「PyTorchは速いぞ」という記事がいろいろ出てて気になったので、何番煎じかわかりませんが、どのぐらい速いんだろうと思って実験してみました。実験するのはこの前作ったDenseNetです。
環境
- Google Colab
- GPUはTesla K80、ハードウェアアクセラレータはON
- Kerasのバージョンは2.1.6、PyTorchのバージョンは0.4.1
条件
Dense Netの論文の条件を若干アレンジしたものです。Data Augmentationはシンプルにしました。
- 成長率K=16とし、DenseNet-121と同じ構成のDenseNetを作る
- CIFAR-10を分類する
- Data Augmentationは左右反転、ランダムクロップのみ。
- L2正則化(Weight Decay)に2e-4(0.0002)。ドロップアウトはなし
- オプティマイザーはAdam、初期の学習率は0.001。全体の50%を過ぎたエポック、80%を過ぎたエポックでそれぞれ学習率を1/10にする
- 80epoch訓練させる
論文によると、k=12、深さ100のDenseNet(-BC)ではCIFAR-10のエラー率4.51まで落とせるそうです。自分がやった例ではエラー率8%止まりでしたが、正則化頑張ればあと2,3%は落とせるはずです。
Kerasの場合
コードはこちら https://gist.github.com/koshian2/99a6e48430f0ab0d7bb9e90d2b90353c
DenseNetの記事でだいたい説明したので、特に解説はいいですよね。Kerasで書いたコードの可読性の良さ素晴らしい。
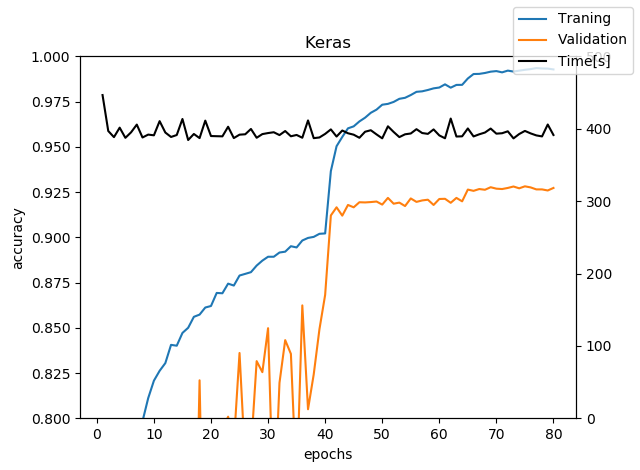
Validation Accuracyの最大値は92.82%。1epoch目を除くと、epochあたり約400秒使っています。ちなみにKerasの場合のepochあたりの時間は、Train+epochの最後のValidateを含んだ時間です。
PyTorchの場合(benchmark=False)
コードはこちら https://gist.github.com/koshian2/f1ecf57390d5efe24f6d67f3e596b43b
PyTorch書くの初めてだったので、見よう見まねで書きました。ここらへんとか、ここらへんとかかなり参考にしています。いくつか解説していきます。
デバイス設定
Kerasの場合勝手にGPU使ってくれるのですが、PyTorchの場合明示的にデバイスを指定してあげる必要があります。
device = 'cuda' if torch.cuda.is_available() else 'cpu'
torch.backends.cudnn.benchmark=True
「torch.backends.cudnn.benchmark=True」は最初入れるの忘れてしまったのですが、cuDNNのベンチマークモードをオンにするかどうかのオプションだそうです。Trueにするとオートチューナーがネットワークの構成に対して最適なアルゴリズムを見つけるため、高速化されます。CNNのようにネットワークの入力サイズが変化しない場合はTrueにすることを推奨だそうです(ソース)。これをFalseとTrueにした例をそれぞれ示します。
後にネットワークを作ったあと、GPUで実行する場合はネットワークもCUDA対応させないといけませんこれは、
net = DenseNet(16, blocks=[6,12,24,16])
if device=="cuda":
net = net.cuda()
のように.cuda()のメソッドを実行すればOKです。ただしネットワークのクラスはnn.Moduleを継承しているものとします。
データローダー
ここはKerasとあまり変わらないような感じはします。パイプラインをつなげていくだけです。ただSamplewiseな標準化をどうやるのかよくわからなかったので、平均・標準偏差0.5でずばっと標準化させました。
# Data
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
testloader = torch.utils.data.DataLoader(testset, batch_size=100, shuffle=False)
モジュールの定義
KerasがDefine-and-runに対して、PyTorchはDefine-by-runなのでモデル定義が似てるようで違います。Back Propagationは勝手にやってくれるからいいとして、forwardだけKeras風に書いたらパラメーターがないぞと怒られてしまいました。
# Model
class DenseBlock(nn.Module):
def __init__(self, input_channels, growth_rate):
super().__init__()
self.input_channels = input_channels
self.output_channels = input_channels + growth_rate
# Layers
self.bn1 = nn.BatchNorm2d(input_channels)
self.relu = nn.ReLU(inplace=True)
self.conv1 = nn.Conv2d(input_channels, 128, kernel_size=1)
self.bn2 = nn.BatchNorm2d(128)
self.conv2 = nn.Conv2d(128, growth_rate, kernel_size=3, padding=1)
def forward(self, x):
out = self.conv1(self.relu(self.bn1(x)))
out = self.conv2(self.relu(self.bn2(out)))
return torch.cat([x, out], 1)
