「利用者は数十億人!? SQLiteはどこが凄いデータベース管理システムなのか調べてみた」の続きです。
はじめに
複雑な構造のデータを扱うのであればシェルスクリプトや Unix (POSIX) コマンドでデータ管理を行うのは避けるべきだと思います。解決不可能な問題が多いからです。しかしそれでも何かしらの理由でやろうと考える(やらなければいけない)のであれば SQLite を使うのをおすすめします。シェルスクリプトや Unix コマンドは行単位の単純なテキストデータをシーケンシャルにデータ処理するのが前提となっており、改行や空白が含まれるデータや複雑な構造のデータ扱うのは苦手です。またシェルスクリプトと Unix コマンドではランダムアクセスが出来ないためデータの検索や更新に時間がかかってしまいます。これら多くの欠点は SQL でかなり解決することが出来ます。(「Unix コマンドの制限と移植性に苦しむ」 vs 「簡単で高機能な SQL で楽をする」どちらを選ぶ?)
ひとこと 長いので時間があるときに「あとで読む」か、目次で気になった所を読むことを推奨(過去一番の分量な気がする…)
この記事は SQLite に関する補足記事「利用者は数十億人!? SQLiteはどこが凄いデータベース管理システムなのか調べてみた」のメイン記事です。SQLite の話として思いの外ウケたようですが、実はこっちの記事の方がメインです。SQLite つながりでこの記事にたどり着いた人でシェルスクリプトに興味がある人は少ないかもしれませんが「複数言語を横断したデータ管理方法」の話でもあるため他の言語の利用者にとっても意味がありますし、止む終えない事情でシェルスクリプトを使わなければならない場合に Unix コマンドにはこのような問題があるということを頭の片隅に入れておくのも良いのではないかと思います。なおこの記事で言う「Unix コマンド」とはリンク先のリストのように、歴史的な Unix コマンドのことで POSIX コマンドや tar などの昔から Unix 系 OS で使われていたコマンドのことを指しています。sqlite3 コマンドや jq や curl コマンドのように POSIX 誕生(およそ 30 年前)以降に登場や普及した比較的新しいコマンドは含めていません。
補足 この記事は「シェルスクリプト+データベース活用テクニック Bourne ShellとSQLiteによるDBシステム構築のすすめ」という書籍を一部参考にしています。なかなかユニークな本だと思うのですががあまり知られてない気がするので紹介です。また私の現在の知識は SQLite のことを知ったが使ったことはない程度だと考えてください。かなり昔に Perl で SQLite を使って簡単なウェブシステムを作ったことはありますが、シェルスクリプトでは本格的に使ったことありません。まああれです、この記事でシェルスクリプト界隈における SQLite の認知度を上げて、みんなに使ってもらってそのノウハウを公開してもらおうという魂胆です(笑)
注意事項
この記事の趣旨を勘違いして欲しくないので、それを先に述べておきます。
一つ目は、私はデータ管理の全てをシェルスクリプトだけでやるべきだとは言っていません。シェルスクリプトはグルー言語と言われていることからもわかるように、複数の適切な言語を組み合わせることが得意な言語であり、したがった他の言語やツールを使うことが大前提であると私は考えています。組み合わせることが得意な言語なのに使って良いコマンドを Unix コマンド または POSIX コマンドだけに制限するのはナンセンスです。そもそもシェルスクリプトと Unix コマンドは制限が大きく限られた OS の API しか使用しない(できない)ため、他の言語を使わなければハードウェアや OS の能力を引き出すことができません。他の言語とは C 言語や awk のように POSIX で規定されているものだけではなく、あらゆるプログラミング言語です(SQL も含みます)。それらの言語は POSIX 準拠 OS 上で動くことから証明されているように POSIX 準拠のアプリケーションです。POSIX は開発に使用する言語を制限しておらず、さまざま言語で POSIX 準拠アプリケーションを書くことができます。POSIX 準拠がどういうことであるかは「POSIX準拠 とは本当はどういうことなのか?「POSIXで規定されたものだけを使う」ではありません」を参照してください。
