はじめに
OpenCV(Open Source Computer Vision Library)はBSDライセンスの映像/画像処理ライブラリ集です。画像のフィルタ処理、テンプレートマッチング、物体認識、映像解析、機械学習などのアルゴリズムが多数用意されています。
● OpenCVを使った動体追跡の例 (OpenCV Google Summer of Code 2015)
https://www.youtube.com/watch?v=OUbUFn71S4s
● インストールと簡単な使い方はこちら
OpenCV 3(core + contrib)をPython 3の環境にインストール&OpenCV 2とOpenCV 3の違い&簡単な動作チェック
● 静止画像のフィルター処理についてはこちら
OpenCVでエッジ検出してみる
OpenCVで各種フィルター処理をする(グラディエント、ハイパス、ラプラシアン、ガウシアン)
● 動画ファイルの処理についてはこちら
OpenCVで動画をリアルタイムに変換してみる
OpenCVでWebカメラ/ビデオカメラの動画をリアルタイムに変換してみる
今回は、OpenCVを使って特徴点を抽出してみます。
特徴点は、複数の画像をつなげてパノラマ画像を作成したり、動画で動体のオプティカルフローを作成する際の基礎データとして使います。
ORB (Oriented FAST and Rotated BRIEF)、AKAZE (Accelerated KAZE)
ORBは、特徴点、特徴量を抽出するアルゴリズムで、移動、回転、ズームのどれにもロバストネスがあるアルゴリズムです。
もともとSIFTというアルゴリズムが、移動、回転に加えてズーム対するロバストネスを獲得しました。ただSIFTは計算量が多く、低速だったため、速度を改良したSURFというアルゴリズムがでてきました。ただし、SIFTもSURFも特許で守られているため、使用するためには特許料を払う必要があります。
そこで、移動、回転、ズームの3つに対してロバストネスをもち、計算速度も速く、フリーで使うことができるORBというアルゴリズムが2011年に開発されました。
またOpenCV 3.0からは、2013年に開発されたAKAZEというアルゴリズムがサポートされています。AKAZEは、計算量がORBよりもやや多いものの、低周波領域、高周波領域の抽出精度がORBよりも優れていて、ハイスピードカメラのトラッキングでその威力を発揮するとされています。AKAZEとORBの比較動画はこちら(youtube)。
アルゴリズムは、対象物やタスクに応じて適切なものが異なるので、実際に適用してみてどれが一番適切なのかを比較する必要があります。特徴点、特徴量が検出できているか、求められているサンプリングタイム内に収まるか、ハードウェアの性能は適切か、など、多岐に渡った検討が必要になります。
プログラム
それでは、ORBアルゴリズムを使って特徴点を抽出し、画像に抽出した特徴点を表示してみます。
流れは以下のようになります。
- 画像ファイルの読み込み
- ORBで特徴点&特徴量の抽出
- 画像に特徴点を書き込み
- 結果画像を表示
-
各種パラメータ
- 全てデフォルト
-
動作検証環境
- OpenCV 3.1.0
- Python 3.5.1
import cv2
# 画像ファイルの読み込み
img = cv2.imread('img.jpg')
# ORB (Oriented FAST and Rotated BRIEF)
detector = cv2.ORB_create()
# 特徴検出
keypoints = detector.detect(img)
# 画像への特徴点の書き込み
out = cv2.drawKeypoints(img, keypoints, None)
# 表示
cv2.imshow("keypoints", out)
実行結果
ORBで特徴点を抽出し、特徴点を画像に重ね合わせると以下のようになりました。
人間の目では、手前の道路に立っている人が特徴点なのかと思ってしまいますが、コンピュータの目では、道路に立っている人はそれほど特徴的とは思っていないようでした。

ORB
AKAZEで特徴点を抽出し、特徴点を画像に重ね合わせると以下のようになりました。
