はじめに
みなさんこんばんは。
Qiitaユーザーの中で最もハーモニカの所有数の多い男(推定)ことkon2です。

日々いろんなハーモニカを吹いていて、思うんですよね。
実際、メーカーや機種ごとに音、変わんなくない? って。
そう思って、同じリフを8つのハーモニカで録音してみました。
8本のハーモニカで同じブルースのリフを演奏したやつのまとめ。
— konkon (@konkon28983820) December 16, 2019
Have you heard ‘Blues Harmonica Comparison’ by konkon on #SoundCloud? #np https://t.co/jByNu6BI1t
う~ん・・・。
録音を聞く限りでは、正直あんまりわからない・・・。
本当に違いがあるのか確かめるために、人工知能(QuantumCoreのQoreSDK)にこの2つのリフを聞き分けてもらいます。
ちなみにQoreSDKを使ったまじめな記事は下にあります。こっちも見てね!
QoreSDKを使ってリチウムイオン電池の劣化を予測してみた
今回の内容も全部(音源も含めて)GitHubに投稿してます!
データ概要
学習用データには2種のハーモニカ(SuzukiのManjiとHohnerのMarineBand)の以下の演奏を、
- Walles Coleman's Liff (29 sec)
- SecondLine Intro (12 sec)
- Juke Intro (23 sec)
- The Sailor & The Maid Intro (12 sec)
テスト用データは以下の演奏の別テイクを使います。
- Walles Coleman's Liff (29 sec)
トレーニングデータの読み込み
以下のように、Manjiによる演奏のデータを取り込みます。
path = glob.glob('./train/Manji/*.wav')
dataset = []
shapes = []
for p in path:
sound = AudioSegment.from_file(p)
data = np.array(sound.get_array_of_samples())
dataset.append(data)
取り込んだデータを可視化するとこんな感じです。
fig = plt.figure(figsize=(12,5))
plt.subplots_adjust(hspace=0.35)
for i in range(4):
plt.subplot(2,2,i+1)
plt.title(path[i])
x_range = np.linspace(0,dataset[i].shape[0]-1,dataset[i].shape[0])
plt.plot(x_range/44100,dataset[i])
よく見る感じのデータになってますね。
ちなみにMarineBandの演奏はこちら。