複数の言語を組み合わせる時によく使われるのがパイプです。しかしパイプはシーケンシャルでしかデータ処理できずパイプ間通信のオーバーヘッドがあるため、必ずしも最善の手段とは限りません。データ管理は最終的にファイルに保存するため、さまざまな言語から読み書きできるファイル形式を使えば複数の言語を組み合わせることが容易になります。テキストファイルもどの言語からでも読み書きできると思うかもしれませんが、それは独自ルールのない単純なテキストファイルに限った話です。データベース管理システムのようなものは複雑な構造を持ったファイルでなければ実現できないため、テキストファイルベースのファイル形式であっても正しく読み書きするには各言語で同じようなデータ管理のコードを書かなければならなくなります。
二つ目は、私は Unix コマンドを否定しているわけではありません。Unix コマンドはデータ管理は苦手ですが「テキスト処理のフィルタコマンド」としての価値があります。Unix コマンドはデータ管理を行うには機能が大きく不足しているため、データ管理を行う場合であれば SQLite を使うことで Unix コマンドの使用を減らすことができ、Unix コマンドの欠点や限界をカバーすることができるというのがこの記事の趣旨です。これはシェルスクリプトの本来あるべき使い方や Unix 哲学に従ったより良い活用方法です。そして私の最終目的は現在の多くの問題を解決することで、より便利に簡単にシェルスクリプトを使えるようにシェルスクリプトの世界を大きく変える(進化させる)ことです。
難しいことまで Unix コマンドで頑張るのはやめましょう。頑張ったところで大したメリットはありません。SQLite を使いましょう。SQLite を使うことに大きなデメリットはありません。シェルスクリプトと SQL を含む複数の言語を簡単に組み合わせることが可能なファイル形式が SQLite のデータベースです。
データ管理のスペシャリストにとって RDBMS (SQL) は必須の知識である
RDBMS は数学者が理論のないデータ管理にムカムカして考案した
RDBMS はエドガー・フランク・コッド博士によって考案されました。彼は IBM でプログラマーとして働き、ミシガン大学アナーバー校でコンピューターサイエンスの博士号を取得したセルオートマトン理論でも有名なコンピュータ科学者です。1960 年代から 1970 年代にかけてデータベースの理論を構築し、1970 年に 論文「A Relational Model of Data for Large Shared Data Banks」を発表しています。日本データベース学会に寄稿された記事「リレーショナルデータベースの始祖Dr. Edgar F. Coddの死を悼む」より、なぜ RDBMS を考案したのかという話を見つけたので紹介します。
折しも世の中はソフトウェアの生産性を如何に上げるかを標榜してソフトウェア危機(software crisis)が叫ばれていた只中であった.博士がそこで見たものは理論など全く存在しないデータ管理システムの惨憺たる姿であった.“ドキュメントを読み始めたが,むかむかした”と博士は言ったという[3].それが元々は数学を修めた博士の代数的頭脳をいたく刺激したのであろう.単純にして強力で美しきリレーショナルデータモデルの提案となって結晶した.
