はじめに
本記事は、計三回に渡ってお送りしている、RoCEv2を用いた実機検証シリーズの第三回目の記事となります。
第二回目となる前回は、Ethernet上にロスレスネットワークを構築する上での前提となる、ネットワーク側(Cisco Nexus)の具体的な機能の話について流れを追って解説しました。
当シリーズの最終回となる本記事では、実際にパケットジェネレータを使用してRoCEv2トラフィックを生成し、前回の記事で取り扱った各種設定(QoS/負荷分散)の動作について詳しく確認していきます。
検証環境
・物理構成図
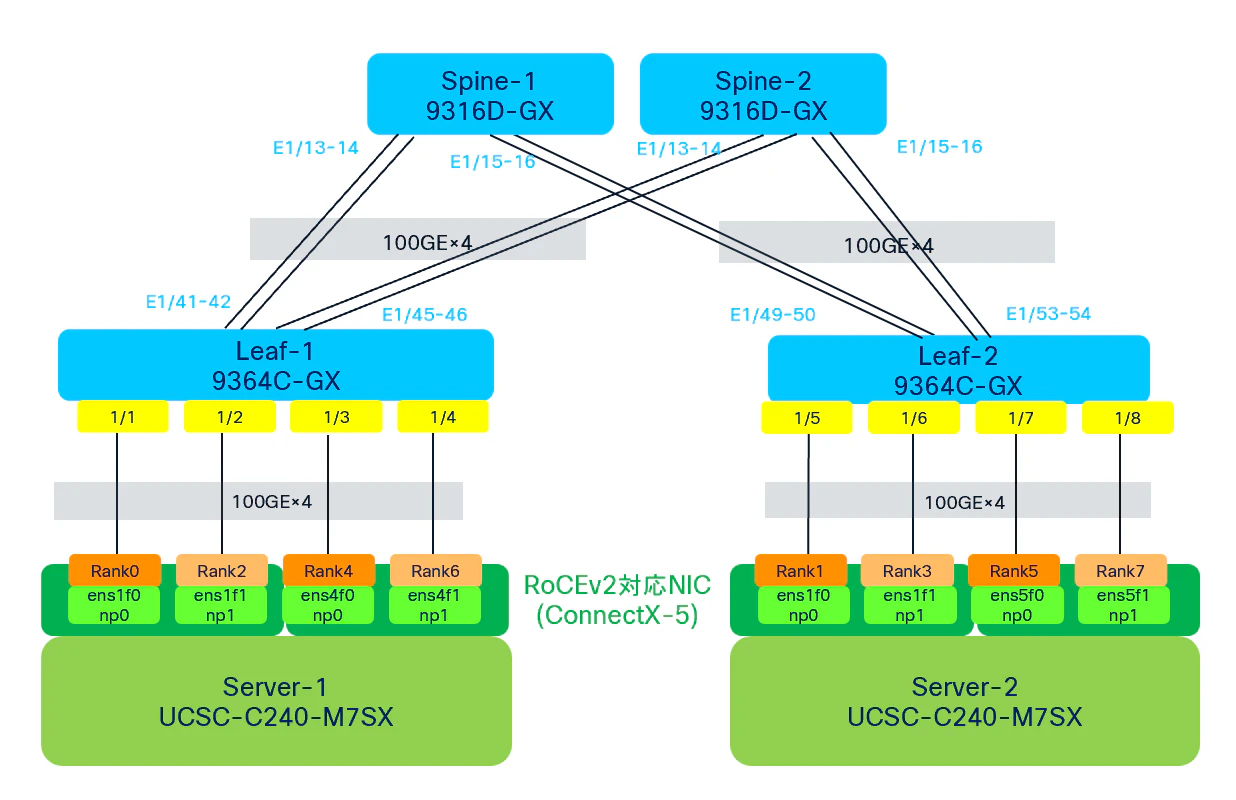
・使用機器
Switch
Leaf:Cisco Nexus 9364C-GX ×2
Spine:Cisco Nexus C9316D-GX ×2
Leaf-SpineによるFabric構成を採用し、Leaf-Spine間はOSPFによるECMP(Equal-Cost Multi-Path)を用いて接続。
Server
・Cisco UCS C240 M7SX ×2
・OS:Ubuntu 22.04 LTS
各サーバにはRoCEv2対応NICを4ポート搭載し、100GbE ×4でLeafスイッチへ接続。
RoCEv2対応NIC
・NVIDIA Mellanox ConnectX-5
RoCEv2によるRDMA通信を行い、PFCおよびECN/DCQCNによる輻輳制御を実施。
(※今回の検証では、後述するトラフィックジェネレータを使用してRDMAトラフィックを生成します。このジェネレータと上記NICを連携させることで、実際にGPUを使用せずともRoCEv2トラフィックを生成可能となります。)
Keysight KAI Data Center Builder
RDMAトラフィックを生成するためのトラフィックジェネレータとして、Keysight社が提供する「AI Data Center Builder(以後、Builderと記載)」を使用します。
このソリューションは、GPU間で発生する大量のRoCEv2トラフィックを模擬再現し、帯域・遅延・混雑状況を計測することが出来ます。
これを活用することで、AIデータセンターネットワーク上のボトルネックを可視化し、最適なネットワーク設計を支援することが可能になります。
本ソリューションにはハードウェア版とソフトウェア版がありますが、今回はソフトウェア版をUbuntuサーバ上にインストールし、RoCEv2テストトラフィックを生成します。
(参考)Builderの内部コンポネント
1. DFE Software(データプレーン)
- NICと連携し、RoCEv2トラフィックを生成する役割を担う。
2. DSE Controller(コントロールプレーン)
- Dockerコンテナ上で動作し、シミュレーションに関する設定やテスト結果の管理を行う
3. License Server(ライセンス管理)
- KVMまたはVMware上で動作し、ライセンス管理を担う。
(今回は仮想環境としてKVMを使用)
※ 1は上述のサーバ二台それぞれにインストール
※ 2と3はトラフィックを流すサーバとは別にサーバを一台用意(Cisco UCS C220 M6)しインストール。
1のDFE Software側とやり取りすることで各種必要な情報のやり取りを行う。
