この記事は ウェブクルー Advent Calendar 2018の5日目の記事です。
昨日は@wc_omuroさんの「いますぐはじめよう!ユーザーリサーチ!」でした。
今年はオンプレのDockerで動作しているWebアプリやオンプレの少々古いフレームワークをリプレイスして、KubernetesのフルマネージドサービスであるGKEに載せ替える業務をメインにやってきました。
KubernetesのServiceが、どういった仕組みでPodと通信しているのかを正確に把握出来ていない部分があったので、使用した機能を中心にKubernetesのドキュメントを読みつつまとめました。
以下、KubernetesのことをK8sと書きます。
なぜK8sなのかは下記のリンクでご確認ください。。
https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#what-does-kubernetes-mean-k8s
https://medium.com/@rothgar/why-kubernetes-is-abbreviated-k8s-905289405a3c
Serviceとは?
Kubernetesのドキュメントから抜粋
A Kubernetes Service is an abstraction which defines a logical set of Pods and a policy by which to access them - sometimes called a micro-service.
The set of Pods targeted by a Service is (usually) determined by a Label Selector (see below for why you might want a Service without a selector).
K8sのサービスは、論理的なPodのセットとそれと通信するためのポリシーを定義する抽象的なものです。これはマイクロサービスと呼ばれることもあります。
サービスを介して通信する一連のポッドは、通常、ラベル・セレクタによって決定されます。
Serviceの役割
PodはNodeに散らばっているため、それぞれのPodと通信しようとしたら、愚直にIPアドレスを指定して通信することになります。
また、K8sの特性上、NodeのIPアドレスは一定になりません。
突然Podと通信できなくなる可能性があります。
ということは、複数のPod,NodeのIPアドレスをクライアントが意識せずに単一のエンドポイントで通信する方法が必要になります。
上記の事象に対する解決策としてPod,Nodeの存在を抽象化し、Podとの通信に単一のエンドポイントを提供するのがServiceの主な役割になります。
Defining a service - Serviceを定義する
Serviceは以下のように定義します。
apiVersion: v1
kind: Service
metadata:
name: play-app-svc
spec:
selector:
app: play-app-link
ports:
- protocol: TCP
port: 9000
targetPort: 9000
上記のServiceを作成するとServiceとそれに対応するEndpointsが自動で作成されます。
% kubectl get service play-app-svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
play-app-svc ClusterIP 10.47.251.158 <none> 9000/TCP 10m
% kubectl get endpoints play-app-svc NAME ENDPOINTS AGE
play-app-svc <none> 12m
上記の定義でServiceを作成すると、サービスプロキシで使用されるIPアドレス(クラスタIPとも呼ばれます)がServiceに割り当てられ、Serviceとは?に書いたとおりapp:play-app-linkのラベルがつけられたPodを通信先として、Serviceの9000番ポートに来た通信を通信先Podの9000番ポートにマッピングします。
targetPortはデフォルトではportと同じ値になりますが、任意のtargetPortにマッピングすることも出来ます。
サポートしているプロトコルはTCP,UDP,SCTPで、デフォルトではTCPになります。
補足
Note: SCTP support is an alpha feature since Kubernetes 1.12
SCTPはKubernetes 1.12以降のアルファ機能です。
Services without selectors - ラベル・セレクタを使用しないケース
