昨日の記事で、echizen_tmさんはstring attractorsとLZ77の関係を説明しました。今日は圧縮の話を続けましょう。
はじめに
去年のアドベントカレンダーではいろいろデータ圧縮算法が紹介されていました。 しかし、データ圧縮アルゴリズムは圧縮アプリの一部でしかありません。 データ圧縮の能力は圧縮アルゴリズムとエンコーディングとの組み合わせです。その組み合わせを実験的に編み出すために、いろいろエンコーディングとエンコーディングパラメーターを合わせて調査するものです。
つまり、新しい圧縮アプリを作ることは大変です。 簡単に圧縮アルゴリズムの実装をエンコーディングに組み合わることができる道具が必要です。 そのために、tudocomp (発音:ツードーコンプ)が生まれました1。 tudocompはC++14のテンプレートライブラリーです。 LZ77といった有名な算法とhuffmanといった一般的なエンコーディングがtudocompで実装されています。 C++のテンプレートのお陰で、この組み合わせはとても簡単になります。
定義
tudocompではデータ圧縮的な単語を利用しています。 その単語を紹介しましょう。
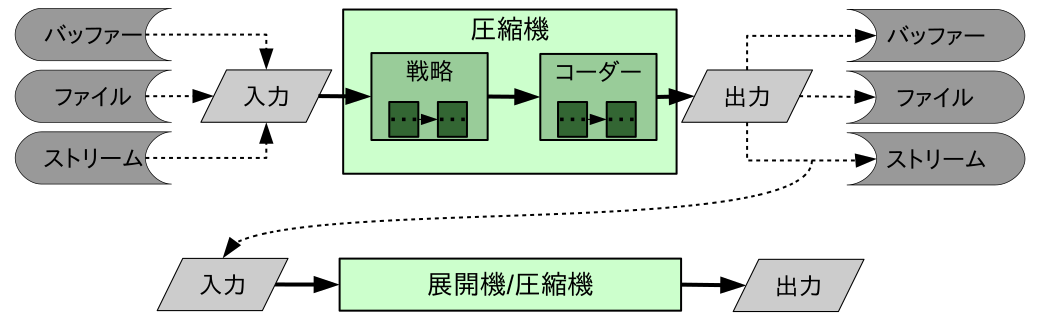
まず、圧縮アルゴリズムの実装は圧縮機(英語: compressor)と、 圧縮したデータを修復できる実装は展開機(英語:decompressor)と呼ばれます。それぞれの圧縮機は指定の展開機を持っています。
エンコーディングを作ることができる部分はコーダ(英語:coder)です。
圧縮機とコーダ以外の組み合わせられる物も作ることができます。これは戦略(英語:strategy)と言われています。圧縮機とコーダーあと、どちらも任意の数の戦略を持つことができます。
次の図で、I/Oと定義した部分をどうやって組み合わせることができるかを示しています:
最初のステップ
LinuxかMacがあれば、tudocompは以下の方法で組み込めます。まず、次のアプリが必要です:
- cmake (バーション 3.7.2以上)
- gcc (バーション 6.3以上) かclang (バーション 4.0以上)
以下のコマンドでtudocompをコンパイルできます。
git clone https://github.com/tudocomp/tudocomp.git
mkdir build && cd build
cmake ..
make
registry
このコマンドは全部の実装した圧縮機とコーダーを直積集合に組み合わせますから、最後のコマンドは早くないパソコンではたくさん時間がかかってしまいます。 この直積集合の部分はregistryで執筆しています。 tudocompのregistryはパイソンで書いてあるスクリプトです。 初期設定のregistryはtudocomp/etc/registries/all_algorithms.pyというファイルです。 このフォルダーでほかの使えるregistryが置いてあります。registryは基本的に配列で編成されていますから、自分に新しいregistryを作るのは問題ではありません。
使用方法の紹介
コンパイルの最後にtudocomp/build/tdcというコマンド行のアプリが作られます。 このアプリで、任意のregistryで書いた合同が使えます。 そのために、tdcのパラメータ-aで使って欲しい圧縮機の名前を入力できます。 例えば、tdc -a 'lzss_lcp(coder=ascii)' file.txtはfile.txtを読み込んで、lzss_lcpの圧縮機を使って、lzss_lcpの出力をasciiというコーダでエンコーディングして、file.txt.tdcに出力を書き込みます。
さらに、任意の圧縮法と任意の圧縮法は「:」で組み合わせできます。 例えば、bwt:rleはbwtの出力をrleの入力にします。 rleという圧縮機は戦略を持っていませんから、コーダーを直接に書くことはできません。 その代わりに、encodeというメタ圧縮機が利用できます。 rle:encode(ascii)はrleの出力をasciiでエンコーディングします。 I/Oをストリームしたい場合は、--usestinか--usestdoutというパラメタを利用できます。
最後に、-dというパラメタで圧縮したファイルを展開できます。 この時、ファイルの圧縮形式を指定する必要はありません。 tudocompは圧縮したファイルのヘッダーに圧縮方法を書き込みますので、自動的に展開できます。 そのヘッダーは場所を取るので、ヘッダーなしのオプションもあります。 そのオプションは--rawというパラメタで選択できます。
使用例
以下の例でxxdという2進文字のビューアを使います。 我々の例文はabracadabraabracadabraです。 日本語の文も入力できますが、tudocompは入力をバイト列として扱っていますから、出力を分解することは大変そうです。
まずはただの例文です:
echo "abracadabraabracadabra" | xxd
出力は
00000000: 6162 7261 6361 6461 6272 6161 6272 6163 abracadabraabrac
00000010: 6164 6162 7261 0a adabra.
