概要
Qiitaのストックを整理するためのサービス「Mindexer(ミンデクサー)」をリリースしました🙌
この記事では、Mindexerで利用している技術について、解説したいと思います。
GitHubでソースコードも公開しています。
https://github.com/nekochans/qiita-stocker-frontend
https://github.com/nekochans/qiita-stocker-backend
https://github.com/nekochans/qiita-stocker-terraform
サービスについて
個人サービスを開発しようとしたきっかけは、技術力の向上のためでした。でも、どうせなら自分だけでなく、多くの人に使ってもらえるようなサービスが良いと思いQiitaのストックを整理するためのサービスを作りました。
こんな問題抱えてませんか?
- Qiitaのストック一覧を見ても何のためにストックした記事か思い出せない
- 後で読もうと思ってとりあえずストックしたけれど、読まれない記事が溜まっていく
- ストックから欲しい記事を探せない
開発者はこれらの問題を抱えていました😭
ストックを整理する機能を追加する
これらの問題はすべて、ストックの整理ができていないことに要因があるではないかと考え、ストックを整理するためのサービスを作りました。整理するための手段として、自分専用のカテゴリを作成する機能を追加しています。記事をフォルダに分けるようなイメージです。
-
カテゴリの追加・編集・削除

-
ストックをカテゴリに分類

-
カテゴライズを解除

Qiitaのアカウントを持っていれば、すぐに使い始めることができます!
![]() Mindexer | Qiitaのストックを整理するためのサービスです
Mindexer | Qiitaのストックを整理するためのサービスです
アプリケーションアーキテクチャ概要
バックエンドはREST APIを提供し、フロントエンドはVue.js/Vuexを利用したSPAとなっています。
また、バックエンドにはDDD(ドメイン駆動設計)を採用しています。
インフラはAWSを採用し、すべてTerraformで管理しています。
Qiitaのストック記事の取得には、Qiita API v2 を利用しています。
インフラ構成
AWS構成図
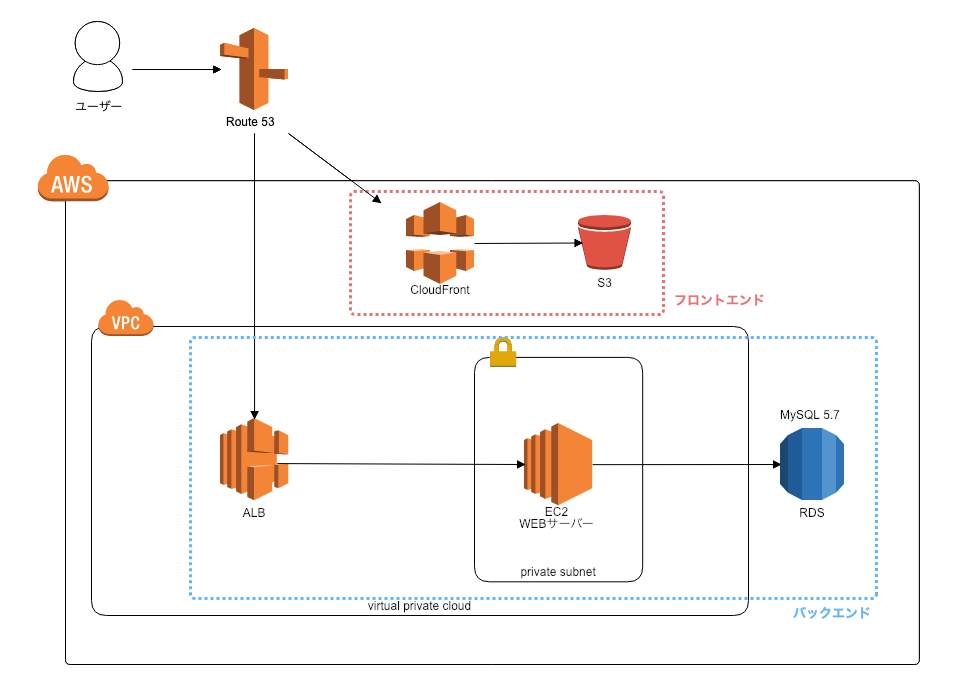
フロントエンド
ビルドしたSPAのソースコードをS3にデプロイし、CloudFrontで配信しています。
バックエンド
EC2にWEBサーバーを構築し、RDSはAurora MySQLを使用しています。
RDSにはAurora Serverlessも検討しましたが、Aurora Serverlessはオンデマンドで起動するため、初回起動時に25秒ほど時間がかかります。一般ユーザ向けのサービスには不適切であると判断し、Aurora MySQLを採用しました。
バックエンド
技術要素
- Laravel5.7
- nginx
- Amazon Aurora(MySQL)
概要
Laravelを使用してREAT APIを作成しています。
DDD(ドメイン駆動設計)を取り入れ、ビジネスロジックであるドメインモデルを技術の関心事を分離し、変化に強いコードとなることを意識しました。
ソースコード
https://github.com/nekochans/qiita-stocker-backend
REST API
バックエンドが返すAPIは、RESTの原則に沿った形でAPIを設計しています。URLが操作する対象のリソースを指定し、それに対するCRUD操作をHTTPメソッドで指定する、というものです。
APIの設計については、翻訳: WebAPI 設計のベストプラクティスを参考にさせて頂きましたので、詳細はこちらをご確認頂ければと思います。
