0. はじめに。
ある昼下がり、ふと思い立った。アナログメータを画像認識で取得しようと。
今回は同じような気持ちになったエンジニアに向けて、こんな方法もあるよ![]()
ということを提案したい。
※尚、とりあえず動けばいいやコードなので、その点ご容赦ください
目的のメータの感じ。電気のメータなんかはこれが多いのではないか。
アナログメータといえば、検針がある丸型を想像するかもしれないが、
そちらに関しての記事はいくつか見つけたので、こちらを対象にした。
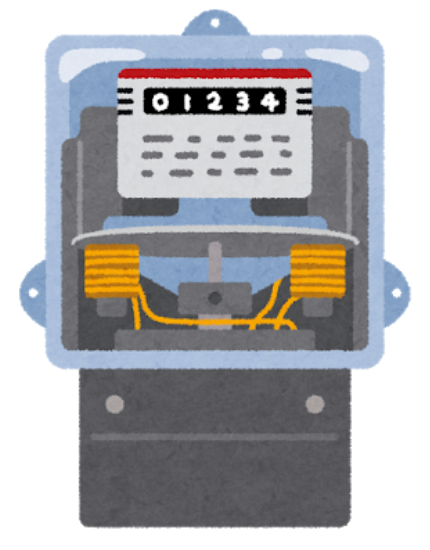
リアルなやつ
ちなみに結論を先に示すと、認識の結果はこんな感じになる。![]()
(数字が違うのはテストはランダムな画像を抽出しているので)
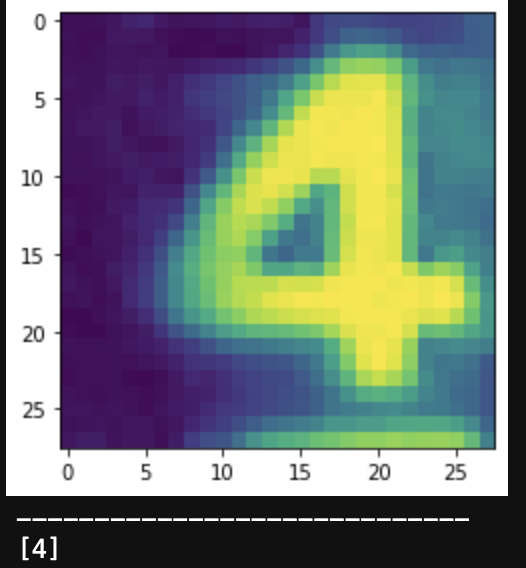
なんとなく成功している気もする...
では始めていくが、そもそも何からやろうか![]()
- 画像を集める
- 学習させる/チューニングする
- テストする
大きく分けるとこんな感じか?とりあえずやってみよう!
1. 学習用画像データの準備
始めようとした時ふと思った。「画像集めるのめんどくさくね?」
データセットがネットに落ちてないか調べてみた。
.
.
.
ないですね。
「なら、MNISTのデータセット使ってやればできんじゃね?」

[MNIST]:https://ja.wikipedia.org/wiki/MNIST%E3%83%87%E3%83%BC%E3%82%BF%E3%83%99%E3%83%BC%E3%82%B9
すまん無理だったわ。手書きとアナログ数字では結構違う特徴があるみたいで、
正解率が70%くらいだった。
覚悟を決めて、画像を収集することに![]()
イメージはこんな感じで、ウェブカメラ(¥1000くらい)でひたすら画像を撮影し、データを蓄積していく。
(我ながらひどいイメージですみません)
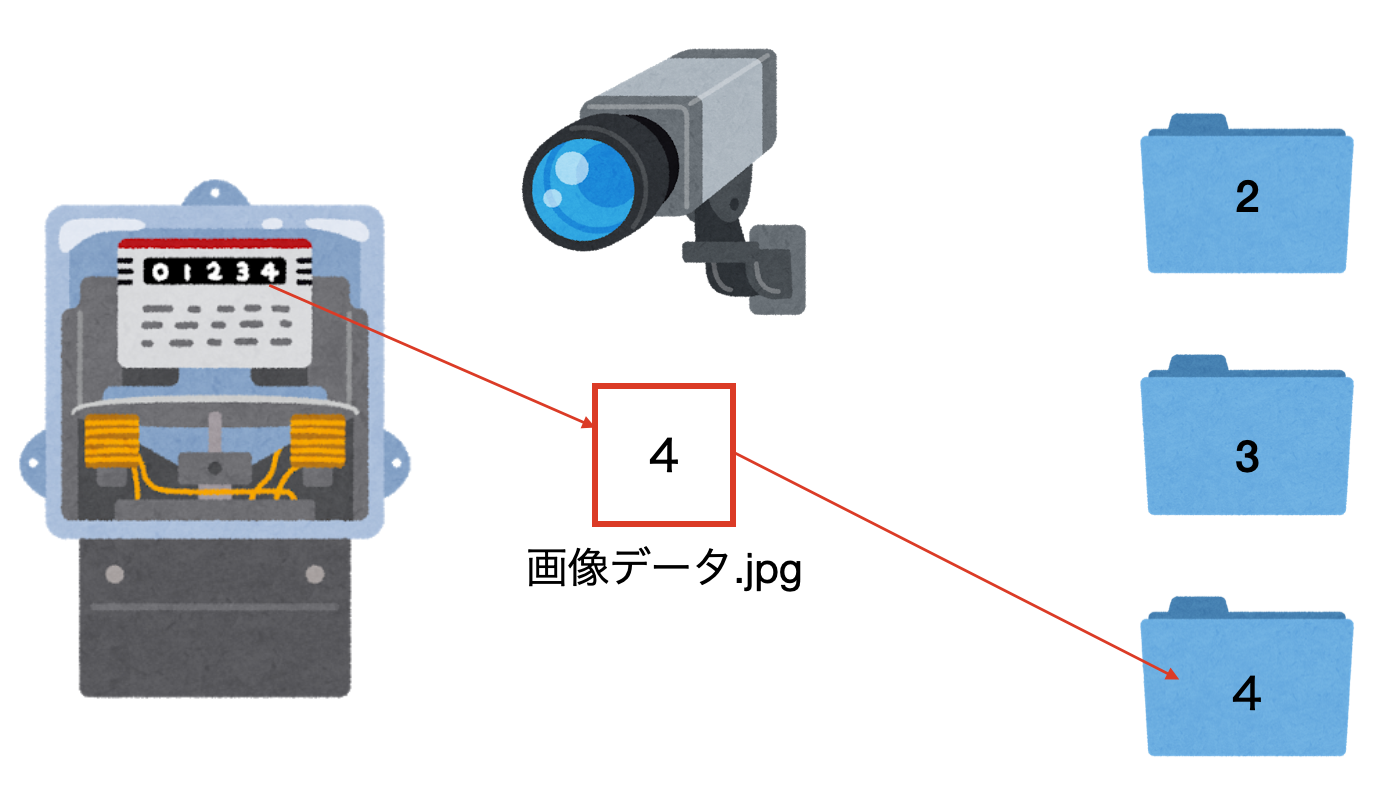
画像を集める
今回は長時間放置して撮影したいので、[ARマーカー][link-1]を使って、ちょっとカメラがズレても良い仕様にしようと思う。
もっといい方法はあると思うけど。
また、切り取り位置は調整してください。
メータ任せでデータをひたすら取得するので、止めるタイミングは自分自身で決める。
この時、取れないデータやデータ量の偏りが発生するので、意識してデータを取得する。
[link-1]:https://qiita.com/hsgucci/items/37becbb8bfe04330ce14
