はじめに
Microsoftが提供するVSCode向けのPostgreSQL拡張機能を試してみました。
本記事では、私が個人的に注目している機能の一つである「エージェントモード」を中心に、使い方や使用感をまとめています。
なお、記事公開時点でのバージョンは1.8.0のパブリックプレビュー版であり、エージェントモードの機能面からも使用環境は慎重に検討してください。
何ができるのか
この拡張機能では、以下のようなことができます。
- GUI上でのテーブル、スキーマ、カラムなどの確認
- スキーマやテーブル構造の可視化
- SQLクエリの作成と実行
- GitHub Copilot Chat を使用した自然言語でのデータベース操作 ⭐️
- Docker経由でPostgreSQLコンテナを簡単に作成 ⭐️
※⭐️は今回実際に使用した機能です。
事前準備
PostgreSQL拡張機能をインストール
VSCodeの拡張機能マーケットプレイスでms-ossdata.vscode-pgsqlと検索し、インストールします。
PostgreSQLで検索すると同名の別拡張機能も表示されるため、識別子であるms-ossdata.vscode-pgsqlでの検索を推奨
Copilotとの統合機能を有効化
エージェントモードを利用するためには、VSCodeの設定から有効化する必要があります。
デフォルトでは、Copilotの統合機能は無効になっています。
有効にするには、VSCodeの設定画面を開き、pgsql copilotと検索します。その後、Pgsql > Copilot : Enable のチェックボックスをオンにします。

