本記事でやること
-
encoding/json/v2(以下v2)のUnmarshal関数の内部実装を読み解く -
export変数を通じた内部APIアクセスの仕組みを理解する -
sync.Poolによるメモリ効率化の仕組みを理解する
対象読者
-
encoding/json(v1, v2)を使ったことがある方 - Go標準ライブラリの内部実装に興味がある方
はじめに
encoding/json/v2とは
encoding/json/v2は、Go1.25で実験的に追加されたGo標準ライブラリのJSONパッケージの次期バージョンです。現在はまだ実験的な立ち位置ですが、今後標準パッケージとして採用される可能性があります。
v1の設計を見直し、以下の改善が図られています:
- パフォーマンスの向上: メモリアロケーションの削減
- 機能の拡張: より柔軟なカスタマイズオプション
-
パッケージの分離: 低レベルAPI(
jsontext)と高レベルAPI(json)の明確な分離
本記事では、Unmarshal関数の実装を通じて、これらの改善がどのように実現されているかを見ていきます。
この記事で扱う範囲
今回はUnmarshal関数のエントリーポイントに焦点を当てます:
-
export変数による内部APIアクセス -
sync.Poolによるオブジェクト再利用 -
Decoder構造体の役割
実際の型判定やJson解析処理については、続編で解説します。
Unmarshal関数の実装
まずはともあれ、Unmarshal関数の実装を見てみましょう。パッとみただけでv1とv2でだいぶ実装が違うことがわかります。
それでは、順を追って処理を追っていきましょう。
v2のUnmarshal関数の実装
v1のUnmarshal関数の実装
export変数とは
Unmarshal関数の実装を見ると、最初に登場するのがexport変数です。
このexport変数は、jsonパッケージからjsontextパッケージの内部機能を安全に利用するための変数です。
export変数は同ファイル内で以下のように定義されています
この定義を理解するには、Export関数の実装を見る必要があります
export構造体は以下のようなパブリックなメソッドを持っており、jsontextパッケージのプライベートな関数を内部的に呼んでいます。
つまり、このexportオブジェクトを通してでしかjsontextパッケージの内部機能/内部状態にアクセスできないということです。
以下の図は、v2のパッケージ構成を示しています。jsonパッケージのUnmarshalからjsontextパッケージのDecoderを繋ぐ線がexport変数の役割を表しています。
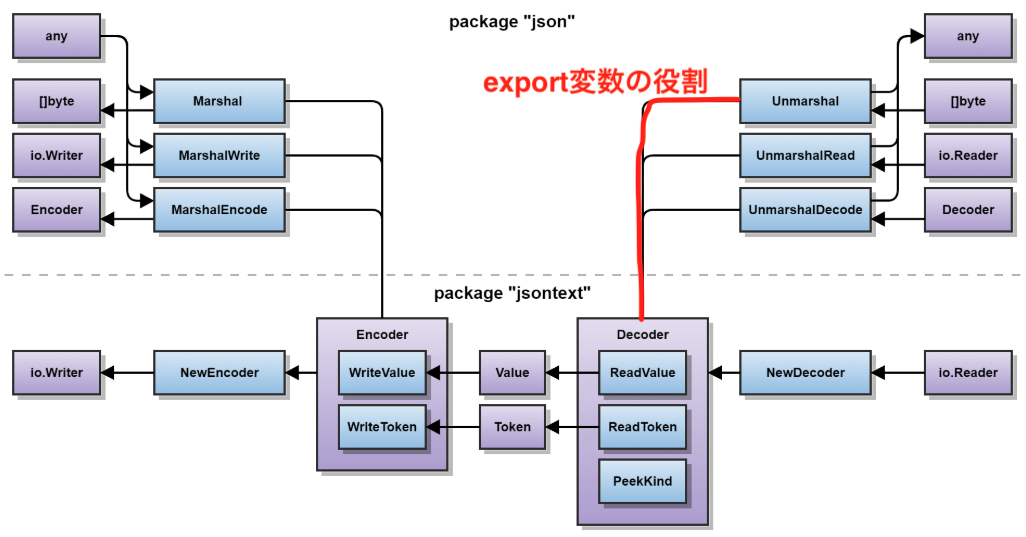
export.GetBufferedDecoder関数
まず、最初の行のexport.GetBufferedDecoderメソッドを追っていきます。
export.GetBufferedDecoderメソッドは内部的に以下のgetBufferedDecoder関数を呼んでいます。この関数は、Unmarshal関数が受け取った[]byteとOptions型の入力をそのまま受け取り、Decoder型のポインタを返します。
Decoder構造体
Decoder構造体の定義は以下の通りです。Decoder構造体を一言で表現すると「Jsonを解析するための内部状態を保持する構造体」といえます。
Decoder構造体は、decoderState型の1つのフィールドを持ちます。
ここでは、decoderState構造体に埋め込まれている、decoderBuffer構造体に焦点をあてます。
decoderBuffer構造体
decoderBuffer構造体の定義は以下の通りです。
decoderBuffer構造体は以下の役割を持つフィールドが存在します。
| フィールド名 | 主な役割 |
|---|---|
| peekPos | 次のトークンの開始位置(先読み) |
| peekErr | 先読み時のエラー |
| buf | 入力データを保持するバッファ |
| prevStart | 前回読んだ値の開始位置 |
| prevEnd | 前回読んだ値の終了位置 |
コメントアウトに記載されている通り、buf, prevStart, prevEndフィールドを用いて以下の4つのセグメントを管理します。
| セグメント | 説明 |
|---|---|
| buf[0:prevEnd] | 既に読み終わった部分 |
| buf[prevStart:prevEnd] | 前回読んだ値 |
