はじめに
GANの一種、cGAN(conditional GAN)を用いてくずし字MNISTの生成をやってみました。
詳しい理論面については適宜参考になるリンクなどを載せるので、参照してください。
- PyTorchでGANを実装したい
- 狙った画像を生成できるモデルが作りたい
といった方の参考になれば幸いです。
くずし字MNIST(KMNIST)とは
今回使うデータセットについてです。
KMNISTは、人文学オープンデータ共同利用センターによって作成された、「日本古典籍くずし字データセット」の派生として機械学習用として作られたデータセットのことです。
GitHubのリンクからダウンロードすることができます。

『KMNISTデータセット』(CODH作成) 『日本古典籍くずし字データセット』(国文研ほか所蔵)を翻案 doi:10.20676/00000341
機械学習やったことある人ならだれもが知っているあのMNIST(手書き数字)と同じく、1枚の画像が1×28px×28pxのサイズになっています。
リポジトリからは以下の3種類のデータセットが、numpy.arrayの圧縮形式でダウンロードできます。
- kuzushiji-MNIST(ひらがな10文字)
- kuzushiji-49(ひらがな49文字)
- kuzushiji-kanji(漢字3832文字)
今回はこのうち、"kuzushiji-49"を用います。深い理由は特にありませんが、ひらがな49文字が狙って生成できるのならば、手書き文章を生成できそう?と思ったのが軽いモチベーションです。
GANとは
cGANの前にGANについて軽くふれておきます。
GANは"Generative Adversarial Network"(=敵対的生成ネットワーク)の略で、ディープラーニングの生成モデルの一種です。特に画像生成の分野で威力を発揮しており、世界に存在しない人の顔画像を生成した結果などが有名かと思います。
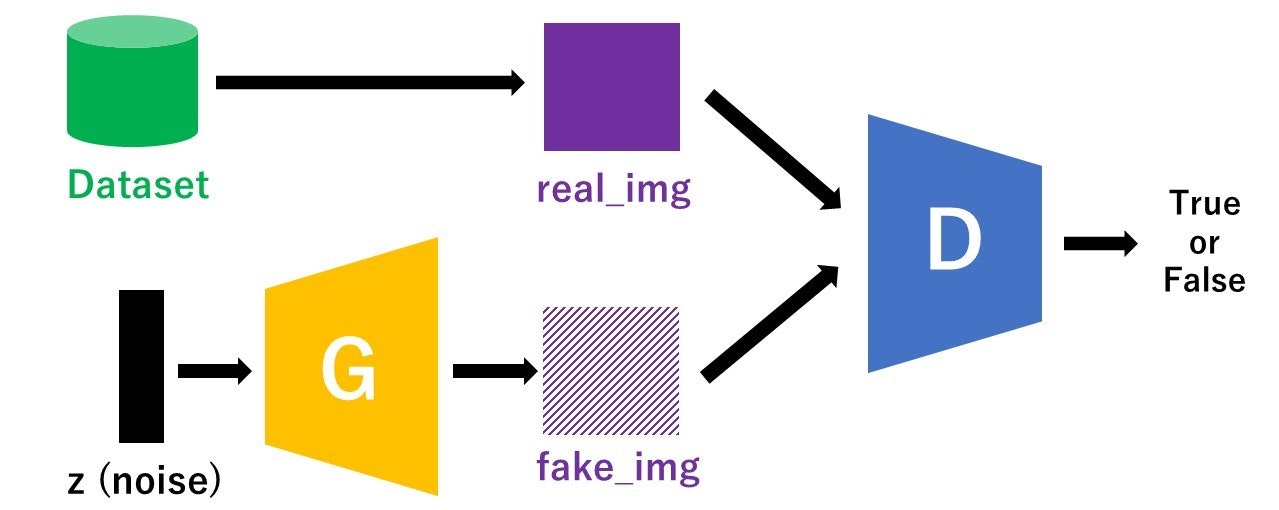
GANのモデル構造
以下に示したのがざっくりとしたGANのモデル図です。"G"がGeneratorで"D"がDiscriminatorを表しています。
Generatorはノイズからできるだけ本物に近い偽物画像を生成します。
Discriminatorはデータセットからとってきた本物画像(real_img)とGeneratorによって作られた偽物画像(fake_img)を判別します(True or False)。
この学習を繰り返して行うことで、GeneratorはできるだけDiscriminatorに見破られないような本物に近い画像を作ろうとし、DiscriminatorはGeneratorが作った偽物とデータセット由来の本物を見破ろうとするので、Generatorの生成精度が上がっていきます。
<参考記事>
今さら聞けないGAN(1) 基本構造の理解
GAN関連の論文はこのGitHubリポジトリにまとまっています。
cGAN(conditional GAN)とは
続いて、今回使うconditional GANについてです。
簡単に言えば、**「狙った画像を生成できるGAN」**です。発想としてはシンプルで、discriminatorやGeneratorの入力にラベル情報を加えることで、生成する画像を決めようという感じです。
元論文はこちら
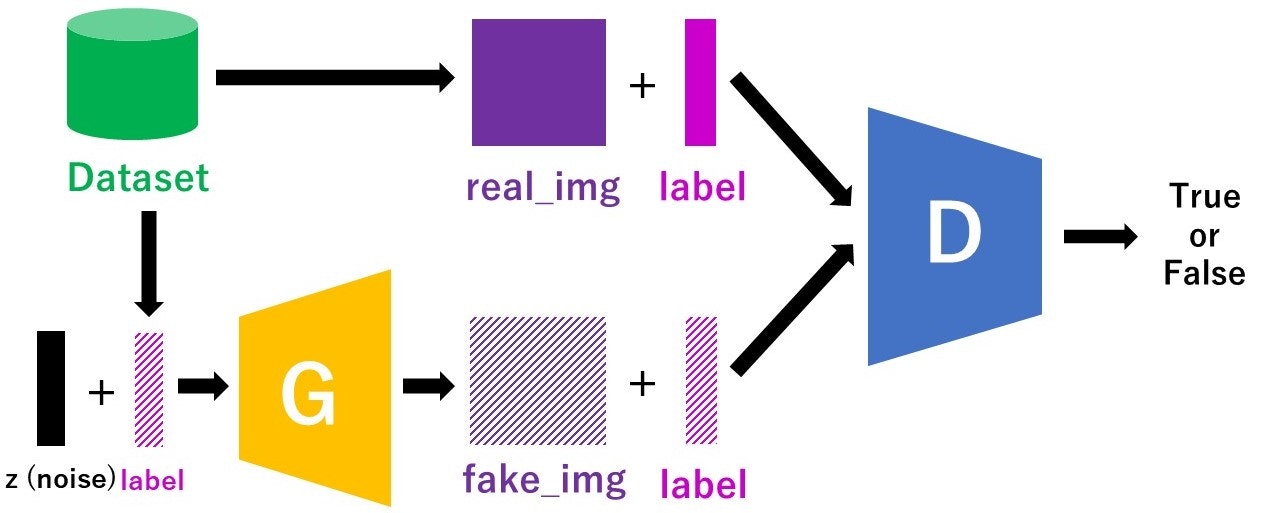
cGANのモデル構造
**「訓練時にラベルも入力する」**という点以外は普通のGANと変わりません。
また、ラベル情報を用いてはいますが、Discriminatorが判別するのは「その画像が本物かどうか」だけです。
<参考記事>
今さら聞けないGAN(6) Conditional GANの実装
実装
それでは、実装に入っていきます。
環境
Ubuntu18.04上にjupyterlabをインストールして動かしています。
- Python 3.7.4
- PyTorch 1.4.0
- torchvision 0.5.0
学習の準備
必要なmoduleをimport
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import numpy as np
import matplotlib.pyplot as plt
import time
import random
データセットを作る
データをダウンロード
先ほどのKMNISTのgithubからnumpyフォーマットのデータをダウンロードします。
jupyterlabなら、Terminalを開いてリポジトリを移動した後で
wget http://codh.rois.ac.jp/kmnist/dataset/k49/k49-train-imgs.npz