※(ご参考)Keysight社「AI Data Center Builder」公式URL
https://www.keysight.com/jp/ja/cmp/kai.html
☆本記事で登場する"Rank"という概念について
Rankとは、分散処理において使用する論理的なIDのことであり、分散処理ソフトウェアが通信を制御する際に「誰がどの相手と通信するか」や「どのデータをやり取りするか」等を制御するために使用されます。
本検証では、GPU同士での勾配データのやり取りをシミュレートするためにこの概念を使用します。今回の環境では、RankとGPU(およびNIC)は一対一に対応するよう設定しています。
検証シナリオ
今回は以下の流れで検証を実施します。
(1) 輻輳制御技術の効果測定
RoCEv2トラフィック向けに設定した各種QoS機能が、想定通り動作するかを確認します。
1. DCQCNの動作確認
具体的には、前回の記事で説明した一連の動作(スイッチ側でECNが発行され、それを受けたサーバ側NICがCNPパケットを送信する流れ)を観察します。
2. PFCの設定ON/OFFによるパケットロス発生の有無の観察
PFCの有効/無効を切り替えながら、RoCEv2通信におけるパケットロス発生状況を確認します。
※ 尚、本効果測定時のロードバランス手法は、Flowlet DLBで固定して実施します。
(2) 各ロードバランシング手法の動作確認 + 通信効率の比較
今回は、ロードバランス手法として以下4種類を使用し、それぞれの動作および通信効率を比較します。
・5-tuple ECMP
・Flowlet DLB
・Per Packet DLB
・Static Pinning
※ 尚、この検証ではPFC/ECNは常時有効化した状態で実施します。
ロードバランスの性能測定指標
各ロードバランス手法の性能比較には、CV(Coefficient of Variation:変動係数)を使用します。
CVは、「各リンクへどれだけ均等にトラフィックを分散できたか」を定量的に評価するための指標です。
本検証では、各Leaf-Spine間リンクにおける送信Byte数(Tx Bytes)を取得し、以下を計算します。
・平均
・標準偏差
その後、以下の式でCVを算出します。
・CV = 標準偏差 ÷ 平均
CVは値が小さいほど、各リンクへ均等にトラフィックが分散されていることを意味します。
つまり、CVが0に近いほど理想的なロードバランス状態と言えます。
(例1)均等に分散されている場合
Link1:25 GB
Link2:25 GB
Link3:25 GB
Link4:25 GB
この場合、各リンクへ均等に通信が分散されているため、標準偏差は0となり、CVも0になります。
(例2)偏りがある場合
一方で、以下のように通信量に偏りがある場合は、CVが大きくなります。
Link1:70 GB
Link2:20 GB
Link3:5 GB
Link4:5 GB
本検証では、各Leaf-Spine間リンクのTx Byte数を取得し、その分散度合いをCVで比較することで、各ロードバランス手法がどの程度均等にFabric全体へトラフィックを分散できているかを評価します。
(参考) 今回の検証で使用するトラフィックについて
