本記事は日本オラクルが運営する下記Meetupで発表予定の内容になります。発表までに今後、内容は予告なく変更される可能性があることをあらかじめご了承ください。
はじめに
AIの活用が広がるなかで「AI Ready Data」というキーワードが注目を集めています。これはAIが即座に活用できるように整えられたデータのこと意味し、単に「整形され、きれいに整ったデータ」というだけではなくアクセスのしやすさ、データ構造の統一、意味づけ、セキュリティやガバナンスまで含めてAIにとって「今すぐ使える状態」 にあることを意味します。
これまで大規模言語モデル(LLM)の登場を契機にRAG(Retrieval-Augmented Generation)やAIエージェントなど、生成AIを活用したアプリケーション開発が注目を集め、技術的関心の焦点も次々と移り変わってきました。そうした中で改めてAIの価値と性能を左右する根幹は「データ」にあるという原点に立ち返る動きが強まりつつあり、「AI Ready Data」という概念が新たに注目を集めているのだと思います。
そのようなAI Ready Dataを実現するためには主に以下のような条件を満たす環境が理想的とされており、これらを満たさない限りどれほど多くのデータがあっても、それは 「AIにとって未整備な素材」にすぎないということになります。
- 異なる種類のデータ(構造化・非構造化・半構造化)を統合的に扱えること
- 意味のあるデータモデルで管理されており、コンテキストを保持していること
- AIやユーザーが簡単にアクセス・クエリできるインターフェースがあること
- 信頼できるセキュリティ・ガバナンスが確保されていること
ただ、これらの要件を満足するために様々なデータストアを導入してしまうと運用工数が大幅に増加してしまうことは言うまでもありません。願わくば単一のデータストアで上述した全ての要件をカバーしたいものです。

そんな願いを叶えるべく、本記事ではOracle Databaseを用いて様々なデータモデルを、AIアプリから利用できるという点にフォーカスして、その様子を簡単なサンプルでご紹介します。
サンプル実装の概要
生成AIアプリといっても様々な実装がありますが、今回はOracle DatabaseのMCPを使って、NL2SQL(※1) やAgentic RAG(※2) を想定し、自然言語による様々なデータモデルの分析をOracleデータベースという単一のデータストアで実行するというシナリオで検証してみたいと思います。
※1 NL2SQL:入力プロンプトをSQLに変換し、データベースにクエリを実行する処理
※2 Agentic RAG:エージェントが動的にデータベースの検索・推論を繰り返しながら情報を収集・統合し、精度の高い回答を生成するRAGの手法

利用するサービスとしては下記の通り。
-
Oracle Database
様々なデータモデルを統合するデータストアとしてOracle Databaseを利用します。今回はOracle DatabaseのクラウドサービスであるAutonomous Databaseを利用しています。 -
Claude Desktop
チャットボットツールとしてClaude Desktopを利用します。 -
Oracle DatabaseのMCP
Oracle Database純正のMCPを利用します。入力プロンプトをSQLに変換し、Oracleデータベースに対して実行するためのモジュールです。
MCPって何?という方はこちらの記事をご参照ください。Claude Desktopのセットアップ手順も記載しています。
Oracle Database用のMCPのセットアップ手順はこちら。
以降は、上述の構成で下記にリストした様々なデータモデルのサンプルデータを片っ端からデータベースに突っ込んで、Claude Desktopから自然言語で簡単な分析をしてみます。
- グラフデータ(プロパティ・グラフ)
- 時系列データ
- 空間データ(Spatial)
- ドキュメントデータ(JSON)
- ドキュメントデータ(XML)
- テキストデータ(全文検索)
- カラム型データ
- キー・バリュー型データ
グラフデータ(プロパティ・グラフ)
グラフデータ(プロパティ・グラフ)は「点(ノード)」と「線(エッジ)」で情報を表し、それぞれに名前や属性(プロパティ)を定義するようなデータモデルです。人や物の関係性やつながりを表現する例として、SNSの友達関係などの複雑な繋がりの分析に向いています。ユースケースとしては以下のようなものがあります。
| ユースケース | 取得するデータの例 |
|---|---|
| ソーシャルネットワークの友人関係分析 | ユーザーID、友人関係のエッジ情報、関係の強さや頻度などの属性 |
| 商品のおすすめレコメンデーション | 商品ID、購入履歴のエッジ(誰が何を買ったか)、商品の属性(価格、カテゴリなど) |
| ネットワークの影響力分析 | ノード(ユーザーや組織)、エッジ(影響力の方向や強さ)、活動履歴 |
| IT資産管理と依存関係の可視化 | サーバーやアプリケーションのノード、依存関係のエッジ、バージョン情報や稼働状況などの属性 |
| 詐欺検出(不正取引のパターン検出) | 取引ノード、取引間のリンク(送金経路)、異常度やリスクスコアの属性 |
サンプルスキーマの作成
下記サンプルスキーマは「銀行口座間の取引」を表すグラフデータをイメージしています。口座間の送金経路の分析を目的としたシステムで、口座間の送金履歴を管理、循環送金などの不正送金の検出するようなシナリオです。銀行口座をノードとし、口座間の送金情報をエッジとしたサンプルスキーマです。
-- ノード用のテーブル
CREATE TABLE bank_account (
acc_id NUMBER
);
-- エッジ用のテーブル
CREATE TABLE bank_transaction (
acc_id_src NUMBER,
acc_id_dst NUMBER,
txn_id NUMBER,
amount NUMBER
);
-- サンプルデータを入れる
INSERT INTO bank_account VALUES (1);
INSERT INTO bank_account VALUES (2);
INSERT INTO bank_account VALUES (3);
INSERT INTO bank_account VALUES (4);
INSERT INTO bank_account VALUES (5);
INSERT INTO bank_transaction VALUES (1, 2, 101, 800);
INSERT INTO bank_transaction VALUES (2, 3, 102, 700);
INSERT INTO bank_transaction VALUES (3, 4, 103, 600);
INSERT INTO bank_transaction VALUES (4, 5, 104, 500);
INSERT INTO bank_transaction VALUES (5, 1, 105, 400);
-- ノード用のテーブルに主キーを追加
ALTER TABLE bank_account
ADD CONSTRAINT pk_bank_account PRIMARY KEY (acc_id);
-- エッジ用のテーブルに主キーを追加
ALTER TABLE bank_transaction
ADD CONSTRAINT pk_bank_transaction PRIMARY KEY (txn_id);
作成されたスキーマは下記の通り。