ソフトウェア危機とは 1960 年代(Unix 誕生と同じか少し前)のソフトウェア工学がまだ十分に確立していなかった頃に叫ばれていた言葉で、ハードウェア性能の向上に伴うコンピュータ利用の需要と要求の増加でソフトウェアの規模や複雑性が増大する一方、ソフトウェア開発手法が未成熟なためプロジェクトの遅延や品質の低下などの状況に陥ったことを指しています。現在も完全に解決されているとは言い難いですが、ソフトウェア危機以降に登場したアジャイルや継続的インテグレーション等の方法論、設計手法やデザインパターンやテスト自動化、バグ管理システムやバージョン管理ソフト、構造化プログラミングやオブジェクト指向等のプログラミング技術といった、数多くのさまざまな手法でソフトウェア危機を乗り越えてきました。(以下の引用は「システム開発技法の歴史」より)
高品質のソフトウェアを効率よく開発すること、保守改訂が容易なソフトウェアにすることが重要であることは、プログラムが出現した当初から認識されていた。
これが深刻になったのは1960年代末である。コンピュータが広く用いられるようになるのに伴い、プログラマが不足してきた。システムの規模が大きくなるのに伴い、システムが複雑になり、システムの品質を維持することが困難になってきた。
NATOは1969年にソフトウェアエンジニアリング会議を開催した。このような状況をソフトウェア危機(Software Crisis)であるとし、それを解決するためには、ソフトウェア開発を工学的な観点から方法論や手法を整備すること、すなわち、ソフトウェア工学(Software Enginnering)が必要だとしたのである。この指摘もあり、1970年代には、ERDやDFDなどの図法、ウォータフォールモデルなどのシステム開発技法など、現在でも広く利用されている手法が発表され、次第に洗練されるようになった。
この問題はデータ管理システムにもあてはまり、未熟な技術者による散々なシステムを目にした博士によって生み出されたソフトウェア工学の一つがリレーショナルモデルという理論というわけです。当時はすでに、柔軟だが扱うのが難しい網型データベース (NDB) や、分かりやすいが柔軟性に欠ける階層型データベース (HDB) が存在していました(参考 データベースの歴史(概要))。そのいいとこ取りをしているのがリレーショナル型データベース (RDB) です。RDB が広く普及した今では信じられないかもしれませんが、当時はそれまでのデータベースの開発者からの反発で壮絶な論争があったそうです。その論争を経て勝利したのが RDB というわけです。
上記の日本データベース学会の記事より「コッド博士が唱えた至極当たり前のこと」を紹介します。
- アプリケーションプログラムとデータは切り離されなければならない.
- データモデルは単純・明快でなければならない.
- データベースの構築と管理を経験と勘に頼ることから脱却するには,データモデルは理論的基盤を持たなければならない.
上記の事を Unix コマンドだけで実現するのは困難です。Unix コマンドが本質的に抱えている制約を回避するためにアプリケーションプログラム(シェルスクリプト)は独自のファイル構造のデータと切り離せないコードとなってしまい、データモデルは現場の担当者の経験と勘に頼った理論のない複雑なものとなりがちで、難易度が高い設計を十分に行わなければ柔軟性のない変更に弱いソフトウェアとなってしまいます。それではすぐにソフトウェアの寿命が来てしまいます。
Unix コマンドで RDB のマネごとをするのであれば本物の RDBMS を使った方が良いのは言うまでもありません。現在は新しく NoSQL と呼ばれるドキュメント型やグラフ型のデータベースが登場していますが、これらは RDBMS を置き換えるものではなく、特に ACID 特性が重要なミッションクリティカルな用途では今後も置き換わることはないでしょう。使い所の違いが理解され共存する形で落ち着きました。また RDBMS には NoSQL の機能(JSON データへの対応など)が一部取り入れられたため RDBMS の適用範囲は以前より広がっています。
Unix コマンドは 30 年前に進化を終えた古い技術
