今の時代、自分が保持しているデジタルデータのバックアップは必須となっています。Qiitaの投稿だっていつ壊れるかわかったものじゃありません。というわけでAWS LambdaでQiita APIを叩いてバックアップを取る仕組みを作ります。
前提
- Qiita API V2を利用する
- AWS LambdaにPython3でスクリプトを書く
- バックアップ先はS3とする
- 定期実行を想定して重複するデータは再度のバックアップをしない(ちょっぴりインテリジェントに)
成果物
投稿の取得処理
Qiita APIのページにて開設されている通り、以下のようなURLで認証なしで投稿内容は取得ができますので、今回はこれを用います。
https://qiita.com/api/v2/users/{user_id}/items?page={page}&per_page=100
処理の中で100件以上を取得できるようにループをします。次ページの件数が0件になるまで繰り返します。
while is_loop:
url = QIITA_BASE_URL.format(user_id = name, page = page)
result = requests.get(url)
result_json = json.loads(result.text)
response_json.extend(result_json)
page+=1
if len(result_json) == 0:
is_loop = False
取得した処理の中身を確認し、URL(識別子とする)を抽出し、配列にします。後ほど同様にS3に保存されている保存済みURLリスト(JSON配列)も、こちらでURLのみの配列に変換します。
def extract_keys_as_array(target_json_array, key):
result_array = []
for target in target_json_array:
result_array.append(target[key])
return result_array
で、既にS3に保存されている(2回目以降は)のJSONデータと比較し、過不足があるかを確認します。過不足がなければ何もしないようにします。S3からの取得処理はこんな感じになりまs。
def get_topics():
json_file = SETTING_FILE_NAME + ".json"
response_data = []
try:
response = s3_client.get_object(Bucket=S3_BUCKET, Key=json_file)
response_data = json.loads(response['Body'].read())
except botocore.exceptions.ClientError as ex:
if ex.response['Error']['Code'] == 'NoSuchKey':
print("No Objects.")
return response_data
保存されているURLのリストが現在のトピックと一緒かどうかの判断は下記になります。
def is_same_topics(org_topics_array, target_array):
is_same = True
for org in org_topics_array:
if org in target_array:
target_array.remove(org)
else:
is_same = False
break
return is_same
過不足がある場合は新しいトピックがあるとみなし、JSONをS3に保存するようにします。ついでに保存済みURLのリストも更新するようにします。
def put_data_to_s3(contents, file_name):
tmp_dir = "/tmp/"
tmp_file = file_name + ".json"
with open(tmp_dir + tmp_file, 'w') as file:
file.write(json.dumps(contents, ensure_ascii=False, indent=4, sort_keys=True, separators=(',', ': ')))
s3_client.upload_file(tmp_dir + tmp_file, S3_BUCKET, tmp_file)
return True
呼び出し元はこんな感じです。
def run(event, context):
result = "No need to update."
response_json = get_qiita_post(event['name'])
org_topics = get_topics()
if len(org_topics) > 0:
target_array = extract_keys_as_array(response_json, 'url')
org_array = extract_keys_as_array(org_topics, 'url')
if not is_same_topics(org_array, target_array):
put_data_to_s3(response_json, BACKUP_FILE_NAME)
put_data_to_s3(extract_keys_as_json(response_json, 'url'), SETTING_FILE_NAME)
result = "Update finished."
return result
実行してみる
1回目は保存されましたが、2回目は既にあるURLのリストとS3に保存されているURLのリストが同じになるため、保存は実行されませんでした。
$ sls invoke local -f run -d '{"name": "kojiisd"}'
"Update finished."
$ sls invoke local -f run -d '{"name": "kojiisd"}'
"No need to update."
こんな感じでS3の方には無事保存されました。(ファイル名は環境変数で指定できるようになっています)
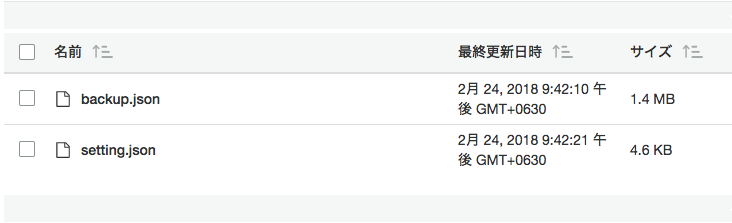
まとめ
ひとまず必要な情報の保存はできるようになりました。今回はS3を保存先にしましたが、インタフェースを変更することでDynamoDBなどの他のストレージへの保存も簡単に実現できそうです。あとはこのスクリプトを定期実行するようにLambdaのスケジューラでも設定すれば、いつでもQiitaのバックアップは取れるようになります。