bank_account 表
- acc_id : 口座の一意識別番号(口座ID)
bank_transaction表
- acc_id_src : 送金元の口座ID
- acc_id_dst : 送金先の口座ID
- txn_id : 取引ごとに割り当てられた一意の取引ID
- amount : 送金された金額
SQL> select * from bank_account;
ACC_ID
_________
1
2
3
4
5
SQL> select * from bank_transaction;
ACC_ID_SRC ACC_ID_DST TXN_ID AMOUNT
_____________ _____________ _________ _________
1 2 101 800
2 3 102 700
3 4 103 600
4 5 104 500
5 1 105 400
SQL>
この2つのリレーショナル表から、プロパティグラフのビュー(bank_graph_view)を作成します。
SQL> CREATE PROPERTY GRAPH bank_graph_view
2 VERTEX TABLES (
3 bank_account
4 KEY (acc_id)
5 LABEL account
6 PROPERTIES (acc_id)
7 )
8 EDGE TABLES (
9 bank_transaction
10 KEY (txn_id)
11 SOURCE KEY (acc_id_src) REFERENCES bank_account (acc_id)
12 DESTINATION KEY (acc_id_dst) REFERENCES bank_account (acc_id)
13 LABEL transfer
14 PROPERTIES (txn_id, amount)
15* );
Property GRAPH created.
下記の通り、作成したグラフのビューが確認できます。
SQL> select * from user_property_graphs;
GRAPH_NAME GRAPH_MODE ALLOWS_MIXED_TYPES INMEMORY
__________________ _____________ _____________________ ___________
BANK_GRAPH_VIEW TRUSTED NO NO
SQL>
自然言語でクエリしてみる
以下のように、口座の送金ルートをクエリするためのプロンプトを入力してみます。
入力プロンプト:「口座IDが1の顧客が送金した取引を探し、その送金先の口座IDと送金額を取得してください。」

うまく動作していることがわかります。
因みに、この入力プロンプトは下記のSQLに変換されてOracle DBの中で実行されており、その結果から最終的な応答テキストを生成しているのが上記の画面になります。
SELECT /* LLM in use is claude-sonnet-4 */
dst_id,
amount
FROM GRAPH_TABLE(
BANK_GRAPH_VIEW
MATCH (src)-[txn]->(dst)
WHERE src.acc_id = 1
COLUMNS (dst.acc_id AS dst_id, txn.amount AS amount)
)
時系列データ
時系列データとは、「時間もしくは順序に沿って記録されたデータ」のことです。大抵の場合、時間もしくは順序のデータが記録された列があり、その時間・順序に対応した各要素の値が記録されているようなデータモデルとなります。たとえば、工場の設備には沢山のセンサーが設置されており、そのセンサーの値を毎秒で計測した値を時系列データとして保存し、稼働確認や故障の予兆検知システムの構築などに利用します。その他下記のようなユースケースがあります。
| ユースケース | 取得するデータの例 |
|---|---|
| 設備の稼働確認や故障の予兆検知 | センサーデータ、設備の温度・振動データ |
| 投資判断や予測モデルの学習、リアルタイム取引 | 株価や為替レート、暗号資産の価格変動 |
| 不正利用の検出やユーザー行動の分析 | クレジットカードの利用履歴 |
| システム監視や障害予兆の検出 | サーバーのCPU使用率・メモリ使用率 |
| 稼働率の最適化や製造工程の改善 | 製造ラインの稼働状況、生産数・不良率の時間変化 |
| 故障の予知保全や設備の安全性確保 | 設備の温度・振動データ |
サンプルスキーマの作成
下記サンプルスキーマは、設備機器に設置されている複数のセンサーからセンサーID、時刻、温度、湿度などの値を時系列で採取することをイメージしたサンプルデータです。
-- テーブル作成
CREATE TABLE sensor_data (
sensor_id VARCHAR2(20),
measurement_time TIMESTAMP,
temperature NUMBER(5,2),
humidity NUMBER(5,2)
);
-- 複数のセンサーからデータを挿入
BEGIN
FOR s IN 1..3 LOOP
FOR i IN 0..9 LOOP
INSERT INTO sensor_data (
sensor_id, measurement_time, temperature, humidity
) VALUES (
'sensor_' || LPAD(s, 3, '0'),
SYSTIMESTAMP + INTERVAL '1' MINUTE * i,
ROUND(DBMS_RANDOM.VALUE(15 + s, 25 + s), 2),
ROUND(DBMS_RANDOM.VALUE(30 + s*2, 50 + s*2), 2)
);
END LOOP;
END LOOP;
COMMIT;
END;
/
作成したサンプルスキーマは下記のように複数のセンサーから取得されたセンサーデータ(センサーID、時刻、温度、湿度)です。
SQL> select * from sensor_data;
SENSOR_ID MEASUREMENT_TIME TEMPERATURE HUMIDITY
_____________ __________________________________ ______________ ___________
sensor_001 17-JUL-25 07.13.32.087373000 AM 100 10
sensor_001 17-JUL-25 06.40.00.000000000 AM 60 20
sensor_001 17-JUL-25 06.36.55.701527000 AM 28.26 41.96
sensor_001 17-JUL-25 06.37.55.879189000 AM 23.56 46.14
sensor_001 17-JUL-25 06.38.55.879324000 AM 22.86 43.35
sensor_002 17-JUL-25 06.38.31.401878000 AM 24.5 40.31
sensor_002 17-JUL-25 06.39.31.401956000 AM 24.47 46.5
sensor_002 17-JUL-25 06.40.31.402062000 AM 22.94 38.58
sensor_002 17-JUL-25 06.41.31.402147000 AM 24.98 43.86
sensor_002 17-JUL-25 06.42.31.402221000 AM 22 35.68