上ではServiceはラベル・セレクタを定義して、Podへの通信を抽象化すると書きましたが、他のバックエンドへの通信を抽象化することもできます。
例えば以下の様なケースがあります。
- productionではクラスタ外のデータベースクラスタを使用したいが、テストではテストでは独自のデータベースを使用する
- Serviceをクラスタ外のServiceに向けたい
- Kubernetesへワークロードを移行中で、一部のバックエンドはKubernetesの外で実行する
ラベル・セレクタを使用しないServiceの定義は以下のようになります。
apiVersion: v1
kind: Service
metadata:
name: play-app-svc-no-selector
spec:
ports:
- protocol: TCP
port: 30050
targetPort: 30050
Serviceは作成されていますが、対応するEndpointsは作成されません。
% kubectl get service play-app-svc-no-selector [19:11:34]
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
play-app-svc-no-selector ClusterIP 10.47.253.105 <none> 30050/TCP 1m
% kubectl get endpoints [19:12:07]
NAME ENDPOINTS AGE
play-app-svc <none> 19m
セレクタ無しのServiceはEndpointsが作成されず、独自のEndpointsを作成できます。
apiVersion: v1
kind: Endpoints
metadata:
name: play-app-svc-no-selector
subsets:
- addresses:
- ip: 10.3.42.250
ports:
- port: 30050
% kubectl get endpoints
NAME ENDPOINTS AGE
play-app-svc <none> 42m
play-app-svc-no-selector 10.3.42.250:30050 1m
上記のようにmetadataのnameを揃えてService, Endpointsを定義することでセレクタなしServiceに来た通信は、対応するEndpointsの定義にしたがって、10.3.42.250:30050にルーティングされます。
Virtual IPs and service proxies - 仮想IPとサービス・プロキシ
K8sはクラスタの全ノードでkube-proxyが動きます。
kube-proxyはExternalNameタイプ以外のService用に仮想IPのフォームが実装されています。
K8s 1.0ではサービスはレイヤ4でプロキシはuserspaceにありました。
K8s 1.1でレイヤ7に対応し、Ingress API(beta)が追加され、iptablesのプロキシも追加されました。
K8s 1.2以降でiptablesによるプロキシがデフォルトの動作モードになりました。
K8s 1.8.0-beta.0では、ipvsのプロキシが追加されました。
userspase
このモードでは、K8sのマスターのkube-proxyがServiceとEndpointsオブジェクトの追加、削除を監視します。
各Serviceに対してローカルノードにランダムに選ばれたポート(プロキシポート)を開きます。
このプロキシポートへの接続はServiceのバックエンドにいるPod(Endpointsによって報告されている)のいずれかにプロキシされます。
使用するバックエンドポッドは、サービスのSessionAffinityに基づいて決定されます。
最後にiptablesをインストールして、ServiceのクラスタIPおよびポートへのトラフィックを収集しバックエンドポッドのプロキシポートにリダイレクトします。
デフォルトではラウンドロビン方式でPodを選択します。
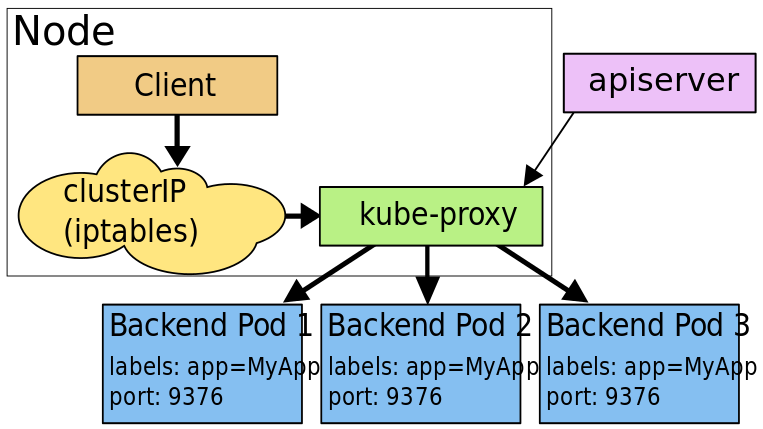
出典:https://kubernetes.io/docs/concepts/services-networking/service/
iptables
このモードでは、K8sはマスターのkube-proxyがServiceとEndpointsオブジェクトの追加、削除を監視します。
各Serviceに対してiptablesのルールを適用し、ServiceのクラスタIP(仮想)とポートへのトラフィックを取得し、トラフィックをServiceのバックエンドセットの1つにリダイレクトします。
各Endpointsに対してPodを選択するiptablesのルールを適用します。