今回使用するトラフィックジェネレータでは様々なパラメータを指定できるようになっており、本検証では以下の項目をGUI上で設定しています。
トラフィックパターン:Ring All Reduce
NCCLベースのAI学習環境で代表的に使用される通信パターンとなります。
(Ring All Reduce通信の特徴については第一回目の記事で解説)
1回のテストで流す総トラフィック量:1.56 TB
本検証では、1回のテストで約1.56TB相当の通信をFabric内へ流しています。
これは単一フローの通信量ではなく、All Reduce通信全体としてFabric内部を流れる総通信量を表しています。
RDMA Message Size:32 MB
RDMA Message Sizeは、1回のRDMA通信で送信されるデータの塊(チャンク)のサイズを表します。
今回指定した32MBというサイズは、ディープラーニングにおける勾配同期の文脈で、比較的大きなデータチャンクを効率良く転送するために一般的に使用されるサイズの一例です。
QP(Queue Pair)数:1
QP(Queue Pair)は、RDMA通信における通信単位です。
RoCEv2では、基本的に「1つのQP = 1つのRDMAフロー」として考えることができます。
今回はQP数を1本に設定しているため、ECMPハッシュ計算に使用される情報のばらつきが少なく、特定リンクへ通信が偏りやすい条件となっています。
そのため、各ロードバランシング手法による差異が比較的現れやすい構成になっていると考えられます。
検証結果
(1) 輻輳制御技術の効果測定
ECN/PFCそれぞれの設定有無を変更しながら、トラフィックの挙動を計測した結果を整理したものが下図になります。
まずは、DCQCN/PFCが期待通り動作することを確認するため、ECN/PFCを共にONにした状態(赤枠)の結果を見てみます。
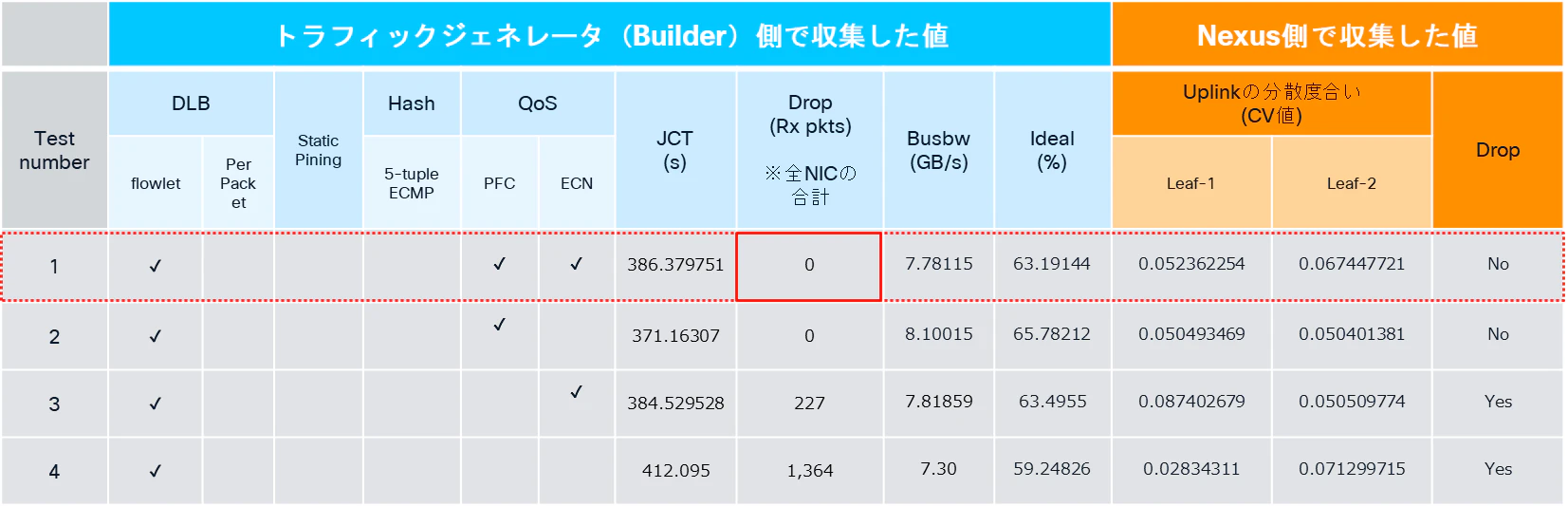
図中のDrop (Rx pkts) の列を確認すると、Drop=0となっていることが分かります。
また、その下の行(Test number=2)、すなわちECNを無効化し、PFCのみをONにした場合でも、Drop=0となっていることが確認できます。
つまり、PFCが有効である場合には、ロスレス通信を実現できていることが分かります。
この結果は前回の記事で解説したPFCの役割と一致しており、期待通り動作していることを確認できました。
☆PFCがOFFの場合
PFCがOFFの場合,ECNのON/OFFに関わらず、Server側/Nexus側の双方でパケットドロップを観測しました。
一方で細かく見ると、ECNがONの場合には、ECNをOFFにした場合と比較して、ドロップ数が比較的抑えられていることも確認できます。
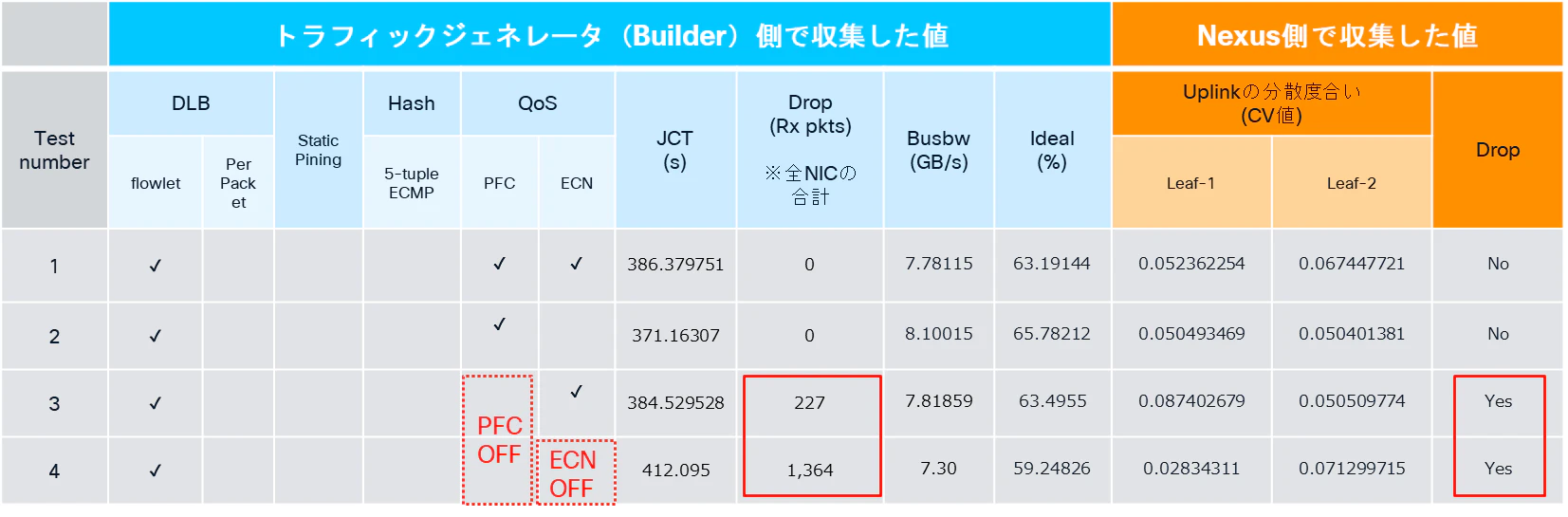
これは、DCQCNの仕組みによって、Server側NICがRDMAトラフィック送出時のレートを制御し、その結果として、スイッチ側バッファの逼迫度合いを一定程度緩和できているためと考えられます。
・ジョブ完了時間(JCT=Job Completion Time)の観点
ジョブ完了時間(JCT)の観点では、ECN/PFCを共に無効化した場合に、最もJCTが長い結果(約412秒)となりました。
