1,0.3], 'max_depth': [5,6,7,8,9,10], 'gamma': [0.01,0.1,1.0,10.0]}, verbose=1, n_jobs=-1, cv=5)
# 学習
xgb_model_cv.fit(feature_train, label_train, sample_weight=weight_train)
print(xgb_model_cv.best_params_, xgb_model_cv.best_score_)
4.6 モデル評価
分類精度を見てみます。
from sklearn.metrics import confusion_matrix, classification_report
pred = xgb_model_cv.predict(feature_test)
print(classification_report(label_test, pred))
| ラベル | precision | recall | f1-score | support |
|---|---|---|---|---|
| 1 | 0.51 | 0.60 | 0.55 | 5011 |
| 2 | 0.47 | 0.38 | 0.42 | 5023 |
| 3 | 0.34 | 0.29 | 0.31 | 2587 |
| 4 | 0.09 | 0.14 | 0.11 | 389 |
| 5 | 0.05 | 0.33 | 0.09 | 39 |
| 指標 | ||||
| accuracy | 0.44 | 13049 | ||
| macro avg | 0.29 | 0.35 | 0.30 | 13049 |
| weighted avg | 0.45 | 0.44 | 0.44 | 13049 |
全体のaccuracyは44%。大きく炎上したラベル4, 5の
サンプルサイズがもっとあると良くなりそうです。
逆翻訳(日本語⇒英語⇒日本語)でデータ量を増幅させてみたりすると
もっと精度が良くなるかもしれません。
また、今回は段階的なクラス分けになっているため、一応
ニアピンで外しているものも正解とした場合の精度もみてます。
result = sum(1*(p == t or p == t+1 or p==t-1) for p, t in zip(pred.tolist(), label_test)) / len(label_test)
print("Accuracy: {:.2f}".format(result))
Accuracy: 0.89
炎上する傾向がある程度は掴めている感じがします。
炎上したツイートをもっと効率的に集められると良いのですが
Twitterで検索文字列に ":(" を入れるネガティブ検索は
普通に顔文字として検索されているようで上手く機能していないようでした。
5. chatbot作成
Webサービス化するにあたって、分類結果を返すだけだと味気ないので、
想定されるリプライも返すようchatbotを作ってみました。
アプリ自体はdjangoを使って作っています。
5.1 会話データ準備
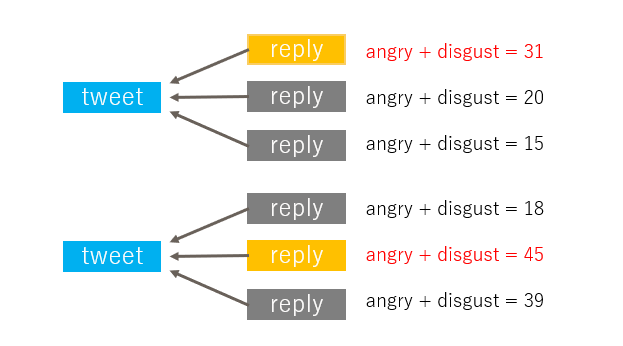
なるべく辛辣なリプライを返してくれた方が面白いかなと思ったので、
以下のように各ツイートへのリプライから"怒り"と"嫌悪感"のスコアの和が
最も高いリプライのみを抽出し、これを学習させる会話データとしました。
5.2 会話データの学習
Tensor2Tensorを使いました。
Tensor2Tensorを使ったchatbotの作成については
検索により手順が大量に出てくるためここでは割愛します。
以下のあたりを参考にさせて頂きました。
Tensor2Tensor Documentation
Tensor2Tensorで雑談チャットボットを作ったら今度はうまくいった話
あとがき
今回は炎上ツイートにフォーカスして予測をしてみましたが
炎上した内容でも何らかの課題提起になっていたりするので
必ずしも炎上=悪いということでは無いと思います。
ただ、投稿するツイートに対する反応をある程度予測できることに
価値があるのではないかと考えてやってみました。
また、今回は単にリプライの文章に対して感情分析をかけただけで
ツイートとリプライ間の文脈の考慮ができていません。
そのため、"ネガティブなワードを含む同意"が多いツイートを炎上する
可能性が高いと判定してしまっているケースがあったりします。
例)
「〇〇ひどいな」 ← 「ほんと最悪」
今後の展望
全体的にまだ拙い部分が多いと思いますので
まとまった時間が取れたら見直してみる予定です。
以上です。