wget http://codh.rois.ac.jp/kmnist/dataset/k49/k49-train-labels.npz
とやれば画像とラベルがダウンロードできます。
ちなみに、ひらがな10文字のKMNISTであれば、torchvisionの方にデフォルトで入っています。そちらでよければ普通のMNISTと同じように
transform = transforms.Compose(
[transforms.ToTensor(),
])
train_data_10 = torchvision.datasets.KMNIST(root='./data', train=True,download=True,transform=transform)
とやれば使えます。
データの前処理
PyTorchで自分でカスタマイズしたデータセットを作りたい場合、前処理を自分で定義する必要があります。画像系の前処理はtorchvision.transformsの中に大体入っているので、これを利用することが多いですが、自分で作ることもできます。
class Transform(object):
def __init__(self):
pass
def __call__(self, sample):
sample = np.array(sample, dtype = np.float32)
sample = torch.tensor(sample)
return (sample/127.5)-1
transform = Transform()
numpyで扱う小数はnp.float64(浮動小数点数64bit)が多いですが、PyTorchでは小数の値をデフォルトだと浮動小数点数32bitで扱うので、揃えないとエラーがでます。
また、ここで画像の輝度値を[-1,1]の範囲に正規化する処理を行っています。これは、後で出てくるGeneratorの出力の最終層でTanhを使っているので、本物画像の輝度値をそれに合わせた形にするためです。
Datasetクラス
続いて、Datasetクラスを定義していきます。
これはデータとラベルを1組返すモジュールで、データを取り出すときに先ほど定義したtransformで前処理したデータを返します。
from tqdm import tqdm
class dataset_full(torch.utils.data.Dataset):
def __init__(self, img, label, transform=None):
self.transform = transform
self.data_num = len(img)
self.data = []
self.label = []
for i in tqdm(range(self.data_num)):
self.data.append([img[i]])
self.label.append(label[i])
self.data_num = len(self.data)
def __len__(self):
return self.data_num
def __getitem__(self, idx):
out_data = self.data[idx]
out_label = np.identity(49)[self.label[idx]]
out_label = np.array(out_label, dtype = np.float32)
if self.transform:
out_data = self.transform(out_data)
return out_data, out_label
最初のtqdmを入れておくとfor文を回したときに進捗状況が棒グラフのように表示されますが、特にcGAN本体には関係ありません。
np.identityを用いて、長さ49のone-hotベクトルを作っています。
DLしたデータからDatasetを形成
先ほどダウンロードしたデータから実装したTransform,Datasetクラスを用いてDatasetを作ります。
path = %pwd
train_img = np.load('{}/k49-train-imgs.npz'.format(path))
train_img = train_img['arr_0']
train_label = np.load('{}/k49-train-labels.npz'.format(path))
train_label = train_label['arr_0']
train_data = dataset_full(train_img, train_label, transform=transform)
先ほどのtqdmを入れておくと、これを実行したときに進捗状況が表示されます。最も、データ数は232625個ですが、これに時間はかからないと思います。
DataLoaderを作成