sensor_002 17-JUL-25 06.43.31.402298000 AM 19.75 48.83
自然言語でクエリしてみる
温度や湿度が基準値から外れているセンサーデータだけを抽出するクエリをイメージして下記のようなプロンプトを入力してみます。
入力プロンプト:「温度が23度未満または27度を超えている、もしくは湿度が45%未満または55%を超えているような、基準から外れたセンサーデータだけを、計測日次の昇順(古い順)に並べて取得してください。」


うまく動作していることがわかります。
因みに、実行されたSQLは下記の通り。
SELECT
SENSOR_ID,
MEASUREMENT_TIME,
TEMPERATURE,
HUMIDITY,
CASE
WHEN TEMPERATURE < 23 THEN '温度低'
WHEN TEMPERATURE > 27 THEN '温度高'
ELSE ''
END AS temp_status,
CASE
WHEN HUMIDITY < 45 THEN '湿度低'
WHEN HUMIDITY > 55 THEN '湿度高'
ELSE ''
END AS humidity_status
FROM SENSOR_DATA
WHERE
(TEMPERATURE < 23 OR TEMPERATURE > 27)
OR (HUMIDITY < 45 OR HUMIDITY > 55)
ORDER BY MEASUREMENT_TIME ASC;
空間データ(Spatial)
空間データ(GIS)は、場所を示す「位置情報(例:緯度・経度)」と、その場所に関する「属性情報(例:地名、用途、人口など)」がセットになったデータモデルです。大抵の場合、地図上で表示・分析できるように整理されています。下記のようなユースケースがあります。
| ユースケース | 取得するデータの例 |
|---|---|
| 災害リスク評価やインフラ整備、洪水シミュレーションの実施 | 地形データ(標高、傾斜など)、災害リスクデータ(浸水想定区域、地震断層など) |
| 都市計画、農地評価、森林管理、環境影響評価 | 土地利用・土地被覆データ |
| 政策立案や人口統計分析、選挙区の設定、災害対応区域の把握 | 行政区画データ |
| 商圏分析、サービス提供の最適化、公共施設配置の検討 | 人口・統計データ(空間的に関連付け) |
| 環境変化の監視、違法伐採の検出、都市拡張のモニタリング | 衛星画像・空中写真 |
| 防災計画、ハザードマップの作成、保険リスクの評価 | 災害リスクデータ(浸水想定区域、地震断層など) |
| 環境監視、規制区域の設定、健康影響評価 | 環境データ(大気汚染、水質など) |
サンプルスキーマの作成
東京の主要スポット(駅や名所)10か所の位置情報を空間データとして格納・検索できるようにしたサンプルデータを作成します。
-- サンプル表を作成する
CREATE TABLE gis_tokyo_locations (
id NUMBER PRIMARY KEY,
name VARCHAR2(100),
location SDO_GEOMETRY
);
-- ポイントデータを挿入
-- 10件の東京の有名スポットを追加
INSERT INTO gis_tokyo_locations VALUES (
1, '東京駅',
SDO_GEOMETRY(2001, 8307, SDO_POINT_TYPE(139.7670, 35.6812, NULL), NULL, NULL)
);
INSERT INTO gis_tokyo_locations VALUES (
2, '新宿駅',
SDO_GEOMETRY(2001, 8307, SDO_POINT_TYPE(139.7006, 35.6896, NULL), NULL, NULL)
);
INSERT INTO gis_tokyo_locations VALUES (
3, '渋谷駅',
SDO_GEOMETRY(2001, 8307, SDO_POINT_TYPE(139.7013, 35.6595, NULL), NULL, NULL)
);
INSERT INTO gis_tokyo_locations VALUES (
4, '池袋駅',
SDO_GEOMETRY(2001, 8307, SDO_POINT_TYPE(139.7101, 35.7295, NULL), NULL, NULL)
);
INSERT INTO gis_tokyo_locations VALUES (
5, '上野駅',
SDO_GEOMETRY(2001, 8307, SDO_POINT_TYPE(139.7770, 35.7138, NULL), NULL, NULL)
);
INSERT INTO gis_tokyo_locations VALUES (
6, '秋葉原駅',
SDO_GEOMETRY(2001, 8307, SDO_POINT_TYPE(139.7730, 35.6987, NULL), NULL, NULL)
);
INSERT INTO gis_tokyo_locations VALUES (
7, '品川駅',
SDO_GEOMETRY(2001, 8307, SDO_POINT_TYPE(139.7388, 35.6285, NULL), NULL, NULL)
);
INSERT INTO gis_tokyo_locations VALUES (
8, '六本木ヒルズ',
SDO_GEOMETRY(2001, 8307, SDO_POINT_TYPE(139.7302, 35.6605, NULL), NULL, NULL)
);
INSERT INTO gis_tokyo_locations VALUES (
9, '東京タワー',
SDO_GEOMETRY(2001, 8307, SDO_POINT_TYPE(139.7454, 35.6586, NULL), NULL, NULL)
);
INSERT INTO gis_tokyo_locations VALUES (
10, '浅草寺',
SDO_GEOMETRY(2001, 8307, SDO_POINT_TYPE(139.7967, 35.7148, NULL), NULL, NULL)
);
-- 空間インデックス作成
CREATE INDEX gis_tokyo_locations_spatial_idx
ON gis_tokyo_locations(location)
INDEXTYPE IS MDSYS.SPATIAL_INDEX;
作成されたサンプルデータは以下のように都内の駅とその位置情報です。
SQL> select * from gis_tokyo_locations;
ID NAME LOCATION
_____ _________ _____________________________
1 東京駅 oracle.sql.STRUCT@3a296107
2 新宿駅 oracle.sql.STRUCT@1f129467
3 渋谷駅 oracle.sql.STRUCT@646cd766
4 池袋駅 oracle.sql.STRUCT@57151b3a
5 上野駅 oracle.sql.STRUCT@26457986
6 秋葉原駅 oracle.sql.STRUCT@2dff7085
7 品川駅 oracle.sql.STRUCT@2faa55bb
8 六本木ヒルズ oracle.sql.STRUCT@501957bf
9 東京タワー oracle.sql.STRUCT@5d1d9d73
10 浅草寺 oracle.sql.STRUCT@b30a50d
10 rows selected.