PostgreSQLコンテナの作成
この拡張機能には、ローカル環境のDockerコンテナ上にPostgreSQLコンテナを簡単に作成できる機能が用意されています。今回は、この方法で作成したコンテナを利用してエージェントモードを試してみます。
なお、利用する前にDockerをインストールし、起動しておく必要があります。
拡張機能のウィンドウから、画像の矢印をクリックして画面の指示に従って進めます。
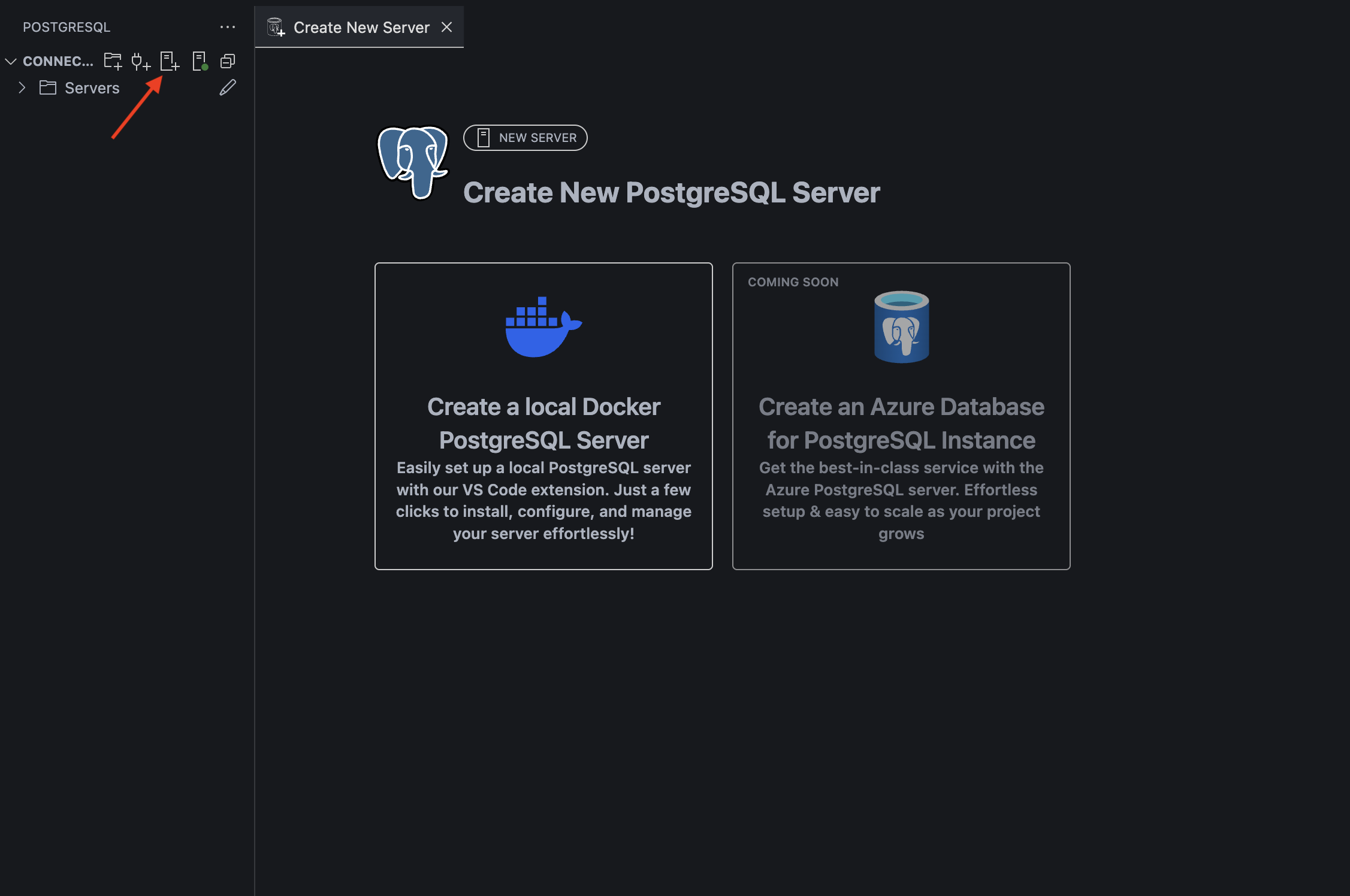
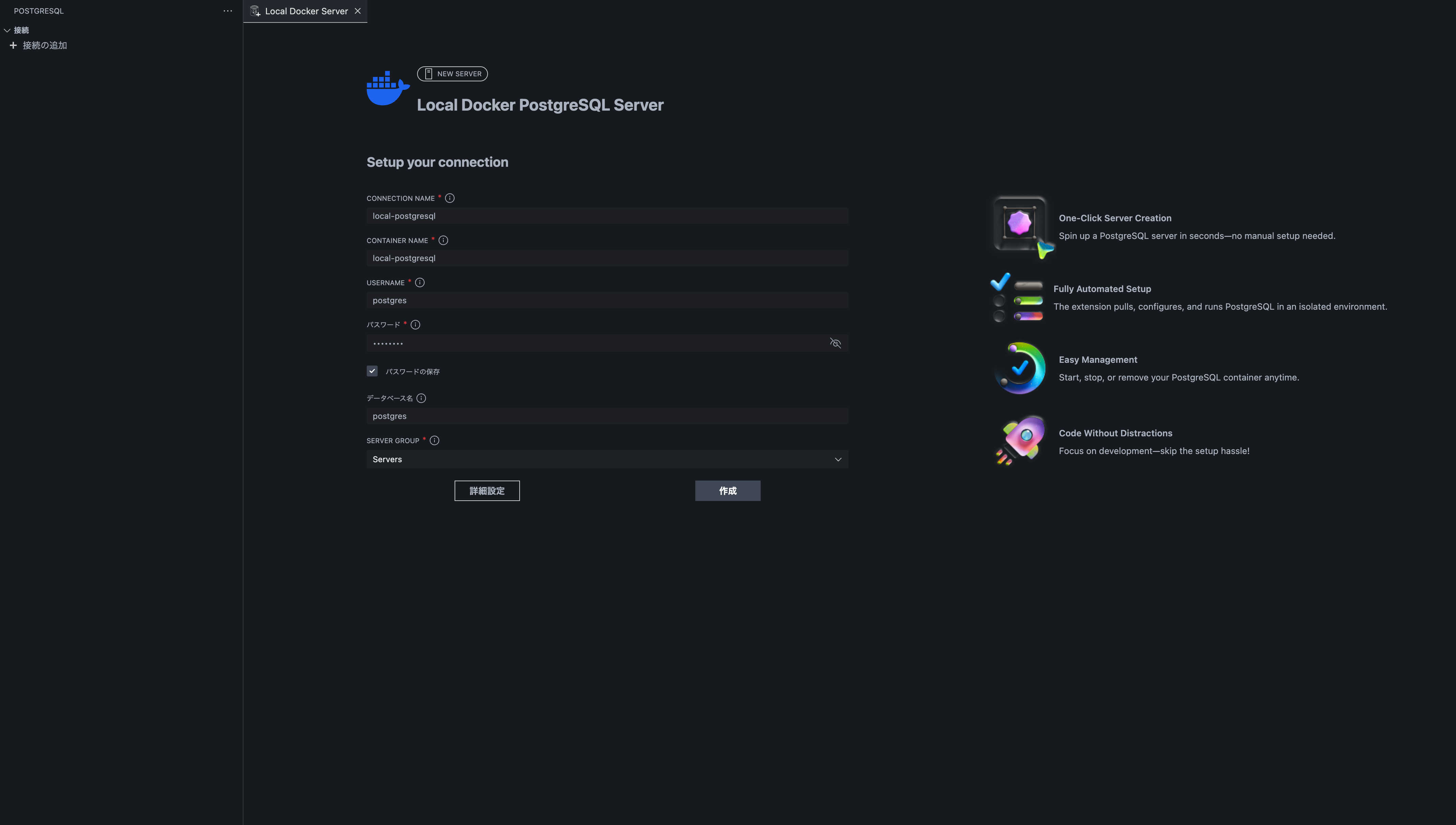
途中で、サーバーのセットアップ画面が表示されるので、各項目を入力し「作成」をクリックすると、コンテナが作成されて起動します。
また、詳細設定からはポート番号やコンテナイメージのバージョンを指定することも可能です。
エージェントモード
エージェントモードとは?
GitHub Copilot Chat の「Agent Mode」で@pgsqlを利用すると、データベースの操作を自然言語で実行できます。
@pgsqlエージェントは、接続からスクリプトの生成・実行までを自律的に進めますが、最終的な操作にはユーザーの確認が必要となる設計になっています。
※この機能を利用するには、VSCodeでGitHub Copilot Chatが利用可能である必要があります。