Global Average Pooling
Kerasには組み込みのGlobal Average Pooling(GAP)がありましたが、PyTorchの組み込みはなかったので代用しました。GAPを使う前の画像サイズが(4,4)だったら、kernel_size=(4,4)でAveragePoolingすれば出力は(1,1)になり、それを全結合化すれば結果的にGAPをやったのと同じになるからです。
def make_model(self):
# 中略
self.gap = nn.AvgPool2d(kernel_size=4) # 最後は(4,4)
self.fc = nn.Linear(n, 10) # softmaxは損失関数で
self.gap_channels = n
# モデルの作成
def forward(self, x):
out = self.conv1(x)
# 中略
out = self.gap(out)
out = out.view(-1, self.gap_channels)
out = self.fc(out)
return out
大本の参考にしたPyTorch版のDenseNetもそんな実装していました。
ちなみにPyTorchの場合、ソフトマックスは損失関数のほうでやらせるので、nn.Linearで止めるのが流儀だそうです。
損失関数・オプティマイザー
PyTorchの場合は直接オプティマイザーに対してWeight Decay(L2正則化)を投げられます。これはいいですね。
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001, weight_decay=2e-4)
nb_epochs = 80
scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[nb_epochs*0.5, nb_epochs*0.8], gamma=0.1)
学習率のスケジューラー用の関数も用意されていて、MultiStepLRという関数を使うと、全体の50%までは初期の学習率、そこから80%までは1/10、80%以降はさらに1/10ということができます。詳しくはこちら。
ただし訓練のたびに、scheduler.step()を呼び出すのを忘れないようにしないと、学習率の変更が反映されない(はず)なので、ここはちょっと注意が必要です。こういうのを細かい所意識しなくていいのがKerasはやっぱり強い。
訓練
Kerasの場合fit()で一発だったのですが、ここを細かく書いていく必要があります。
# Training
def train(epoch):
print('\nEpoch: %d' % epoch)
net.train()
train_loss = 0
correct = 0
total = 0
start_time = time.time()
for batch_idx, (inputs, targets) in enumerate(trainloader):
inputs, targets = inputs.to(device), targets.to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
train_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
if batch_idx%50 == 0:
print(batch_idx, len(trainloader), 'Loss: %.3f | Acc: %.3f%% (%d/%d)'
% (train_loss/(batch_idx+1), 100.*correct/total, correct, total))
net.history["loss"].append(train_loss/(batch_idx+1))
net.history["acc"].append(1.*correct/total)
net.history["time"].append(time.time()-start_time)
def validate(epoch):
global best_acc
net.eval()
val_loss = 0
correct = 0
total = 0
with torch.no_grad():
for batch_idx, (inputs, targets) in enumerate(testloader):
# trainとほぼ同じなので省略
# Main-loop
for epoch in range(nb_epochs):
scheduler.step()
train(epoch)
validate(epoch)
trainのoptimizer.step()より下は必須のものではないですが、ミニバッチ単位の精度も計算するようにしています。Validationのデータのほうも同様に。ちなみにValidationの「with torch.no_grad()」の意味ですが、model.eval()と似て非なる場所で使われるようです。
These two have different goals:
model.eval() will notify all your layers that you are in eval mode, that way, batchnorm or dropout layers will work in eval model instead of training mode.
torch.no_grad() impacts the autograd engine and deactivate it. It will reduce memory usage and speed up computations but you won’t be able to backprop (which you don’t want in an eval script).
