本シリーズの概要
日頃お仕事などでネットワークの領域に携わっている方であれば、近年ホットなトピックであり続けているAIインフラの文脈で、「RoCEv2(RDMA over Converged Ethernet v2)」という言葉を耳にする機会が増えているかもしれません。
そこで今回は、CiscoのDC向けスイッチであるNexusの実機を用い、このRoCEv2技術を用いたAIネットワーキング環境の構築及び動作検証を実施してみました。
本シリーズでは、具体的な検証内容や検証の結果、および検証を通して得た学びなど、計3回に分けて記事をまとめていきます。
第一回目となる今回は、AIネットワーキングの検証を進める上でのキーワードとなるいくつかのインフラ技術、およびAIのトレーニングフェーズの裏側で動く数学的な仕組みの概要について、座学を中心に解説していきます。
導入
RoCEv2は、簡単に言うと、サーバ間でメモリ上のデータを高速にやり取りするためのRDMA通信を、Ethernetネットワーク上で実現する技術です。通常のTCP/IP通信では、データ転送の過程でCPUやOSのネットワークスタックが多く関与しますが、RDMAではこれらの処理を極力バイパスすることで、低遅延かつ高スループットな通信を実現します。
特にAIトレーニングのように、複数のGPUサーバ間で大量のデータを継続的にやり取りする環境では、この高速なサーバ間通信が非常に重要になります。モデルの学習中には大量のトラフィックが発生するため、ネットワーク性能がそのまま学習時間に大きく影響します。
一方で、RoCEv2を安定して動作させるためには、通常のIPネットワークとは異なる重要な前提があります。それが「ロスレスネットワーク」、つまりパケットロスを極力発生させないように設計されたネットワークです。
一般的なTCP/IP通信では、多少のパケットロスが発生しても、TCPの再送制御によって通信を継続できます。しかしRoCEv2では、パケットロスが発生すると性能劣化や通信異常につながりやすく、AIワークロード全体の完了時間にも大きな影響を与える可能性があります。そのため、RoCEv2環境では、単にL3到達性を確保するだけでなく、輻輳時におけるパケットロスの発生を抑えるためのQoS制御が重要になります。
RDMAとは
RDMA(Remote Direct Memory Access)とは、アプリケーションがOSを介さずに、リモートサーバのメモリへ直接アクセスできる通信技術です。
通常のネットワーク通信では、アプリケーションがデータを送信する際、OSのTCP/IPスタックを通じて処理が行われます。具体的には、カーネルへのコンテキストスイッチ、プロトコル処理、メモリコピーなど、複数のソフトウェア処理が介在します。
