画像認識で爆笑問題を判別
コロナで暇だったのでサクッと作りました。
コードは欅坂46の画像認識した時の使い回しがほとんどです。
ディープラーニングで、好きなものを画像認識してみたい方は是非!
初めてでもできるように、つまずきそうな箇所も記載しています!!
[pythonの環境設定はこれだけでいけると思います!]
(https://prog-8.com/docs/python-env)
ディレクトリ
/bakusyomondai
/data
/TANAKA
/ota
/face
/ota
/TANAKA
/train
/ota
/TANAKA
/test
/ota
/TANAKA
get_image.py
detect_face/py
devide_test_train.py
inflation.py
learn2.py
Bakunin.py
例えば、macの場合は下のようになってます。

目次
1,学習させる画像をダウンロード
2,ダウンロードした画像の顔検出
3,学習させる画像の水増し
4,学習(DeepLearninng本番)
5,学習したモデルを使って、画像を判別
1,学習させる画像をダウンロード
まずは、get_image.pyという以下のようなファイルを作って保存してください。
google検索の画像から自動でダウンロードする方法はこちら
from icrawler.builtin import BingImageCrawler
import sys
import os
argv = sys.argv
if not os.path.isdir(argv[1]):
os.makedirs(argv[1])
crawler = BingImageCrawler(storage = {"root_dir" : argv[1]})
crawler.crawl(keyword = argv[2], max_num = 1000)
このpythonファイルをターミナルで以下のように実行してもらうと画像をダウンロードしてくれます。
例えば、爆笑問題の田中をダウンロードしたい時は、
$ python */get_image.py */data/TANAKA 爆笑問題 田中
と実行してもらえるとダウンロードが開始します。
イメージとしては
$python */get_image.py 保存したい場所のディレクトリ 検索したい名前
ちなみに
今回コードの中に */get_image.py みたいにアスタリスクがたくさん出てくると思いますが、今回はあえてアスタリスクで隠してあるので
皆さん自身のパソコンにある、ファイルのディレクトリを確認する時は下のリンクを参考にしてください。
windowsの場合
Macの場合
2、ダウンロードした画像の顔検出
先ほど作ったファイルの中身は以下のようになっていると思います。
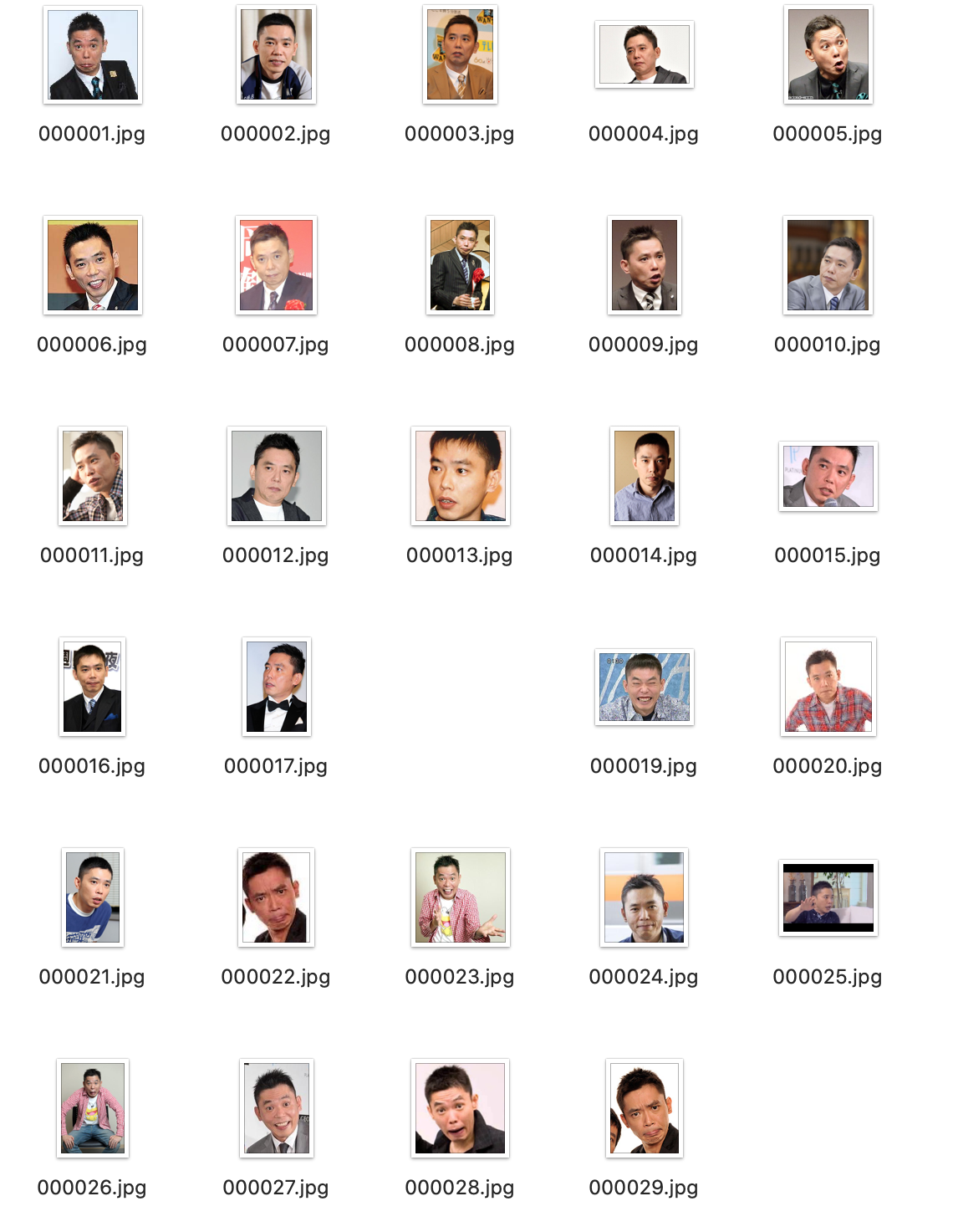