異論があるとは思いますが、Unix コマンドは 30 年前に未完成のまま進化を終えた古い技術です。30 年前というのは Unix を開発した AT&T が Unix の開発から撤退し権利を他社に譲り渡したときです。Unix は完成して終わったのではありません。Unix の後継とみなされていた Plan9 という OS がありましたが Unix を置き換えることなく開発は終了しました・・・と思っていたのですが 2021 年に開発再開したような話があります(参考 UNIX開発チームが開発した分散OS「Plan 9 from Bell Labs」の権利がオープンソースコミュニティに移行)。それでも少なくとも現時点においては Unix は Plan9 で実現しようとした「ネットワークやユーザインタフェースまでをもファイルとして表現する」ことができていないため Unix 哲学的に未完成の OS と言えます。ネットワークがファイルとして表現されていないことは Unix コマンドでネットワークを扱うことができない理由の一つです。
Unix コマンドに足りていないものは「ファイルにランダムアクセスするコマンド」「全てのバイト列を扱える行志向のコマンド」です。全てのバイト列を扱える行志向のコマンドというのは、例えばデータの値の中に改行文字を含むことができるという意味です。行志向かつ値に改行文字を(エスケープして)含めることができる形式として JSON Lines がありますが、その登場時期から JSON Lines に対応した Unix コマンドはありません。Unix コマンドは 30 年前からほぼ停滞しているので新しいコマンドが増えないのも仕方のない話でしょう。
私は進化の終わった Unix コマンドを置き換える、より使いやすくどの環境でも完全に同じように動く新しいシェルスクリプト用のライブラリまたはコマンドセットが必要だと考えています。Unix コマンド、特に POSIX コマンドは互換性を維持する必要性から仕様変更ができないため、現在問題になっている OS 間での互換性問題はほとんど改善されないか 10 年スパンの長い時間がかかってしまいます。いつまでも古くて問題が多い Unix コマンドに依存し続けるのはよくありません。シェルスクリプトでの生産性をあげるため移植性の問題を解決し、より使いやすく進化させる必要があります。普通に書いただけでどの環境でも同じように動いてこそ、本当の意味でどこでも動くということです。
RDBMS (SQL) はデータ管理の普遍的な技術でどこでも使われてる
RDBMS (SQL) はデータ管理の世界で普遍的な基本技術の一つであり、プログラマーだけではなく統計解析やデータ分析を行ったりビッグデータを扱うエンドユーザーにとっても必須の知識です。これらの単語で検索するとプログラマー向けに書かれてないような書籍も数多く見つかります。
RDBMS や SQL が使われている分野は多岐にわたります。SQLite だけではなく MySQL、PostgreSQL、Oracle、MS SQL Server と多数の RDBMS の実装が存在し、クラウドサービスでも GCP の Cloud SQL や AWS の RDS などがあります。RDBMS ではないが SQL が使える BigQuery もあります。『データ活⽤を全ての⼈に。データ⺠主化のためのソーシャルデータプラットフォーム「delika」』(この記事の最後の「補足」参照)でもビジネスデータやオープンデータを活用した⾼度なデータ分析を行うのに SQL を使います。どこでも使え、どこでも使われているのが RDBMS です。
一方ファイルはどうかというと、ソースコードや設定ファイルや簡単なドキュメント書き程度には使われていますが、データを格納するものとしてファイルが使われることは殆どありません。ファイルを使う場合でも独自のデータ構造を設計することはなく、テキスト形式ベースであったとしても JSON や YAML や XML と言った構造がきちんと定義されている汎用の形式が使われています。そしてそれらの形式はライブラリ経由で使うため、自分で直接ファイルのデータ構造を読み書きすることはありません。
かつては私も C 言語で自分のソフトウェアのための設定ファイルをパースするコードを書いたりしましたが今はいずれかのライブラリを使います。特殊な構造のテキストファイルの読み書きを自分で行うようなことは殆どありません。もちろん特殊な構造のファイルが必要ならそうすべきですが、そのような目的がなく SQLite のようなよく知られた方法が使えるのであればそれを使うべきです。RDBMS を使いこなせるようになるには技術が必要ですが、そもそもプログラマーは技術者なわけで、専門技術が必要だからと敬遠するようでは技術者にはなれません。
