以前の記事でKeras遅いなとぼやいたら「MXNetをバックエンドにすると速いよ」と指摘してくださった方がいたので、どうにかしてGoogle Colabで使う方法を模索してみました。Colabで使う情報が全くなかったので書きます。
Keras+MXNetは速い
KerasのMXNetのバックエンドは、Amazonにより開発が進められています。
AWSLabsが公開しているベンチマークによると、ResNet50を使ったCIFAR10の分類で、TensorFlowのバックエンドよりもMXNetのバックエンドのほうが1.5倍~4倍程度速いとの結果が出ています。
| Instance Type | GPUs | Batch Size | Keras-MXNet (img/sec) | Keras-TensorFlow (img/sec) |
|---|---|---|---|---|
| C5.18X Large | 0 | 32 | 87 | 59 |
| P3.8X Large | 1 | 32 | 831 | 509 |
| P3.8X Large | 4 | 128 | 1783 | 699 |
| P3.16X Large | 8 | 256 | 1680 | 435 |
出典:https://github.com/awslabs/keras-apache-mxnet/tree/master/benchmark
本当かよという感じはじますが、特にGPUの数が増えると効果が絶大ですね。ぜひこれを体験してみましょう。
インストール
2018年8月現在、Keras公式ではMXNetのバックエンドは対応していないので、フォークされたKeras(keras-mxnet)を導入します。
Google ColabのGPUアクセラレーターをオンにしたら、まずはGPU対応のMXNetをインストールします。
!pip install mxnet-cu80
CUDA9.0対応のMXNetをインストールすると「import keras」したときに「libcudart.so.9.0: cannot open shared object file: No such file or directory」と怒られてしまいました。CUDA8.0のMXNetをインストールすると特に問題ありませんでした1。楽な解決方法あったら募集中です。
次にkeras-mxnetも同様にインストールします。
!pip install keras-mxnet
Channels_firstへの切り替え
CNNで使う場合はここだけ注意が必要です。MXNetはchannels_firstなので、例えばCIFARだったら(50000, 32, 32, 3)ではなく(50000, 3, 32, 32)となります。TensorFlowがバックエンドのと同じようにchannel_lastで書いていると怒られると思います。
keras.jsonの編集
デフォルトをchannels_lastからchannels_firstに切り替えます。Jupyter Notebookからもできます。以下のコードを実行してください。
import os
keras_json='{\n "floatx": "float32",\n "epsilon": 1e-07,\n "backend": "mxnet",\n "image_data_format": "channels_first"\n}'
keras_json_dir=os.environ['HOME']+"/.keras"
if not os.path.exists(keras_json_dir): os.mkdir(keras_json_dir)
with open(keras_json_dir+"/keras.json", "w") as fp:
fp.write(keras_json)
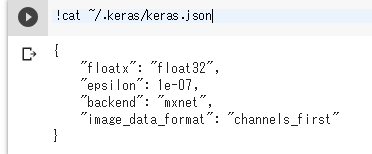
本当に編集できているかは「!cat ~/.keras/keras.json」を実行すると確認できます。
MXNetがバックエンドになっているか確認
「import keras」を実行して「Using MXNet Backend」と表示されればOKです。

モデルを作る際の注意点
channels_firstなので**Conv2dやPoolingといった層を追加する際は、「data_format="channels_first"」**と明示的に宣言してあげる必要があります。また、**BatchNormalizationやMerge(Add, Concatenate等)を行う際は、「axis=1」**とチャンネルの軸を教えてあげる必要があります。
エラー文でも出てきますが、channels_lastで作ると激重になるので注意が必要です。
MNISTサンプル
簡単なサンプルコードとしてAlexNetもどきを作ってみました。データはMNISTです。
from keras.layers import Conv2D, Activation, MaxPooling2D, BatchNormalization, Input, Flatten, Dense
from keras.models import Model
from keras.optimizers import Adam
from keras.datasets import mnist
from keras.utils import to_categorical
import numpy as np
# Data
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = np.expand_dims(X_train, axis=1)
X_test = np.expand_dims(X_test, axis=1)
X_train = X_train / 255.0
X_test = X_test / 255.0
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
def create_conv_layers(input, nb_filters, kernel_size):
x = Conv2D(nb_filters, kernel_size=kernel_size, padding="same", data_format="channels_first")(input)