# 必要なライブラリ
import cv2
import time
# ARマーカーの設定
aruco = cv2.aruco
dictionary = aruco.getPredefinedDictionary(aruco.DICT_4X4_50)
def meterImageSaver(camera_num, cycle):
# ウェブカメラ検出、設定
cap = cv2.VideoCapture(camera_num)
img_cnt = 0
# 自分が納得するまでデータを撮り続ける。
while True:
ret, frame = cap.read()
cv2.imshow("frame", frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
Height, Width = frame.shape[:2]
img = cv2.resize(frame,(int(Width),int(Height)))
#マーカーを検出
corners, ids, rejectedImgPoints = aruco.detectMarkers(img, dictionary)
if len(corners) > 0:
#マーカーid=01検出時(今回マーカーID:01を使用)
if ids[0] == 1:
x_AR = int(corners[0][0][3][0])
y_AR = int(corners[0][0][3][1])
print(x_AR, y_AR)
# 切り取り範囲の指定 x:横, y:縦
# (今回はメータ4桁だったのでnumber1~4)
# number 1
x1_l = x_AR + 17 # 左上X
y1_l = y_AR - 8 # 左上Y
x1_r = x1_l + 30 # 右上X
y1_r = y1_l + 35 # 右上X
# number 2
x2_l = x1_l + 39
y2_l = y1_l
x2_r = x2_l + 30
y2_r = y2_l + 35
# number 3
x3_l = x2_l + 39
y3_l = y2_l
x3_r = x3_l + 30
y3_r = y3_l + 35
# number 4
x4_l = x3_l + 39
y4_l = y3_l
x4_r = x4_l + 30
y4_r = y4_l + 35
img_list = list(range(4*img_cnt+4))
img_list = img_list[-4:]
# Cut val_1
name = "imageFolder/" + str(img_list[0]) + ".jpg"