自然言語でクエリしてみる
指定した緯度・経度の範囲にあるスポットを取得するクエリをイメージし、下記のようなプロンプトを入力します。
入力プロンプト:「東京の中心部(緯度35.66〜35.70、経度139.73〜139.76)にあるスポットを検索してください。」


うまく検出できていることがわかります。
この入力プロンプトにより、内部で実行されているSQLは以下の通りです。
SELECT /* LLM in use is claude-sonnet-4 */
ID,
NAME,
SDO_UTIL.TO_WKTGEOMETRY(LOCATION) AS wkt_geometry,
TO_NUMBER(REGEXP_SUBSTR(
SDO_UTIL.TO_WKTGEOMETRY(LOCATION),
'[0-9]+\\.[0-9]+',
1, 1
)) AS longitude,
TO_NUMBER(REGEXP_SUBSTR(
SDO_UTIL.TO_WKTGEOMETRY(LOCATION),
'[0-9]+\\.[0-9]+',
1, 2
)) AS latitude
FROM
GIS_TOKYO_LOCATIONS
WHERE
TO_NUMBER(REGEXP_SUBSTR(
SDO_UTIL.TO_WKTGEOMETRY(LOCATION),
'[0-9]+\\.[0-9]+',
1, 2
)) BETWEEN 35.66 AND 35.70
AND TO_NUMBER(REGEXP_SUBSTR(
SDO_UTIL.TO_WKTGEOMETRY(LOCATION),
'[0-9]+\\.[0-9]+',
1, 1
)) BETWEEN 139.73 AND 139.76
ORDER BY
ID;
ドキュメントデータ(json)
ドキュメントデータ(JSON)は、キーとバリューのペアで情報を整理したデータ構造です。単純な表構造だけでなく、各要素のネスト(入れ子)構造も表現でき、文章や表、リストなど柔軟に表現可能なデータモデルです。主に下記のようなユースケースで利用されます。
| ユースケース | 取得するデータの例 |
|---|---|
| ユーザー管理やプロフィールのカスタマイズ表示 | ユーザーのプロフィール情報 |
| 商品の一覧表示や検索、詳細表示 | 商品情報(名前、価格、説明、画像URLなど) |
| コンテンツの管理、表示、SEO対策 | 記事やブログの本文、タイトル |
| システム監視や障害対応、トラブルシューティング | ログデータ(操作履歴、エラーメッセージなど) |
| アプリケーションの設定管理やバージョン管理 | 設定情報(アプリの構成、パラメータなど) |
サンプルスキーマの作成
顧客のデモグラフィックデータ(顧客の名前、年齢、メール、住所(都市・郵便番号)、興味・関心(趣味など))をJSON構造で管理し、指定した条件の要素を抽出・分析する用途を想定したサンプルスキーマを作成します。
CREATE TABLE json_customer_data (
id NUMBER GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
customer_info CLOB CONSTRAINT ensure_json CHECK (customer_info IS JSON)
);
INSERT INTO json_customer_data (customer_info) VALUES
('{"name":"山田太郎","age":30,"email":"yamada@example.com","address":{"city":"東京","zip":"100-0001"},"interests":["旅行","音楽"]}');
INSERT INTO json_customer_data (customer_info) VALUES
('{"name":"佐藤花子","age":25,"email":"sato@example.com","address":{"city":"大阪","zip":"530-0001"},"interests":["映画","料理"]}');
INSERT INTO json_customer_data (customer_info) VALUES
('{"name":"鈴木一郎","age":40,"email":"suzuki@example.com","address":{"city":"名古屋","zip":"450-0002"},"interests":["ゴルフ","旅行"]}');
INSERT INTO json_customer_data (customer_info) VALUES
('{"name":"田中美咲","age":22,"email":"tanaka@example.com","address":{"city":"東京","zip":"100-0003"},"interests":["音楽","読書"]}');
INSERT INTO json_customer_data (customer_info) VALUES
('{"name":"高橋誠","age":35,"email":"takahashi@example.com","address":{"city":"福岡","zip":"810-0001"},"interests":["野球","映画"]}');
INSERT INTO json_customer_data (customer_info) VALUES
('{"name":"伊藤陽子","age":28,"email":"ito@example.com","address":{"city":"東京","zip":"100-0004"},"interests":["料理","旅行"]}');
INSERT INTO json_customer_data (customer_info) VALUES
('{"name":"渡辺健","age":33,"email":"watanabe@example.com","address":{"city":"札幌","zip":"060-0001"},"interests":["音楽","野球"]}');
INSERT INTO json_customer_data (customer_info) VALUES
('{"name":"中村沙織","age":27,"email":"nakamura@example.com","address":{"city":"東京","zip":"100-0005"},"interests":["読書","映画"]}');
INSERT INTO json_customer_data (customer_info) VALUES
('{"name":"小林亮","age":31,"email":"kobayashi@example.com","address":{"city":"京都","zip":"600-0001"},"interests":["ゴルフ","音楽"]}');
INSERT INTO json_customer_data (customer_info) VALUES
('{"name":"加藤愛","age":29,"email":"kato@example.com","address":{"city":"東京","zip":"100-0006"},"interests":["旅行","映画"]}');
下記のようなデータが作成されました。
SQL> select * from json_customer_data;
ID CUSTOMER_INFO
_____ ___________________________________________________________________________________
1 {"name":"山田太郎","age":30,"email":"yamada@example.com","address":{"city":"東京","zip
2 {"name":"佐藤花子","age":25,"email":"sato@example.com","address":{"city":"大阪","zip":
3 {"name":"鈴木一郎","age":40,"email":"suzuki@example.com","address":{"city":"名古屋","zi
4 {"name":"田中美咲","age":22,"email":"tanaka@example.com","address":{"city":"東京","zip
5 {"name":"高橋誠","age":35,"email":"takahashi@example.com","address":{"city":"福岡","z
6 {"name":"伊藤陽子","age":28,"email":"ito@example.com","address":{"city":"東京","zip":"
7 {"name":"渡辺健","age":33,"email":"watanabe@example.com","address":{"city":"札幌","zi
8 {"name":"中村沙織","age":27,"email":"nakamura@example.com","address":{"city":"東京","z
9 {"name":"小林亮","age":31,"email":"kobayashi@example.com","address":{"city":"京都","z
10 {"name":"加藤愛","age":29,"email":"kato@example.com","address":{"city":"東京","zip":"
10 rows selected.