Datasetはできましたが、モデルを訓練するときにこのデータセットから直接データを取ってくることはありません。バッチごとに訓練するので、バッチサイズのデータを返してくれるDataLoaderを定義します。
batch_size = 256
train_loader = torch.utils.data.DataLoader(train_data, batch_size = batch_size, shuffle = True, num_workers=2)
shuffle=Trueにすると、DataLoaderからとってくるデータがランダムになります。num_workersはDataLoaderが使うcpuのコア数を指定する引数で、特にcGAN本体には関係ありません。
ここまでのTransform~Dataset~DataLoaderについては、以下の記事にまとまっています。
<参考記事>
PyTorch transforms/Dataset/DataLoaderの基本動作を確認する
Generatorを定義
モデル本体を作っていきます。Generatorはノイズ(noise)とラベル(labels)から偽物画像(fake_img)を作ります。
人によっても実装の仕方が結構違いますが、今回作ったGeneratorの構造は以下です。
(手書きですが勘弁・・・)
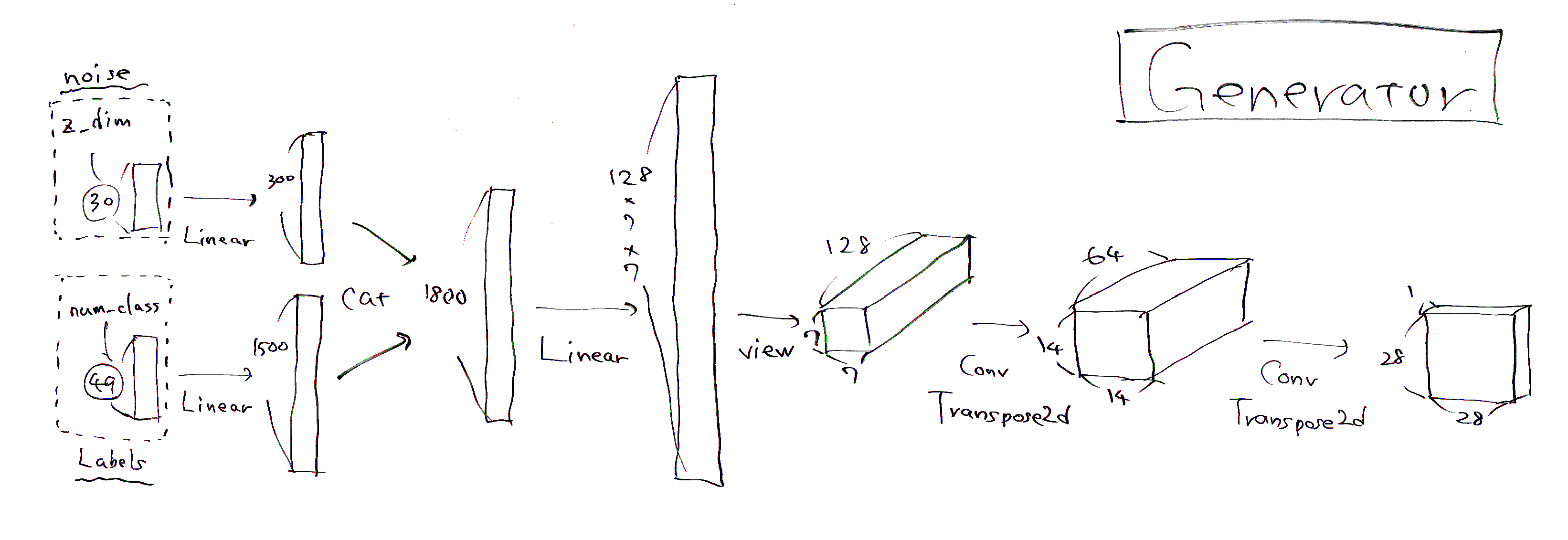
入力でz_dim(ノイズの次元)が30、num_class(クラス数)はひらがな49文字ですので49にしています。出力の偽物画像は1(チャネル)×28(px)×28(px)の形状になります。
class Generator(nn.Module):
def __init__(self, z_dim, num_class):
super(Generator, self).__init__()
self.fc1 = nn.Linear(z_dim, 300)
self.bn1 = nn.BatchNorm1d(300)
self.LReLU1 = nn.LeakyReLU(0.2)
self.fc2 = nn.Linear(num_class, 1500)
self.bn2 = nn.BatchNorm1d(1500)
self.LReLU2 = nn.LeakyReLU(0.2)
self.fc3 = nn.Linear(1800, 128 * 7 * 7)
self.bn3 = nn.BatchNorm1d(128 * 7 * 7)
self.bo1 = nn.Dropout(p=0.5)
self.LReLU3 = nn.LeakyReLU(0.2)
self.deconv = nn.Sequential(
nn.ConvTranspose2d(128, 64, kernel_size=4, stride=2, padding=1), #チャネル数を128⇒64に変える。
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2),
nn.ConvTranspose2d(64, 1, kernel_size=4, stride=2, padding=1), #チャネル数を64⇒1に変更
nn.Tanh(),
)
self.init_weights()
def init_weights(self):
for module in self.modules():
if isinstance(module, nn.ConvTranspose2d):
module.weight.data.normal_(0, 0.02)
module.bias.data.zero_()
elif isinstance(module, nn.Linear):
module.weight.data.normal_(0, 0.02)
module.bias.data.zero_()
elif isinstance(module, nn.BatchNorm1d):
module.weight.data.normal_(1.0, 0.02)
module.bias.data.zero_()
elif isinstance(module, nn.BatchNorm2d):
module.weight.data.normal_(1.0, 0.02)
module.bias.data.zero_()
def forward(self, noise, labels):
y_1 = self.fc1(noise)
y_1 = self.bn1(y_1)
y_1 = self.LReLU1(y_1)
y_2 = self.fc2(labels)
y_2 = self.bn2(y_2)
y_2 = self.LReLU2(y_2)
x = torch.cat([y_1, y_2], 1)
x = self.fc3(x)
x = self.bo1(x)