一方、RDMAではこれらの処理を大幅に省略し、RDMA対応NIC(Network Interface Card)が中心となって通信処理を実行します。アプリケーションはRDMAライブラリ(例:NCCL)を通じてNICに指示を出し、NICがリモート側メモリとのデータ転送を実行します。
この仕組みにより、RDMAでは従来のTCP/IP通信と比較して、以下のような特徴を持ちます。
-
低遅延(Low Latency)
OSのネットワーク処理をバイパスするため、処理遅延が大幅に削減される -
高スループット(High Throughput)
ソフトウェア処理のボトルネックが減ることで、より効率的なデータ転送が可能 -
低CPU負荷
通信処理の大部分をNICが担うため、CPUの使用率を抑えることができる -
メモリコピー削減(Zero Copy)
カーネルバッファなどを経由せず、ユーザメモリ間で直接データ転送が行われる
<イメージ図>
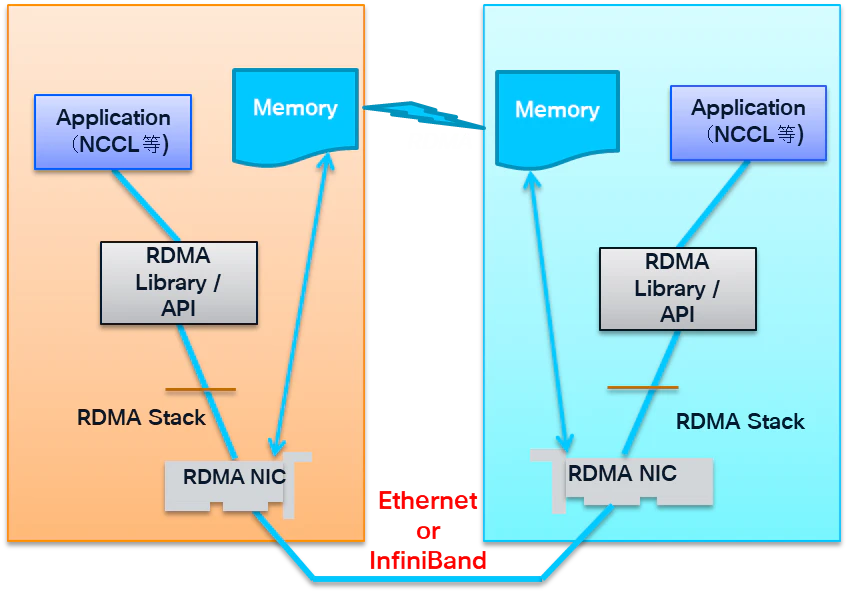
このような特性から、RDMAは特に分散AI処理やHPC(High Performance Computing)といった、大量データを高速にやり取りする用途で広く利用されています。実際、LLMの学習においては、GPU間で頻繁に行われるAll-Reduceなどのデータ転送性能が全体の処理時間に大きく影響するため、RDMAの有無が性能を左右する重要な要素となります。
・RDMAを実現する主な方式
RDMAの通信には複数の通信方式が存在します。
(1)InfiniBand
RDMA専用に設計された高性能ネットワーク技術。専用ハードウェアを用いることで、非常に高い性能を実現する
(2)RoCE(RDMA over Converged Ethernet)
Ethernet上でRDMAを実現する方式。特にRoCEv2はIPネットワーク上で動作するため、既存のデータセンターネットワークとの親和性が高い
(3)iWARP
TCP/IP上でRDMAを実現する方式。TCPを利用するため、標準的なIPネットワーク上で動作しやすく、RoCEのようにロスレス性を強く前提としない点が特徴。一方で、TCPによる信頼性制御や輻輳制御、再送制御などの仕組みを利用するため、RoCEと比較するとプロトコル処理が増加しやすく、レイテンシ面では不利になる場合がある。
このうち本記事で扱うRoCEは、「Ethernetを使いながらもRDMAの性能を引き出す」というアプローチであり、その代わりにネットワーク側にロスレス性が求められるという特徴を持っています。
RoCEv2とは
RoCEv2(RDMA over Converged Ethernet v2)とは、RDMAの仕組みをEthernet/IPネットワーク上で利用可能にした通信方式です。
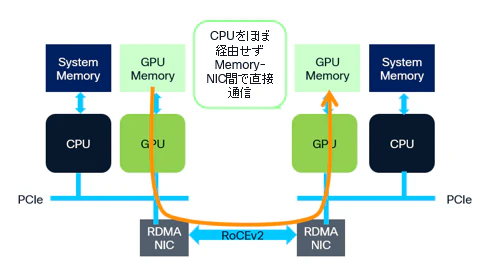