デフォルトでは、バックエンドの選択はランダムに行われます。
iptablesはuserspaceとkernelspaceの間を行き来する必要がないため、userspaceモードのプロキシよりも高速で信頼性が高いはずです。
しかし、userspaceモードのプロキシとは異なる点があり、iptablesモードではService作成時に選択したPodが応答しない場合に自動的に別のPodを選択することができません。
そのため、Podの準備が整っている(readinessProbeのチェックが正常になっている)必要があります。
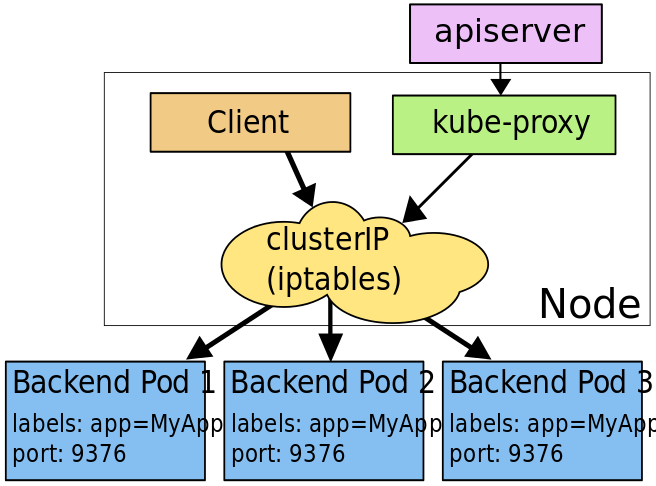
出典:https://kubernetes.io/docs/concepts/services-networking/service/
Ipvs
K8s 1.9のbeta機能です。
K8s 1.11でGAになりましたが、1.11ではデフォルトにはなっていません。
Kubernetes 1.11: In-Cluster Load Balancing and CoreDNS Plugin Graduate to General Availability - Kubernetes
このモードで、kube-proxyはServiceとEndpointsを監視し、netlinkインターフェースを呼び出してIpvsルールを作成、定期的にIpvsルールをService, Endpointsと同期させて、Ipvsのステータスが期待通りになるようにします。
Serviceへの通信はPodの1つにリダイレクトされます。
iptablesと同様にIpvsはnetfilterフック関数に基づいていますが、データ構造にハッシュテーブルを使用し、kernelspaceで動作します。
これは、ipvsがトラフィックの転送をはるかに高速化できることと、プロキシルールを同期するパフォーマンスが大幅に向上することを意味します。
更に、Ipvsは次のような負荷分散のためのアルゴリズムのオプションを多く提供します。
- rr: round-robin ラウンドロビン
- lc: least connection 最小接続
- dh: destination hashing 宛先IPハッシュ
- sh: source hashing ソースIPハッシュ
- sed: shortest expected delay 最短予測遅延
- nq: never queue キューなし
注:ipvsモードは、kube-proxyを実行するノードにIPVSカーネルモジュールがインストールされていることを想定しています。
kube-proxyがIpvsモードで起動するとIpvsモジュールがインストールされているか確認します。インストールされていない場合、iptablesモードで動作します。
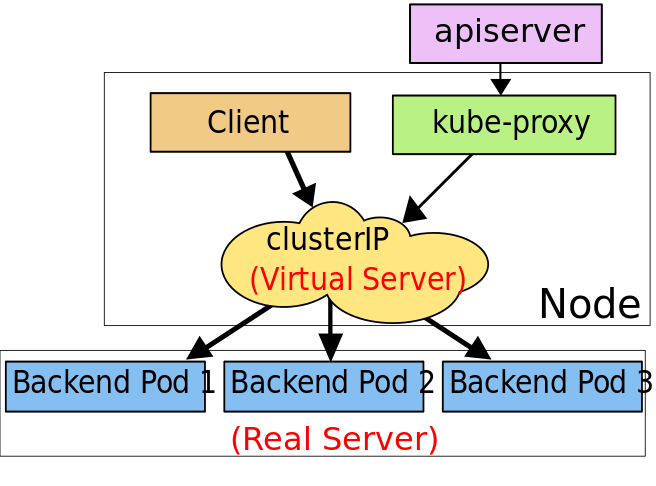
出典:https://kubernetes.io/docs/concepts/services-networking/service/
上記のどのプロキシモデルにおいても、ServiceのIPアドレス:ポートにバインドされた通信はクライアントがK8s, Service, Podについて何も知らなくても適切なバックエンドにプロキシされます。
クライアントIPベースのセッションアフィニティは、service.spec.sessionAffinityを「ClientIP」(デフォルトは「None」)に設定し、
スティッキーセッションのタイムアウトを最大に設定する場合は、service.spec.sessionAffinityConfig.clientIP.timeoutSecondsに設定します。
service.spec.sessionAffinityにクラスタIPを設定している場合、タイムアウトはデフォルトで10800に設定されます。
Choosing your own IP address - 独自IPアドレスの選定
独自のクラスタIPアドレスをServiceの作成要求に含める事ができます。これを行うには.spec.clusterIPを指定します。
例えば、既存のDNSエントリを利用したい場合や、特定のIPアドレス用に設定されていて、再設定が難しいレガシーシステムがある場合に使います。
指定するIPアドレスは有効なIPアドレスで、apiserverで指定されたservice-cluster-ip-rangeCIDR範囲内(デフォルト:10.0.0.0/24)である必要があります。
指定したIPアドレスが無効な場合、apiserverは値が無効であることを示す422 HTTPステータスコードを返します。
Discovering services - サービスのディスカバリ
K8sはServiceを見つける2つのモードをサポートしています。
Environment variables - 環境変数
PodがNode上で実行されると、kubeletがアクティブなServiceに対する環境変数を追加します。
たとえば、TCPポート6379を公開し、クラスタIPアドレス10.0.0.11が割り当てられているサービスredis-masterは、次の環境変数を生成します。
REDIS_MASTER_SERVICE_HOST=10.0.0.11
REDIS_MASTER_SERVICE_PORT=6379
REDIS_MASTER_PORT=tcp://10.0.0.11:6379
REDIS_MASTER_PORT_6379_TCP=tcp://10.0.0.11:6379
REDIS_MASTER_PORT_6379_TCP_PROTO=tcp
REDIS_MASTER_PORT_6379_TCP_PORT=6379
REDIS_MASTER_PORT_6379_TCP_ADDR=10.0.0.11
PodがアクセスするServiceはそのPodよりも前に作成しておく必要があり、そうしないと環境変数が設定されず、Serviceにアクセスできません。
つまり、このモードではServiceを作成する順番を考慮する必要があります。
次のDNSモードではこの制約は存在しません。
DNS
強く推奨されているクラスタアドオンはこちらのモードです。
DNSサーバーはK8s APIでServiceを監視し、新しいServiceを見つけたらそれに対してDNSレコードを作成します。
DNSがクラスタ全体で有効になっている場合、PodはServiceの名前解決を自動的に行うことが出来ます。
たとえば、 my-nsという名前のnamespaceにmy-serviceというServiceがある場合、 my-service.my-nsのDNSレコードが作成されます。 「my-ns」namespaceに存在するPodは、単に「my-service」の名前検索を行うだけで見つけることができます。他のnamespaceに存在するPodは、名前を my-service.my-nsとする必要があります。これらの名前検索の結果はクラスタIPになります。
K8sは、名前付きポート用のDNS SRV(サービス)レコードもサポートしています。 my-service.my-nsServiceにhttpという名前のポートがある場合は、 _http._tcp.my-service.my-nsのDNS SRVクエリを実行して、httpという名前に紐付いたポート番号を取得することができます。
名前付きのポートを用いたServiceの定義は次の通りです。
apiVersion: v1
kind: Service
metadata:
name: play-app-svc
spec:
selector:
app: play-app-link
ports:
- protocol: TCP
port: 9000
name: http
また、K8s DNSサーバーは、ExternalName型のServiceにアクセスする唯一の方法です。詳細については、「DNS Pods and Services」をご覧ください。
Publishing services - service types - 公開サービス サービスタイプ
アプリケーションの一部では、Serviceをクラスタ外に公開したい場合があります。
K8s ServiceTypesでは、必要なサービスの種類を指定できます。
デフォルトはClusterIPになります。
型の値と振る舞いをは次の通りです。
-
ClusterIp
クラスタ内のIPにServiceを公開します。
この値ではServiceはクラスタ内からのみアクセス可能になります。
これがデフォルトのServiceTypeです。 -
NodePort
各ノードのIP上のServiceを静的ポート(NodePort)に公開します。
NodePort ServiceがルーティングするClusterIP Serviceが自動的に作成されます。
<NodeIp>:<NodePort>を要求することで、クラスタ外からNodePort Serviceにアクセスできます。 -
LoadBalancer
クラウドプロバイダのロードバランサを使用して外部にServiceを公開します。
外部ロードバランサがルーティングするNodePort ServiceとClusterIP Serviceが自動的に作成されます -
ExternalName
値を含むCNAMEレコードを返すことにより、ServiceをexternalNameフィールドのコンテンツ(たとえば、foo.bar.example.com)にマッピングします。この場合、どのような種類のプロキシも設定されません。この型を使うには、バージョン1.7以上のkube-dnsが必要です。
Type NodePort