x = self.LReLU3(x)
x = x.view(-1, 128, 7, 7)
x = self.deconv(x)
return x
Discriminatorの定義
続いて、Discriminatorです。Discriminatorは本物/偽物画像とそのラベル情報を入力し、本物か偽物かを判定します。
今回作ったDiscriminatorの構造は以下です。
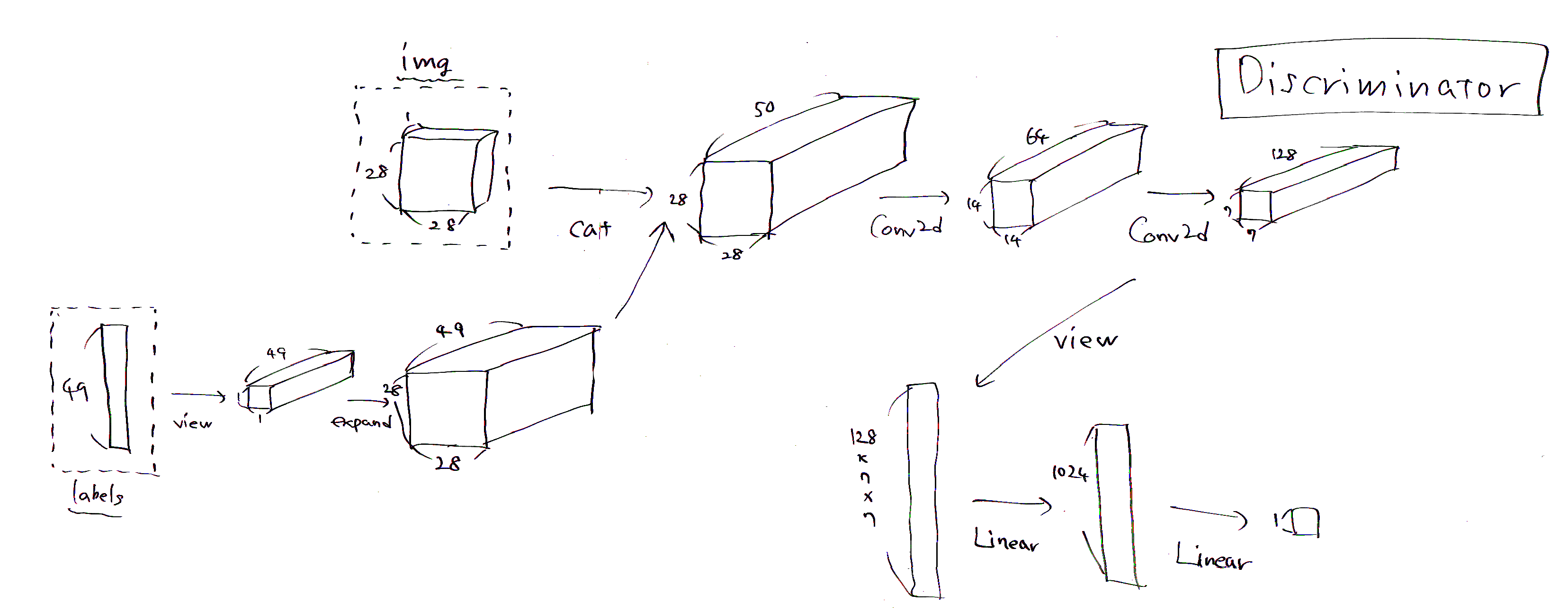
img(入力画像)は本物も偽物も1(チャネル)×28(px)×28(px)、labels(入力ラベル)は49次元のone-hotベクトルです。出力で本物かどうかを0~1の値で判定します。
途中のcatで画像とラベル情報をチャネル方向にconcatします。この辺のことは先ほどのcGANの記事がわかりやすいかと思います。
class Discriminator(nn.Module):
def __init__(self, num_class):
super(Discriminator, self).__init__()
self.num_class = num_class
self.conv = nn.Sequential(
nn.Conv2d(num_class + 1, 64, kernel_size=4, stride=2, padding=1),
nn.LeakyReLU(0.2),
nn.Conv2d(64, 128, kernel_size=4, stride=2, padding=1),
nn.LeakyReLU(0.2),
nn.BatchNorm2d(128),
)
self.fc = nn.Sequential(
nn.Linear(128 * 7 * 7, 1024),
nn.BatchNorm1d(1024),
nn.LeakyReLU(0.2),
nn.Linear(1024, 1),
nn.Sigmoid(),
)
self.init_weights()
def init_weights(self):
for module in self.modules():
if isinstance(module, nn.Conv2d):
module.weight.data.normal_(0, 0.02)
module.bias.data.zero_()
elif isinstance(module, nn.Linear):
module.weight.data.normal_(0, 0.02)
module.bias.data.zero_()
elif isinstance(module, nn.BatchNorm1d):
module.weight.data.normal_(1.0, 0.02)
module.bias.data.zero_()
elif isinstance(module, nn.BatchNorm2d):
module.weight.data.normal_(1.0, 0.02)
module.bias.data.zero_()
def forward(self, img, labels):
y_2 = labels.view(-1, self.num_class, 1, 1)
y_2 = y_2.expand(-1, -1, 28, 28)
x = torch.cat([img, y_2], 1)
x = self.conv(x)
x = x.view(-1, 128 * 7 * 7)
x = self.fc(x)
return x
1エポック当たりの計算
1エポックの計算を行う関数を作ります。
def train_func(D_model, G_model, batch_size, z_dim, num_class, criterion,
D_optimizer, G_optimizer, data_loader, device):
#訓練モード
D_model.train()
G_model.train()
#本物のラベルは1
y_real = torch.ones((batch_size, 1)).to(device)
D_y_real = (torch.rand((batch_size, 1))/2 + 0.7).to(device) #Dに入れるノイズラベル
#偽物のラベルは0
y_fake = torch.zeros((batch_size, 1)).to(device)
D_y_fake = (torch.rand((batch_size, 1)) * 0.3).to(device) #Dに入れるノイズラベル
#lossの初期化
D_running_loss = 0
G_running_loss = 0
#バッチごとの計算
for batch_idx, (data, labels) in enumerate(data_loader):