ただし、PFC/ECNを共に有効化した場合(約386秒)と比較すると、今回の検証では劇的な差が発生しているわけではないように見えます。
この結果には様々な要因が関係していると考えられますが、例えば、テスト時の総トラフィック量や、All-Reduce通信へ参加するGPU数を増加させた場合、パケットドロップによる影響はより顕著になり、結果としてJCTへ与える影響も大きくなっていく可能性があると考えています。
1. DCQCNの動作確認
(DCQCNの動作フローについては前回の記事で解説)
ECN/PFCを共にONにした場合(Test number=1)について、DCQCNが実際に動作する様子を追ってみます。
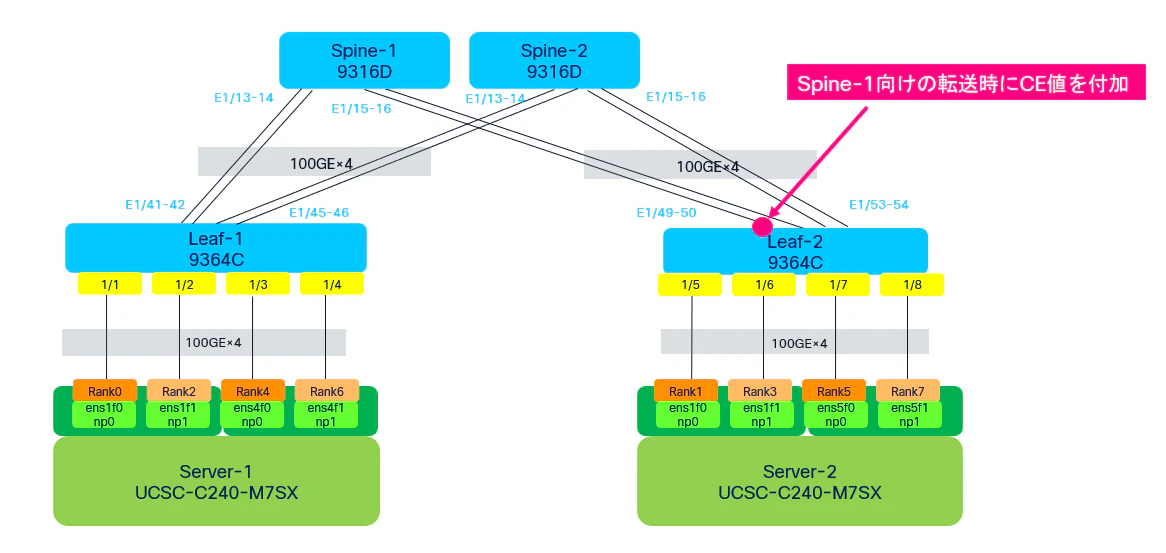
・show queuing interface ethernet 1/49(Leaf2のSpine2向け出力ポート)
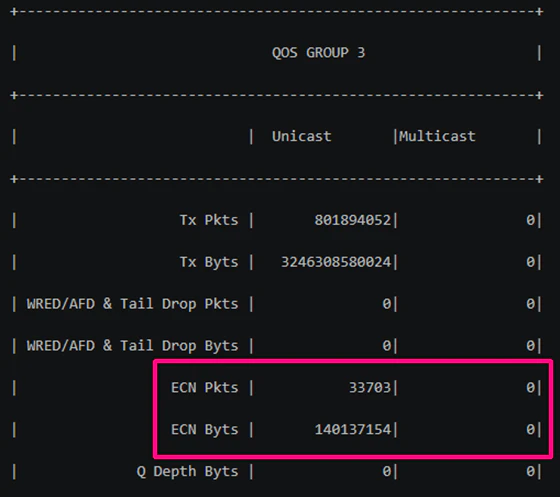
Server-2側から受信したRoCEv2トラフィックをLeaf2がSpine-2側へ転送する際、Spine-2向け出力キューにおいてECNが発動し、データパケットへCEマークが付与されている様子です。
つまり、Spine-2向け出力バッファにおける輻輳状況が、一定の閾値を超えた状態であることを意味しています。
・Server1のNICから出されたPriotiry6のパケットカウント(BuilderのGUIより)
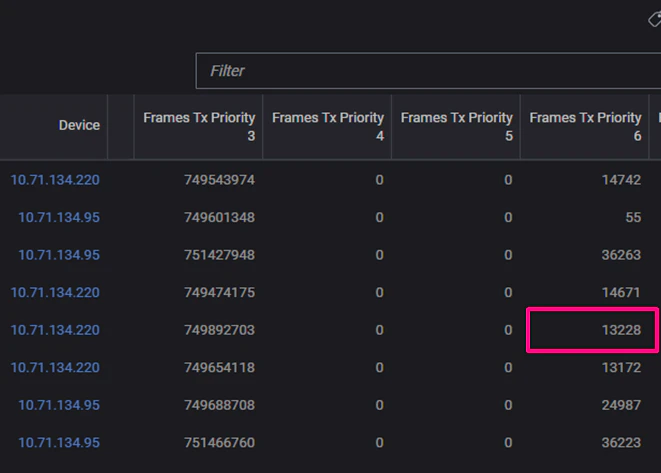
本環境では、各Serverにおいて、CNPパケットへPriority6を付与するよう設定しています。
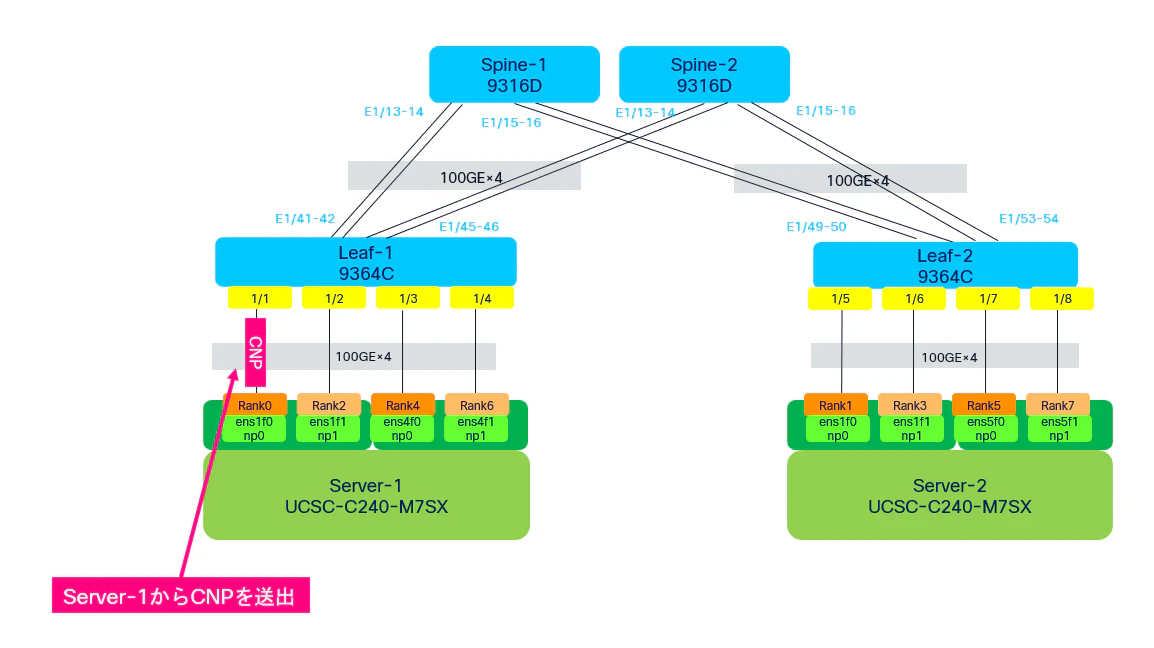
つまり、この結果は、Server1からServer2へ向けてCNPを送信している状態を示しています。
一つ前のフェーズでは、Server1はLeaf2側からCEマーク付きデータパケットを受信していました。
Server1はこれにより、Leaf2側で一定の輻輳が発生していることを認識します。
その後、Server1はServer2側へCNPを送信することで、RDMAトラフィック送出レートを低下させるよう通知しているのです。
・show policy-map interface ethernet 1/1(Server1からの受信ポート)
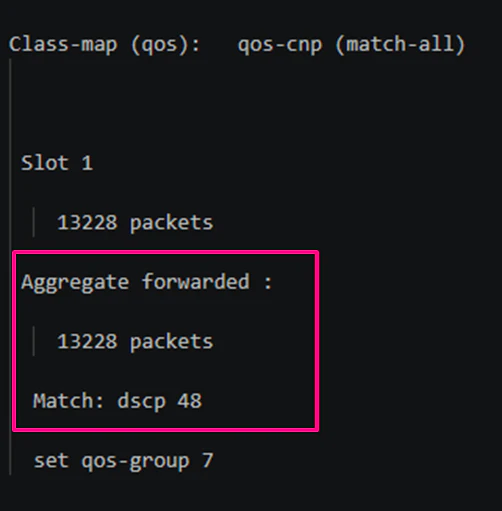
Server1から送信されたCNPパケットについても、Leaf1側受信インターフェースのカウンタから確認できます。
2. PFCの動作確認
Nexus側 (Spine-2)
・show interface priority-flow-control
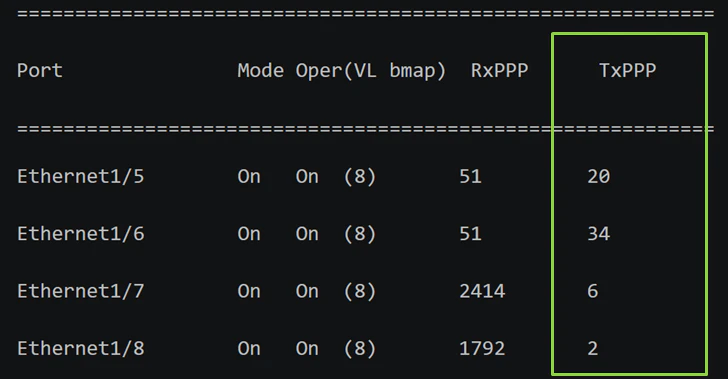
DCQCNによってServer側の送信レートを一定期間低下させた後も輻輳が継続し、Leaf側出力バッファが閾値へ到達しそうになると、PFCが発動します。
今回は、Nexus2から対向Serverへ向けてPause Frameが送信されている様子を確認できます。
Server2側の観測結果(BuilderのGUIより)