エラーの設計については、WebAPIでエラーをどう表現すべき?15のサービスを調査してみたを参考に下記の通り定義しています。
{
"code":エラーコード,
"message":"エラーメッセージ",
"errors":{
"フィールド名":[
"エラーエラーメッセージ"
],
}
}
errorsはバリデーション エラーの場合のみ使用。
ドメイン駆動設計
ドメイン駆動設計で実装するにあたって、レイヤードアーキテクチャを採用しています。
実際のディレクトリ構成とレイヤードアーキテクチャの関係は以下の通りです。
レイヤードアーキテクチャの説明に不要な部分は、下記の図には載せていません。
app
├── Http ------------- プレゼンテーション層
│ ├── Controllers
│ └── Middleware
├── Infrastructure --- インフラストラクチャ層
│ └── Repositories
│ ├── Api
│ └── Eloquent
├── Models ------------ ドメイン層
│ └── Domain
└── Services ---------- アプリケーション層
レイヤードアーキテクチャの層ごとに、実装のポイントを解説していきたいと思います。
プレゼンテーション層
コントローラーにおいて、HTTPリクエストを受け取る・レスポンスを返すことのみを責務としています。
コントローラーには、ビジネスルールや知識を記述しないことを意識しています。
アプリケーション層
シナリオクラスを作成しています。
シナリオクラスの責務は、ドメイン層が提供するビジネスロジックを調整することです。
ここにおいても、ビジネスルールや知識は含めないことを意識しています。
ドメイン層
ビジネスルールや知識を表す層です。
エンティティ・値オブジェクト
ドメイン知識をエンティティ、値オブジェクトとして表現しています。
エンティティと値オブジェクトの違いは、「識別」を持つかどうかで区別しています。
また、エンティティ・値オブジェクトの生成にBuilderパターンを採用しています。
バリデーション
バリデーションもドメイン知識であると考え、仕様パターンを定義しています。
下記の例では、カテゴリ名のバリデーションチェックを行なっています。
バリデーション自体を、エンティティ・値オブジェクトに追加する方法もあると思いますが、その場合
エンティティ・値オブジェクトが複雑になると思い、仕様パターンを採用しました。
class CategorySpecification
{
/**
* CategoryNameValue が作成可能か確認する
*
* @param array $requestArray
* @return array
*/
public static function canCreateCategoryNameValue(array $requestArray): array
{
$validator = \Validator::make($requestArray, [
'name' => 'required|max:50',
]);
if ($validator->fails()) {
return $validator->errors()->toArray();
}
return [];
}
}
独自例外
ステータスコード、メッセージ、レスポンスの形式は全てドメイン知識であるため、ドメイン層に定義しています。
リポジトリインターフェース
データの永続化は、インフラストラクチャ層の責務ですが、そのインターフェースをドメイン層で定義しています。
インターフェースを定義することによって、データを永続する際はドメイン層からインターフェースのメソッドのみを呼び出せばよく、永続化に関する技術的な関心事を知る必要が無くなります。
また、フレームワークへの依存を避けるため、Eloquentに依存しない形でインターフェースを定義しています。
インフラストラクチャ層
