概要
RTX2080を衝動買いしたため、これで機械学習を高速化できないか、とtensorflow+CUDA10自家ビルドで試してみた話。
結果としては「FP32性能上昇分しか変わりませんでした」という残念なものになっています。
ただ、やり方を間違えている可能性はあるのでいずれリベンジ記事を書け...ればいいなぁ。
なおこの記事ですが「Windows10+Python3.6」というマイナー(?)環境でやっていますのでその点ご注意を。
前準備
RTX20xxシリーズの機能をフルに使うにはCUDA10の案内で「Turingサポート」が挙げられているので、CUDA10を使ってやる必要がありそう。
が、ビルド済みパッケージの提供は
| プラットフォーム | CUDAバージョン |
|---|---|
| Tensorflow v1.11 | 9.0 |
| Pytorch 0.4 | 9.2 |
という状況で、どちらもCUDA10は組み込まれていません(10/9現在)。
なければビルド...ということでビルドしてみましたが、どちらも一筋縄ではビルドできず。
そもそもWindowsビルドなんてそんな検証されてない(であろう)ため、解決策を探すのに難儀しましたが、こちらの神記事のお蔭で無事解決。
自分がWindowsビルドで嵌った以下4か所はすべてこの文書でカバーされてました。
- VC2015 update3以上じゃないとだめ(VS2017 CommunityはOK)
- checkout version/configure.pyで成功する組み合わせ(v1.11+CUDA10.0+CuDNN7.3.1でOK)
- cuda/half.hでビルドエラーが出る問題(patchで対応)
- ビルドは通るんだけどパッケージができない問題(zipファイルが2GBを超えないよう手修正)
なおビルド時のconfigure.pyでは使用するカードに合わせたCompute Capabilityを設定する必要があるんですが、configure.pyの設定時に両方("6.1,7.5"みたいに)設定すると
「zipファイルが2Gを超えないようにする」を満たすのが非常に難しくなります。仕方がないのでCC6.1ビルドとCC7.5ビルドの2パッケージを作ることにしました。
| 使用カード | Compute Capability |
|---|---|
| Geforce 10xx | 6.1 |
| Geforce 2080ti/2080/2070 | 7.5 |
どちらも"tensorflow-1.11.0-cp36-cp36m-win_amd64.whl"という同名パッケージとしてできてしまうので、差し替えの際にはアンインストール→インストールの手順を踏む必要があります...
ちなみにPytorchもビルドしようとしたんですが、今日時点では