x = BatchNormalization(axis=1)(x)
x = Activation("relu")(x)
return x
# Model
input = Input(shape=(1, 28, 28))
x = create_conv_layers(input, 256, 5)
x = create_conv_layers(x, 256, 5)
x = MaxPooling2D((2,2), data_format="channels_first")(x)
x = create_conv_layers(x, 384, 3)
x = create_conv_layers(x, 384, 3)
x = create_conv_layers(x, 384, 3)
x = Flatten()(x)
x = Dense(10, activation="softmax")(x)
model = Model(input, x)
model.compile(Adam(lr=0.0001), loss="categorical_crossentropy", metrics=["acc"])
model.fit(X_train, y_train, batch_size=128, epochs=20, validation_data=(X_test, y_test))
結果は次のようになりました。
Train on 60000 samples, validate on 10000 samples
Epoch 1/10
/usr/local/lib/python3.6/dist-packages/mxnet/module/bucketing_module.py:408: UserWarning: Optimizer created manually outside Module but rescale_grad is not normalized to 1.0/batch_size/num_workers (1.0 vs. 0.0078125). Is this intended?
force_init=force_init)
60000/60000 [==============================] - 138s 2ms/step - loss: 0.1339 - acc: 0.9615 - val_loss: 0.1315 - val_acc: 0.9663
Epoch 2/10
60000/60000 [==============================] - 138s 2ms/step - loss: 0.0500 - acc: 0.9850 - val_loss: 0.0981 - val_acc: 0.9710
Epoch 3/10
60000/60000 [==============================] - 138s 2ms/step - loss: 0.0400 - acc: 0.9885 - val_loss: 0.0460 - val_acc: 0.9874
Epoch 4/10
60000/60000 [==============================] - 138s 2ms/step - loss: 0.0353 - acc: 0.9899 - val_loss: 0.0811 - val_acc: 0.9776
Epoch 5/10
60000/60000 [==============================] - 138s 2ms/step - loss: 0.0310 - acc: 0.9911 - val_loss: 0.0599 - val_acc: 0.9872
Epoch 6/10
60000/60000 [==============================] - 138s 2ms/step - loss: 0.0251 - acc: 0.9926 - val_loss: 0.0598 - val_acc: 0.9864
Epoch 7/10
60000/60000 [==============================] - 138s 2ms/step - loss: 0.0309 - acc: 0.9915 - val_loss: 0.0698 - val_acc: 0.9851
Epoch 8/10
60000/60000 [==============================] - 138s 2ms/step - loss: 0.0252 - acc: 0.9931 - val_loss: 0.0451 - val_acc: 0.9895
Epoch 9/10
60000/60000 [==============================] - 138s 2ms/step - loss: 0.0242 - acc: 0.9941 - val_loss: 0.0554 - val_acc: 0.9894
Epoch 10/10
60000/60000 [==============================] - 138s 2ms/step - loss: 0.0223 - acc: 0.9944 - val_loss: 0.0524 - val_acc: 0.9900
ちなみにこれをいつものTensorFlowのバックエンドでやるとこうなります。
Epoch 1/20
60000/60000 [==============================] - 153s 3ms/step - loss: 0.1154 - acc: 0.9648 - val_loss: 0.0774 - val_acc: 0.9795
MXNetのほうが1割ぐらい速くなってますね。けど爆速というほど爆速でもないような 他のモデルも試してみると速い例が出てくるかもしれませんね。
以上です。Amazonが開発中のMXNetベースのKeras、ぜひ体験してみてください。
-
Google ColabのGPUはTesla K80で、このCompute Capabilityが3.7とそこそこ古いです。例えば、GTX 1080TiならCC6.1、750TiでもCC5.0あります。Google Colabの環境でCUDA9.0にしたところであまり恩恵を受けられないかもしれません。 ↩