img1 = img[y1_l:y1_r, x1_l:x1_r]
cv2.imwrite(name, cv2.resize(img1,(x1_r-x1_l,y1_r-y1_l)))
# Cut val_2
name = "imageFolder/" + str(img_list[1]) + ".jpg"
img2 = img[y2_l:y2_r, x2_l:x2_r]
cv2.imwrite(name, cv2.resize(img2,(x2_r-x2_l,y2_r-y2_l)))
# Cut val_3
name = "imageFolder/" + str(img_list[2]) + ".jpg"
img3 = img[y3_l:y3_r, x3_l:x3_r]
cv2.imwrite(name, cv2.resize(img3,(x3_r-x3_l,y3_r-y3_l)))
# Cut val_4
name = "imageFolder/" + str(img_list[3]) + ".jpg"
img4 = img[y4_l:y4_r, x4_l:x4_r]
cv2.imwrite(name, cv2.resize(img4,(x4_r-x4_l,y4_r-y4_l)))
img_cnt += 1
# 今回は1時間に一回撮影(メータがそこそこ回る時間)
time.sleep(cycle)
cv2.destroyWindow("frame")
# 実行
if __name__ == '__main__':
meterImageSaver(camera_num=0, cycle=3600)
漂うクソコード臭ですね。リファクタリングは読者にお任せします![]()
ふむふむどんな感じか確認してみよう。とその前に、フォルダないにある画像データを
datasetsフォルダ内に、正解ラベルをつけて以下のようなフォルダ構造に保存。
(瞬時に画像を識別して正解を割り出す人間は凄いと再確認)
エラーデータもたくさん。アナログメータなので、数字と数字の間の瞬間はデータとして分類不可でした。
(これ後々の問題提起になります)
# フォルダー構造
datasets
├── 0
├── 1
.
.
└── 9
2日ほどプログラムを放置した結果...
取得できた数値データ↓
| 数値 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| 枚数 | 35 | 16 | 20 | 30 | 13 | 22 | 37 | 24 | 27 | 12 |
かなり偏りがあるけど仕方ない。
というかデータ少なすぎ??