自然言語でクエリしてみる
登録されている顧客から、指定の条件でクエリを行うようなプロンプトを入力してみます。
入力プロンプト:「関東在住で趣味が映画の方は誰ですか?」

ちゃんと動作していることが分かります。
この入力プロンプトから、内部で実行されたSQLは以下の通りです。
SELECT /* LLM in use is claude-sonnet-4 */
id,
JSON_VALUE(customer_info, '$.name') AS name,
JSON_VALUE(customer_info, '$.age') AS age,
JSON_VALUE(customer_info, '$.address.city') AS city,
JSON_QUERY(customer_info, '$.interests') AS interests
FROM json_customer_data
WHERE JSON_VALUE(customer_info, '$.address.city') IN (
'東京', '横浜', '千葉', '大宮', 'さいたま', '川崎', '船橋', '柏', '市川', '松戸',
'宇都宮', '前橋', '高崎', '水戸', 'つくば'
)
AND JSON_EXISTS(customer_info, '$.interests[*]?(@ == "映画")')
ORDER BY id;
ドキュメントデータ(XML)
XMLは、階層構造でデータを表現するマークアップ形式のデータモデルです。要素(タグ)、属性、テキストから成り、親子関係でデータ構造を定義します。異種システム間のデータ交換に適しており、下記のようなユースケースで利用されます。
| ユースケース | 取得するデータの例 |
|---|---|
| ECサイトや在庫管理システムにおける商品情報の共有・連携 | 製品カタログ情報(商品名、価格、説明など) |
| アプリやシステムにおけるユーザーごとの環境設定の反映 | ユーザー設定(言語、画面レイアウト、通知設定など) |
| 電子出版や学術データベースでのコンテンツ整理・検索・表示 | 書籍や論文の構造化データ(章、節、著者、タイトルなど) |
| 異なる企業間での業務データ交換(EDI)や帳票の自動処理 | ビジネス文書(発注書、請求書、見積書など) |
| 地図システムや災害管理での地理空間情報の活用 | 地理情報(地物、座標、属性など) |
| システム間の連携やWebサービスの仕様定義 | Webサービスの定義(WSDLなど) |
同じドキュメントデータでもJSONはシンプルで読みやすく、データをキーとバリューのペアやリストで表現し、軽量でプログラムの中で扱いやすいデータモデルです。XMLはタグで囲まれた階層構造で、属性も使えて柔軟ですが、やや冗長で人間が読むには少し複雑です。
XMLは構造が厳密で、文書の意味や構成をしっかり定義できる場面に強く、業務間連携、標準仕様、検証・拡張性が重要な場合はJSONよりXMLが選ばれるケースが多いように思います。
サンプルスキーマの作成
ECサイトで顧客の注文履歴をイメージしたデータをXML形式で表したサンプルデータを作成します。
-- テーブル作成
CREATE TABLE xml_order_data (
id NUMBER GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
order_doc XMLTYPE
);
-- データ挿入
-- 注文 1
INSERT INTO xml_order_data (order_doc) VALUES (XMLTYPE('
<Order>
<OrderID>5001</OrderID>
<OrderDate>2025-07-18</OrderDate>
<CustomerName>田中 一郎</CustomerName>
<Items>
<Item>
<ProductName>ノートパソコン</ProductName>
<Quantity>1</Quantity>
<Price>120000</Price>
</Item>
</Items>
</Order>'));
-- 注文 2
INSERT INTO xml_order_data (order_doc) VALUES (XMLTYPE('
<Order>
<OrderID>5002</OrderID>
<OrderDate>2025-07-19</OrderDate>
<CustomerName>佐藤 花子</CustomerName>
<Items>
<Item>
<ProductName>スマートフォン</ProductName>
<Quantity>1</Quantity>
<Price>80000</Price>
</Item>
<Item>
<ProductName>ケース</ProductName>
<Quantity>1</Quantity>
<Price>2000</Price>
</Item>
</Items>
</Order>'));
-- 注文 3
INSERT INTO xml_order_data (order_doc) VALUES (XMLTYPE('
<Order>
<OrderID>5003</OrderID>
<OrderDate>2025-07-20</OrderDate>
<CustomerName>鈴木 次郎</CustomerName>
<Items>
<Item>
<ProductName>イヤホン</ProductName>
<Quantity>2</Quantity>
<Price>3500</Price>
</Item>
</Items>
</Order>'));
-- 注文 4
INSERT INTO xml_order_data (order_doc) VALUES (XMLTYPE('
<Order>
<OrderID>5004</OrderID>