#バッチサイズに満たない場合は無視
if data.size()[0] != batch_size:
break
#ノイズ作成
z = torch.normal(mean = 0.5, std = 0.2, size = (batch_size, z_dim)) #平均0.5の正規分布に従った乱数を生成
real_img, label, z = data.to(device), labels.to(device), z.to(device)
#Discriminatorの更新
D_optimizer.zero_grad()
#Discriminatorに本物画像を入れて順伝播⇒Loss計算
D_real = D_model(real_img, label)
D_real_loss = criterion(D_real, D_y_real)
#DiscriminatorにGeneratorにノイズを入れて作った画像を入れて順伝播⇒Loss計算
fake_img = G_model(z, label)
D_fake = D_model(fake_img.detach(), label) #fake_imagesで計算したLossをGeneratorに逆伝播させないように止める
D_fake_loss = criterion(D_fake, D_y_fake)
#2つのLossの和を最小化
D_loss = D_real_loss + D_fake_loss
D_loss.backward()
D_optimizer.step()
D_running_loss += D_loss.item()
#Generatorの更新
G_optimizer.zero_grad()
#Generatorにノイズを入れて作った画像をDiscriminatorに入れて順伝播⇒見破られた分がLossになる
fake_img_2 = G_model(z, label)
D_fake_2 = D_model(fake_img_2, label)
#Gのloss(max(log D)で最適化)
G_loss = -criterion(D_fake_2, y_fake)
G_loss.backward()
G_optimizer.step()
G_running_loss += G_loss.item()
D_running_loss /= len(data_loader)
G_running_loss /= len(data_loader)
return D_running_loss, G_running_loss
引数で出てくるcriterionはlossのクラス(今回はBinary Cross Entropy)のことです。
この関数でやっているのは、順番に
- Datasetの本物画像をDiscriminatorに入れて誤差逆伝播
- Generatorで作った偽物画像をDiscrminatorに入れて誤差逆伝播(このときGeneratorは更新しない)
- Generatorで作った偽物画像をDiscriminatorに入れて、Generatorを誤差逆伝播
です。
実装の工夫
すこし古いですが、"How to Train a GAN"at NIPS2016に出てくる、GANの学習をうまくいかせるための工夫を今回の実装に盛り込んであります。
GitHubリンク
<参考記事>
GAN(Generative Adversarial Networks)を学習させる際の14のテクニック
※番号は記事とGitHubリンク内の番号と対応しています。
1.入力を正規化
Datasetクラスを作ったときの
return (sample/127.5)-1
がこれです。また、Generatorの最終層もnn.Tanh()にしています。
2.GのLoss関数を修正
# Gのloss(max(log D)で最適化)
G_loss = -criterion(D_fake_2, y_fake)
がこれに当たります。D_fake_2がDiscriminatorの判定、y_fakeというのは128×1の0ベクトルです。
3.zはガウス分布から
Generatorに入れるノイズを一様分布ではなく正規分布からサンプルします。
# ノイズ作成
z = torch.normal(mean = 0.5, std = 0.2, size = (batch_size, z_dim)) #平均0.5の正規分布に従った乱数を生成
平均と標準偏差は適当ですが、一様分布だと[0,1]からサンプルすればマイナスの値が出ないので、サンプルされたノイズの値がほとんど正になるようにしました。
4.Batch Norm
上の方で作ったDataLoaderから出てくるデータはすべて本物画像です。逆に
fake_img = G_model(z, label)
ではDataLoaderからとってきたラベル情報とノイズから、バッチサイズ個の偽物画像を作っています。