| buf[prevEnd:len(buf)] | これから読む部分 |
| buf[len(buf):cap(buf)] | 未使用(拡張可能な領域) |
具体的な例を用いて説明すると、以下の入力jsonがあったときnameまで読んだ直後の状態は以下の通りになります。
入力: {"name":"Alice","age":30}
buf: [{"name":"Alice","age":30}]
0 1 7 14 24
| | |
| prevStart (1)
| prevEnd (7)
既読: {"name"
前回の値: "name"
未読: :"Alice","age":30}
上記のことから、Decoder構造体はJsonデータを効率的に処理するための状態(どこまで読んだかなど)を管理する構造体だと言えます。
具体的になぜこのような設計にしているのかは、jsonを処理していく過程から読み解いていきたいと思います。
getBufferedDecoder関数
1行目のbufferedDcoderPool変数は同ファイル内で以下のように定義されています。
-
Decoderオブジェクトを再利用するためのsync.Poolによって定義されたオブジェクトプール -
GetメソッドによってプールにDecoderオブジェクトがあれば再利用し、なければ初期化する
2行目のresetメソッドは、前回の内部状態を消去し、今回処理する入力バッファやオプションをdecodeBuffer構造体に設定しDecoder構造体を再度初期化します。
前回の状態は完全に消去されるので、異なる入力でも同じDecoder構造体を安全に再利用ができます。
export.PutBufferedDecoder関数
Unmarshal関数を抜ける際にdeferで実行される処理です。
PutBufferedDecoder関数も内部的にはjsontextパッケージのputBufferedDecoder関数が実行されています。
この関数では、Decoder構造体で保持していた入力バッファをnilに初期化し、オブジェクトプールにDecoderオブジェクトを返却します。つまり、Unmarshal関数が次に呼ばれることに備えて内部状態を初期化して、オブジェクトプールを再利用するための役割を担っています。
sync.Poolによるメモリ効率の改善
getBufferedDecoder関数とputBufferedDecoder関数は、sync.Poolを使ってDecoderオブジェクトを再利用します。
// プールから取得(初回は新規作成、2回目以降は再利用)
dec := bufferedDecoderPool.Get().(*Decoder)
// 使用後にプールへ返却(次回の再利用のため)
defer putBufferedDecoder(dec)
オブジェクトプールを使わないとUnmarshal関数が実行されるたびに毎回小さくはないサイズのメモリが確保されます。そのため、頻度高くGCが発生することになります。
オブジェクトプールを使うことで、メモリアロケーションとGCを削減することを達成しています。v2では、decodeState構造体が大きくなったため、プールによる再利用が効果的になったのではないかと考えています。
v1との比較
v1のUnmarshal関数の実装は以下の通りです。内部状態を保持するdecodeState構造体を毎回ゼロ値で初期化しています。
v2ではプールによってオブジェクトを再利用する設計に変更したことで、メモリ効率が改善したと考えられます。
export.Decoder関数
GetBufferedDecoder関数の次に実行されるDecoderメソッドはjsontextパッケージにあるDecoder構造体の非公開フィールドであるdecoderStateにアクセスする役割を担っています。
まとめ
Unmarshal関数のエントリーポイントで行われること
-
export.GetBufferedDecoder: プールからDecoderを取得(または新規作成) -
export.Decoder:Decoderの内部状態(decoderState)にアクセス -
unmarshalDecode: 実際のJson解析処理(次回解説) -
export.PutBufferedDecoder:Decoderをプールに返却
v2の設計の特徴
-
パッケージ分離:
jsontext(低レベル)とjson(高レベル) -
安全な内部アクセス:
export変数による制御 -
メモリ効率:
sync.Poolによるオブジェクト再利用
次回予告
次回は、unmarshalDecode関数の内部を見ていきます: