slackのカスタムレスポンスが使いにくい

会社でslackのカスタムレスポンスを使って、簡単なChatbotのようなものが運用されています。これは特定のワードに反応して、既定のメッセージを返す簡単な仕組みです。特に、プログラムを書く必要がないので、簡易的な用途としては十分に動くのですが、 厳密一致しか対応していないという問題があって、
- デモどこ
- デモの資料教えて
- デモの一覧を教えて
と言っても、反応しません。そのため、ちゃんと呪文を厳密に覚えていないと、使えない。という問題点がありました。
そんな中で、最近の生成AIの流れで、RAGという技術があります。これは、とどのつまり、自分たちが用意したドキュメントから曖昧検索を行い、検索にヒットしたドキュメントの内容をLLMに流し込んで回答させる技術です。この曖昧検索の技術を使って、FAQ検索っぽいものが作ってみた。というのがこの記事です。
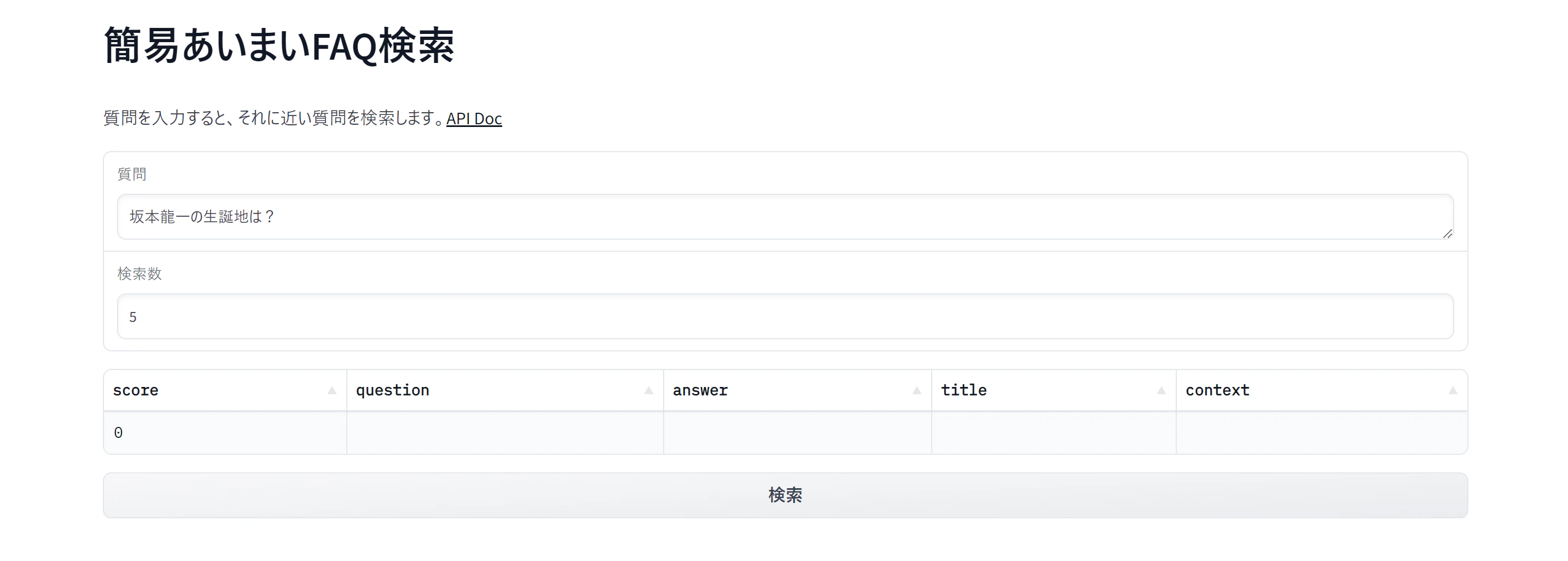
今回作ったものはこちら
サービス画面(無料枠の制約上、最初の画面表示に時間がかかる場合があります)
https://free-similarity-search.onrender.com/
REST API(openapi)
https://free-similarity-search.onrender.com/docs
リポジトリ
https://github.com/kotauchisunsun/free_similarity_search
データはJGLUEのJSQuADを利用しています。大体700件ぐらいのデータが入っています。
技術スタック
- FastAPI
- langchain
- chromaDB
- spacy
- gradio
- rye
APIとしての作成は、個人的に好きなFastAPI。とくにOpenAPIのドキュメントが自動で作られてよい。文書検索部分は飛ぶ鳥を落とす勢いのlangchain。どちらかというとLLM界隈で使われるほうがメジャーなライブラリ。ベクトル検索はchromaDB。文章の埋め込み表現(Embedding)にはspacy。最後に、簡易的なUI作成がgradio。パッケージの管理にはrye。今回、FastAPI以外は全部使ったことがない技術スタックです。
技術的にやったこと。やってみたかったこと。
- renderを使いたい
- ryeをつかってみたい
- ベクトル検索をやってみたい
今回は、GWということで時間があるということで割とモリモリな構成にしています。
renderを使ってみたい
Herokuが無料枠を閉じてしまって幾星霜。個人が無料でWebサービスを構えられるようなPaaSというものがなくなったなぁ。という気持ちでいました。そんななかで、タダの実行環境一覧という記事を見つけました。最近のこういう無料系PaaSの傾向として、
- 静的HTMLサイトをホスティングする系
- netlify
- cloudflare pages
- firebase hosting
- 特定フレームワークに限る系
- Vercel
- Glitch
- cyclic.sh
みたいな形で、自由に書かせてくれなかったり、機能が足りなかったりします(ワガママ)。そんな中で、renderは無料枠で、各種言語(Node.js,PHP,Python,Ruby)が動き、なおかつDockerコンテナも動く。そして、1か月に750時間の無料稼働枠で、512MBのメモリまでくれるので、個人が遊びで動かすには割と十分な性能だったりします。今回は、こいつに入門したい。というのが目標にありました。
ryeをつかってみたい
Pythonは、割と昔からプロジェクト管理のつらい言語でした。(その一端は「pipとpipenvとpoetryの技術的・歴史的背景とその展望」が詳しい)
そもそもライブラリのインストール環境で言えば、昔はexeで配られてたライブラリもあり、easy_installというものがあり、pipが主流になり・・・と思っていたら、ライブラリの環境も、virtualenv,venv,pipenvを私も踏んできました。そのなかで、pyenvなど、Python自体のバージョン管理をする流れもでてきて(Node.jsでいうnやnvm相当)・・・となかなか混迷しています。
ある日、Xを見ていると、
Rye / Ruff / uv でこんなにも Python の体験が変わるんだなという気持ちになってる。そのうち mypy の Rust 版が出てきそうだ。
— V (@voluntas) April 26, 2024
というポストを見て、内心マジか・・・という気持ちでした。最近は、pipenvを使うことが多く、そこまで問題ではなかったのですが、どうも使い心地が悪い。この使い心地の悪さ。というのは、パッケージのインストール速度で、pipenvはこれが非常に遅く、割と問題になっているようです。私もこれは嫌だなぁ。という気持ちがあったので、まぁ触ってみるか・・・という気持ちでryeを導入してみました。
ベクトル検索をやってみたい
その昔、「ChatGPTで執行役員を勝手に遊戯王カードにしてみた」という記事を書きました。これは、StableDiffusionやChatGPTを使って、オリジナルの遊戯王カードを作る。という割と変な試みでした。その時に思ったことは、「トークン数が足りない」ということでした。平たく言うと、ChatGPTへ入力できる文字数に制限があって、その制限が厳しいために推論できない。という話でした。先の例でいうと、まず、既存の遊戯王カードの画像をCLIPを用いて、キャプションを抽出することで、画像を文字情報へ変換しました。この文字情報と、攻撃力や守備力、属性などをChatGPTに複数入力し、学習データとしたうえで、オリジナル遊戯王カードの画像のキャプションを入力することで、攻撃力や守備力を推論させる。ということをしていました。そこで、先ほどのトークン数の問題が発生し、学習データの量が大量には入らず、少ないデータからのカード情報の推論になってしまいました。先の記事は2023年3月の記事で、最近ではトークン数も上昇はしていますが、LLM系に多くのデータをプロンプトとして入れるのは、あまりできない。という印象があります。
という、LLMのトークン数の上限問題や、LLMの学習時期により最新の情報が推論できない。社内情報のようなクローズドな情報源を利用したい。という問題の解決として用いられているのがRAGです。詳しくはリンク先を見てもらえばよいのですが、簡単に説明します。LLMへ読み込ませたい文章を分割し、その文章をEmbeddingという技術を用いて、数値のベクトルデータへ変換します。このベクトルデータをベクトル検索ができるDBへ登録します。これが登録の過程です。実際に、推論させたい時は、入力された文章の内容を、同様にEmbeddingにより、ベクトルデータへ変換し、このベクトルデータと近い情報をDBへ問い合わせて、元の文章を引き当て、その文章を参考データとしてプロンプトに付与し、LLMに回答させる。といった技術です。
これを見たときに、あれ?文章のあいまい検索って簡単にできるんだ?という気持ちになりました。だったら、ちょっと社内で問題になってるあいまい検索的なものを趣味でやってみよう(たぶんLLMの技術の勉強にもなるし)。という気持ちになりました。
ベクトル検索ライブラリの選定
今回、ChromaDBというベクトル検索のDBを利用しました。ここにはいろいろな理由があります。ベクトル検索のライブラリは、langchainのサイトにまとまっていたり、近傍探索のベンチマークのサイトがあるので、それを参考に見つけ出します。この選定にはいろいろ経緯があるのですが、特にポイントとなる点が2点あります。
- 静的ファイルとしてホスティングできる
- ドキュメントがそろっており、使いやすそう。
まず1.の時点で相当少なくなります。これは、自分の気持ちとして、sqliteみたいなやつがいい。と思っていました。いわゆるファイルベースで、最悪、ソースコードと一緒に配置できるタイプのDBだと、ホスティングが楽だなぁ。と思っていました。そういうことを考えたとき、PostgreSQLの上で動く~といった拡張的なライブラリは除外されます。また、ベクトル検索のシステムとして、デーモンが動くタイプのものもホスティングが面倒なので駄目です。なおかつ、SaaSとして提供されているベクトル検索のDBは金がかかりそうなので除外されます。そうすると以外に選択肢がない。という状況になります。これらの条件を満たすライブラリを考えると、大体以下の選択肢になってきます。
faissはlangchainのサンプルでよく見ていたのですが、公式ドキュメントを見に行くとc++の資料しかなく、これは嫌だなぁ。と思いました。もともとのコンセプトの元であるsqliteを考えていた時に、sqlite-vssを見つけていましたが、ドキュメントをそこそこ読んでみると、使い方が煩雑で使いにくそうだな。という印象がありました。そんな中でChromaDBは公式サイトがあり、ドキュメントは少ないながらあり、pythonで実装されている。なおかつ、ファイルベースでも動いていました。また、適当に動かしていると、ファイルベースの挙動だと、内部的にはsqliteを利用しており、じゃあ安心かな。と思って使いはじめました。
で、この「選定にはいろいろな経緯がある」の話になるのですが、もともとlangchainを使って実装する予定はなく、ベクトル検索のライブラリとEmbeddingのライブラリを素で使うつもりでした。そのため、ドキュメントがそろっていることに対して、重要度があったのですが、langchainの各種integrationが素晴らしく作りこまれており、非常に使い勝手が良かったので、今となってはファイルベースだったらなんでもよかったな。という気持ちはあります。そんな、紆余曲折はありましたが、ChromaDBを使いました。
後付けですが、ChromaDBは相当速いようです。ChromaDBのVector IndexはHNSWという方式が使われており、先ほどの ベンチマークサイトでも速度上位のライブラリとして、hnsw(nmslib)が掲げられてるので、おそらく精度もよく、速度も速いと思われます。
render/rye/chromaDBの食い合わせ問題
renderには、大きく2つの実行方式があります。1つは、言語ランタイムを使う場合。もう1つはDockerを使う場合。の2種類です。前者の場合、以下のようにBuild CommandとStart Commandを指定してやることで簡単に動いたりします。(https://docs.render.com/deploy-flask)

で、なんですが、これがryeとの食い合わせが悪い。renderには言語ランタイムで動くコマンドの一覧が公開されていますが、当たり前ですがryeはありません。そのため、手動インストールする必要があります。また、ryeはインストールの最後に、.bashrcに
source "$HOME/.rye/env"
と書け。とでます。そのため、おおむねワンライナーではかけず、シェルスクリプトを書く必要があります。まぁ、これ自身はあんまり問題ではないです。
しかし、大きく問題になったのはchromaDBです。これは、先ほどすこし話したhnsw周りでソースコードのビルドが必要になります。そのため、
$ apt-get install --no-install-recommends -y clang libomp-dev
あたりの処理が必要になります。が。renderが用意している言語ランタイムは母艦のOSもよくわからない。とりあえずaptは動きそうだったけど、権限エラーで動かない。sudoはコマンド自体がない。という形で、追加でライブラリを入れることができません。というわけで、結局、Dockerfileベースのデプロイしかできない。ということになりました。
render/spacy食い合わせ問題
意外かもしれませんが、ここもしんどいです。何かというと、renderのメモリ512MB制約で言語モデルを動かすのがつらい。
まず私はsentence-transformerベースのEmbeddingを見てました。そこのサンプルでは、all-MiniLM-L6-v2というモデルによるサンプルがあり、これで試作をしてみました。まぁ精度が悪い。 それは、当たり前で、all-MiniLM-L6-v2は英語のモデルで日本語に対応していないからです。では、日本語に対応したモデルは?という話になるのですが、これが分からない。 sentence-transformerに公開されているpretrained modelの一覧 を見ても、日本語対応しているかわからない。
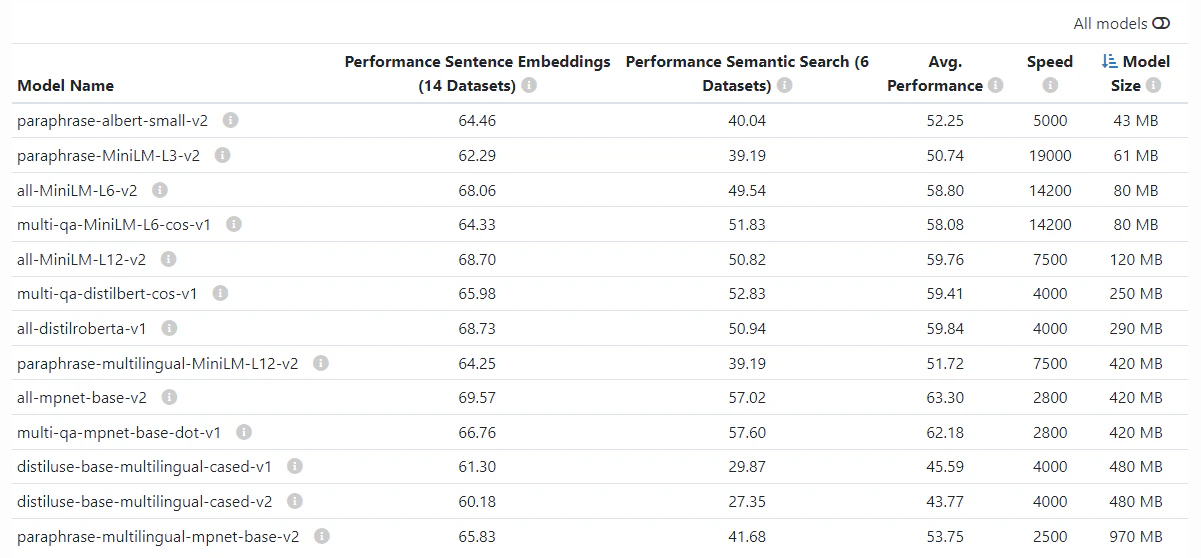
ここで、sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2というモデルがあり、 これは、50以上の言語で学習されているので日本語も正常に動きそうです。が、無駄が多い。 どういうことかというと、renderのメモリ制約が512MBの中で、この言語モデルが420MBあると流石に動かないだろうと思いました。むしろ、日本語だけ学習したモデルが欲しい。で、sentence transformersで日本語を扱えるモデルのまとめ という記事を見つけ、日本語のsentence transformersに関してベンチマークをとってくれているサイトがあります。しかし、ここは逆にモデルのファイルサイズがない・・・ただ、どうもですがこれらのモデルは海外のモデルが多く、日本語は英語以外のその他の言語のおまけ。としてチューニングされてるような雰囲気があります。そのため、モデルがどうしても肥大化しがちであり、512MB制約で動かすのがつらい。という気持ちがありました。
そんなわけで、sentence-transformer周りはあきらめ、langchainのembeddingを見渡すと、spacyというライブラリを見つけました。ここに日本語専用モデルの一覧があって、ja_core_news_mdというモデルが、40MB程度のファイルサイズで公開されています。これを使ってみると、検索精度もよく、メモリに乗りそうだったので、これを採用しました。
rye/langchain/gradioの食い合わせ問題
デモの画面はgradioで作られていますが、gradioを最近使ったことのある方だと違和感のあるデザインだと思います。これは、gradio3系でできています。ふつうは今の最新であるgradio4を使うと思います。なぜ、こんなことが起こっているのか。という話です。
えー、ちゃんと追っていないので、何とも言えないですが私の理解はこういう感じです。
langchain経由で、chromadbを触っており、このlangchainに対応したchromaDBが少し古い。このchromaDBがpydantic1系にしか対応していない(chromaDBの最新はpydantic2に対応している)。しかし、gradio4はpydantic2にしか対応していない。したがって、gradio3とメジャーダウングレードするしかなかった。で、gradioのドキュメントはgradio4ベースなので、地味に文法が違ってめんどくさいなどの問題はあった・・・
で、ここは実は解決のしようがあったのではないかなーという気持ちがありました。それは、ryeがバージョンがあれば、パッケージの依存解決をなんとかしてくれないかなーという気持ちがあって、この辺をえいや。としてくれるコマンドを期待したんですが、どうやらなさそうでした。この辺は、「そもそもライブラリの依存関係上、解決できない問題」なのか、「問題として解決できるがryeが解決できないのか」という2つの次元がありますが、さすがにこの依存関係を手動で見に行って、バージョン1個1個試して、解決方法があるということを調べる。というかったるいことはしたくなかったので、早々に諦めました。
まとめ
自分としては結構攻めたなぁ。という技術スタックでした。初めてやることが多かった。renderも気になってたし、ryeも気になってた。ベクトル検索も気になってたし、Embeddingも気になっていた。だから、全部組み込んでみましたが、まぁ大変。やるほうは、やれるだけのことをやるんですが、文章に起こしたときに、なにとなにが問題になって、普通の解決策だと駄目で、一歩引いた策を講じる必要がある。というのを1つ1つ詳細に書いてく必要があり、それが非常に大変。というか、他人が見て理解できんのか・・・みたいな問題がある。
先進的技術はそのもの自体華々しく見えるのだが、それを実サービスに乗せるとなると相当に大変。なおかつ、それを無料インフラに乗せるとなると、制約が厳しくなって、さらに大変。だから攻めすぎ注意。といいながらも、なかなか、ぎりぎりのラインでサービスは形になったんじゃないかな。と思うクオリティでした。作業の裏ではphi-3とかもやってたので、こいつものせたるかーみたいな気持ちはあったんですが、さすがに7Bとかのパラメーター数はファイルサイズがGB超えるんで無理だなー感が強いです。試してないけど。思うに、ここまで苦労するんだったら、OpenAIのAPIの課金するほうが、まぁ楽だねー感は強いです。あくまで、この記事は一切お金をかけない縛りプレイの範囲内の話です。
LLMでのRAGがーという話がありつつも、割と本質的に欲しいのって、自分でホスティングできる曖昧文書検索じゃね?と思ってて、それはそれで作れるんだっけ?という気持ちがあったので、そこが自分の中で解消したので良かったです。1問1答なら問題なくて、おそらくLLMに解決してほしいのは、六法全書読んで、こういうサービスって違法?合法?みたいなのが聞けるところなんだろうなー感がありました。そういう風に1問1答に落とせないパターンには有用なんだけども、その出力が本当に正しいのかを判断するのが難しいわけですが・・・
ぶっちゃけrenderは相当いいなーという気持ちがあります。楽。非常に。いままでHeroku難民だった身からするとだいぶ良いです。いわゆるChatBotの母艦程度なら雑に使えそうです。やっぱり結局はストレージの問題にはなるんですが、それは過去もそうなので、そこは変わらないかな。なので、ストレージのアップデートが頻繁じゃないこういうFAQはこれでいいかな。感がありました。