<OrderDate>2025-07-21</OrderDate>
<CustomerName>山本 真理</CustomerName>
<Items>
<Item>
<ProductName>プリンター</ProductName>
<Quantity>1</Quantity>
<Price>20000</Price>
</Item>
</Items>
</Order>'));
-- 注文 5
INSERT INTO xml_order_data (order_doc) VALUES (XMLTYPE('
<Order>
<OrderID>5005</OrderID>
<OrderDate>2025-07-22</OrderDate>
<CustomerName>伊藤 健</CustomerName>
<Items>
<Item>
<ProductName>キーボード</ProductName>
<Quantity>1</Quantity>
<Price>5000</Price>
</Item>
<Item>
<ProductName>マウスパッド</ProductName>
<Quantity>1</Quantity>
<Price>1500</Price>
</Item>
</Items>
</Order>'));
作成されたデータは以下の通り。
SQL> select * from xml_order_data;
ID ORDER_DOC
_____ ___________________________________________
1 <Order>
<OrderID>5001</OrderID>
<OrderDate>2025-07-18</OrderDate>
<CustomerName>田中 一郎</CustomerName>
<Items>
<Item>
<ProductName>ノートパソコン</ProductName>
<Quantity>1</Quantity>
<Price>120000</Price>
</Item>
</Items>
</Order>
2 <Order>
<OrderID>5002</OrderID>
<OrderDate>2025-07-19</OrderDate>
<CustomerName>佐藤 花子</CustomerName>
<Items>
<Item>
<ProductName>スマートフォン</ProductName>
<Quantity>1</Quantity>
<Price>80000</Price>
</Item>
<Item>
<ProductName>ケース</ProductName>
<Quantity>1</Quantity>
<Price>2000</Price>
</Item>
</Items>
</Order>
・・・
・・・
自然言語でクエリしてみる
オーダー履歴を検索するクエリをイメージしたプロンプトを入力します。
入力プロンプト:「誰がいつパソコンをオーダーしましたか?」
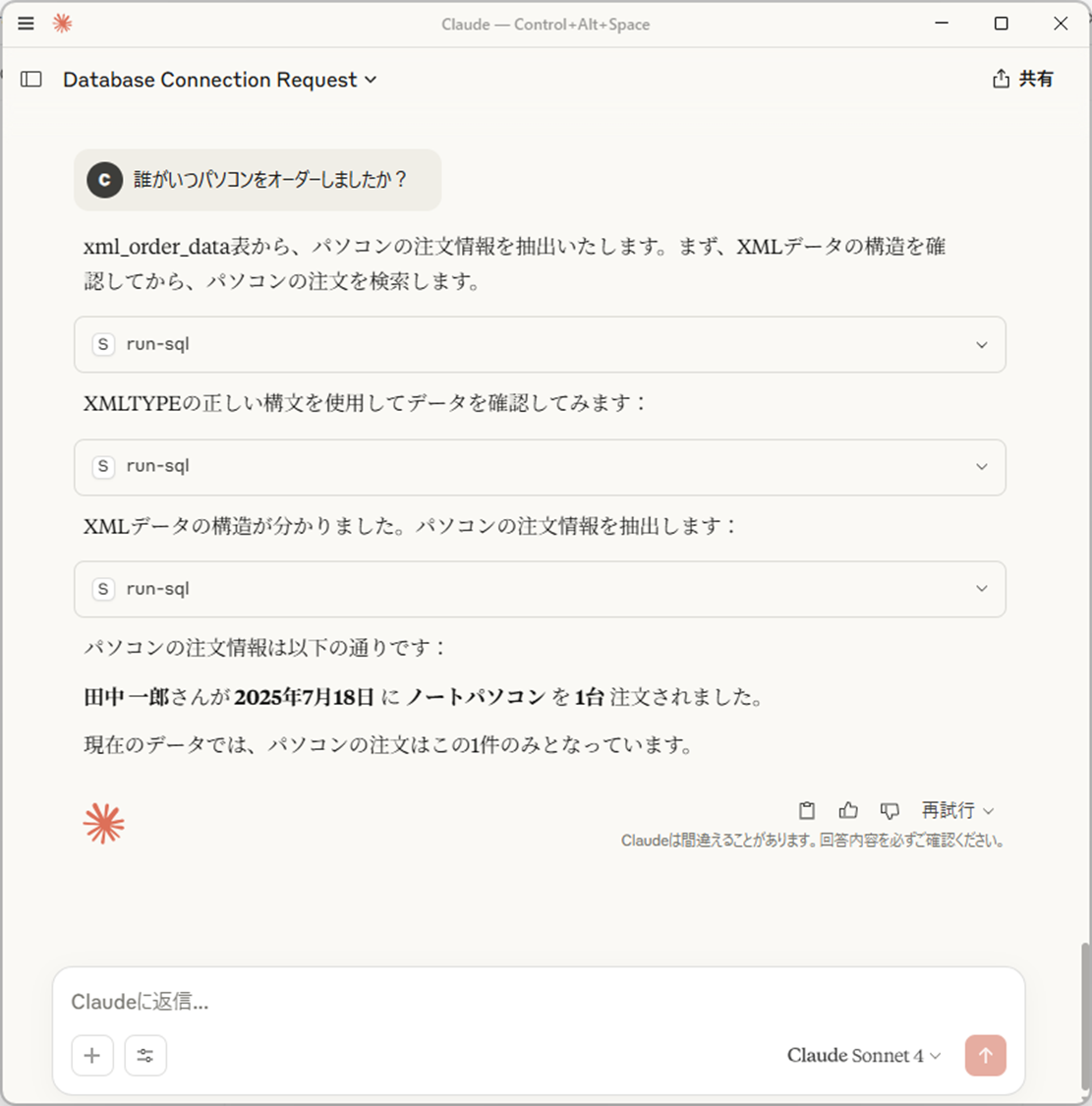
うまく動作していることがわかります。
入力プロンプトから内部的に実行されたSQLは以下の通りです。
SELECT
id,
XMLCast(
XMLQuery('/Order/CustomerName/text()'
PASSING order_doc
RETURNING CONTENT
) AS VARCHAR2(100)
) AS customer_name,
XMLCast(
XMLQuery('/Order/OrderDate/text()'
PASSING order_doc
RETURNING CONTENT
) AS VARCHAR2(20)
) AS order_date,
XMLCast(
XMLQuery('/Order/Items/Item/ProductName/text()'
PASSING order_doc
RETURNING CONTENT
) AS VARCHAR2(100)
) AS product_name,
XMLCast(
XMLQuery('/Order/Items/Item/Quantity/text()'
PASSING order_doc
RETURNING CONTENT
) AS VARCHAR2(10)
) AS quantity
FROM
xml_order_data
WHERE
XMLExists(
'/Order/Items/Item[contains(ProductName, "パソコン")]'
PASSING order_doc
)
ORDER BY
XMLCast(
XMLQuery('/Order/OrderDate/text()'
PASSING order_doc
RETURNING CONTENT
) AS DATE
);
テキストデータ(全文検索)
文書など自然言語の長い文字列ををそのままテキストデータとして保持します。指定のキーワードやフレーズを含むかどうかを効率的に検索できるように構造化されたデータモデルです。下記のようなユースケースで利用されます。
| ユースケース | 取得するデータの例 |
|---|---|
| 商品の評判や顧客ニーズの把握 | 商品レビュー内の特定キーワードやフレーズ |
| トレンド把握や関連情報の抽出 | ニュース記事中の人物名、出来事、地名などの記述 |
| 類似質問への迅速な対応 | FAQやサポート記事内の質問文や回答文 |
| 世論分析やブランド評価 | SNS投稿やブログ記事に含まれる感情表現やユーザーの意見 |
| 契約書や法的文書のリスク分析・内容確認の自動化 | 法律文書・契約書中の特定条項や法的用語 |
| 医療情報の検索やエビデンスの収集 | 医学論文・研究資料中の病名、治療法、薬剤名などの記述 |
| ナレッジ共有や社内業務の効率化 | 社内文書・報告書中のプロジェクト名、進捗状況、課題などの記述 |