5.ReLUやMax Poolingのように勾配がスパースになるものは避ける
GeneratorとDiscriminatorの両方でLeakyReLUが有効らしいので、活性化関数はすべてLeakyReLUにしています。引数の0.2は多くの実装でこの値が採用されていたので従いました。
6.Dの正解ラベルにはノイジーなラベルを使う
Discriminatorのラベルは、普通は0or1ですが、ここにノイズを加えます。本物ラベルを0.7~1.2、偽物ラベルを0.0~0.3からランダムにサンプリングします。
# 本物のラベルは1
y_real = torch.ones((batch_size, 1)).to(device)
D_y_real = (torch.rand((batch_size, 1))/2 + 0.7).to(device) #Dに入れるノイズラベル
# 偽物のラベルは0
y_fake = torch.zeros((batch_size, 1)).to(device)
D_y_fake = (torch.rand((batch_size, 1)) * 0.3).to(device) #Dに入れるノイズラベル
この部分です。普通に使うのがy_real/y_fakeで、今回実際に使ったのがD_y_real/D_y_fakeの方です。
9.最適化手法はAdamを使う
これは記事が古いので今ではRAdamなど別のoptimizerの方が良いかもしれません。
14.GにDropoutを入れる
今回はGeneratorのLinearの層に1回だけDropoutをいれました。ですが、BatchNormとDropoutの相性が悪い説もあるので、一概に入れた方が絶対に良くなるとは言えない気がします。
Generatorが作った画像を表示する
モデルを訓練する前に、Generatorが作った画像を表示する関数を定義しておきます。これを作っておいて、epochごとにGeneratorの学習度合いをチェックします。
import os
from IPython.display import Image
from torchvision.utils import save_image
%matplotlib inline
def Generate_img(epoch, G_model, device, z_dim, noise, var_mode, labels, log_dir = 'logs_cGAN'):
G_model.eval()
with torch.no_grad():
if var_mode == True:
#生成に必要な乱数
noise = torch.normal(mean = 0.5, std = 0.2, size = (49, z_dim)).to(device)
else:
noise = noise
#Generatorでサンプル生成
samples = G_model(noise, labels).data.cpu()
samples = (samples/2)+0.5
save_image(samples,os.path.join(log_dir, 'epoch_%05d.png' % (epoch)), nrow = 7)
img = Image('logs_cGAN/epoch_%05d.png' % (epoch))
display(img)
やっていることは単純で、Generatorにノイズを入れて作った画像をlogs_cGANというフォルダに入れ、表示するだけです。
var_modeがFalseの時には毎回同じ乱数を使うことを想定しています。
モデルの訓練
モデルを訓練します。
# 再現性確保のためseed値固定
SEED = 1111
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
torch.cuda.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
# device
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def model_run(num_epochs, batch_size = batch_size, dataloader = train_loader, device = device):
#Generatorに入れるノイズの次元
z_dim = 30
var_mode = False #表示結果を見るときに毎回異なる乱数を使うかどうか
#生成に必要な乱数
noise = torch.normal(mean = 0.5, std = 0.2, size = (49, z_dim)).to(device)
#クラス数
num_class = 49
#Generatorを試すときに使うラベルを作る
labels = []