NodePortを設定すると、K8sのマスターは--service-node-port-rangeで指定された範囲(デフォルト:30000-32767)からポートを割り当て、各Nodeはそのポートを開きServiceに追加します。
この時開いたポート番号はServiceの.spec.ports.nodePortに公開されます。
特定のポートを指定したい場合は、.spec.ports.nodePortを設定すると適用されます。
指定しているポートが衝突するとServiceの作成は失敗します。
また、指定するポートは上述の指定された範囲内である必要があります。
こうすることで、独自のロードバランサを設定、K8sのサポートがない環境をServiceにする、1つ以上のNodeのIPを公開することができます。
この型で設定したServiceは、<NodeIP>:spec.ports.nodePortと.spec.clusterIP:spec.ports.portの両方でアクセスできます。
Type LoadBalancer
外部ロードバランサをサポートするクラウドプロバイダでは、LoadBalancerを設定するとService用のロードバランサがプロビジョニングされます。
ロードバランサの作成は非同期で行われ、作成されたロードバランサに関する情報はServiceの.status.loadBalancerに公開されます。
例えば、次の様なymlでプロビジョニングを行います。
kind: Service
apiVersion: v1
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
clusterIP: 10.0.171.239
loadBalancerIP: 78.11.24.19
type: LoadBalancer
status:
loadBalancer:
ingress:
- ip: 146.148.47.155
この型を指定した場合、外部ロードバランサからのトラフィックはPodに送信されますが、クラウドプロバイダに依存する形になります。
また、一部のクラウドプロバイダはloadBalanserIPを指定することで、外部ロードバランサを指定したIPアドレスで作成することができます。
loadBalanserIPが指定されていない場合、エフェメラルなIPアドレスが割り当てられます。
loadBalanserIPをクラウドプロバイダがサポートしていない場合、設定されていても無視されます。
GKEでは、loadBalanserIPはサポートされており、静的IPアドレスを予約してServiceに使用することができます。
以下のチュートリアルに、LoadBalancer型Serviceの作成が含まれています。
静的IPアドレスを使用したドメイン名の設定
Type Externalname
ExcternalNameを設定するとServiceはセレクタではなく、spec.externalNameに指定したDNS名にServiceをマッピングします。
次のServiceでは、prod namespaceのmy-serviceをmy.database.example.comにマッピングします。
kind: Service
apiVersion: v1
metadata:
name: my-service
namespace: prod
spec:
type: ExternalName
externalName: my.database.example.com
参考文献
Services - Kubernetes
Kubernetes 1.11: In-Cluster Load Balancing and CoreDNS Plugin Graduate to General Availability - Kubernetes
what-does-kubernetes-mean-k8s
why-kubernetes-is-abbreviated-k8s
静的IPアドレスを使用したドメイン名の設定
まとめ
GKE, K8sを触り始めたころはブラックボックスの塊のように捉えていましたが、ドキュメントを読みながら使っていくことで、今はブラックボックスのように捉えることは少なくなってきています。
英語力がそこまで高くないためドキュメントを読むのに苦労しますが、だからと言って避けていると「よく分からないけどすごい技術」みたいな認識になってしまい、新しい機能がリリースされた時に把握するのを尻込みしてしまうので、今後もドキュメントを読むようにしてGKE,K8sに置いて行かれないようにしていかなければと思っています。
これからK8sやGKEを触るエンジニアの皆様、最初はブラックボックスの様に思うかも知れませんがドキュメントや先人の方の知見を参照することで、少しずつブラックボックスは無くなっていきますので頑張ってください!
最後に、この記事とこれからの私のアウトプットもそういった方々の助けになればと思います。
明日は、@DotaKobayashiさんです。
よろしくお願いします。