・Nexus2側からのPause Frameを受信している様子(各行はServer-2の各NICに対応)
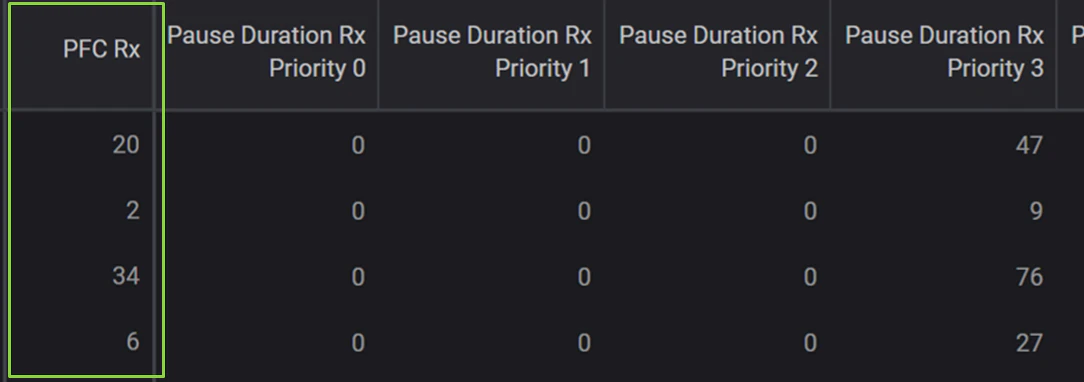
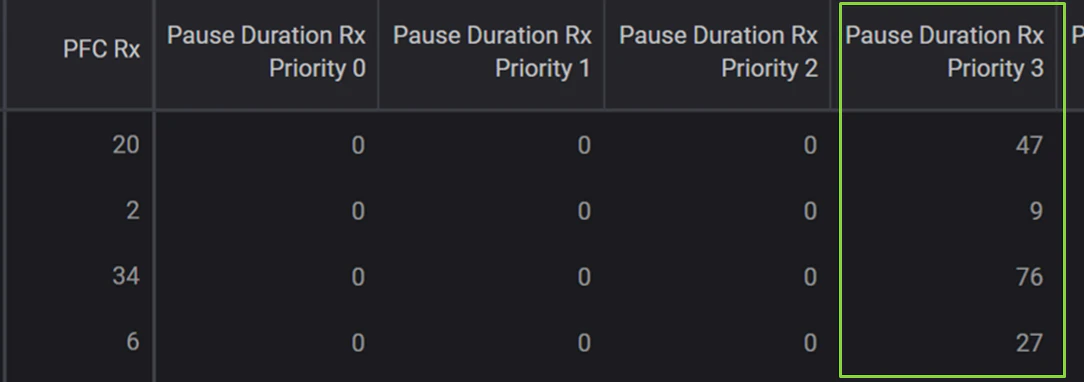
・Pause Frameの受信をトリガーに,RDMAトラフィックの送出を一定期間 (Pause Duration) 停止している様子
(2) ロードバランス手法ごとの分散度合い(CV値)と通信効率比較
・ECN/PFCをONにした状態で、各ロードバランス手法の計測結果をまとめたものが以下になります。
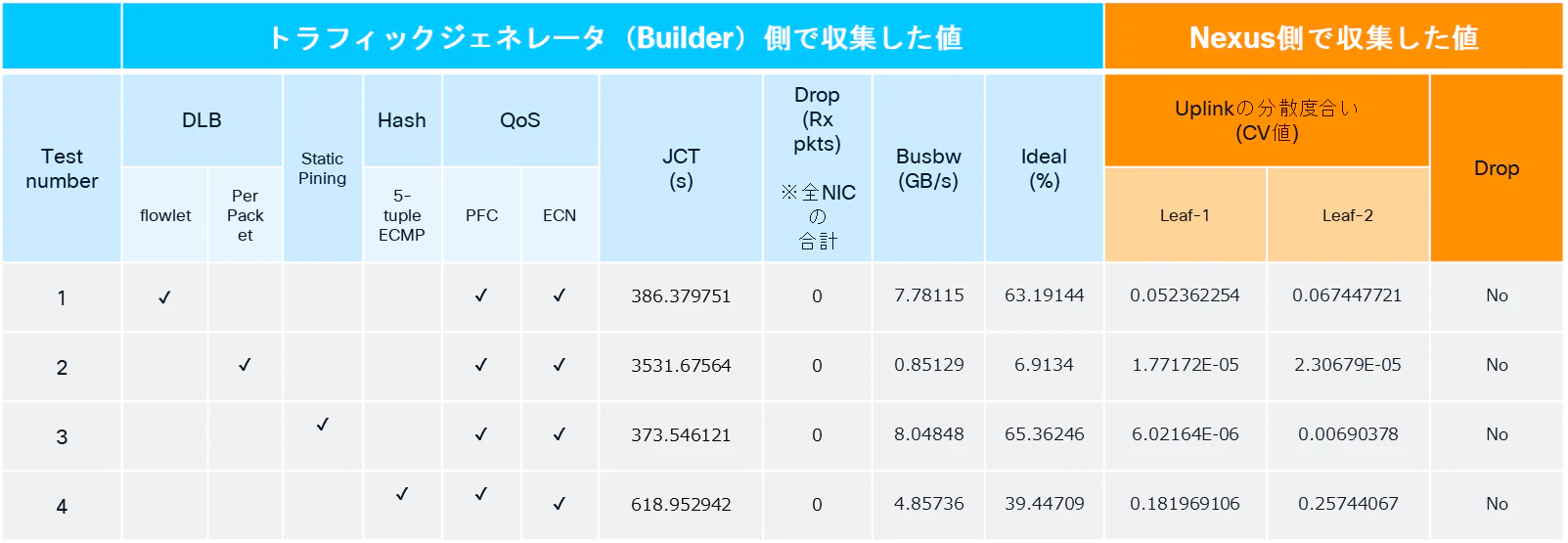
CV値の比較
(1) 5-tuple ECMPの場合
まず一つ目のポイントは、5-tuple ECMPによる負荷分散時のCV値です(下図緑枠)。
Leaf1/Leaf2共に、他手法と比較してCV値が高くなっていることが分かります。
これは、リンク間でトラフィックを均等に分散できていないことを意味しています。
その結果、ジョブ完了時間(Job Completion Time = JCT)についても、同じフローベース負荷分散であるFlowlet DLBと比較して長くなっていることが確認できます。
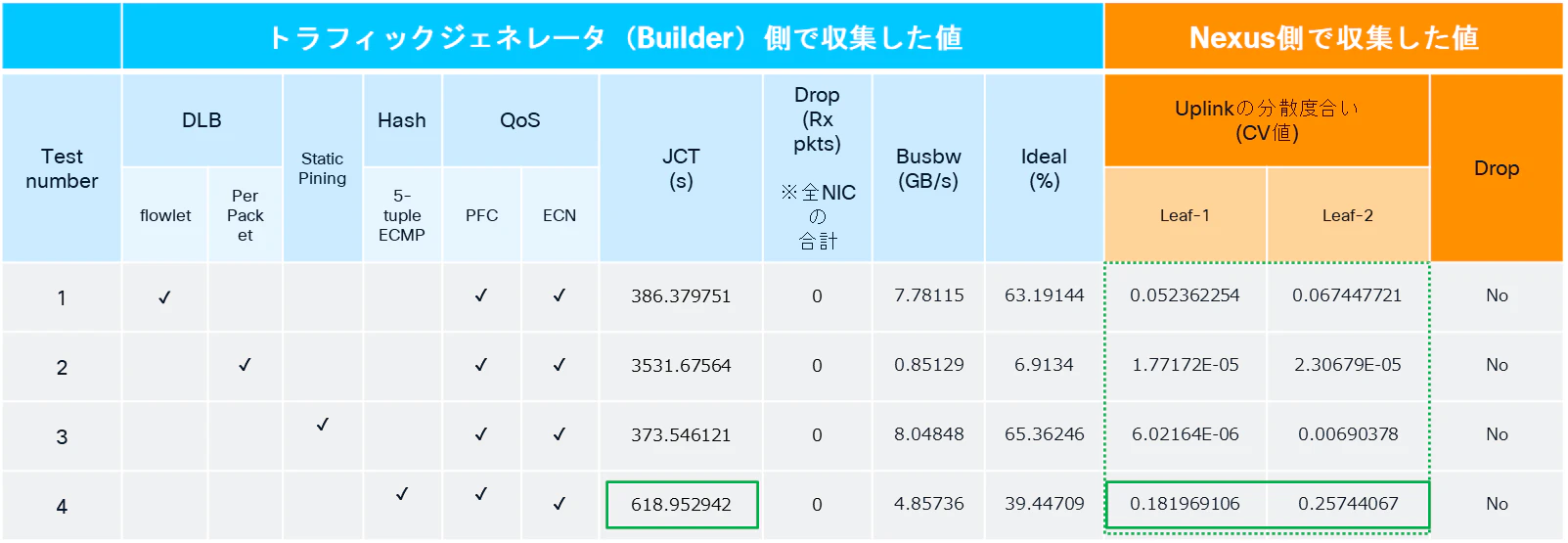
このような結果となった要因としては、5-tuple ECMPでは、5-tupleが同一である限り、同一フローが常に同じ物理リンクを通過し続けることに起因すると考えられます。
本検証環境では、
・5-tupleが同じ=RDMAフローが同じ
ことを意味します。
つまり、同一RDMAフローは、通信中を通して同一経路を利用し続けることになります。
その結果、フローごとに利用経路や混雑状況へ偏りが生じ、送信元NICから宛先NICへ到達するまでの時間差が発生しやすくなります。
前回の記事でも解説した通り、All-Reduce通信では、各Rank(GPU)間で同期を取りながら処理が進行します。
そのため、今回のようなRank間到着時間のばらつきが、ジョブ完了時間全体を大きく悪化させる結果につながったものと推測できます。
(2) Per Packet DLB / Static Pinningの場合
一方で、Per Packet DLBおよびStatic Pinningについては、CV値が非常に低く、ほぼ均等にトラフィックを分散できていることが分かります。
(①がPer Packet DLB、②がStatic Pinning)
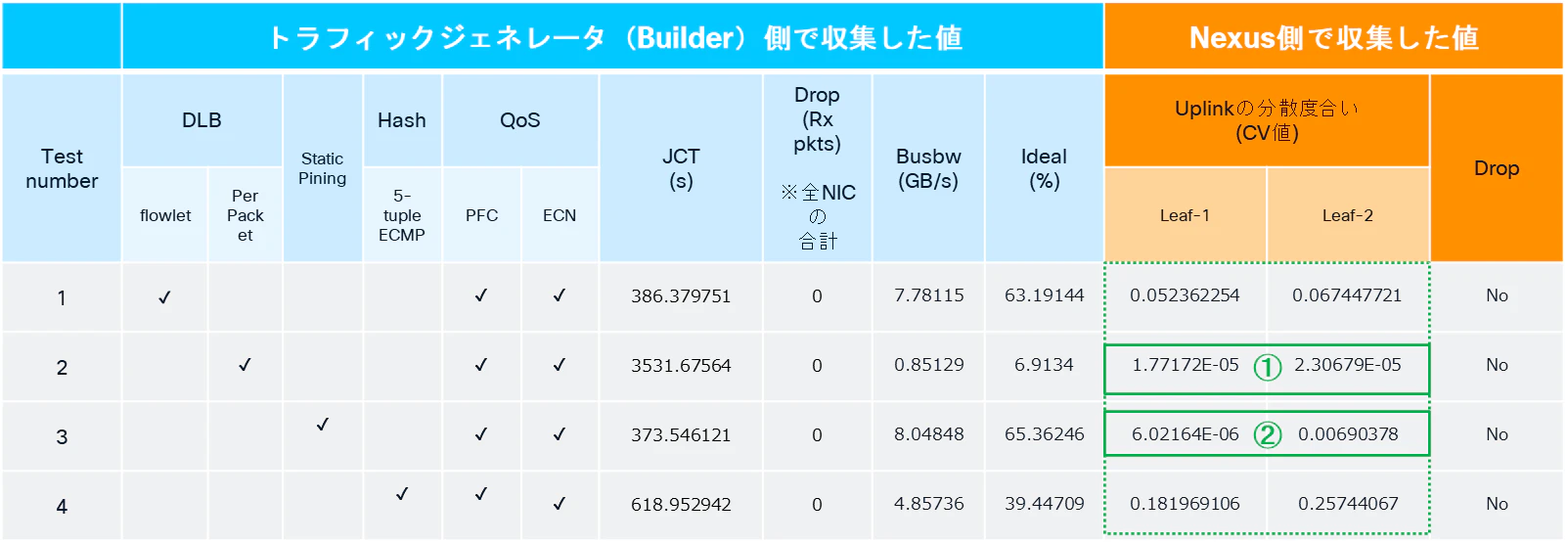
・Per Packet DLBはその名の通り、パケットごとにリンクを使い分けられるため、リンク間でほぼ均等な負荷分散を実現しやすいことはイメージしやすいかと思います。
・次にStatic Pinningですが、Static Pinningでは、「どの受信ポートから受信したか」に応じて、送出ポートが固定されます。
そのため、各受信ポートにおける受信トラフィック量が均等であれば、送出ポート側の送信トラフィック量についても均等になりやすい特徴があります。
