(目次はこちら)
はじめに
ロジスティック回帰 [TensorFlowでDeep Learning 1]をtensorflow2.0で実現するためにはどうしたらいいのかを書く。
方法
-
tf_upgrade_v2- 1系からの暫定的な移行用としか思えない
-
tf.keras- 間違いない
コード
Python: 3.6.8, Tensorflow: 2.0.0a0で動作確認済み
ロジスティック回帰 [TensorFlowでDeep Learning 1] (mnist_logistic.py)を書き換えると、
v2/mnist_logistic.py
from helper import *
IMAGE_SIZE = 28 * 28
CATEGORY_NUM = 1
LEARNING_RATE = 0.1
EPOCHS = 30
BATCH_SIZE = 100
LOG_DIR = 'log_logistic'
EPS = 1e-10
def loss_fn(y_true, y):
y = tf.clip_by_value(y, EPS, 1.0 - EPS)
return -tf.reduce_mean(y_true * tf.math.log(y) + (1 - y_true) * tf.math.log(1 - y))
class LR(tf.keras.layers.Layer):
def __init__(self, units, *args, **kwargs):
super().__init__(*args, **kwargs)
self.units = units
def build(self, input_shape):
input_dim = int(input_shape[-1])
self.W = self.add_weight(
name='weight',
shape=(input_dim, self.units),
initializer=tf.keras.initializers.GlorotUniform()
)
self.b = self.add_weight(
name='bias',
shape=(self.units,),
initializer=tf.keras.initializers.Zeros()
)
self.built = True
def call(self, x):
return tf.nn.sigmoid(tf.matmul(x, self.W) + self.b)
if __name__ == '__main__':
(X_train, y_train), (X_test, y_test) = mnist_samples(flatten_image=True, binalize_label=True)
model = tf.keras.models.Sequential()
model.add(LR(CATEGORY_NUM, input_shape=(IMAGE_SIZE,)))
model.compile(loss=loss_fn, optimizer=tf.keras.optimizers.SGD(LEARNING_RATE), metrics=['accuracy'])
cb = [tf.keras.callbacks.TensorBoard(log_dir=LOG_DIR)]
model.fit(X_train, y_train, batch_size=BATCH_SIZE, epochs=EPOCHS, callbacks=cb, validation_data=(X_test, y_test))
print(model.evaluate(X_test, y_test))
v2/helper.py
import numpy as np
import tensorflow as tf
def mnist_samples(flatten_image=False, binalize_label=False):
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data()
def normalize(images):
return images.astype(np.float32) / 255.0
def flatten(images):
d, w, h = images.shape
return images.reshape(d, w * h)
def binalize(labels):
return list(map(lambda x: [1] if x == 1 else [0], labels))
def one_hot_label(labels):
return tf.keras.utils.to_categorical(labels, 10)
X_train, X_test = normalize(X_train), normalize(X_test)
if flatten_image:
X_train, X_test = flatten(X_train), flatten(X_test)
if binalize_label:
y_train, y_test = binalize(y_train), binalize(y_test)
else:
y_train, y_test = one_hot_label(y_train), one_hot_label(y_test)
return (X_train, y_train), (X_test, y_test)
と書け、ちゃんと動く。
$ python mnist_logistic.py
Train on 60000 samples, validate on 10000 samples
Epoch 1/20
2019-05-20 15:50:09.369914: I tensorflow/core/profiler/lib/profiler_session.cc:164] Profile Session started.
60000/60000 [==============================] - 1s 11us/sample - loss: 0.0633 - accuracy: 0.9820 - val_loss: 0.0387 - val_accuracy: 0.9899
Epoch 2/20
60000/60000 [==============================] - 1s 9us/sample - loss: 0.0413 - accuracy: 0.9879 - val_loss: 0.0329 - val_accuracy: 0.9915
...
Epoch 19/20
60000/60000 [==============================] - 1s 9us/sample - loss: 0.0294 - accuracy: 0.9915 - val_loss: 0.0240 - val_accuracy: 0.9936
Epoch 20/20
60000/60000 [==============================] - 1s 9us/sample - loss: 0.0292 - accuracy: 0.9916 - val_loss: 0.0239 - val_accuracy: 0.9937
10000/10000 [==============================] - 0s 10us/sample - loss: 0.0239 - accuracy: 0.9937
[0.023882714230008425, 0.9937]
実際は、こんなに長ったらしく書く必要はなく、
v2/mnist_logistic_simple.py でOK
v2/mnist_logistic_simple.py
from helper import *
IMAGE_SIZE = 28 * 28
CATEGORY_NUM = 1
LEARNING_RATE = 0.1
EPOCHS = 20
BATCH_SIZE = 100
LOG_DIR = 'log_logistic'
if __name__ == '__main__':
(X_train, y_train), (X_test, y_test) = mnist_samples(flatten_image=True, binalize_label=True)
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Dense(CATEGORY_NUM, input_shape=(IMAGE_SIZE,), activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer=tf.keras.optimizers.SGD(LEARNING_RATE), metrics=['accuracy'])
cb = [tf.keras.callbacks.TensorBoard(log_dir=LOG_DIR)]
model.fit(X_train, y_train, batch_size=BATCH_SIZE, epochs=EPOCHS, callbacks=cb, validation_data=(X_test, y_test))
print(model.evaluate(X_test, y_test))
もはや、tensorflowの原形がない。
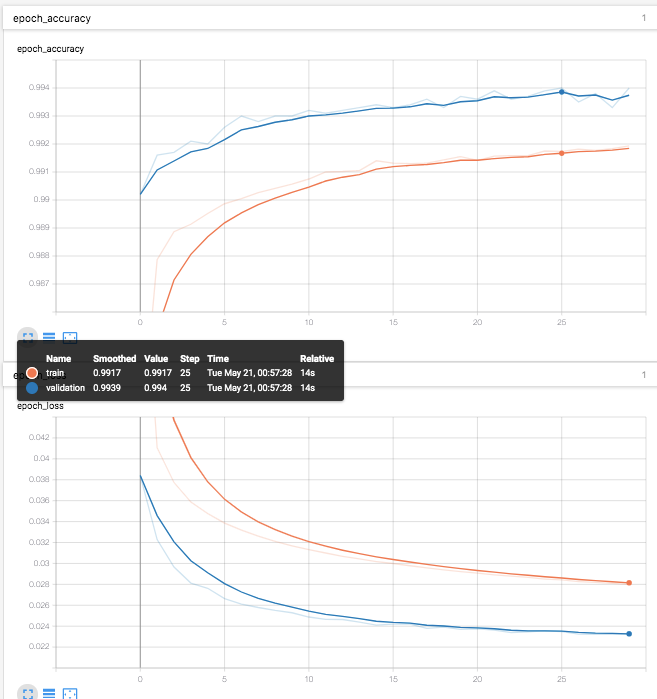
TensorBoardも引き続き利用できる。(なぜか、validationがtrainを常に上回っている。。。)