Repositoryを定義しています。ストレージへのアクセス手段として利用し、ドメイン知識は持ちません。
ここでは、DBの操作はLaravelのEloquentoモデルを利用しています。
テストについて
APIの単位でテストクラスを作成しています。
API単位でテストを作成するメリットとして、APIのIFさえ変わらなければ動作を保証できるというメリットがあります。
開発中に何度か仕様を変更する必要性が出てきたのですが、テストで動作の保証ができる分、仕様を変更することへのハードルがすごく低くなりました。また何度かリファクタリングを行いましたが、その際もリファクタリングの工数を減らすことができ、開発を続けながらコードを改善することができたと思います。
テストについて下記の記事を参考にさせていただきました。
Laravel 5.3でREST APIのテストコードを書く
以下は、細かい部分になりますが、テストで使用した技術について参考になりそうなポイントです。
Guzzleを使ったMockの作成
HTTPクライアントにGuzzleを使用しています。主にQiitaAPIへのリクエストに使用しています。
Guzzleは非同期リクエストが可能であったり使い勝手がいいHTTPクライアントライブラリでしたが、テストにおいても簡単にMockを作成をすることができ便利でした。
Testing Guzzle Clients
テストコードの抜粋となりますが、Mockクライアントを生成するメソッドを下記の通り定義しています。
protected function setMockGuzzle($responses)
{
app()->bind(Client::class, function () use ($responses) {
$mock = [];
foreach ($responses as $response) {
$mock[] = new Response($response[0], $response[1] ?? [], $response[2] ?? null);
}
$mock = new MockHandler($mock);
$handler = HandlerStack::create($mock);
return new Client(['handler' => $handler]);
});
}
例えば、「ステータスコード200、ヘッダーは"total-count: 20"、BodyはJSON」のレスポンスを作成する場合、下記のように配列を引数で渡すことで作成できます。複数のレスポンスを作成する場合は、配列を追加するだです。
$this->setMockGuzzle([[200, ['total-count' => 20], '{ hoge: hoge}']]);
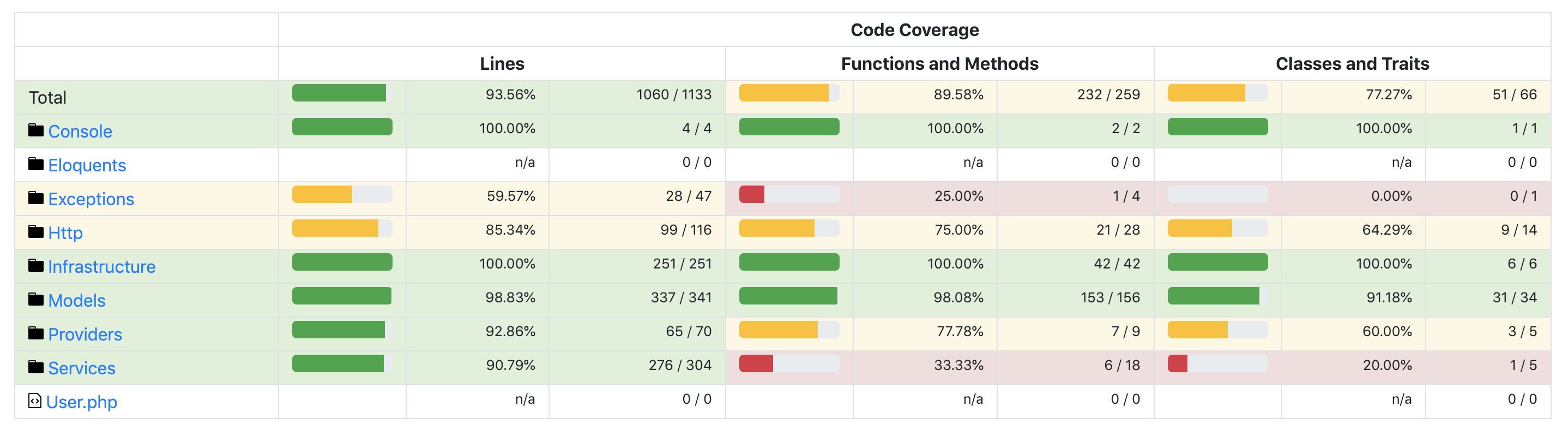
カバレッジを出力
テストケースが十分に網羅されているか確認するために、カバレッジの出力を行なって確認しています。カバレッジを100%を目指すことが目的ではなく、テストが十分に網羅されていないコードを検出することを目的としています。
カバレッジの出力結果のイメージです。
フロントエンド
技術要素
- Vue.js + Vuex
- Vue Router
- TypeScript
- Jest
- vue-test-utils
- Bulma
概要
Vue.js/Vuexを利用したSPAを作成しています。
Vueのプロジェクトは、Vue CLIのテンプレートを利用。スタイルについては、CSSフレームワークのBulmaを採用しています。
ソースコード
https://github.com/nekochans/qiita-stocker-frontend
設計
コンポーネント
ディレクトリを2つに大きく分けています。
- pages
- components
pagesは、Vue Routerのルーティングに対応するコンポーネントです。将来的に、Nuxt.jsに乗り換えたいという思いもありこのような形にしています。