本検証環境では、各NIC(Rank)から送出されるトラフィック量がほぼ同一であるため、結果として各送出ポートについても均等な負荷分散を実現できていたものと考えられます。
その結果、ジョブ完了までを通して、リンク帯域を効率良く利用できていたと推測できます。
一方で、Static Pinningは、その名の通り静的マッピングを前提とした手法です。
つまり、
・RDMA以外のトラフィックも混在する環境
・サーバごとに役割や通信量が異なる環境
・通信パターン変動が大きい環境
では、最適なマッピング設計が難しくなり、運用・チューニング難易度は大幅に上がるものと考えられます。
(重要) Per Packet DLBにおけるRe-orderの発生について
今回の負荷分散検証では、ジョブ完了時間(JCT)の観点で、もう一つ無視できない重要な結果が得られました。
それは、Per Packet DLB使用時に、JCTが極端に長くなった(約3500秒)ことです。
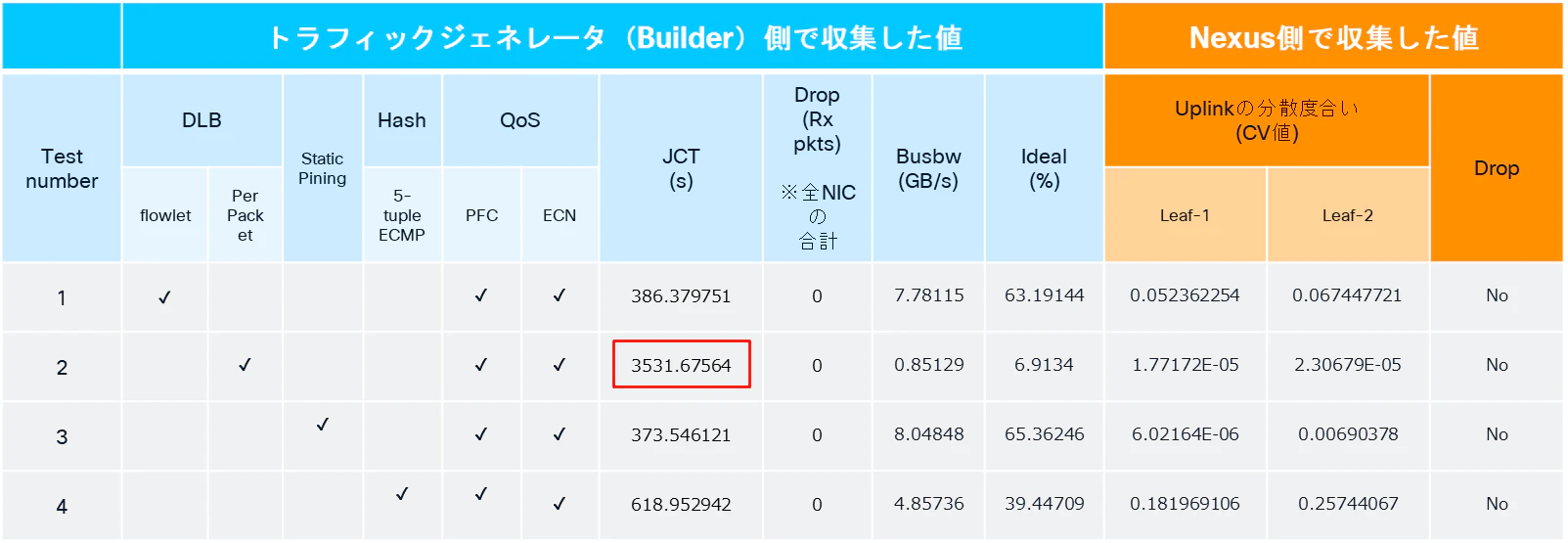
これは、Per Packet DLBによってトラフィックが負荷分散された際の、NIC側における処理挙動を考えることで説明できそうです。
Per Packet DLBは、その名の通り、同一フロー内の通信であっても、パケット単位で異なる経路へ振り分ける仕組みです。
そのため、結果として、NICへ到着するパケット順序の入れ替わり(Re-order)が発生しやすくなります。
一般的なTCP通信では、パケット順序が多少前後しても、受信側OSが後から並べ替える仕組みを持っています。
一方、RoCEv2は、低遅延・高効率を極限まで追求した通信方式であり、NIC側がパケット順序を厳格に管理することを前提としています。
そのため、パケット順序が入れ替わって到着すると、受信側NICは「本来到着するはずのパケットが欠落した」と判断し、後続処理を一時停止した上で、再送要求を発生させます。
このような、待機処理や再送処理が発生すると、通信全体のスループットやレイテンシへ大きな影響を与えることになります。
特に、今回のAll-Reduceのように、複数GPU(Rank)が同期を取りながら処理を進める通信パターンでは、たった一つの通信経路で遅延が発生するだけでも、他GPU側処理まで待機状態となります。
その結果、計算クラスタ全体の効率が低下し、最終的なジョブ完了時間(JCT)が大きく悪化してしまうのです。
(※補足)
今回の検証ではNICとしてConnectX-5を使用しましたが、ConnectX-7以降(SuperNIC世代)のNICでは、「Out-of-Order Handling」機能が搭載されています。
この機能を持つNICでは、ネットワーク側から順不同で到着したパケットについても、GPUやメモリへ渡す直前にNIC内部で高速に並び替えを実施できます。
これにより、
・ネットワーク層ではPer Packet DLBによる細粒度負荷分散を実施
・アプリケーション層(NCCL等)には順序保証されたデータを提供
という両立が可能になります。
結果として、Re-orderによる再送や、再送の発生に伴う待機時間を大幅に削減でき、Job Completion Time(JCT)の短縮につながることが期待されます。
(※ご参考) Per Packet DLB環境におけるRe-order制御については、LINEヤフーさんの解説資料が非常に参考になります。