従来のRDMAはInfiniBandのような専用ネットワーク上で利用されることが一般的でしたが、RoCEv2ではUDP/IPヘッダを付与することで、既存のIPネットワーク上でもRDMA通信を実現できるようになっています。これにより、データセンターに広く普及しているEthernetインフラを活用しながら、高速・低遅延な通信を実現できる点が大きな特徴です。
(参考) RoCEv2では、RoCEのパケット形式に対してシンプルな変更を加え,IPヘッダおよびUDPヘッダを付与することで,RDMAトラフィックをIPネットワーク上でカプセル化して転送する。
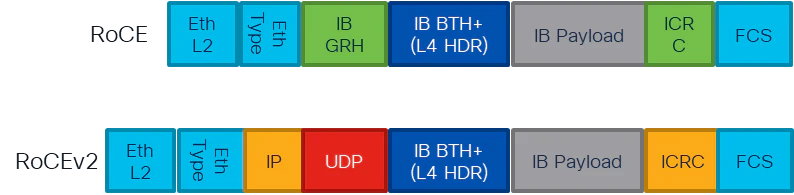
※RoCEv2環境でロスレスを実現するためのネットワークの要素技術(QoS,負荷分散)については、第二回目の記事で別途解説予定です。
AIネットワーキングにおけるロスレス環境の必要性
特に分散AI処理(後述するAll-Reduceなど)では、GPU間で大量のデータを高速にやり取りする必要があるため、このようなGPU間通信の効率が全体の性能を大きく左右します。そのため、現在のEthernetベースのAIデータセンターでは、RoCEv2はほぼ前提技術の一つとなりつつあります。
All-Reduce通信とは
分散AI学習において、ネットワーク通信が最も頻繁に発生する処理の一つが「All-Reduce通信」です。
ここでは、その役割を学習プロセスの流れに沿って整理します。
(注記) 尚、この話はディープラーニングの基礎的な理解を前提としたものであり、本記事のコアであるネットワークの領域とは少しレイヤーが離れたトピックであるため、時間の無い方は読み飛ばして頂いて問題ありません。
分散学習の前提:順伝播と逆伝播
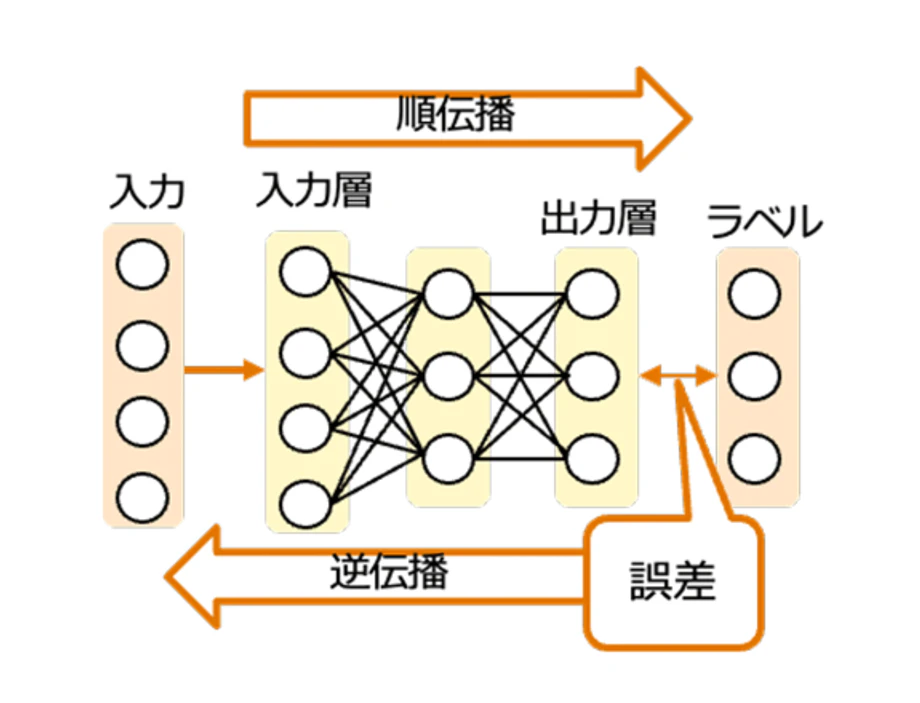
All-Reduce通信の役割を理解するために、まずはニューラルネットワークにおける基本的な学習の流れを整理します。
[参考URL]
https://xtrend.nikkei.com/atcl/contents/technology/00007/00053/
ニューラルネットワークの学習は、ものすごく簡単に言うと、以下の流れを何度も繰り返す処理です。
入力データを使って予測する
↓
正解と比べて、どれくらい間違っているかを確認する
↓
間違いが小さくなるように、モデル内部の重みを少しずつ修正する
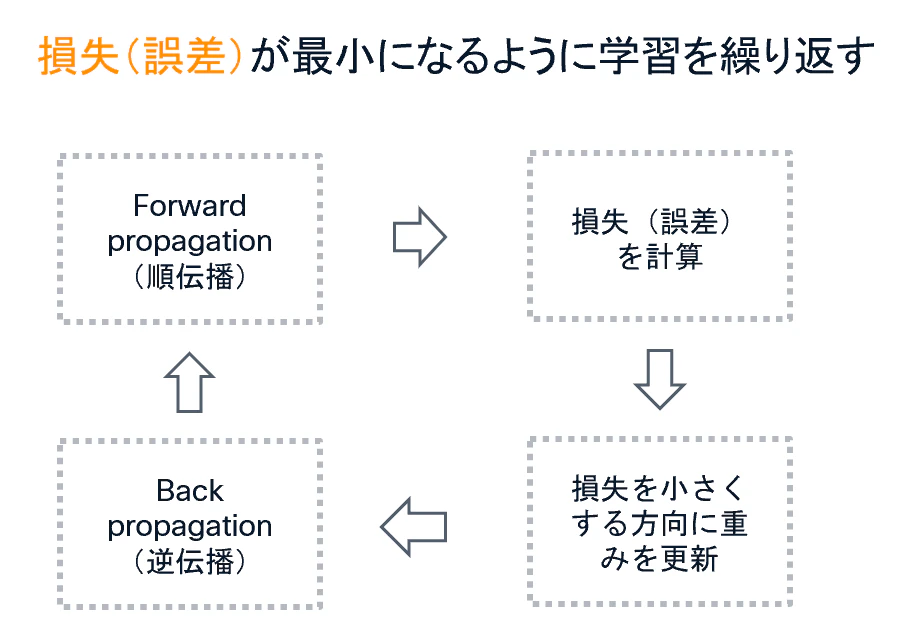
このうち、「予測する処理」が順伝播であり、「重みを修正するための情報を計算する処理」が逆伝播です。
① 順伝播(Forward Propagation)
順伝播とは、入力データをニューラルネットワークに通して、予測結果を得る処理です。
例えば画像認識であれば、以下のような流れになります。
