特徴点マッチングて?
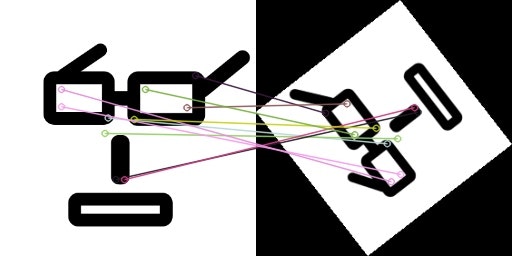
こんなやつ。
400x400px の画像と、それを 200x200px にリサイズし回転させたものを特徴点を検出しマッチングさせています。
コード
上の画像を出力しているコードです。
これだけ。
import cv2
from IPython.display import Image
from IPython.display import display
# 画像読み込み
img1 = cv2.imread('/path/to/dir/megane400x400.png')
img2 = cv2.imread('/path/to/dir/megane200x200_rotate.png')
# 特徴点検出
akaze = cv2.AKAZE_create()
kp1, des1 = akaze.detectAndCompute(img1, None)
kp2, des2 = akaze.detectAndCompute(img2, None)
# マッチング
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
matches = bf.match(des1, des2)
# 特徴点間のハミング距離でソート
matches = sorted(matches, key=lambda x: x.distance)
# 2画像間のマッチング結果画像を作成
img1_2 = cv2.drawMatches(img1, kp1, img2, kp2, matches[:10], None, flags=2)
decoded_bytes = cv2.imencode('.jpg', img1_2)[1].tobytes()
display(Image(data=decoded_bytes))
コードを分割して見ていきます
画像読み込み
img1 = cv2.imread('/path/to/dir/megane400x400.png')
img2 = cv2.imread('/path/to/dir/megane200x200_rotate.png')
print(img1)
# [[[255 255 255]
# [255 255 255]
# [255 255 255]
# ...
# [255 255 255]
# [255 255 255]
# [255 255 255]]
#
# [[255 255 255]
# [255 255 255]
# [255 255 255]
# ...
# [255 255 255]
# [255 255 255]
# [255 255 255]]
#
# ...
#
# [[255 255 255]
# [255 255 255]
# [255 255 255]
# ...
# [255 255 255]
# [255 255 255]
# [255 255 255]]
#
# [[255 255 255]
# [255 255 255]
# [255 255 255]
# ...
# [255 255 255]
# [255 255 255]
# [255 255 255]]]
print(img1.shape)
# (400, 400, 3)
ピクセルごとのBGR値が返されます。
cv2.imread()メソッドではRGBではなくBGR(値の順番がちがう)。
Pillowで使う場合はRGBに変換が必要なので注意。
参照: https://note.nkmk.me/python-opencv-bgr-rgb-cvtcolor/
コレは400x400pxの画像なので、シェイプが(400, 400, 3)となっています。
[255 255 255] <- こいつが1ピクセルあたりのBGR値。
[255 255 255]が並んでいるのは画像の白い部分ですね。
特徴点検出
akaze = cv2.AKAZE_create()
kp1, des1 = akaze.detectAndCompute(img1, None)
kp2, des2 = akaze.detectAndCompute(img2, None)
print('##### 特徴点 #####')
print(kp1)
# [<KeyPoint0x11af41db0>, <KeyPoint0x11af649c0>, <KeyPoint0x11af64ba0>,
# ...
# <KeyPoint 0x126265030>, <KeyPoint 0x126265120>, <KeyPoint 0x126265150>]
# 検出された特徴点がcv2.KeyPointクラスでとして配列で返される。
print('##### 特徴点の数 #####')
print(len(kp1))
# 143
# 特徴点の数 画像の種類やサイズによって変わる
# 画像を大きくすることで特徴点を増やせるが、一定の値を超えるとサチって計算量が増えるだけになるので出力を確認しながら大きくする
print('##### 特徴量記述子 #####')
print(des1)
# [[ 32 118 2 ... 253 255 0]
# [ 33 50 12 ... 253 255 48]
# [ 0 134 0 ... 253 255 32]
# ...
# [ 74 24 240 ... 128 239 31]
# [245 25 122 ... 255 239 31]
# [165 242 15 ... 127 238 55]]
# AKAZEでは61次元ベクトルで返される
print('##### 特徴ベクトル #####')
print(des1.shape)
# (143, 61) <- (58は特徴点の数, 特徴量記述子の要素数)
AKAZE は特徴点検出アルゴリズムの一つで、ORB、SIFT、SURF などと同じ立ち位置。
計算スピードが早く、オープンソースなので使いやすいなどの利点があるようです。
※ SIFT や SURF は特許の問題がある。
こちらの記事がとてもわかりやすいです。
https://qiita.com/hitomatagi/items/62989573a30ec1d8180b
また、こちらによると ORB より AKAZE の方が検出精度が高そう。
https://docs.opencv.org/3.0-rc1/dc/d16/tutorial_akaze_tracking.html
特徴点ってどうやって検出してるの?

A~F はこの画像から一部分を切り取ったものです。
どこを切り取った画像かわかりますか?
多くの人がこのような感想を持つのではないでしょうか?