ネットワークのボトルネック可視化
次に、Rankのペアごとに、パケット到着時間へどの程度差が発生していたのかを、Builder GUIを用いて可視化してみます。
(1) 5-tuple ECMP
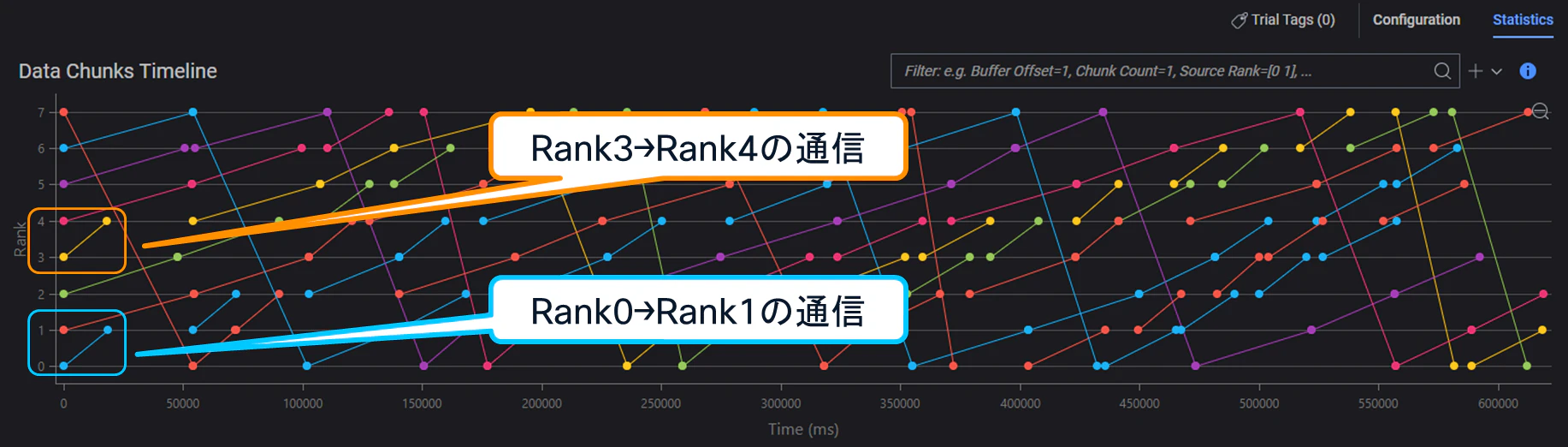
上図からは、
・「Rank0→Rank1」
・「Rank3→Rank4」
の通信については比較的到着が早い一方、それ以外の通信(例:「Rank1→Rank2」)については、到着までにより長い時間を要していることが確認できます。
前述の通り、All-Reduce通信では、全GPU(Rank)が同期を取りながら処理を進行します。
そのため、一部フローのみ到着が早かったとしても、他フローの到着が遅れることで、次ステップ全体の開始タイミングも遅延することになります。
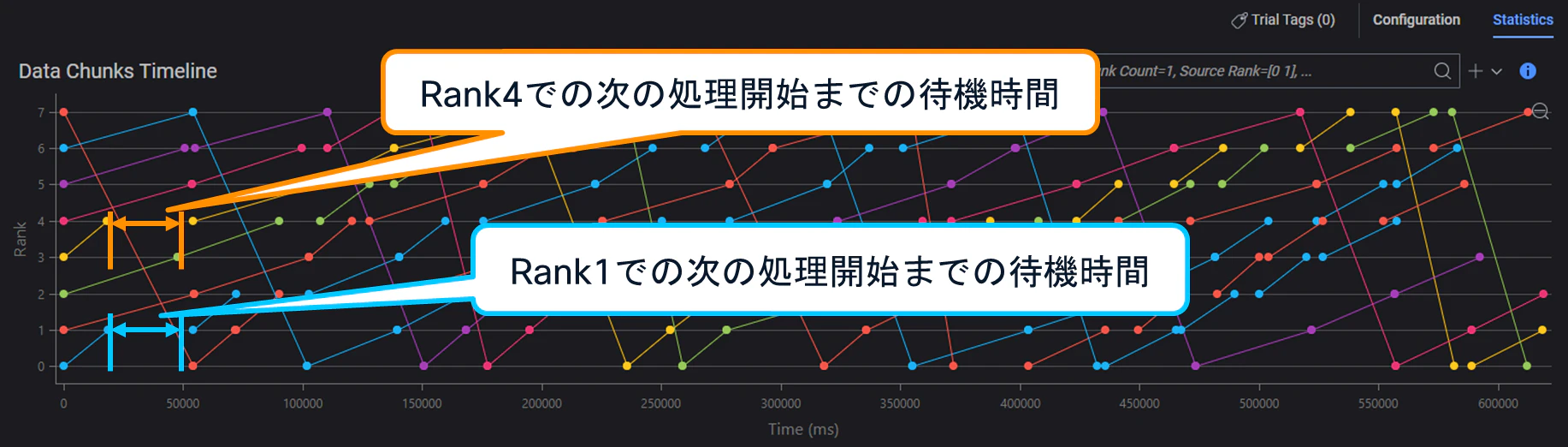
つまり、効率的な勾配同期を実現するためには、各Rank間における到着時間差を小さく抑えることが重要になります。
その観点では、フローごとに利用経路や混雑状況へ偏りが生じやすい5-tuple ECMPは、All-Reduce通信との親和性が必ずしも高いとは言えないことが分かります。
(2) Per packet DLB
Per Packet DLBの場合、5-tuple ECMPと比較して、各Rank間におけるパケット到着時間差が非常に小さいことが確認できます。
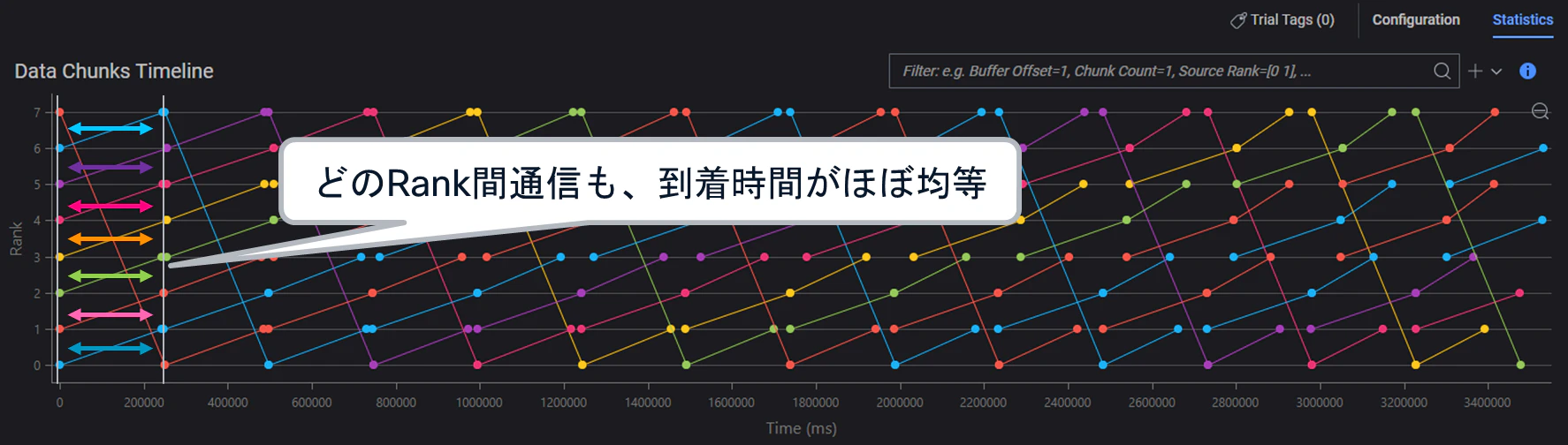
つまり、勾配データ配送というネットワーク観点では、非常に効率的に通信を分散できていることが分かります。
※ただし前述の通り、Per Packet DLBでは別途、Re-order処理/再送処理がNIC側で大きなボトルネックとなる可能性があり、その結果、ジョブ全体の完了時間へ大きな影響を与える点には注意が必要です。
☆ロードバランス手法に関する考察
今回の検証結果を踏まえ、AIトレーニング環境に対する各ロードバランス手法の親和性について整理してみました。
性能検証を実施する際の「性能」を何と定義するかによりますが、JCTが短いほど「性能が高い」と表現する場合、NIC性能や通信特性へ依存しにくく、安定した性能を発揮しやすいのはFlowlet DLBであると言えそうです。
一方で、前述したように、
・Per Packet DLB
・Out-of-Order Handling対応NIC(例:ConnectX-7)
を組み合わせた場合には、順序保証および帯域利用効率を高いレベルで両立できる可能性があります。
そのため、そのような構成を前提とできる環境では、Per Packet DLBが最も高性能な選択肢となる可能性もあると考えられます。
| 手法 | 分散粒度 | 順序保証 | 帯域効率 | RDMA適性 |
|---|---|---|---|---|
| 5-tuple ECMP | フロー単位 | ◎ | △ | △ |
| Flowlet DLB | 中粒度 | ○ | ○ | ○ |
| Per Packet DLB | パケット単位 | × | ◎ | ◎(条件付き) |
| Static Pinning | 固定 | ◎ | 環境依存 | 環境依存 |
