これは深層学習以外の機械学習と応用技術 by QuantumCore Advent Calendar 2019の第2日目の記事です。
はじめに
QuantumCoreのリードエンジニアの@sk1010kです。
@ryoppippiに続いて、QoreとQoreSDKについて紹介していきます。
弊社QuantumCoreは時系列解析のソリューションを提供している会社で、Reservoir Computingを応用したQoreシリーズというものを展開しています。
その中の、コア技術である「Qore」と、前処理・特徴抽出・APIクライアントを含んだ「QoreSDK」を、今回のアドベントカレンダーでは無料で公開しています。
Reservoir ComputingやQoreについては、第1日目に@ryoppippiが紹介しているので、この記事ではQoreSDKについて紹介していきます。
合わせて、Qore+QoreSDKを使って、心電図から不整脈を検出する事例を紹介します。
不整脈検出で使うコードや環境構築の方法はGithubの公式リポジトリに載せていますので、ぜひ試してみてください。
本企画では、iPhone11やGoogle Pixel4、NVIDIA Jetson Nano開発キットといった豪華プレゼントを用意していますので、ぜひ皆さんの投稿もお待ちしております!
QoreかQoreSDKの一方のみを使ってもいいですし、Reservoir Computingに関することやその他の機械学習技術についてでも歓迎です!
ちなみに、社内の人はプレゼント対象外ですので、ご安心を。。。
QoreSDKについて
QoreSDKは、Qoreの前段で使われる、前処理・特徴抽出・APIクライアントなどをひとまとめにしたライブラリです。
生データを直接Qoreに入れて学習・推論することもできますが、QoreSDKで前処理・特徴抽出することで、より少ないデータで、かつ、Qore内部のReservoirを小さく保ちつつ(省メモリで)、高精度を維持することができます。
QoreSDKの特徴抽出器(qore_sdk.featurizer.Featurizer)は、時系列データに対するフィルタ処理を基本としたものになっています。
詳細は非公開としていますが、一言でいうと周波数分解です。
Qore及びQoreSDKの利用には現在アカウント申請が必要です。
こちらのフォームから「利用タイプ」で「Qiitaアドベントカレンダ執筆」を選択し、Qiitaアカウント名、メールアドレスを入力し送信していただくと、返信メールからQoreSDKをダウンロードできます。
今回QoreSDKはPython版のバイナリパッケージのみ公開しています。
自分のOSやPythonのバージョンにあったバイナリをダウンロードして、インストールしてください。
具体的な手順はGithubの公式リポジトリに記載されています。
コード例
簡単に使い方を説明します。
QoreSDKはNumPyなどと同じく、Pythonのライブラリとなっているので、pipでインストール可能で、(Ubuntu18.04, Python3.6の例)
$ pip install qore_sdk-0.1.0-cp36-cp36m-linux_x86_64.whl
importも同様です。
>>> import qore_sdk.featurizer
QoreSDKの特徴抽出器(qore_sdk.featurizer.Featurizer)にかけるデータを用意します。
shapeが (サンプル数, 時系列長)の2次元のNumPy配列です。つまり、単変量の時系列データです。
>>> import numpy as np
>>> X = np.arange(10*100).reshape(10,100)
>>> print(X.shape)
(10,100)
それではこのデータにFeaturizerを使います。
Featurizerをインスタンス化するときに、コンストラクタにいくつのフィルタを使うか(n_filters)を指定します。
n_filtersは大体20~40くらいでうまくいく場合が多いです。axisでどの軸を処理するか指定します。
>>> n_filters = 40
>>> featurizer = qore_sdk.featurizer.Featurizer(n_filters)
>>> features = featurizer.featurize(X, axis=1)
>>> print(features.shape)
(10, 40)
100だった第2次元の長さが40に変わっています。
これは、長さが100の単変量時系列データから40個のフィルタを使って、40個の特徴を抽出したことを表しています。
※追記
その他のクラスやメソッドの使い方は、help関数などを使って、docstringを参照してください。
不整脈検出
上記で扱ったのは、説明のためだけの無意味な配列でした。
以降は、QoreとQoreSDKを使って、もっと実践的なデータを扱ってみます。
題材は心電図のデータから不整脈を検出するというタスクです。(正常拍動と不整脈の2値分類)
日本メディカルAI学会のオンライン講義資料にある8. 実践編: ディープラーニングを使ったモニタリングデータの時系列解析を参考にしています。
Githubの公式リポジトリに環境構築方法がありますので、参考にしてください。
以下のコードは、こちらのノートブックにまとめてあります。
データセット
MIT-BIH Arrhythmia Database (mitdb)を使います。以下のようなデータです。(上述の講義資料から引用)
正常拍動
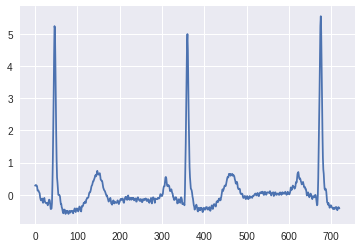
不整脈
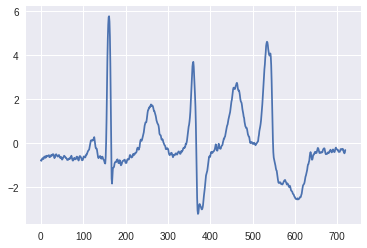
コード解説
データのダウンロード
上述の講義資料を参考に、mitdbから心電図データをダウンロードし、前処理を施すモジュール(dataloader.py)を用意しました。
モジュール実行ディレクトリ直下のdataset/download/にダウンロードされます。
と同時に、dataset/preprocessed-denoise/に前処理を施したデータが出力されます。
初回実行時は、ダウンロードに結構時間がかるので、辛抱強くお持ちください。。。
from dataloader import load_dataset
X_train, X_test, y_train, y_test = load_dataset()
print('X_train.shape:', X_train.shape)