太田さん以外の写真がある場合は削除して、太田さん以外の人も写っている場合は太田さんだけの顔を切り抜きしました。
まず今回は、以下のコードを使いました。
import glob
import os
import cv2
names = ['ota','TANAKA']
out_dir = "*/bakusyomondai/face/"
os.makedirs(out_dir, exist_ok=True)
for i in range(len(names)):
in_dir = "*/bakusyomondai/data/"+names[i]+"/*.jpg"
in_jpg = glob.glob(in_dir)
os.makedirs(out_dir + names[i], exist_ok=True)
# print(in_jpg)
print(len(in_jpg))
for num in range(len(in_jpg)):
image=cv2.imread(str(in_jpg[num]))
if image is None:
print("Not open:",num)
continue
image_gs = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
cascade = cv2.CascadeClassifier("*/haarcascade_frontalface_alt.xml")
face_list=cascade.detectMultiScale(image_gs, scaleFactor=1.1, minNeighbors=2,minSize=(64,64))
if len(face_list) > 0:
for rect in face_list:
x,y,width,height=rect
image = image[rect[1]:rect[1]+rect[3],rect[0]:rect[0]+rect[2]]
if image.shape[0]<64:
continue
image = cv2.resize(image,(64,64))
fileName=os.path.join(out_dir+"/"+names[i],str(num)+".jpg")
cv2.imwrite(str(fileName),image)
print(str(num)+".jpgを保存しました.")
else:
print("no face")
continue
print(image.shape)
このコードを実行すると
 このように、先ほどダウンロードした画像の顔だけが切り取られた画像が、faceファイル内に出来上がります。
このように、先ほどダウンロードした画像の顔だけが切り取られた画像が、faceファイル内に出来上がります。
顔検出にはhaarcascade_frontalface_alt.xmlというカスケードファイルを使うので、
ここからダウンロードしてください!