運用環境での利用は慎重に行ってください。生成されたSQLは必ず事前に確認し、安全な環境でテストしてから実行するようにしてください。
GitHub Copilot Chatを開く
拡張機能のウィンドウから対象のデータベースを左クリックし、Chat with the databaseを選択します。
すると、必要に応じて次の操作が求められるので手順に沿って進めます。
- 対象データベースへの接続確認
- 対象データベースのパスワード入力
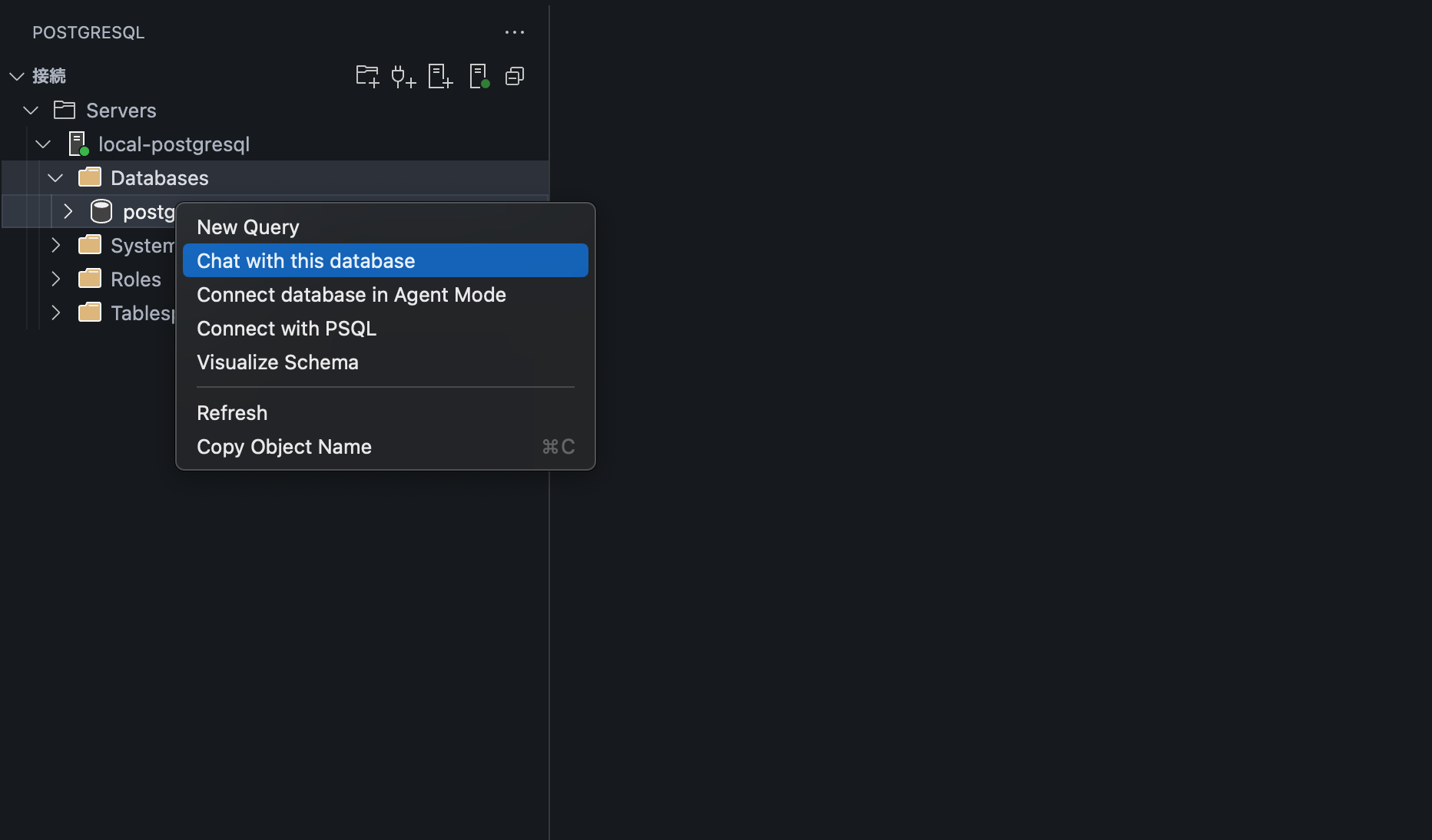
続いて、表示されたチャットウィンドウで「Agent Mode」に切り替えます。

筆者の環境では、Connect database in Agent Modeでの接続がうまくいかなかったため、チャットウィンドウから直接「Agent Mode」に切り替えました。
テーブル作成を指示してみる
今回は某SNSを模倣したテーブルを作成してみます。
チャットから下記プロンプトを投げます。
@pgsql
以下のMermaid記法で書かれたER図を元にテーブルを作成してください。
また、user_relationshipsテーブルにはfollower_idとfollowee_idの複合ユニークキーを設定してください。
```mermaid
erDiagram
users ||--o{ posts : ""
users ||--o{ comments: ""
posts ||--o{ comments: ""
users }o--o{ user_relationships: ""