componentsのコンポーネントを組み合わせることによって、全体のレイアウトを構築しています。またpagesの特徴として、Storeを直接参照できるようにしています。
componentsのコンポーネントは、比較的大きいコンポーネントとしています。
このような形にしている背景としては、以下のような理由が挙げられます。
- CSSフレームワークのBulmaを利用しているため、コンポーネントにスタイルを閉じ込める重要性があまりない
- サービスの規模が大きくないため、大きめのコンポーネントで実装を進めたほうが開発効率が良い
componentsは、Storeに依存しない設計にしています。
なぜ、このような形にしているかというと、コンポーネントの依存を少なくすることで、コンポーネントの再利用性を高め、テストをしやすくするためです。
今後も開発を進めていく予定なので、コンポーネントの設計は見直す必要が出てくるかもしれません。
Store
状態管理のため、Vuexを利用しています。
基本的には、Vuexのコアコンセプトを基に作成しており、特筆すべき点は無いのですが、下記の点だけ考慮しています。
VuexではコンポーネントからMutationを直接コミットすることが可能となっていますが、このプロジェクトでは、コンポーネントから操作する際は、必ずActionを経由するようにしています。理由は、データの流れを見やすくするためです。多少コードが冗長になるデメリットもあるかと思いますが、複数人での開発になった場合、データの流れが明確になっているほうが不具合の発生が少なくなるのではないかと考えています。
テストについて
テストフレームワークはJest、コンポーネントのテストにはvue-test-utilsを使用しています。
Jestは、テストランナーとアサーションの機能を兼ね備えており、Jestのみでテストを実行できるという点で採用してしています。
テスト対象は、全てのコンポーネントとVuexのモジュールです。E2Eのテストは導入していません。
コンポーネント
各コンポーネントのテストケースを作成しています。
テスト観点は、Jestのdescribe()の単位で下記の通りです。コンポーネント単体の振る舞いだけでなく、コンポーネント同士の連携についてもテストしています。
props
propsが正しく受け取れているか。
method
methodが正しく動作しているか。
主に、子コンポーネントのメソッドの実行により、親コンポーネントのメソッドがemitされているかを確認しています。
template
正しくレンダリングされているか。
DOMイベントが発火した際に、メソッドが実行されるか。
子コンポーネントとの結合テストとして、子コンポーネントのイベントが発火した際に期待する親コンポーネントのイベントが発火しているか。
Vuexのモジュール
VuexのGetter、Mutation、Actionのテストケースを使用しています。
ここはビジネスロジックが詰まった部分であるので、テストケースとしては必須になると思います。
現在、全てのテストケースを1つのファイルに書いておりテストファイルが肥大化しているため、Getter、Mutation、Action単位で分割する予定です。
改善点
実際に上記の観点でテストケースを作成しましたが、コンポーネントのテストにおいて、全てのコンポーネントのテストを書くのは大変でした・・・
細かい単位でコンポーネントが作成されており、かつ、再利用されているというケースにおいては、コンポーネントのテストを書くメリットがあると思いますが、今回ようなコンポーネントの再利用があまりされていないケースでは、全てのコンポーネントのテストを書くことはメリットがあまりないのではないかと思いました。
Storeに依存するコンポーネントに限定したテストでもよかったのではないかと思っています。
この点については、改善していきます!