[入力画像]
↓
[ニューラルネットワーク]
↓
[予測結果]
たとえば猫の画像を入力したとき、モデルが「これは猫である確率が80%、犬である確率が15%、車である確率が5%」のように予測したとします。
この予測結果と、実際の正解ラベルを比較することで、「モデルの予測がどれくらい外れていたか」を数値として表します。この値を損失(Loss)と呼びます。
なんとなく予想が付くかと思いますが、予測が正解に近いほど損失は小さくなり、予測が大きく外れているほど損失は大きくなります。
② 逆伝播(Backward Propagation)
逆伝播とは、順伝播で計算された損失をもとに、モデル内部の重みをどのように修正すべきかを計算する処理です。
学習初期のモデルは、この重みがまだうまく調整されていないため、予測誤差が大きくなります。そこで、損失が小さくなるように、各重みを少しずつ修正していきます。
このとき、重み更新の指標として使われるのが勾配(Gradient)です。
勾配とは、「ある重みを少し変えたときに、損失がどれくらい変化するか」を表す値です。数式では、以下のように表されます
∂L / ∂W
(Lは損失、Wは重みを表す。)
また、重みの更新は、一般的には以下のように表されます。
W_new = W_old - η × ∂L/∂W
(W_old , W_new はそれぞれ更新前/更新後の重み。また、ηは学習率と呼ばれ、重みを更新する度合いを表す。)
上述の順伝播/逆伝播の一連の処理を、損失が小さくなるまで大量のデータに対して何度も繰り返します。これによって重みの値は最適化されていき、モデルは少しずつ正しい予測ができるようになっていきます。
分散学習では、GPU間の勾配の同期が必要
単一GPUで学習する場合、勾配は、そのGPUのみがそのまま使い続けることで重み更新を行えば問題ありません。
しかし、分散学習では状況が異なります。
分散学習では、
- 各GPUが異なるデータを使って順伝播・逆伝播を実行する
- その結果、GPUごとに異なる勾配(∂L / ∂Wₖ)が計算される
という状態になります。
このまま各GPUがバラバラに重み更新を行ってしまうと、
- GPUごとに異なるモデルが出来上がってしまう
- 学習が収束しない(もしくは精度が悪化する)
という問題が理論上発生してしまい、分散学習として成立しなくなってしまいます。
そのため、分散学習では
全GPUで勾配を集約し、同じ値を使って重み更新する
必要があるのです。
分散学習における重み更新プロセス
具体的には、各GPUの勾配を平均化して、重み更新を行います。
① 各GPUで勾配を計算
分散学習では、複数のGPUが同じモデルを持ち、それぞれ異なるデータを使って並列に学習を行います。
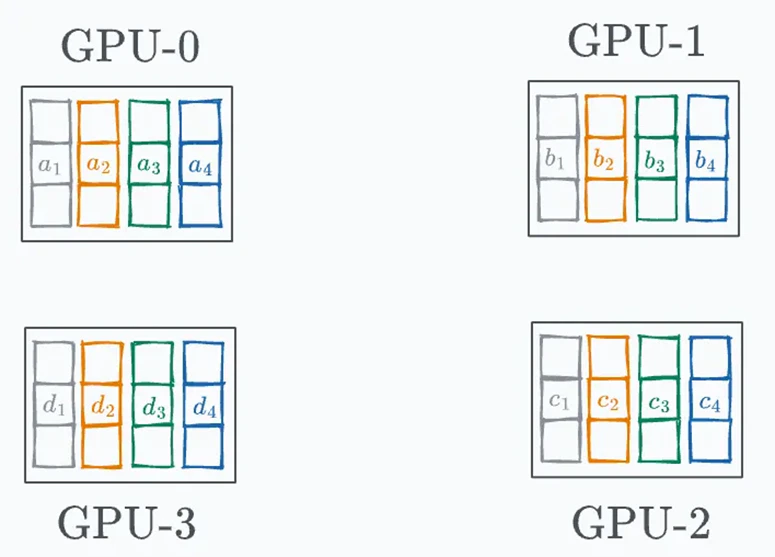