「ないなら増やせばいいじゃない」ということで、省エネ万歳です。
データの水増しをしていきます。
データの水増し
データの水増しは色々と方法があります。
こちらが参考になります。
https://qiita.com/bohemian916/items/9630661cd5292240f8c7
- コントラスト変更
- ガンマ変換
- 平滑化
- ヒストグラム均一化
- 回転や反転
どれを使用しても良いですが、今回は回転や反転は使用しません。
回転してしまっては6と9が同じものになってしまったりするので。状況に応じて使い分けてください。
import cv2
import numpy as np
import sys
import os
# ヒストグラム均一化
def equalizeHistRGB(src):
RGB = cv2.split(src)
Blue = RGB[0]
Green = RGB[1]
Red = RGB[2]
for i in range(3):
cv2.equalizeHist(RGB[i])
img_hist = cv2.merge([RGB[0],RGB[1], RGB[2]])
return img_hist
# ガウシアンノイズ
def addGaussianNoise(src):
row,col,ch= src.shape
mean = 0
var = 0.1
sigma = 15
gauss = np.random.normal(mean,sigma,(row,col,ch))
gauss = gauss.reshape(row,col,ch)
noisy = src + gauss
return noisy
# salt&pepperノイズ
def addSaltPepperNoise(src):
row,col,ch = src.shape
s_vs_p = 0.5
amount = 0.004
out = src.copy()
# Salt mode
num_salt = np.ceil(amount * src.size * s_vs_p)
coords = [np.random.randint(0, i-1 , int(num_salt))
for i in src.shape]
out[coords[:-1]] = (255,255,255)
# Pepper mode
num_pepper = np.ceil(amount* src.size * (1. - s_vs_p))
coords = [np.random.randint(0, i-1 , int(num_pepper))
for i in src.shape]
out[coords[:-1]] = (0,0,0)
return out
if __name__ == '__main__':
# ルックアップテーブルの生成
min_table = 50
max_table = 205
diff_table = max_table - min_table
gamma1 = 0.75
gamma2 = 1.5
LUT_HC = np.arange(256, dtype = 'uint8' )
LUT_LC = np.arange(256, dtype = 'uint8' )
LUT_G1 = np.arange(256, dtype = 'uint8' )
LUT_G2 = np.arange(256, dtype = 'uint8' )
LUTs = []
# 平滑化用
average_square = (10,10)
# ハイコントラストLUT作成
for i in range(0, min_table):
LUT_HC[i] = 0
for i in range(min_table, max_table):
LUT_HC[i] = 255 * (i - min_table) / diff_table
for i in range(max_table, 255):
LUT_HC[i] = 255
# その他LUT作成
for i in range(256):
LUT_LC[i] = min_table + i * (diff_table) / 255
LUT_G1[i] = 255 * pow(float(i) / 255, 1.0 / gamma1)
LUT_G2[i] = 255 * pow(float(i) / 255, 1.0 / gamma2)
LUTs.append(LUT_HC)
LUTs.append(LUT_LC)
LUTs.append(LUT_G1)
LUTs.append(LUT_G2)
# 先ほど作成した画像データファイルごとに8倍に水増ししていく
DATADIR = "datasets/"
CATEGORIES = ["0", "1", "2", "3", "4", "5", "6", "7", "8", "9"]
for n, category in enumerate(CATEGORIES):
path = os.path.join(DATADIR, category)
print(path)
img_len = len(os.listdir(path))
# 連番を名付け
for i, pic in enumerate(os.listdir(path)):
os.rename(DATADIR + CATEGORIES[n] + "/" + pic, DATADIR + CATEGORIES[n] + "/" + str(i)+".jpg")
for num, image_name in enumerate(os.listdir(path)):
# 画像の読み込み
img_src = cv2.imread(os.path.join(path, image_name))
trans_img = []
trans_img.append(img_src)
# LUT変換(4種類)
for i, LUT in enumerate(LUTs):
trans_img.append(cv2.LUT(img_src, LUT))
# 平滑化(1種類)
trans_img.append(cv2.blur(img_src, average_square))
# ヒストグラム均一化(1種類)
trans_img.append(equalizeHistRGB(img_src))
# ノイズ付加(1種類)
trans_img.append(addGaussianNoise(img_src))
trans_img.append(addSaltPepperNoise(img_src))
# 保存(計8種類)
for i, img in enumerate(trans_img):
cv2.imwrite(path + "/" + str(i+num*8+img_len) + ".jpg" ,img)
なんということでしょう。画像データが爆増しました。これで学習できそうですね。
Before
| 数値 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| 枚数 | 35 | 16 | 20 | 30 | 13 | 22 | 37 | 24 | 27 | 12 |
After
| 数値 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| 枚数 | 280 | 128 | 160 | 240 | 104 | 176 | 296 | 192 | 216 | 96 |
余談ですが...