users {
bigint id PK
string name "NOT NULL"
timestamp created_at "NOT NULL"
timestamp updated_at "NOT NULL"
}
posts {
bigint id PK
bigint user_id FK "NOT NULL"
text content "NOT NULL"
timestamp created_at "NOT NULL"
timestamp updated_at "NOT NULL"
}
comments {
bigint id PK
bigint post_id FK "NOT NULL"
bigint user_id FK "NOT NULL"
text content "NOT NULL"
timestamp created_at "NOT NULL"
timestamp updated_at "NOT NULL"
}
user_relationships {
bigint id PK
bigint follower_id FK "NOT NULL"
bigint followee_id FK "NOT NULL"
timestamp created_at "NOT NULL"
timestamp updated_at "NOT NULL"
}
```
すると、実行されるSQLクエリが表示され実行確認を求められます。内容を確認し、問題がなければ承認して実行を依頼します。
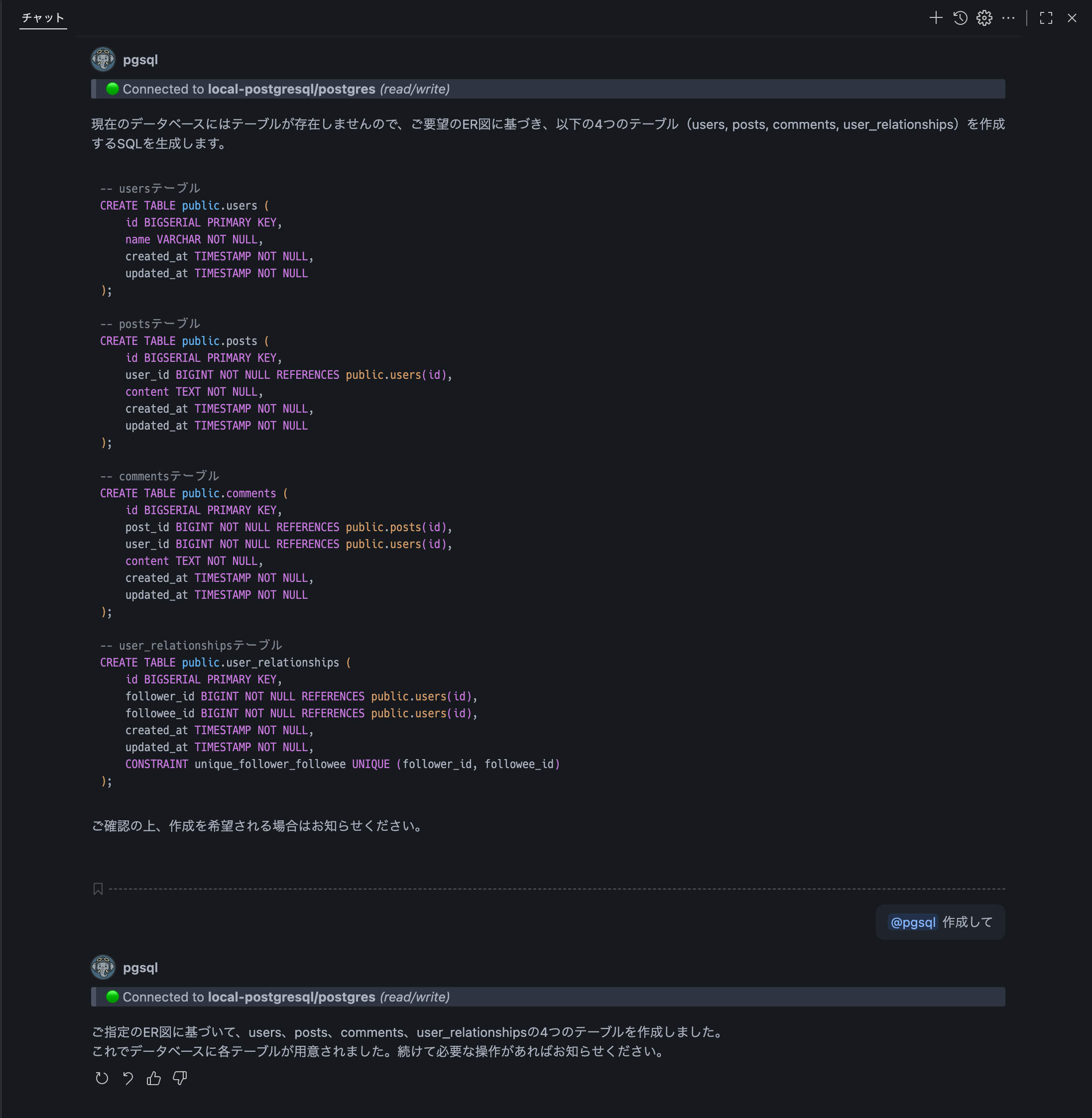
実行されたSQLクエリ
-- usersテーブル
CREATE TABLE public.users (
id BIGSERIAL PRIMARY KEY,
name VARCHAR NOT NULL,
created_at TIMESTAMP NOT NULL,
updated_at TIMESTAMP NOT NULL
);
-- postsテーブル
CREATE TABLE public.posts (
id BIGSERIAL PRIMARY KEY,
user_id BIGINT NOT NULL REFERENCES public.users(id),
content TEXT NOT NULL,
created_at TIMESTAMP NOT NULL,
updated_at TIMESTAMP NOT NULL
);
-- commentsテーブル
CREATE TABLE public.comments (
id BIGSERIAL PRIMARY KEY,
post_id BIGINT NOT NULL REFERENCES public.posts(id),
user_id BIGINT NOT NULL REFERENCES public.users(id),
content TEXT NOT NULL,
created_at TIMESTAMP NOT NULL,
updated_at TIMESTAMP NOT NULL
);