こちらは、手前の道路に立っている人を特徴点として認識しています。
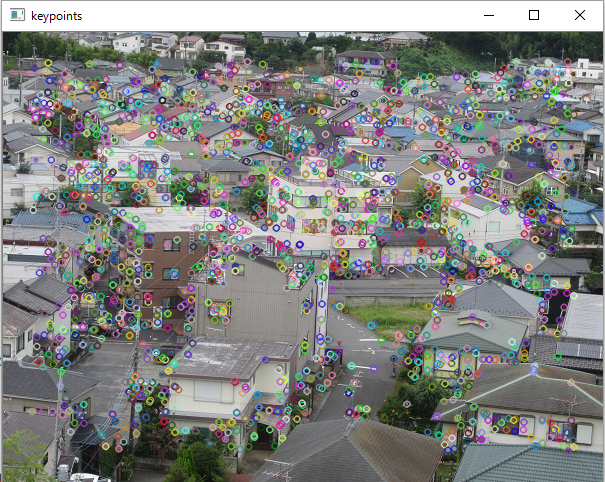
AKAZE
ちなみに、特徴点の数が多かった順に並べると、以下の通りでした。ただし、各種オプションはデフォルトのまま実行していますし、たまたまこの画像でこうなりましたという結果なので、数の大小に深い意味はないです。
SimpleBlobDetector < ORB < MSER < GFTT < AKAZE < KAZE < BRISK < FAST < AgastFeature
OpenCV 3 がサポートしている特徴量抽出アルゴリズム
OpenCVでは、ORB以外のアルゴリズムもサポートしています。
プログラムのdetectorを切り替えるだけでアルゴリズムを変更することができます。
# AgastFeatureDetector
detector = cv2.AgastFeatureDetector_create()# FAST
detector = cv2.FastFeatureDetector_create()# MSER
detector = cv2.MSER_create()# AKAZE
detector = cv2.AKAZE_create()# BRISK
detector = cv2.BRISK_create()# KAZE
detector = cv2.KAZE_create()# ORB (Oriented FAST and Rotated BRIEF)
detector = cv2.ORB_create()# SimpleBlobDetector
detector = cv2.SimpleBlobDetector_create()# SIFT
detector = cv2.xfeatures2d.SIFT_create()
GFTT(Harris法の簡素版)は専用のラッパーメソッドが用意されています。
corners = cv2.goodFeaturesToTrack(image, maxCorners, qualityLevel, minDistance[, corners[, mask[, blockSize[, useHarrisDetector[, k]]]]])
特徴点の数をカウントしたい場合はkeypointsをlen()してあげるとカウントできます。
print(len(keypoints))
ORB, GFTT, AKAZE, KAZE, BRISK, SIFTは、特徴点だけではなく、特徴量も計算しています。
-
2段階のメソッド
keypoints = detector.detect(image)
descriptors = detector.compute(image, keypoints) -
1段階のメソッド
keypoints, descriptors = detector.detectAndCompute(image)
特徴点 KeyPoint オブジェクト
| 属性 | 内容 |
|---|---|
| pt | ポイント(x, y) |
| size | 特徴点の直径 |
| angle | [0, 360) の範囲の角度。y軸が下方向で右回り。計算不能な場合は-1。 |
| response | 特徴点の強度 |
| octave | 特徴点を検出したピラミッドレイヤー |
| class_id | 特徴点が属するクラスのID |
アクセスする際はこんなコードになります。
# 配列の位置を指定する
i = 5
# 特徴量を1つ取り出す
keypoint = keypoints[i]
# 各属性にアクセスする
keypoint.pt
keypoint.size
keypoint.angle
keypoint.response
keypoint.octave
keypoint.class_id
アルゴリズムによっては、KeyPointの一部のみ利用しているようです。
例えば、AKAZEでサンプル画像lena.jpgを分析してみると、pt, size, response, octave, class_id に値がセットされていて、angleは利用されていませんでした。