デザインについて
CSSフレームワークであるBulmaを使用しています。UIコンポーネントのElementUIやVuetifyについても検討しましたが、カスタマイズのしやすさという観点からBulmaを採用しています。
実際にBulmaを使って見たメリットは下記の通りです。
レスポンシブ対応
CSSを読み込むだけで、レスポンシブ対応が完了する点が非常に便利でした。
例えばヘッダーのメニューについても、Bulmaだけでハンバガーメニューへの切り替えが可能です。
学習コストの低さ
Bulma公式のドキュメントに情報が揃っているので、ここを確認すればだいたいのことは実現できました。また、公式のExpoにBulmaを利用したwebサイトの一覧があるので、これらを参考にしながらデザインをしています。
今後改善していきたい事
技術面
現時点では、以下を対応する予定です。
- CI/CDを導入しテスト&デプロイを自動化する
- フロントエンドを Nuxt.js ベースにしてPWAに対応させる
- APIサーバーをDockerで動作するように改修する(AWS Fargateとか使うかも)
機能の追加によって新しい技術の導入が必要になると思うので、これからも継続的に改善を続けていこうと思っています!
機能
最小限の機能しかないので、これからはもっとリッチにしていきたいと思っています。
現時点では、以下の機能があったらより便利かなと考えています💡
- カテゴリの並び替え
- 検索機能の追加 → ストックした記事を検索出来る機能
- メモ機能の追加 → カテゴライズした記事に自分用のメモを追加出来る機能
実際に使ってみて、フィードバックを頂けますと励みになります🙇♀️
開発の進め方
このサービスは、2人で作成しています。
主な開発は自分(kobayashi-m42)が担当し、レビューや技術的なアドバイスを@keitakn にしてもらうという形で進めています。
開発ルールの設定
プロジェクトの開始時点で、開発のルールを設定しました。
最初に認識を合わせておくことで、スムーズな開発が可能になりますので、チームで開発する場合は設定しておくといいと思います。
- Gitのコミットルール
- PRの作成ルール
- 全ての課題に共通するDoneの定義
スクラム開発
スクラム開発で開発を進めました。2人という少人数のチームのため、正確なスクラム開発ではありませんが、スクラムの開発方式をとっています。概要は以下の通りです。
- スプリントは2週間
- 2週間に1度、スプリント計画を対面で行う
- 普段のコミュニケーション手段はSlack
また、スクラムを導入するにあたりZenHubを使いました。Chromeの拡張機能をインストールすることで使い始めることができます。今まで、プロジェクト管理ツールであるBacklogを使用したスクラム開発をしたこともありましたが、個人的にはZenHubの方が使い勝手がよかったという印象です。
ZenHubを使ったスクラム開発の始め方は、下記の記事に詳しく書かれていますので、こちらをご覧ください。
ZenHubで始めるスクラム開発
あとがき
ゼロからサービスを作成するために、企画、技術の選定、設計、実装、デザイン・・・など全て担当し、技術的に多くのことを学ぶことができました。やはり、手を動かして何かを作ることが、技術を身に着ける上で一番大切だと実感しました。
ひとまず、リリースすることができ安堵していますが、これからも「Mindexer」というサービスを成長させながら、技術力を上げていきたいと思っています!
無料で公開していますので、多くの人に使っていただけると嬉しいです😊
![]() Mindexer | Qiitaのストックを整理するためのサービスです
Mindexer | Qiitaのストックを整理するためのサービスです
ソースコードもこちらで公開しています!
ここにはMindexerのソースコードだけでなく、プロジェクトの雛形となるようなboilerplateも追加しています!
![]() https://github.com/nekochans
https://github.com/nekochans