for i in range(num_class):
tmp = np.identity(num_class)[i]
tmp = np.array(tmp, dtype = np.float32)
labels.append(tmp)
label = torch.Tensor(labels).to(device)
#モデル定義
D_model = Discriminator(num_class).to(device)
G_model = Generator(z_dim, num_class).to(device)
#lossの定義(引数はtrain_funcの中で指定)
criterion = nn.BCELoss().to(device)
#optimizerの定義
D_optimizer = torch.optim.Adam(D_model.parameters(), lr=0.0002, betas=(0.5, 0.999), eps=1e-08, weight_decay=1e-5, amsgrad=False)
G_optimizer = torch.optim.Adam(G_model.parameters(), lr=0.0002, betas=(0.5, 0.999), eps=1e-08, weight_decay=1e-5, amsgrad=False)
D_loss_list = []
G_loss_list = []
all_time = time.time()
for epoch in range(num_epochs):
start_time = time.time()
D_loss, G_loss = train_func(D_model, G_model, batch_size, z_dim, num_class, criterion,
D_optimizer, G_optimizer, dataloader, device)
D_loss_list.append(D_loss)
G_loss_list.append(G_loss)
secs = int(time.time() - start_time)
mins = secs / 60
secs = secs % 60
#エポックごとに結果を表示
print('Epoch: %d' %(epoch + 1), " | 所要時間 %d 分 %d 秒" %(mins, secs))
print(f'\tLoss: {D_loss:.4f}(Discriminator)')
print(f'\tLoss: {G_loss:.4f}(Generator)')
if (epoch + 1) % 1 == 0:
Generate_img(epoch, G_model, device, z_dim, noise, var_mode, label)
#モデル保存のためのcheckpointファイルを作成
if (epoch + 1) % 5 == 0:
torch.save({
'epoch':epoch,
'model_state_dict':G_model.state_dict(),
'optimizer_state_dict':G_optimizer.state_dict(),
'loss':G_loss,
}, './checkpoint_cGAN/G_model_{}'.format(epoch + 1))
return D_loss_list, G_loss_list
# モデルを回す
D_loss_list, G_loss_list = model_run(num_epochs = 100)
なんだかやたら長いですが、エポックごとに所要時間やlossを表示させたり、モデルを保存したりしています。
結果
GeneratorとDiscriminatorのlossの推移を見てみます。
import matplotlib.pyplot as plt
%matplotlib inline
fig = plt.figure(figsize=(10,7))
loss = fig.add_subplot(1,1,1)
loss.plot(range(len(D_loss_list)),D_loss_list,label='Discriminator_loss')
loss.plot(range(len(G_loss_list)),G_loss_list,label='Generator_loss')
loss.set_xlabel('epoch')
loss.set_ylabel('loss')
loss.legend()
loss.grid()
fig.show()

20epochあたりからはどちらのlossも変わらなくなっています。
DiscriminatorとGeneratorのlossはどちらも0からは遠いので、割とうまくいってそうです。