目的なくデータ管理の仕組みを独自開発するのは「無駄」である
あなたにとってデータベースを使う目的は何でしょうか?統計解析、データ分析、機械学習、ディープラーニング、ブログ、CMS、商品管理、売上管理、いろいろあると思います。しかし DBMS を作ることが目的の人はほとんどいないと思います。データを管理する事とデータを利用する事は意味が違います。ほとんどの人にとってデータを管理するための DBMS を作ることは目的ではなく、データ (DBMS) を利用して何かを行うことが目的であるはずです。
基本技術が重要だからといって、美味しいラーメンを作るのにかまど作りから始めるのは方向性が間違っています。それが許されるのはアイドルグループぐらいで、ラーメンだけではなく全てのものを作る過程の全てが目的だから許されるのです。実際の所かまどづくりの基本を学んでも美味しいラーメンを作るのに役に立ちません。
それと同じでファイルの読み書きは基本技術だとしても、オレオレ DBMS を作っても機械学習やデータ分析の技術が上がるわけではありません。もし新しい DBMS を開発することが目的であればやる価値はありますが、その場合制限が多く OS の機能を引き出せないシェルスクリプトと Unix コマンドではなく別の言語を使う必要があります。いずれにしろシェルスクリプトと Unix コマンドでデータ管理を頑張る意味がないということです。
目的に応じて適切な言語は違います。統計解析やデータ分析をするなら R 言語が向いているでしょうし、機械学習・ディープラーニング分野では Python が適切でしょう。いろんな言語から同じインターフェースで同じデータベースを参照できると複数の言語を組み合わせやすくなります。シェルスクリプトは複数の言語で作ったコマンドを組み合わせるための言語です。そこに複数の言語で共通で使える SQLite というデータ管理システムを導入することは、適切な言語でデータ処理をするのに最適というわけです。またシェルスクリプトから sqlite3 というコマンド介して SQL を実行するということは、SQL という別の言語を組み合わせて使うという意味でもあります。これもまた複数の言語を組み合わせるシェルスクリプトの流儀に従った手法と言えます。
SQLite と Unix コマンドの根本的な違い
SQLite とは
SQLite は他の多くの RDBMS とは異なりクライアント・サーバー型ではなく組み込み型の RDBMS です。サーバーを複数台連携させるような大規模なシステムには対応できませんが、シェルスクリプトと同じ単一のコンピュータでの使用という用途では優れたソフトウェアです。
SQLite は POSIX に完全に準拠しており、どの環境でも動くソフトウェアの一つで、実際に世界中で何十億というデバイスに組み込まれています。sqlite3 コマンドという CLI インターフェースが提供されておりシェルスクリプトとの相性も良いです。
SQLite については「利用者は数十億人!? SQLiteはどこが凄いデータベース管理システムなのか調べてみた」で詳しく紹介しています。
Unix コマンドは「データベース管理システム」ではない
SQLite は「データベース管理システム (DBMS)」です。DBMS とは「データ」を集めた「データベース」を管理するための専用のソフトウェアです。それに対し Unix コマンドはファイル管理(cp, rm 等)やテキストデータの加工(sed, awk 等)と言った処理を行うもので DBMS とは全く異なる領域を扱っています。例えば DBMS に投入する前のテキストデータの前処理や出力を整形する後処理に使うのが Unix コマンドで、そのデータを保存したり検索したり取り出す時に使うのが DBMS です。
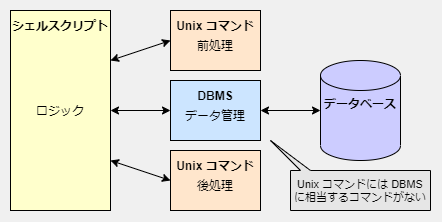