3、画像を訓練データとテストデータに分ける。
import shutil
import random
import glob
import os
names = ['ota','TANAKA']
os.makedirs("*/bakusyomondai/test", exist_ok=True)
for name in names:
in_dir = "*/bakusyomondai/face/"+name+"/*"
in_jpg=glob.glob(in_dir)
img_file_name_list=os.listdir("*/bakusyomondai/face/"+name+"/")
#img_file_name_listをシャッフル、そのうち2割をtest_imageディテクトリに入れる
random.shuffle(in_jpg)
os.makedirs('*/bakusyomondai/test/' + name, exist_ok=True)
for t in range(len(in_jpg)//5):
shutil.move(str(in_jpg[t]), "*/bakusyomondai/test/"+name)
4、訓練データの水増し
さすがに今の画像の数だと少ないので画像を水増しします。
import os
import cv2
import glob
from scipy import ndimage
names = ['ota','TANAKA']
os.makedirs("*/bakusyomondai/train", exist_ok=True)
for name in names:
in_dir = "*/bakusyomondai/face/"+name+"/*"
out_dir = "*/bakusyomondai/train/"+name
os.makedirs(out_dir, exist_ok=True)
in_jpg=glob.glob(in_dir)
img_file_name_list=os.listdir("*/bakusyomondai/face/"+name+"/")
for i in range(len(in_jpg)):
#print(str(in_jpg[i]))
img = cv2.imread(str(in_jpg[i]))
for ang in [-10,0,10]:
img_rot = ndimage.rotate(img,ang)
img_rot = cv2.resize(img_rot,(64,64))
fileName=os.path.join(out_dir,str(i)+"_"+str(ang)+".jpg")
cv2.imwrite(str(fileName),img_rot)
img_thr = cv2.threshold(img_rot, 100, 255, cv2.THRESH_TOZERO)[1]
fileName=os.path.join(out_dir,str(i)+"_"+str(ang)+"thr.jpg")
cv2.imwrite(str(fileName),img_thr)
img_filter = cv2.GaussianBlur(img_rot, (5, 5), 0)
fileName=os.path.join(out_dir,str(i)+"_"+str(ang)+"filter.jpg")
cv2.imwrite(str(fileName),img_filter)
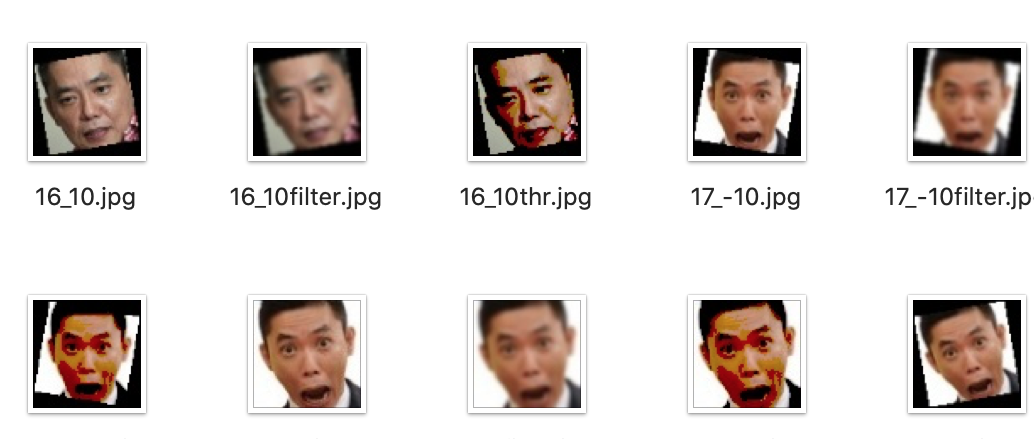
実行すると、以下のように画像が水増しされます。
5、学習の開始
import keras
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers.convolutional import Conv2D, MaxPooling2D
from keras.layers.core import Dense, Dropout, Activation, Flatten
import numpy as np
from sklearn.model_selection import train_test_split
from PIL import Image
import glob
folder = ['ota','TANAKA']
image_size = 50
X_train = []
y_train = []
for index, name in enumerate(folder):
dir = "*/bakusyomondai/train/" + name
files = glob.glob(dir + "/*.jpg")
for i, file in enumerate(files):
image = Image.open(file)
image = image.convert("RGB")
image = image.resize((image_size, image_size))
data = np.asarray(image)
X_train.append(data)
y_train.append(index)
X_train = np.array(X_train)