やっぱよくわかんない。
とりあえず4つしかデータがないのではよくないので、以下の関数で各演奏をだいたい1秒ごと(44000サンプルごと)に分割して、まとめます。
# decは正解ラベル。0 or 1の値を入力。
def SplitTune(dataset,dec,width = 44000):
print('Width:',width)
dataset_separate = []
for n,d in enumerate(dataset):
start = int(d.shape[0]*0.01)
end = int(d.shape[0]*0.99)
num = int((end-start)/width)
print(start,end,num)
for i in range(num):
hoge = d[(start+(i*width)):(start+(i*width))+width]
if(len(hoge) == width):
dataset_separate.append(hoge)
else:
pass
dataset_separate = np.array(dataset_separate)
answer = np.zeros(dataset_separate.shape[0])+dec
print('Shape of separated dataset:',dataset_separate.shape)
return(dataset_separate,answer)
正解データ(y_train)は、0がManji, 1がMarineBandに対応するようにします。
X_train_manji,y_train_manji = QoreTrain.SplitTune(dataset,dec=0)
テストデータの読み込み
トレーニングデータの読み込みと同様です。
今回は、別テイクのWallas Coleman's Riffを使います。
可視化するとこんな感じ。この2つを同様に44000サンプルで分割して、それぞれ分類します。
このリフ、昔はYouTubeで公開されていたんですが、今は非公開になっちゃったんですよね。
かわりに同じ人物の超かっこいい演奏を貼っておきます。
https://www.youtube.com/watch?v=aMHjCT9Y2bs
データの前処理
パラメータを除けば、ほぼ以下の記事と同様です。
QoreSDKの紹介とQoreで不整脈検出
まず、トレーニング用、学習用データをそれぞれまとめます。
ついでに次元も確認。
X_train = np.vstack((X_train_manji,X_train_marine))
y_train = np.hstack((y_train_manji,y_train_marine))
print('X_train.shape:', X_train.shape)
print('y_train.shape:', y_train.shape)
>> X_train.shape: (157, 44000)
>> y_train.shape: (157,)
X_test = np.vstack((X_test_manji,X_test_marine))
y_test = np.hstack((y_test_manji,y_test_marine))
print('X_train.shape:', X_test.shape)
print('y_train.shape:', y_test.shape)
>>X_train.shape: (58, 44000)
>> y_train.shape: (58,)
まずは、この細切れにした音声データを、さらに分割します。
width = 11000
stepsize = 2000
X_train = sliding_window(X_train, width, stepsize)
X_test = sliding_window(X_test, width, stepsize)
print('X_train.shape:', X_train.shape)
print('X_test.shape:', X_test.shape)
>> X_train.shape: (157, 17, 11000)
>> X_test.shape: (58, 17, 11000)
その後、qore_sdk.utilsのFeaturizerを使って、分割されたそれぞれのデータから20次元の特徴量を抽出します。
n_filters = 20
featurizer = Featurizer(n_filters)
X_train = featurizer.featurize(X_train, axis=2)
X_test = featurizer.featurize(X_test, axis=2)
print('X_train.shape:', X_train.shape)
print('X_test.shape:', X_test.shape)
>> X_train.shape: (157, 17, 20)
>> X_test.shape: (58, 17, 20)
QoreSDKを用いた学習
username, password, endpointは申請が必要です。
詳細は![]()
深層学習以外の機械学習と応用技術 by QuantumCore Advent Calendar 2019
client = WebQoreClient(username, password, endpoint
client.classifier_train(X_train, y_train)
まずはトレーニングデータがうまく学習できているかをsklearn.metricsのclassification_reportで検証します。
res = client.classifier_predict(X_train)
report = classification_report(y_train, res['Y'])
print(report)
>> precision recall f1-score support
0.0 0.95 0.91 0.93 79
1.0 0.91 0.95 0.93 78
micro avg 0.93 0.93 0.93 157
macro avg 0.93 0.93 0.93 157
weighted avg 0.93 0.93 0.93 157
とりあえず学習はできてる、かな?
ではテストデータでの検証です。
res = client.classifier_predict(X_test)
report = classification_report(y_test, res['Y'])
print(report)
>> precision recall f1-score support
0.0 0.86 0.83 0.84 29
1.0 0.83 0.86 0.85 29
micro avg 0.84 0.84 0.84 58
macro avg 0.85 0.84 0.84 58
weighted avg 0.85 0.84 0.84 58
F1スコアで0.84! これは結構いいんじゃないでしょうか?
少なくとも自分の耳よりは……。
では、分類結果を可視化してみます。
青色が演奏のうちハーモニカの機種を正しく見分けられた部分、赤色が見分けられなかった部分です。
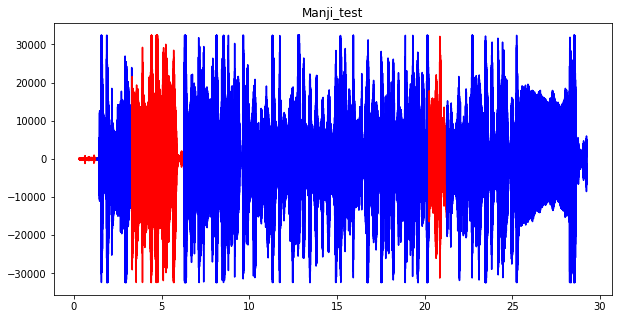
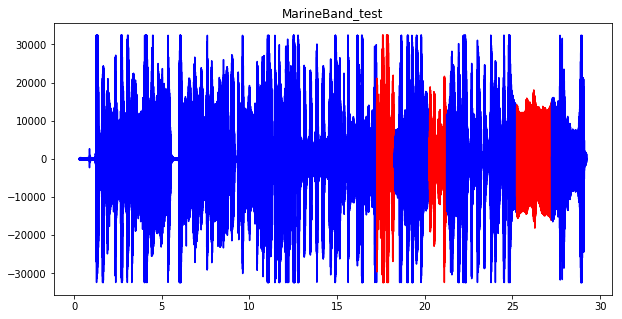
1分ちょいのトレーニングデータで、人工知能(QoreSDK)にはハーモニカの機種が聞き分けられるみたいです。
まとめ
というわけで、ちょっとしたお遊びでした。
さすがQoreは音声処理が得意というだけあり、ちょっとのデータですが一応結果を出すことができました。
実際のところ学習はちょっと不安定で、うまくいったりいかなかったりなので、データを増やすかパラメータの調整が必要だと思います。
(そのためにももっと演奏のレパートリーを増やさなければ……)

将来的には8つのハーモニカ全部で多クラス分類でもやってみたいですね。
あと、木製ボディとプラスチックボディで違いはあるのかとか、リードの材質(真鍮 or ステンレス)を見分けられるのかとか、演奏者ごとの音色にどんな特徴があるのかとか、興味は尽きません。
今後もちまちまと遊びつつ、音響処理について勉強もしていきたいなと思います。
それでは~