print('X_test.shape:', X_test.shape)
X_train.shape: (47738, 720)
X_test.shape: (45349, 720)
前処理
WebQoreへ投げるにはデータが多いので、減らします。(Undersampling)
というよりも、むしろデータが少なくても精度を出せるのがQore+QoreSDKの特徴です。
このデータセットは正常拍動の割合が多いimbalancedなデータなので、若干扱いに注意が必要です。
まず学習データは、正常拍動と不整脈クラスを、数が少ない不整脈クラスのデータ数の1/10に合わせます。
検証データは、正常拍動と不整脈クラスの割合を保ったまま、それぞれ1/100にします。
import numpy as np
from imblearn.datasets import make_imbalance
# 学習データ
_, counts = np.unique(y_train, return_counts=True)
n_samples_per_class = counts.min() // 10
X_train, y_train = make_imbalance(X_train, y_train, {0:n_samples_per_class, 1:n_samples_per_class})
print('X_train.shape:', X_train.shape)
# 検証データ
_, counts = np.unique(y_test, return_counts=True)
X_test, y_test = make_imbalance(X_test, y_test, {0:counts[0]//100, 1:counts[1]//100})
print('X_test.shape:', X_test.shape)
X_train.shape: (748, 720)
X_test.shape: (453, 720)
Qoreへの入力はshapeが(サンプル数, 時系列長, 変量数)の配列なので、それに合わせるために時系列を小時系列に分割します。
つまり、(サンプル数, 時系列長, 小時系列長)の配列をまず作って、QoreSDKのFeaturizerで第3次元の時系列から特徴抽出をし、(サンプル数, 時系列長, 変量数)の配列に変換します。
そのための小時系列への分割です。
from qore_sdk.utils import sliding_window
width = 144
stepsize = 36
X_train = sliding_window(X_train, width, stepsize)
X_test = sliding_window(X_test, width, stepsize)
print('X_train.shape:', X_train.shape)
print('X_test.shape:', X_test.shape)
X_train.shape: (748, 17, 144)
X_test.shape: (453, 17, 144)
特徴抽出
QoreSDKのFeaturizerを使って特徴抽出をし、(サンプル数, 時系列長, 変量数)の配列に変換します。
from qore_sdk.featurizer import Featurizer
n_filters = 40
featurizer = Featurizer(n_filters)
X_train = featurizer.featurize(X_train, axis=2)
X_test = featurizer.featurize(X_test, axis=2)
print('X_train.shape:', X_train.shape)
print('X_test.shape:', X_test.shape)
X_train.shape: (748, 17, 40)
X_test.shape: (453, 17, 40)
学習
発行したアカウント情報を代入して、学習してください。
学習が数秒、遅くとも10秒以内で終わるはずです。
from qore_sdk.client import WebQoreClient
username = ''
password = ''
endpoint = ''
client = WebQoreClient(username, password, endpoint=endpoint)
client.classifier_train(X_train, y_train)
推論
推論結果は以下のようになりました。
データが少ないにもかかわらず高い精度を出せていると思います!
from sklearn.metrics import classification_report
res = client.classifier_predict(X_test)
report = classification_report(y_test, res['Y'])
print(report)
precision recall f1-score support
0 0.99 0.94 0.96 421
1 0.53 0.94 0.67 32
accuracy 0.94 453
macro avg 0.76 0.94 0.82 453
weighted avg 0.96 0.94 0.94 453
参考までに、先程の講義資料の中でDeep Learningを使った場合の結果を載せておきます。
Deep Learningのほうでは、データをフルに使って、学習により長い時間をかけていることを考えると、Qoreの少量データで高速学習という特徴の有用性がわかるのではないでしょうか。
precision recall f1-score support
Normal 0.99 0.97 0.98 42149
VEB 0.67 0.93 0.78 3200
micro avg 0.96 0.96 0.96 45349
macro avg 0.83 0.95 0.88 45349
weighted avg 0.97 0.96 0.97 45349
ちなみに、Qoreで全データを使うと、上記のDeep Learningの結果を超えます!
precision recall f1-score support
0 1.00 0.97 0.98 42149
1 0.73 0.94 0.82 3200
micro avg 0.97 0.97 0.97 45349
macro avg 0.86 0.96 0.90 45349
weighted avg 0.98 0.97 0.97 45349