y_train = np.array(y_train)
folder = ['ota','TANAKA']
image_size = 50
X_test = []
y_test = []
for index, name in enumerate(folder):
dir = "*/bakusyomondai/test/" + name
files = glob.glob(dir + "/*.jpg")
for i, file in enumerate(files):
image = Image.open(file)
image = image.convert("RGB")
image = image.resize((image_size, image_size))
data = np.asarray(image)
X_test.append(data)
y_test.append(index)
X_test = np.array(X_test)
y_test = np.array(y_test)
X_train = X_train.astype('float32')
X_train = X_train / 255.0
X_test = X_test.astype('float32')
X_test = X_test / 255.0
# 正解ラベルの形式を変換
y_train = np_utils.to_categorical(y_train, 2)
# 正解ラベルの形式を変換
y_test = np_utils.to_categorical(y_test, 2)
# CNNを構築
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same',input_shape=X_train.shape[1:]))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(2))
model.add(Activation('softmax'))
# コンパイル
model.compile(loss='categorical_crossentropy',optimizer='SGD',metrics=['accuracy'])
history = model.fit(X_train, y_train, epochs=100)
print(model.evaluate(X_test, y_test))
model.save("*/bakusyomonadai/bakusyo_model.h5")
 このように実行してくれました。
例えば、「'のび太','しずか','スネ夫','ジャイアン'」の4人で学習したいときは
このように実行してくれました。
例えば、「'のび太','しずか','スネ夫','ジャイアン'」の4人で学習したいときは
y_train = np_utils.to_categorical(y_train, 4)
# 正解ラベルの形式を変換
y_test = np_utils.to_categorical(y_test, 4)
model.add(Dense(4))
この部分を変更したら動くようになると思います!!
6、学習したモデルを使って画像を判別
from keras.models import load_model
import numpy as np
from keras.preprocessing.image import img_to_array, load_img
jpg_name = '*/hirate/000002.jpg'
my_model='*/bakusyomondai/bakusyo_model.h5'
model=load_model(my_model)
img_path = (jpg_name)
img = img_to_array(load_img(img_path, target_size=(50,50)))
img_nad = img_to_array(img)/255
img_nad = img_nad[None, ...]
label=['ota','TANAKA']
pred = model.predict(img_nad, batch_size=1, verbose=0)
score = np.max(pred)
pred_label = label[np.argmax(pred[0])]
print('name:',pred_label)
print('score:',score)
今回は違うファイルにある欅坂の平手さんを入れた時にどう判別するのかを見てみました。

99.9%の確率で太田さんだと認識しました笑
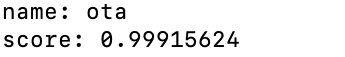
ちなみに、、
本物の田中さんで判別すると

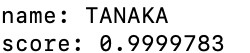
ちゃんと判別してくれます!!!
今回はディープラーニングを用いた画像認識の1連の流れをまとめてみました。
初学者でもできるように、なるべく途中も省きません出来した。
(自分が苦労したのもありますが笑)
皆さんの好きな俳優やキャラクターでもできると思うのでよかったら是非!!