この時、GPU k が持つ勾配を ∂L / ∂W_kと表すとすると、この時点ではGPUごとに異なるデータを見ているため、当然ですが勾配の値もkによってバラバラになっています。
② GPU間で勾配をやり取りして平均化(=All-Reduce)
ここで登場するのがAll-Reduce通信です。
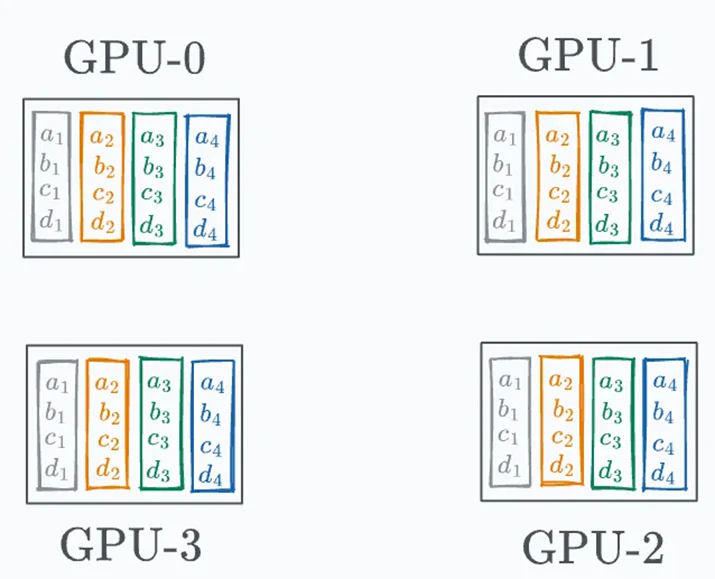
All-Reduceとは、各GPUが計算した勾配を全GPU間で共有し、全体として1つの勾配に集約したうえで、その結果をすべてのGPUに配布する処理です。
All-Reduceでは、以下のように全GPUの勾配の平均を計算します。
∇W = (1 / N) × Σ_k (∂L / ∂W_k)
(NはGPUの数、∂L / ∂W_k はk番目のGPUが計算した勾配を表す。)
この処理により、最終的にすべてのGPUが同じ勾配を持ち、同じ勾配を用いて重みを更新できるようになります。
・勾配同期前の状態(イメージ)
・勾配同期後の状態(イメージ)
[参考URL]
https://blog.dailydoseofds.com/p/all-reduce-and-ring-reduce-for-model
③ 重みの更新
勾配が揃ったら、各GPUは同じ値を使ってモデルの重みを更新します。
W = W - η × ∇W
(ηは学習率)
このようにすることで、すべてのGPUが同じモデル状態を維持したまま学習を進めることができます。
ネットワークとの関係(重要)
分散学習では、このAll-Reduce通信がイテレーションごとに必ず発生します。
つまり、
- GPU数が増えるほど通信量が増える
- モデルサイズが大きいほど通信データも増える
という特性を持ちます。
ここでようやくネットワークの話とつながります。
All-Reduceは、
- 大量データを
- 全ノード間で
- 同期的にやり取りする
という非常に厳しい通信パターンです。
そのため、
- パケットロス → 再送で全体が待たされる
- 輻輳 → 一部のGPUが遅れて全体の処理が待たされる
といった影響が、ダイレクトに学習時間の悪化につながります。
このような背景から、
RoCEv2 + ロスレスネットワーク
という設計が必要になってくる訳です。
(参考) Ring All-Reduceについて
All-Reduceにはいくつかの実装方式がありますが、その中でも広く使われているのが「Ring All-Reduce(リング方式)」です。
これは、GPU同士をリング状に接続し、データを順番に回しながら集約していくアルゴリズムです。
基本的な考え方
Ring All-Reduceでは、全GPUを1つのリングとして扱います。
各時間tにおいて通信の発生する方向としては、
[GPU0 → GPU1] , [GPU1 → GPU2] , [GPU2 → GPU3] , ...