MPI関連のライブラリがリンクできない件とかat::optionalのコンストラクタ問題とかにあたって解決できず。
まぁ2つ分検証するのも面倒だからTensorflowだけでいいや
検証
さて、以下の確認を行ってみようと思います。
ベンチマークにはTensorflowチュートリアルにのってるImages/Pix2Pix を使ってみました。Tesla P100だと1epoch58秒で回るらしい。
- 6.1ビルド + GTX1060
- 6.1ビルド + RTX2080
- 7.5ビルド + RTX2080(FP32)
- 7.5ビルド + RTX2080(FP16)
コードはKerasベースなので、FP32/FP16の切り替えは
import keras.backend as K
K.set_floatx('float16')
で良い..はず。(FP16)として検証している個所は、上記を(モデル構築直前である)コードセル7に突っ込んでいます。
コードセル19の実行時、1epoch実行ごとに時間を表示してくれるみたいで、
1回目が少し多め、2回目以降は安定するため2回目以降での表示を手メモした結果が以下。
| テスト番号 | Tensorflowビルド | GPU | FP16指定 | 実行時間 |
|---|---|---|---|---|
| 1 | v1.11.0+CUDA10+CC6.1 | GTX1060 | なし | 113.8sec |
| 2 | v1.11.0+CUDA10+CC6.1 | RTX2080 | なし | 66.6sec |
| 3 | v1.11.0+CUDA10+CC7.5 | RTX2080 | なし | 66.9sec |
| 4 | v1.11.0+CUDA10+CC7.5 | RTX2080 | あり | 65.1sec |
FP32 FLOPSはGTX1060が4.4T、RTX2080が10.0Tなので大体FP32性能比率通りですね。
性能2倍超なのに時間が2倍以下になってしまっているのはCPUからのデータ転送でGPUが遊んでしまっているためと予想。
タスクマネージャで見てもcompute_0が70%程度しか動いていません。
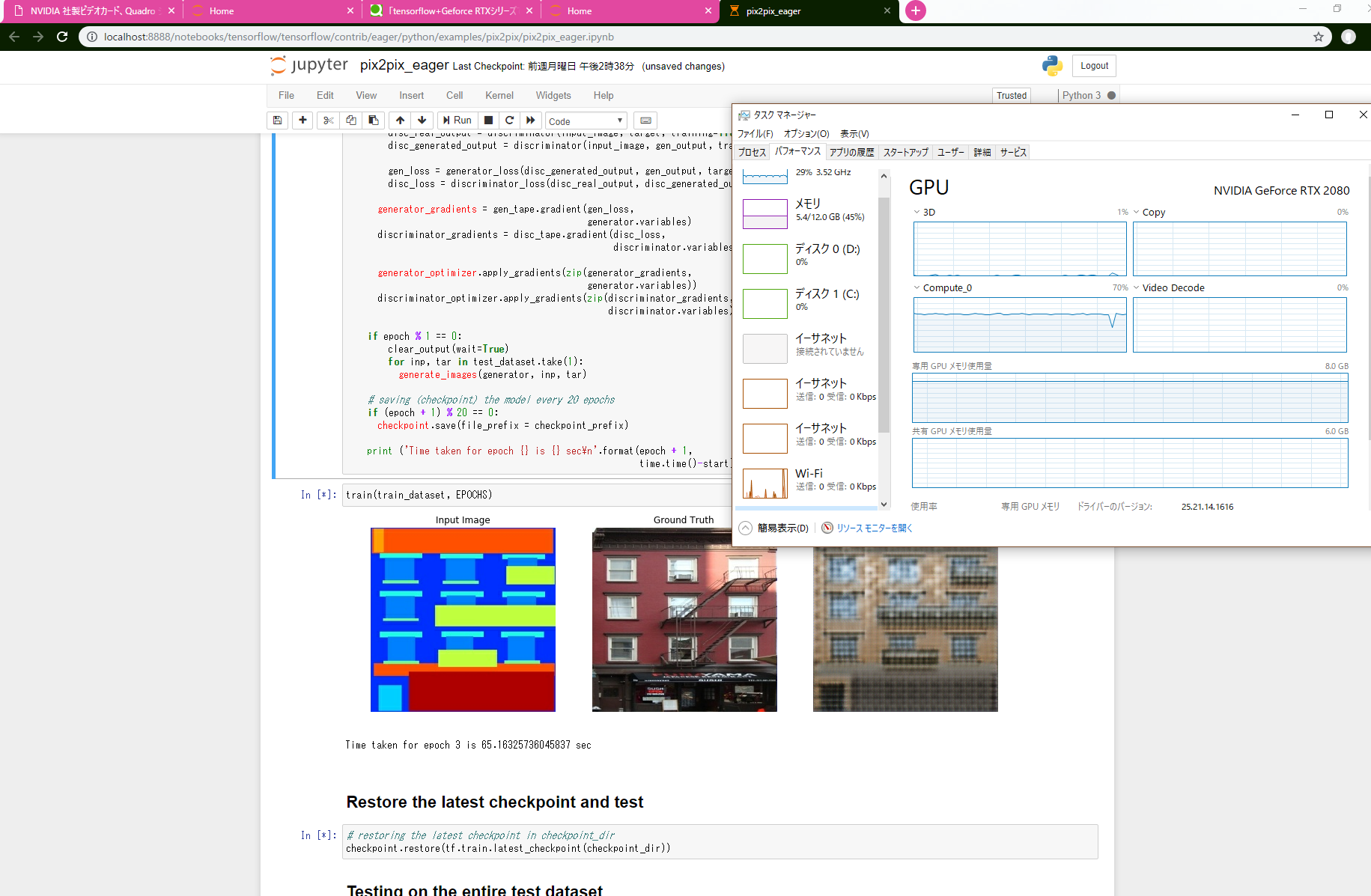
で、FP16にしたときにTensorCoreで爆速..になればよかったのですが、誤差程度。
相変わらずFP32で動いているようにしか見えません。
NvidiaがVoltaのTensorCoreに向けて書いた資料では
Tensorflow1.4時で「tf.cast(...,tf.float16)すればTensorコア使う」とか書いてあるんですけどねぇ...
今後
まずはNvidiaのプロファイラの使い方を覚えねば。jupyterと相性悪そうだなぁ.. →やってみました