MNISTのような手書きデータの場合はこんな量では全く不足していますが、
決まった形の数値データであればこれくらいの枚数でも十分に学習可能と思います。
2. 学習させる/チューニングする
まずは取得してきたデータがどんな風になっているか確認。
ここからはJupyterなどのインターラクティブな開発環境を用いると可視化しながらできるのでおすすめ。
画像を確認
import matplotlib.pyplot as plt
import os
import cv2
DATADIR = "datasets/"
CATEGORIES = ["0", "1", "2", "3", "4", "5", "6", "7", "8"]
# CATEGORIES = ["0", "1", "2", "3", "4", "5", "6", "7", "8", "9"]
for category in CATEGORIES:
path = os.path.join(DATADIR, category)
print(path)
for image_name in os.listdir(path):
try:
img_array = cv2.imread(os.path.join(path, image_name), cv2.IMREAD_GRAYSCALE)
plt.imshow(img_array, cmap="gray")
plt.show()
break
except Exception as e:
pass
break
print(img_array.shape)
print(img_array)
お気づきでしょうか。CATEGORIESがコメントアウトされ、9のラベルフォルダが消されていることに。
作者はどうやら9の画像データを無くしてしまったそうだ。信じられない。
従って、0~8までの画像データで学習を進める。(もちろん9は認識不能となる![]() )
)
気を取り直して画像データを確認する。
0のラベルにある画像ファイルを可視化。この時、カラー情報は不要なので、グレースケール化しているので、
下の方に、画像の白黒明度を示す値を表示している。
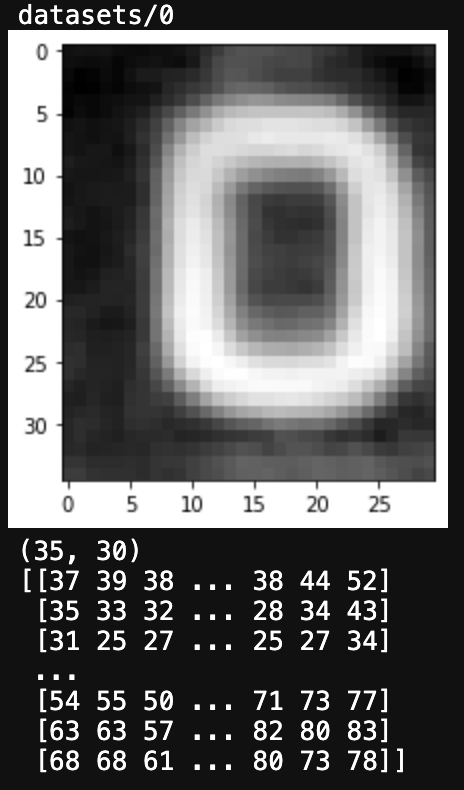
問題なさそう。
ラベルを確認
続いて、各ラベルフォルダ内に保存されているデータとラベルが一致するか確認しておく。
もちろん、9は除く![]()
import matplotlib.pyplot as plt
import os
import cv2
import random
import numpy as np
DATADIR = "datasets/"
CATEGORIES = ["0", "1", "2", "3", "4", "5", "6", "7", "8"]
# CATEGORIES = ["0", "1", "2", "3", "4", "5", "6", "7", "8", "9"]
IMG_SIZE = 28
training_data = []
def create_training_data():
for class_num, category in enumerate(CATEGORIES):
path = os.path.join(DATADIR, category)
for image_name in os.listdir(path):
try:
img_array = cv2.imread(os.path.join(path, image_name), cv2.IMREAD_GRAYSCALE) # 画像読み込み
img_resize_array = cv2.resize(img_array, (IMG_SIZE, IMG_SIZE)) # 画像のリサイズ
training_data.append([img_resize_array, class_num]) # 画像データ、ラベル情報を追加
except Exception as e:
pass
create_training_data()
random.shuffle(training_data) # データをシャッフル
X_train = [] # 画像データ
y_train = [] # ラベル情報
# データセット作成
for feature, label in training_data:
X_train.append(feature)
y_train.append(label)
# numpy配列に変換
X_train = np.array(X_train)