サンプルスキーマの作成
以下のようなテキストデータから全文検索を行うためのサンプルスキーマを作成します。
-- 全文検索テーブルの作成
CREATE TABLE documents (
doc_id NUMBER PRIMARY KEY,
doc_title VARCHAR2(100),
doc_content CLOB
);
-- サンプルデータ挿入
INSERT INTO documents VALUES (1, 'Oracleの紹介', 'Oracleデータベースは高性能なリレーショナルDBMSです。');
INSERT INTO documents VALUES (2, '全文検索とは', '全文検索はテキストの中からキーワードを高速に検索する技術です。');
INSERT INTO documents VALUES (3, '機械学習入門', '機械学習は人工知能の一分野で、データから学習します。');
INSERT INTO documents VALUES (4, 'クラウドコンピューティング', 'クラウドコンピューティングはインターネット経由でのリソース提供モデルです。');
INSERT INTO documents VALUES (5, 'データベース設計', '効率的なデータベース設計はパフォーマンスと保守性を向上させます。');
COMMIT;
-- 日本語用レキサーの作成
BEGIN
CTX_DDL.CREATE_PREFERENCE('japanese_lexer', 'JAPANESE_LEXER');
CTX_DDL.SET_ATTRIBUTE('japanese_lexer', 'INDEX_JAPANESE_NUMERIC', 'TRUE');
END;
/
-- 日本語全文検索用インデックスの作成
CREATE INDEX documents_content_idx ON documents(doc_content)
INDEXTYPE IS CTXSYS.CONTEXT
PARAMETERS('LEXER japanese_lexer');
作成されたデータとしては以下の通り。
SQL> select * from documents;
DOC_ID DOC_TITLE DOC_CONTENT
_________ ________________ ________________________________________
1 Oracleの紹介 Oracleデータベースは高性能なリレーショナルDBMSです。
2 全文検索とは 全文検索はテキストの中からキーワードを高速に検索する技術です。
3 機械学習入門 機械学習は人工知能の一分野で、データから学習します。
4 クラウドコンピューティング クラウドコンピューティングはインターネット経由でのリソース提供モデルです。
5 データベース設計 効率的なデータベース設計はパフォーマンスと保守性を向上させます。
SQL>
自然言語でクエリしてみる
「データ」というキーワードが入っているテキストを検索するプロンプトを入力してみます。
入力プロンプト:「「データ」というキーワードが入っているエントリを検索してください。」

うまく動作していることがわかります。
入力されたプロンプトから、内部的に実行されたSQLとしては下記の通りです。
SELECT
doc_id,
doc_title,
doc_content
FROM documents
WHERE doc_title LIKE '%データ%'
OR doc_content LIKE '%データ%'
ORDER BY doc_id;
カラム型データ
データを列単位で格納するデータモデルです。特定の列だけを効率よく読み込めるため、集計や分析処理に高速です。データ圧縮率も高く、DWHや分析基盤でよく使われます。(行型に比べて更新処理は不得意です。)主に以下のようなユースケースで利用されます。
| ユースケース | 取得するデータの例 |
|---|---|
| 売上の傾向を分析し、経営判断に活用する | 売上金額の月別推移 |
| 人気商品の把握や在庫戦略の見直しを行う | 商品カテゴリごとの販売数 |
| 地域ごとのマーケティング戦略を最適化する | 地域ごとの顧客数 |
| 購入傾向を把握し、ターゲット顧客に応じた販促を行う | 年齢層別の購入傾向 |
| Webサイトの利用状況を分析し、改善施策を検討する | サイト訪問者数の推移 |
サンプルスキーマの作成
ECサイトなどで、商品の販売履歴が記録されているような、サンプルスキーマを作成します。
-- カラム型ストア
CREATE TABLE columnar_sales_data (
sale_id NUMBER PRIMARY KEY,
product VARCHAR2(50),
amount NUMBER,
sale_date DATE
)
INMEMORY; -- ★ カラム型でメモリに格納
-- サンプルデータ
INSERT INTO columnar_sales_data VALUES (1, 'ノートパソコン', 120000, DATE '2023-01-01');
INSERT INTO columnar_sales_data VALUES (2, 'プリンター', 30000, DATE '2023-01-03');
INSERT INTO columnar_sales_data VALUES (3, 'ルーター', 15000, DATE '2023-01-05');
INSERT INTO columnar_sales_data VALUES (4, 'モニター', 40000, DATE '2023-01-10');
INSERT INTO columnar_sales_data VALUES (5, 'キーボード', 5000, DATE '2023-01-12');
COMMIT;
作成されたデータは下記の通り。