同じ出力をecho "abracadabraabracadabra" | ./tdc -a 'noop' --usestdin --usestdout --raw | xxdで産出できます。 noopという圧縮機は入力をそのままに出力します。
次、bwtを利用します:
echo "abracadabraabracadabra" | ./tdc -a 'bwt' --usestdin --usestdout --raw | xxd
bwtは、入力の終わりにヌルバイトが付いていることを期待します。 この例では、ヌルバイトが入力されていませんので、tudocompは自動的にこのバイトを追加します。 出力は、bwtでは入力の並べ替えになります。
00000000: 0a61 7272 6464 6100 7272 6363 6161 6161 .arrdda.rrccaaaa
00000010: 6161 6161 6262 6262 aaaabbbb
bwtの出力をランレングス圧縮してほしければ、次のように書きます:
echo "abracadabraabracadabra" | ./tdc -a 'bwt:rle' --usestdin --usestdout --raw | xxd
rleは同じ文字の連続を文字の数で略すということです。 つまり、$x \ge 3$のとき$y:= x-2$をすると、$a^x$が現れると、$a^x$を$aay$に書き換えます。 例えば、最後のbの連長はbb2に略しました。(2という数字は2進で書いてある)
00000000: 0a61 7272 0064 6400 6100 7272 0063 6300 .arr.dd.a.rr.cc.
00000010: 6161 0662 6202 aa.bb.
最後に、huffmanでランレングス圧縮した入力をエンコーディングします。
echo "abracadabraabracadabra" | ./tdc -a 'bwt:rle:encode(huff)' --usestdin --usestdout --raw
入力が短いせいで、コーダーなしに比べて出力のほうが長くなってしまいました。
00000000: 8200 0100 8304 8039 3081 0305 3131 b213 .......90...11..
00000010: f956 77c8 9362 6603 .Vw..bf.
使われる圧縮機とコーダー
現在のtudocompでは、有名な圧縮アルゴリズムの実装が利用できます。
辞書圧縮2
文法圧縮
- Re-Pair
- ESP7, locally sensitive parsingのような方法
コーダー
- Elias γ
gamma - Elias δ
delta - Huffman
huff
練習
LZ77/LZ78についての記事を参考に、 LZSSとLZ78それぞれの分解をabracadabraabracadabraという例文に適用してみましょう。 幸せに、tudocompでとある分解を計算して、チェックできます。
echo 'abracadabraabracadabra' | ./tdc -a 'lzss_lcp(didactic,threshold=1)' --usestdin --usestdout --raw
-> abr{0, 1}c{3, 1}d{0, 4}{0, 11}
echo 'abracadabraabracadabra' | ./tdc -a 'lz78(ascii)' --usestdout --usestdin --raw
-> 0:a0:b0:r1:c1:d1:b3:a6:r4:a0:d8:a0:
この出力で$i:c$を$(i,c),$に翻訳したら出力を理解しやすいです。 ($i$は一番長い照合している前のfactorの指数、cは続きの文字)
おわりに
この記事ではデータ圧縮アプリの実装について紹介しました。 tudocompというC++で書いてあるライブラリーで簡単に新しい圧縮アプリを作ることができます。 そのために、コマンド行で圧縮機とコーダーをアドリブで組み合わせできます。 圧縮アプリをはじめ、圧縮アルゴリズム、コーダーを作りたいというとき、いろいろ圧縮方法を比べてみたいというときには、tudocompを試してください。
-
Patrick Dinklage, Johannes Fischer, Dominik Köppl, Marvin Löbel, and Kunihiko Sadakane: Compression with the tudocomp Framework. Proc. SEA, LIPIcs 75, pages 13:1-13:22, 2017. ↩
-
じつは、kgotoさんはLZ77についての記事でこのバリアントをLZ77で呼びます。 ↩
-
James Storer, Thomas Szymanski: Data Compression via Textual Substitution, Journal of the ACM. 29 (4): 928–951, 1982. ↩
-
Dominik Köppl and Kunihiko Sadakane: Lempel-Ziv Computation in Compressed Space (LZ-CICS). Proc. DCC, pages 3-12, 2016. ↩ ↩2
-
Jacob Ziv, Abraham Lempel: Compression of individual sequences via variable-rate coding. IEEE Trans. Information Theory 24(5): 530-536, 1978. ↩
-
Welch, Terry: A Technique for High-Performance Data Compression. Computer. 17 (6): 8–19, 1984. ↩
-
Graham Cormode, S. Muthukrishnan: The string edit distance matching problem with moves. ACM Trans. Algorithms 3(1): 2:1-2:19, 2007. ↩