y_train = np.array(y_train)
# データセットの確認(全データをシャッフルした最初の4枚)
for i in range(0, 4):
print("学習データのラベル:", y_train[i])
plt.subplot(2, 2, i+1)
plt.axis('off')
plt.imshow(X_train[i], cmap='gray')
print(X_train.shape)
表示情報の意味
※ 学習データのラベル:フォルダの名前
※ (枚数、縦ピクセル、横ピクセル)
※ 読み込んだ画像

こちらも問題なさそう。
学習モデルの構築/チューニング
ここからが本番です。
今回は学習モデルにCNNを使用します。画像認識といえばCNNという単純な思考です。
今はもっと良いモデルもあるかもしれませんね。
自分はこちらの書籍でディープラーニングモデルについて勉強しました。とても理解しやすい。
https://www.amazon.co.jp/Python%E3%81%A8Keras%E3%81%AB%E3%82%88%E3%82%8B%E3%83%87%E3%82%A3%E3%83%BC%E3%83%97%E3%83%A9%E3%83%BC%E3%83%8B%E3%83%B3%E3%82%B0-Francois-Chollet/dp/4839964262
from keras.models import Sequential
from keras.layers.core import Dense, Activation, Flatten
from keras.layers import Conv2D, Reshape, MaxPooling2D, Dropout
from keras.utils import np_utils
import numpy as np
# モデル構築
# =============================================================
model = Sequential()
model.add(Reshape((28,28,1), input_shape=(28,28)))
model.add(Conv2D(32,(3,3)))
model.add(Activation("relu"))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(Flatten())
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.5))
# model.add(Dense(10, activation='softmax'))
model.add(Dense(9, activation='softmax'))
# =============================================================
X_train = np.array(X_train)/255 # 0-255の白黒のピクセル値を最大1に正規化する
y_train = np_utils.to_categorical(y_train) # [0,0,1,0,0,0,0,0,0,0]=>3の場合の変換例
# コンパイル
model.compile(loss="categorical_crossentropy", optimizer="sgd", metrics=["accuracy"])
# 学習実行
history = model.fit(X_train, y_train, batch_size=1, verbose=1, epochs=5, validation_split=0.1)
# モデルを保存
json_string = model.model.to_json()
open('recog_val.json', 'w').write(json_string)
# 重みの保存
hdf5_file = "recog_val.hdf5"
model.model.save_weights(hdf5_file)
結果はこちら。97.49%の正解率となった。まずまずだ。
しかし、この結果は幾度とモデルを見直した結果による。

勘のいい読者は下記の部分に気づかれたと思う。
0〜9までならこれでも良かったが、9を無くしてしまったからである。反省しろ。
# model.add(Dense(10, activation='softmax'))
可視化
上記の結果を一応可視化しておこう。見えなかった部分が見えてくるかもしれない。