SQL> select * from columnar_sales_data;
SALE_ID PRODUCT AMOUNT SALE_DATE
__________ __________ _________ ____________
1 ノートパソコン 120000 01-JAN-23
2 プリンター 30000 03-JAN-23
3 ルーター 15000 05-JAN-23
4 モニター 40000 10-JAN-23
5 キーボード 5000 12-JAN-23
SQL>
自然言語でクエリしてみる
DWHなどでよく実行されるソート処理をイメージしたプロンプトを入力してみます。
入力プロンプト:「金額の大きい順にソートしてください。」

うまく動作していることがわかります。
この入力プロンプトにより内部で実行されているSQLは下記の通り。
SELECT /* LLM in use is claude-sonnet-4 */
sale_id,
product,
amount,
sale_date
FROM columnar_sales_data
ORDER BY amount DESC;
キー・バリュー型データ
「キー(名前)」と「バリュー(値)」のペアで情報を管理するシンプルなデータモデルです。辞書や連想配列のように、キーを使って、指定のキーに対応する値を高速に検索できます。下記のようなユースケースがあります。
| 取得するデータの例 | 取得の目的 |
|---|---|
| ユーザーID とその設定情報 | ユーザーごとのカスタマイズ設定を高速に取得するため |
| 商品ID と在庫数 | 商品の在庫管理を効率よく行うため |
| セッションID とログイン状態 | 各ユーザーのセッションをリアルタイムで管理するため |
| 言語コードと対応する翻訳文字列 | 多言語対応のUIを瞬時に切り替えるため |
| 商品カテゴリとその説明文 | カテゴリ情報を簡単に参照・表示するため |
| アプリ設定キーとその値(例: max_users) | 設定値を柔軟に変更・管理できるようにするため |
サンプルスキーマの作成
ECサイトなどで、ユーザーがボタンをクリックした際のクリックストリームの履歴情報をイメージしたサンプルスキーマを作成します。
CREATE TABLE kv_user_click_events (
event_id VARCHAR2(50),
user_id VARCHAR2(50),
event_time TIMESTAMP,
attr_key VARCHAR2(100),
attr_value VARCHAR2(100),
PRIMARY KEY (event_id, attr_key)
);
-- 1回目のクリックイベント
INSERT INTO kv_user_click_events VALUES ('evt_001', 'user_123', SYSTIMESTAMP, 'page', 'product_detail');
INSERT INTO kv_user_click_events VALUES ('evt_001', 'user_123', SYSTIMESTAMP, 'product_id', 'SKU123');
INSERT INTO kv_user_click_events VALUES ('evt_001', 'user_123', SYSTIMESTAMP, 'button', 'add_to_cart');
INSERT INTO kv_user_click_events VALUES ('evt_001', 'user_123', SYSTIMESTAMP, 'campaign', 'SUMMER2025');
-- 2回目のクリックイベント
INSERT INTO kv_user_click_events VALUES ('evt_002', 'user_456', SYSTIMESTAMP, 'page', 'home');
INSERT INTO kv_user_click_events VALUES ('evt_002', 'user_456', SYSTIMESTAMP, 'section', 'banner');
INSERT INTO kv_user_click_events VALUES ('evt_002', 'user_456', SYSTIMESTAMP, 'browser', 'Chrome');
自然言語でクエリしてみる
特定ののボタンをクリックしたユーザーをクエリするようなプロンプトを入力してみます。
入力プロンプト:「「add_to_cart」ボタンをクリックしたユーザーは誰ですか?」

うまく検出できていることが分かります。
この入力プロンプトにより、内部的に実行されたSQLは以下の通り。
SELECT /* LLM in use is claude-sonnet-4 */
DISTINCT user_id,
event_time
FROM kv_user_click_events
WHERE attr_key = 'button'
AND attr_value = 'add_to_cart'
AND user_id IS NOT NULL
ORDER BY user_id, event_time;
さいごに
一つ一つは非常にシンプルなデータを使いましたが、あらゆるデータモデルが単一のデータベースに統合でき、生成AIのアプリケーションから利用できる様子がお判りいただけたのではないでしょうか。
Oracleデータベースの場合、このデータベースひとつに、ビジネスシーンで利用される殆ど全てのデータモデルを統合し生成AIアプリケーションから利用できます。
また、データモデルだけでなく、OLTPワークロードやDWH処理、両者を組み合わせたハイブリッドな処理に加え、BIのアドホッククエリや機械学習ワークロードにも対応可能です。
まさにAI Ready Data時代に最適なデータストアの一つと言えるのではないでしょうか。