-- user_relationshipsテーブル
CREATE TABLE public.user_relationships (
id BIGSERIAL PRIMARY KEY,
follower_id BIGINT NOT NULL REFERENCES public.users(id),
followee_id BIGINT NOT NULL REFERENCES public.users(id),
created_at TIMESTAMP NOT NULL,
updated_at TIMESTAMP NOT NULL,
CONSTRAINT unique_follower_followee UNIQUE (follower_id, followee_id)
);
データの作成を指示してみる
チャットから、作成されたテーブルに対してデータ作成を指示してみます。
まずは、ユーザーデータを 1000 件作成するよう指示します。実行されるSQLクエリの確認が求められるので、内容を確認して承認します。
@pgsql
usersテーブルに以下条件のデータを1000件作成してください。
${連番}には、1から1000を順番に割り当ててください。
- name: テスト太郎 ${連番}
- created_at: 現在日時
- updated_at: 現在日時
左ウィンドウからテーブルを選択し、左クリックで「Select Top 1000」を実行すると、レコードの一覧を確認できます。
問題なく作成できていそうです。
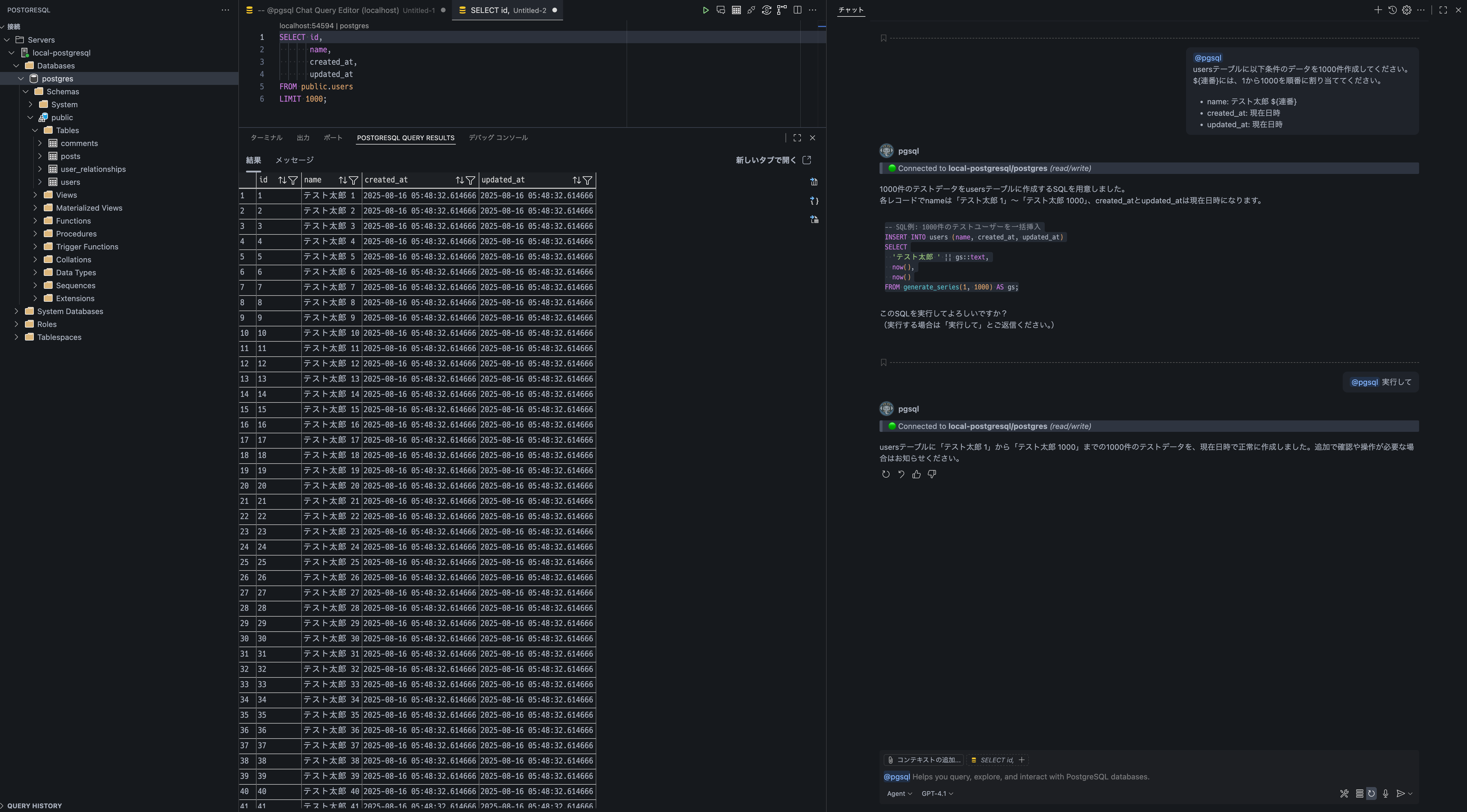
実行されたSQLクエリ
-- SQL例: 1000件のテストユーザーを一括挿入
INSERT INTO users (name, created_at, updated_at)
SELECT
'テスト太郎 ' || gs::text,
now(),
now()
FROM generate_series(1, 1000) AS gs;
続いて、user_relationshipsテーブルに対して、ユニーク制約に違反しないようにデータを作成してみます。
@pgsql
以下のルールに従ってuser_relationshipsテーブルにテストデータを作成してください。
- 作成件数は1000件
- follower_idとfollowee_idの複合ユニーク制約に違反しないデータであること
- follower_idとfollowee_idに同じ値が入らないこと
- follower_idとfollowee_idの組み合わせをランダムにしたい
提案されたSQLクエリが少し複雑だったため解説をお願いし、理解した上で実行を依頼しました。
こちらも問題なく作成されていました。
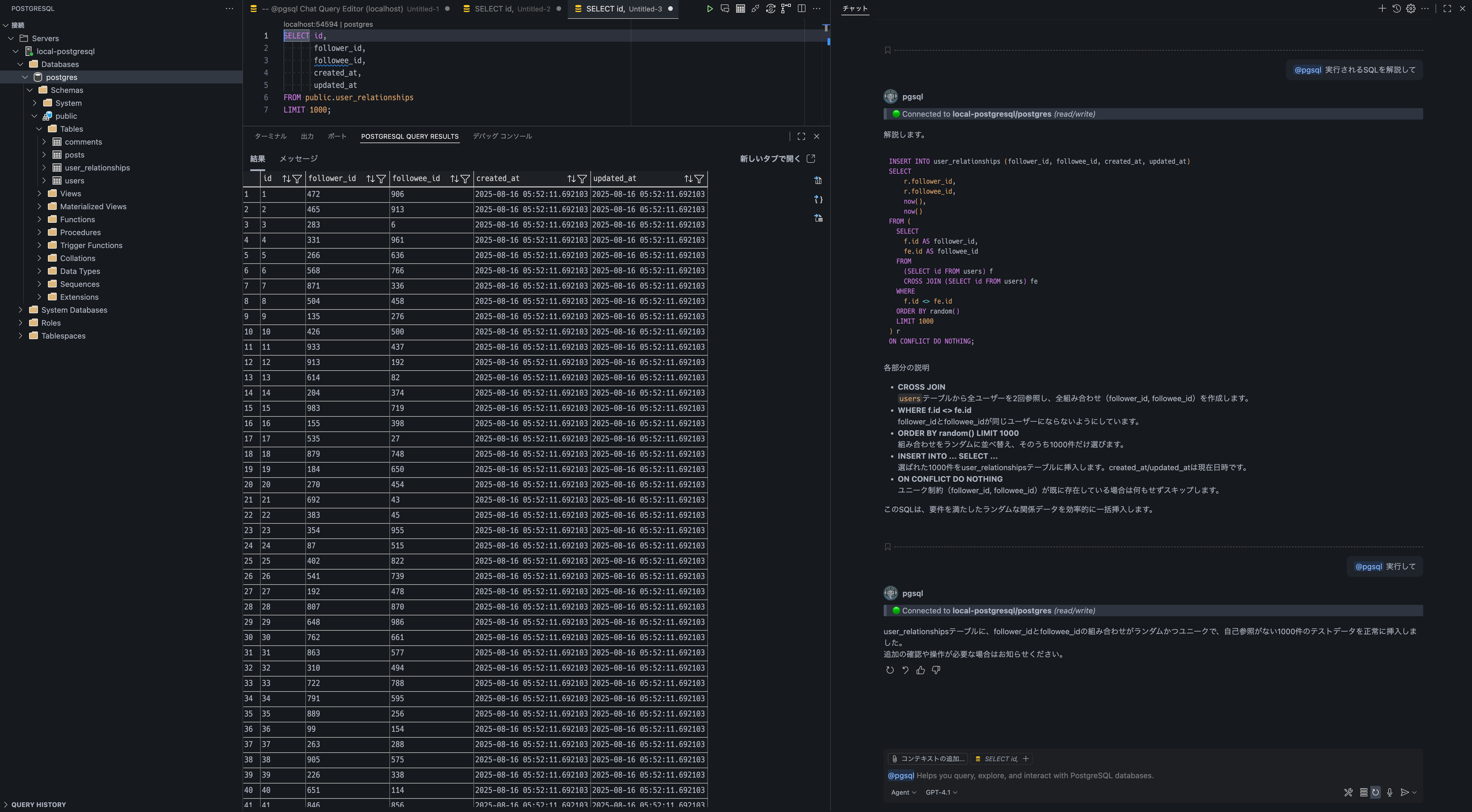
実行されたSQLクエリ
INSERT INTO user_relationships (follower_id, followee_id, created_at, updated_at)
SELECT
r.follower_id,