# 学習結果を表示
import matplotlib.pyplot as plt
acc = model.history.history['accuracy']
val_acc = model.history.history['val_accuracy']
loss = model.history.history['loss']
val_loss = model.history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.figure()
上が正解率、下が損失を示している。
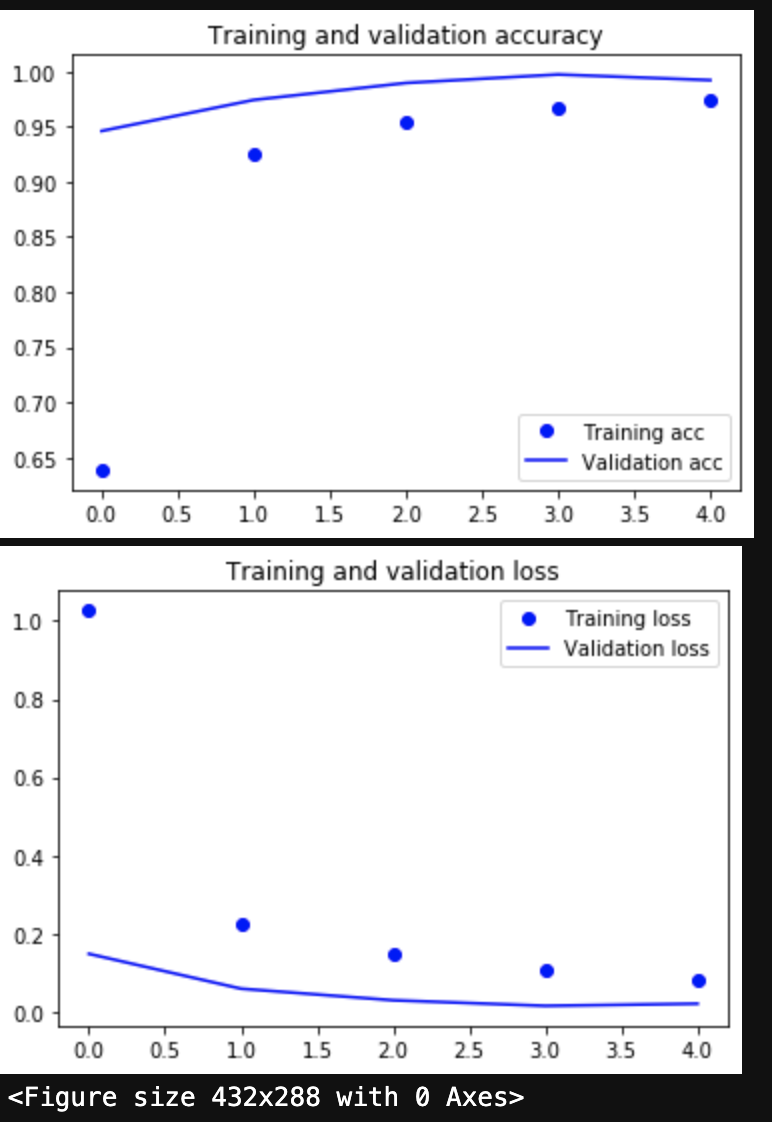
モデルはうまく構築され、評価された。これで行こう。
少し過学習によって正解率が落ち込んでいるが、安定して高い数値を出すことができた
モデルの為、採用した。本来はここからデータを追加したり、水増し方法を詰めたりと、でき
ることは山ほどあるが、今は結果を急ぐ。
3. テストする
ようやくここまで来た。最後に、テスト画像を用意して学習モデルを適用してみる。
この時、テスト画像は学習用に用いたデータを用いることは厳禁。カンニングになります。
では、テスト画像を3枚新たに撮影してきて、予測してみます。
from keras.datasets import mnist
from keras.layers import Dense, Dropout, Flatten, Activation
from keras.layers import Conv2D, MaxPooling2D
from keras.models import Sequential, load_model, model_from_json
from keras.utils.np_utils import to_categorical
from keras.utils.vis_utils import plot_model
import numpy as np
import cv2
import matplotlib.pyplot as plt
# モデルの読み込み
model = model_from_json(open('recog_val.json').read())
model.load_weights('recog_val.hdf5')
# テスト画像を準備
name1 = "val_1.jpg"
name2 = "val_2.jpg"
name3 = "val_3.jpg"
name = [name1, name2, name3]
for i in name:
img = cv2.imread(i)
# Grayed
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 28*28 resize
img = cv2.resize(img,(28, 28), cv2.INTER_CUBIC)
plt.imshow(img)
plt.show()
Xt = []
Xt.append(img)
Xt = np.array(Xt)/255 # 正規化
# 予測
result = model.predict_classes(Xt)
print("-----------------------------")
print(result)
print("-----------------------------")
なんとか予測できております。長い戦いでしたが、なんとかここまでできました。
これで完璧です。(9の認識は除く)
あとは省略しますが、上記のプログラムを一部修正し、画像を一定時間ごとに取得するコードを
追加すれば自動での画像取得、画像認識ソフトの完成です。
課題
お気づきの方もおられるとは思いますが、これで完璧とはなりません。なぜならば、前述したようにアナログメータには数値と数値の狭間という概念が存在します。
つまり、数字のドラムが回転している間に画像認識すると、とんでもない数字が認識される可能性があります。
4. 終わりに
最後までお付き合いありがとうございます。
恐らく、市販でこのようなアプリケーションを取り扱っている会社は多々あると思いますが、各社ごとに
学習方法やデータセットを強みとしているのだと思います。
今回のプログラムは、アナログメータのデジタル化の一例にすぎず、より良いものはゴマンとあります。
特に今時はクラウドサービスの一部に学習モデルの最適化などもやってくれるのもあったりなかったり。
画像認識を始めたばかりという方の参考になればと思います。