A, B -> 空、壁ということはわかるが、場所は特定しづらい。(フラット)
C, D -> 建物上部のどこかであることがわかる。ただし、厳密な場所までは特定が難しい。(エッジ)
E, F -> 建物の角であることがすぐわかる。(コーナー)
このことから E, F のような部分が良い特徴点と言えそうです。
E, F のようなコーナーを探し出すために、AKAZE などのアルゴリズムでは輝度の変化の大きいところを検出しているとのこと。
参照: http://www.lab.kochi-tech.ac.jp/yoshilab/thesis/1150295.pdf
特徴点のマッチング
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
matches = bf.match(des1, des2)
matches = sorted(matches, key=lambda x: x.distance)
print(matches)
# マッチした特徴点がcv2.DMatchクラスとして配列で返される
# [<DMatch 0x1260f5150>, <DMatch 0x1260f5490>, ... <DMatch 0x1260f65f0>, <DMatch 0x1260f69d0>]
print(len(matches))
# 58
print('### 特徴量記述子間の距離 ###')
for i in matches:
print(i.distance)
# 6.0
# 6.0
# ...
# 142.0
# 150.0
BFMatcher は 2 枚の画像から得られた特徴量記述子の距離(ここではハミング距離)を総当たりで計算し、最も近いものをマッチング。
BFMatcher()の第一引数 cv2.NORM_HAMMING でハミング距離で距離による算出を指定しています。
第荷引数の crossCheck はデフォルト False では、一方のキーポイントから見ると最も近いが、他方のキーポイントから見ると他にもっと近いキーポイントがあるという非対称が起こります。True にすると双方が最短である結果のみを返します。
sorted()の引数 key に関数を渡すことで返却値によるソートを行う。
- matches -> DMatch 型オブジェクトのリスト
- DMatch.distance -> 特徴量記述子間の距離 低いほどマッチングの度合いが高い
- DMatch.trainIdx -> 学習記述子(参照データ)中の記述子のインデックス
- DMatch.queryIdx -> クエリ記述子(検索データ)中の記述子のインデックス
- DMatch.imgIdx -> 学習画像のインデックス
ハミング距離って?
等しい文字数を持つ二つの文字列の中で、対応する位置にある異なった文字の個数である。
・ 1011101 と 1001001 の間のハミング距離は 2 である。
・ 2173896 と 2233796 の間のハミング距離は 3 である。
・ "toned" と "roses" の間のハミング距離は 3 である。
bf.match()に渡される def1 と def2 は 61 次元の特徴量記述子が複数格納された配列です。
print(des1)
# [[ 32 118 2 ... 253 255 0] <- 61個
# [ 33 50 12 ... 253 255 48] <- 61個
# [ 0 134 0 ... 253 255 32]
# ...
# [ 74 24 240 ... 128 239 31]
# [245 25 122 ... 255 239 31]
# [165 242 15 ... 127 238 55]
bf.match()では以下の処理がされているようです。
- 10 進数 -> 2 進数変換しハミング距離を算出
- 61 要素分の距離の合計をとる
- 総当りで、すべての特徴量同士の距離を求める
- ある閾値をこえたものを結果として返す <- ここが未確認
実験 1
10 進数 -> 2 進数変換されていることがわかります。
# 0は2進数で00000000
des1 = np.array([0]).astype('uint8')
# 255は2進数で11111111
des2 = np.array([255]).astype('uint8')
# ※ astype('uint8')にしないと、bf.match()に渡せない。
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
matches = bf.match(des1, des2)
matches = sorted(matches, key=lambda x: x.distance)
for i in matches:
print(i.distance)
# 8.0 <- ハミング距離
# 244は2進数で11111110
des1 = np.array([244]).astype('uint8')
# 255は2進数で11111111
des2 = np.array([255]).astype('uint8')
# ※ astype('uint8')にしないと、bf.match()に渡せない。
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
matches = bf.match(des1, des2)
for i in matches:
print(i.distance)
# 1.0 <- ハミング距離
実験 2
特徴量記述子内の要素同士の距離の合計をとっていることがわかります。
# 0bのプレフィックスをつけることで2進数表現ができます。
des1 = np.array([[0b0001, 0b0001, 0b0001], [0b0011, 0b0011, 0b0011], [0b0111, 0b0111, 0b0111]]).astype('uint8')
des2 = np.array([[0b0000, 0b0000, 0b0000]]).astype('uint8')
# ※ astype('uint8')にしないと、bf.match()に渡せない。
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
matches = bf.match(des1, des2)
# [0b0001, 0b0001, 0b0001] と [0b0000, 0b0000, 0b0000]の結果だけ返されている
for i in matches:
print(i.distance)
# 3.0 <- ハミング距離
マッチング結果画像を作成 (冒頭の画像)
img1_2 = cv2.drawMatches(img1, kp1, img2, kp2, matches[:10], None, flags=2)
decoded_bytes = cv2.imencode('.jpg', img1_2)[1].tobytes()
display(Image(data=decoded_bytes)
drawMatches()の引数で matches[:10]とすることで、マッチした中で距離の近い特徴点を上から 10 個描画している。