というように、GPU(n) → GPU(n+1) というペアでの通信が常時発生している形となります。
・Ring All-Reduce型通信のイメージ
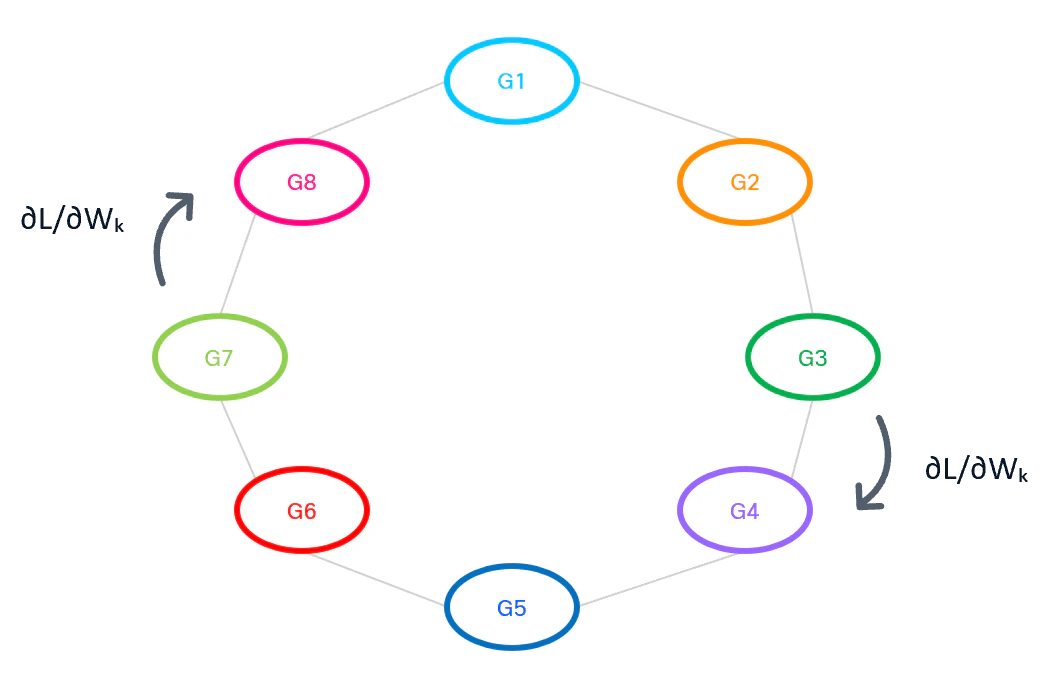
このリングに沿ってデータをやり取りすることで、全体の勾配を効率的に集約します。
はAll-Reduce通信の方式として、このRing All-Reduceを採用し検証を実施します。
まとめ
今回は、RoCEv2動作検証シリーズの第一回目として、RoCEv2の実機検証開始へ向けてポイントとなる各種概念(RDMA、All-Reduce等)について、適宜画像を用いて解説してきました。
第二回目となる次回の記事では、Ethernet上にロスレスネットワークを構築する上で必要となる、ネットワーク側(Cisco Nexus)の具体的な機能の話に入っていきます。