r.followee_id,
now(),
now()
FROM (
SELECT
f.id AS follower_id,
fe.id AS followee_id
FROM
(SELECT id FROM users) f
CROSS JOIN (SELECT id FROM users) fe
WHERE
f.id <> fe.id
ORDER BY random()
LIMIT 1000
) r
ON CONFLICT DO NOTHING;
最後に
一通りエージェントモードを試してみました。
この拡張機能の最大の特徴は、自然言語でデータベースを操作できる点だと感じました。
Microsoft製であるためCopilotとの親和性が高く、PostgreSQLデータベースのコンテキスト情報にアクセスすることで、スキーマに沿った正確なSQLクエリの実行や分析情報の生成が可能です。この点は、他のツールにはない大きな魅力だと感じました。
個人的に有用だと感じたのはテストデータの作成です。大量のデータを用意したい場面は稀にありますが、その頻度が低いため、いざという時にすぐSQLを書けないことがあります。そういった場合でも、自然言語からテストデータを生成できるのは大きな利点だと思いました。
一方で、GUI上からは外部キー制約やカラムの詳細情報を確認できず、SQLクエリを実行する必要がありました。またパブリックプレビュー段階ということもあってか、一部で不安定な挙動も見られました。これらの点については、今後の改善に期待したいと思います。