ちなみに生成された文字を1~100epochまでで順番にgifにしてみるとこんな感じです。
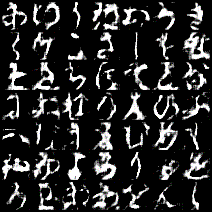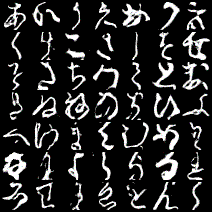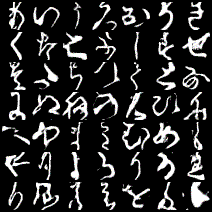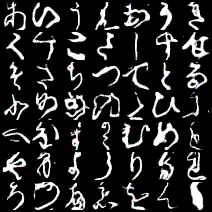
一番左上が「あ」で、一番右下が「ゝ」になっています。
これは文字によって結構差があり、「う」「く」「さ」「そ」「ひ」あたりは安定してうまく生成できているように見えますが、「な」「ゆ」などは遷移が激しいです。
以下、1種類につき5枚ずつ画像を生成した結果です。
Epoch:5

Epoch:50

Epoch:100

これだけ見ると、Epochを重ねた方が良いとは言えなさそうです。「む」なんかは5epoch時点が一番よさそうな一方で、「ゑ」が一番いいのは100epochに見えます。
ちなみに、同じように訓練データを5枚ずつ取ってくるとこんな感じです。

現代人でも読めなさそうなのがちらほら混じっています。「す」や「み」なんかは今の形とかなり違います。これを見ると、モデルの性能は結構良いのではないかと思います。
まとめ
cGANでくずし字生成をやってみました。
実装はまだ向上の余地がたくさんありそうな気がしますが、結果自体はそれなりのものになったかなと思います。
かなり長くなってしましましたが、一部分でも何かの役に立てたら幸いです。
また、cGANでPyTorchを使って一般的なMNIST(手書き数字の方)を実装している方もいらっしゃいます。モデル構造など異なる部分が多くあるので、こちらも参考になると思います。
<参考記事>
ディープラーニングで手書き文字生成してみた【Pytorch×MNIST×CGAN 】
最後に
元々「手書き文章を生成できるのでは?」と思ったのが軽いモチベーションだったので、最後にそれをやってみます。
保存したcheckpointのファイルからモデルの重みをloadしてきて、いったんpklにしてみます。
import cloudpickle
%matplotlib inline
# 取り出すepochを指定する
point = 50
# モデルの構造を定義
z_dim = 30
num_class = 49
G = Generator(z_dim = z_dim, num_class = num_class)
# checkpointを取り出す
checkpoint = torch.load('./checkpoint_cGAN/G_model_{}'.format(point))
# Generatorにパラメータを入れる
G.load_state_dict(checkpoint['model_state_dict'])
# 検証モードにしておく
G.eval()
# pickleで保存
with open ('KMNIST_cGAN.pkl','wb')as f:
cloudpickle.dump(G,f)
普通のpickleではなく、cloudpickleというモジュールを使えばpklにできるみたいです。
このpklファイルを開いて文章を生成してみます。
letter = 'あいうえおかきくけこさしすせそたちつてとなにぬねのはひふへほまみむめもやゆよらりるれろわゐゑをんゝ'
strs = input()
with open('KMNIST_cGAN.pkl','rb')as f:
Generator = cloudpickle.load(f)
for i in range(len(str(strs))):
noise = torch.normal(mean = 0.5, std = 0.2, size = (1, 30))
str_index = letter.index(strs[i])
tmp = np.identity(49)[str_index]
tmp = np.array(tmp, dtype = np.float32)
label = [tmp]
img = Generator(noise, torch.Tensor(label))
img = img.reshape((28,28))
img = img.detach().numpy().tolist()
if i == 0:
comp_img = img
else:
comp_img.extend(img)
save_image(torch.tensor(comp_img), './sentence.png', nrow=len(str(strs)))
img = Image('./sentence.png')
display(img)
結果はこんな感じです。
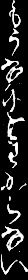
「もうなにもわからない」ですね......