結果のまとめ
今回の検証では、AI/LLM向けRoCEv2ネットワークにおいて、以下の項目について一通り動作を確認することができました。
-
RDMA通信向けQoS設定(PFC/ECN)がNexus上で期待通り動作することを確認
-
NexusとServer(RoCEv2 NIC)間における一連のDCQCN動作を確認
-
各ロードバランス手法(5-tuple ECMP / Flowlet / Per Packet / Static Pinning)の特性を確認
-
ECMPリンク利用率偏りやJCT影響について、CV等を用いて比較
-
QP数やRDMA Message Sizeによって、ECMPエントロピーや輻輳特性が変化することを確認
一方で、JCTをさらに短縮するという観点では、ネットワーク側チューニングによる改善余地も残されていると考えています。
例えば、以下のようなパラメータを細かく調整しながら検証することで、より網羅的な考察が可能になると思われます。
(1) QoS関連パラメータの調整
・ Queue buffer size
・ WRED/ECN発動の閾値
・ AFD(Approximate Fair Drop)による輻輳制御アルゴリズムの調整
※AFDは、単純なTail Dropや従来のECNと比較して、Elephant Flowと呼ばれるサイズの大きなフローを優先的に抑制しやすい仕組みであり、AI Fabric環境における輻輳緩和効果が期待されます。詳しくはNexus9000シリーズのホワイトペーパーやCisco Liveの資料等を参照ください。
(2) DLB(Dynamic Load Balancing)関連パラメータの調整
・ Flowlet Timer(別経路へ切り替えるタイミングを制御)
最後に
本シリーズではこれまで、AIモデル学習環境を支えるRoCEv2ネットワークをテーマに、計三回に渡って解説を行ってきました。
今回、実際に実機を用いて環境構築・検証を行った中で、まず強く感じたのは、「既存のCisco/Nexusの知識を活かしたままAIネットワーキングに応用できる」という点は、やはり非常に取っ付きやすいという点です。
QoS、ECMP、PFC、ECNなど、従来のデータセンターネットワークで扱われてきた技術やコマンドがそのままAI Fabricにも転用可能なためです。
一方で、RoCEv2環境の構築は、ネットワーク設定だけで完結するものではない、という難しさも強く感じました。
というのも、記事中でも繰り返し触れた通り、ロスレスネットワークは、
・スイッチ
・NIC
・GPU通信ライブラリ
・アプリケーション
など複数レイヤー間の連携によって初めて成立します。
そのため、ネットワーク・サーバ・GPU通信ライブラリを横断して理解する知識が必要になります。
また、性能最適化という観点でも、
・NIC性能
・QoS
・ECMP
・DLB
・GPU通信特性
などを総合的に設計・調整する必要があり、AIネットワーク構築には、非常に総合力が求められる分野だと感じました。
そういった意味では、いつか機会があれば、AI/HPC向けに特化したロスレス技術である InfiniBand についても実際に触れながら、EthernetベースRoCEv2との違いについて考察してみたいと思ったりもします。