「目的が違うので、2つを使い分けてね」という趣旨なのですが、Validationデータをミニバッチ単位で評価させていくには、これを読む限りは「with torch.no_grad()」を使うほうが適切なように思えます(PyTorch初めて使ったのでここのニュアンスがよくわからない)。
さらにこれをループで回します
# Main-loop
for epoch in range(nb_epochs):
scheduler.step()
train(epoch)
validate(epoch)
schduler.step()をすごく忘れそうな感じががが(すでにやった)。訓練部分のコードの簡潔さはKerasの圧勝だと自分は思います。
結果
PyTorch+benchmark=Falseにした例です。
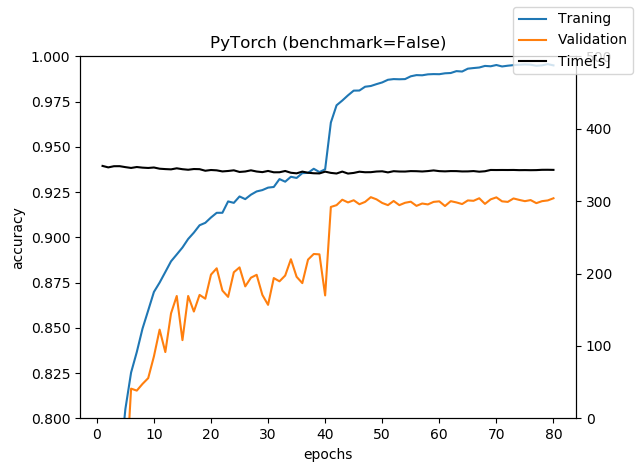
自分のミスでPyTorchの時間測定は訓練部分の時間しか測っていなかったので、Validationの評価も含めるとepochあたりもう10~20秒増えます。グラフでは360秒程度なので、ベンチマークモードを切ると速度はほぼKerasとそこまで変わらないという結果になりました。Google ColabのGPUなので、GeForceとかでやるとまた違うかもしれません。
また、訓練時のミニバッチの精度の計算といった余分なのが入っているのでここを削ぎ落とすともう少し高速化するかもしれません。
ちなみにValidation accuracyの最大値は92.22%となりました。レイヤーのデフォルト値がKerasと若干違うので、完全には一致しませんでしたが、ほぼ誤差みたいなものでしょう。
PyTorchの場合(benchmark=True)
今度はベンチマークモードをONにしてみました。
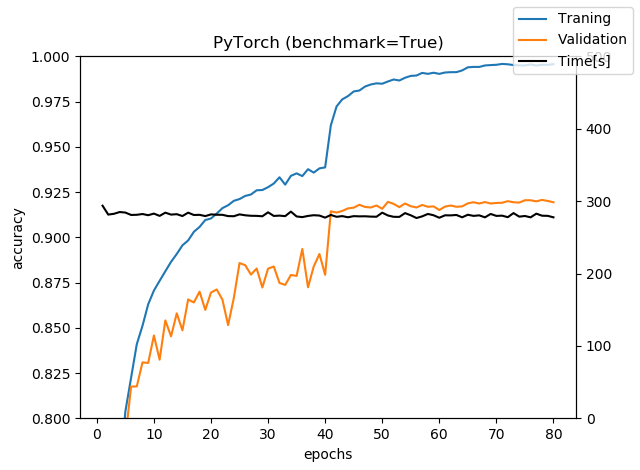
300秒を明確に切ったので明らかに速いです。今回も訓練時間の部分だけの時間のなのですが、そこを割り引いても速いです。Kerasと比べるとベンチマークモードのPyTorchは20~25%ぐらい速いと言えるでしょう。
ただ、例えばこの記事で言われているように、PyTorchのほうがKerasより10倍速いなどは確認できませんでした。レイヤー単位の時間測定と、エポック単位での時間測定で違いますし、GPUも据え置きのGTX1080と、クラウド上のTesla K80では違うのかもしれませんが、これを読んで「PyTorchはええ」と思った自分にとってはちょっと落胆した結果となりました。
まとめ
エポックあたりの時間をまとめます。ただし、KerasはTrain+Validateであるのに対して、PyTorchはTrainのみの時間であることに注意してください(10~20秒の差があります)
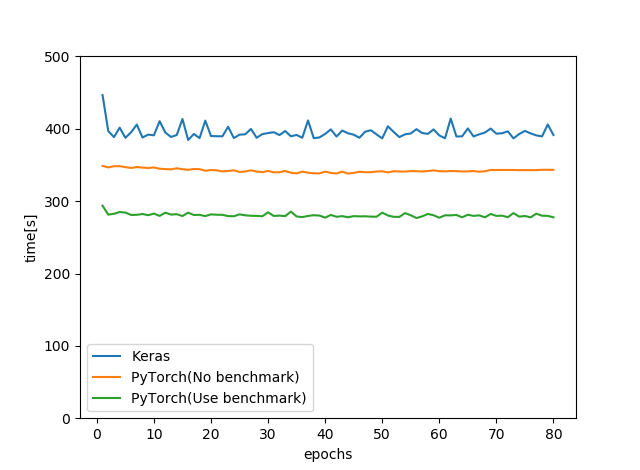
まとめます。
- 今回のGoogle Colabの場合、benchmark=FalseにするとPyTorchとKerasはあまり時間が変わらなかった。benchmark=TrueにするとPyTorchのほうが20~25%ぐらい速い。
- Kerasのコードの簡潔さ、可読性の良さはとても魅力的。速度差が20%ぐらいだったらまだまだKerasでも十分戦えるのでは?と自分は思う
以上です。PyTorch初めて書いた素人なので、「こうするとPyTorchもっと速くなるよ」という方法があったらぜひお待ちしております。