Unix コマンドの出力をそのままファイルに保存すればよいのではないかと思うかもしれませんが、そのような単純なデータ形式では十分な速度や信頼性は実現できません。それを行うのが DBMS であり Unix コマンドに欠けているものです。DBMS が行わなければいけないデータ管理は多く複雑で難易度が高いものばかりです。SQLite は Google、Apple、Microsoft といった OS ベンダーも使用しています。OS はファイルシステムを備えていますが、その OS ベンダーでさえもファイルに直接保存するのではなく DBMS を使っていることから、ただのファイルシステムは DBMS の代わりにはならないということがわかると思います。
wikipedia の データベース管理システムのページでは DBMS の主な機能として以下の項目が挙げられています。
- データベース言語(RDMS では SQL)
- 物理的データ独立性
- 論理的データ独立性
- データ完全性
- トランザクション処理
- セキュリティ
- 障害復旧
- 最適化
- 分散データベース(SQLite では利用できない)
この中で Unix コマンド(awk, join 等)で代替できるのは「データベース言語」に相当する部分だけです。しかも、データ管理に特化した SQL という専用言語に比べると Unix コマンドはデータ管理の機能が劣っています。Unix コマンドを SQL の代替とするならば awk を手続き型プログラミング言語として使い、SQL が提供しているのと同じような機能を自分で実装しなければならないでしょう。
「データベース管理システム」を使わない開発は生産性が低い
もしシェルスクリプトと Unix コマンドで DBMS と同じことをするのであれば相当な量のコードを書くことになります。軽く考えただけでも、検索を速くするためのインデックスはどうするか?更新速度を早くするためのファイル・ディレクトリ構造はどうするか?データに空白や改行が入る場合はどうするか?トランザクションを実現するための処理はどう書くか?排他制御はどう行うか?予期せぬシャットダウンでのゴミデータをどうクリーンアップするか?などといった課題を思いつきます。もちろんテストも必要ですし、Unix コマンドは移植性が低いためどの環境でも動かそうと思うのであれば、それぞれの環境の動作の違いを自分で吸収しなければなりません。これらをすべてやっていては、いつまでたっても目的のアプリケーションは完成しません。
また自分で書いた部分が少なければ少ないほど仕様変更に強いコードになります。なぜなら書いたコードが少なければ仕様変更時に修正しなければいけないコードも少なくなるからです。逆にコードの量が多ければ多いほど、自分でそれらをメンテナンスし続けなければいけません。自分で作りたい気持ちもわかりますが、後に変更しなければいけないコードが多くて後悔するのはあなた自身です。
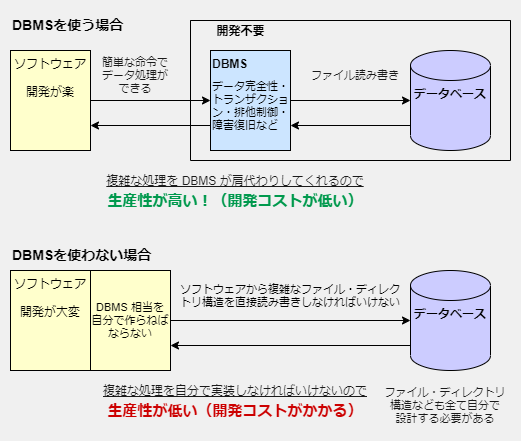
もちろん簡単なシステムであればある程度のことは実現できます。しかしシェルスクリプトと Unix コマンドを使う限り DBMS レベルの生産性や高速性や信頼性を実現することは不可能です。不可能な理由は技術力の問題ではなくシェルスクリプトと Unix コマンドの設計上 OS が持つ全ての機能 (C 言語用のAPI) を使うことが出来ないからです。なので誰がやってもシェルスクリプトと Unix コマンドで本物の DBMS レベルのものを作ることは出来ません。なにが不可能であるかは、この記事の「Unix コマンドを使ったデータ管理は欠点が多すぎる」を参照してください。
「テキスト処理の専門家」は「データ管理の専門家」にはなれない
Unix コマンドが得意なのは「テキスト処理」であって「データ管理」ではありません。データ管理機能がないなら作ればいいと思うかもしれませんが、Unix コマンドにある回避不可能な制限が問題になってきます。その中で特にクリティカルな問題はファイルのランダムアクセスができないという点です。ファイルが大きい場合、その一部だけが必要でも全てを読み込まなければいけないので遅くなってしまいます。それを回避するにはファイルを小さく分割するしかありませんが今度は検索やソートの速度が遅くなってしまいます。工夫すればするほどテキスト形式でありながら複雑な構造を持つ特殊な形式のファイルが必要になってしまい「あちらを立てればこちらが立たず」状態になるでしょう。

データ構造はプログラムから独立しているものです。すなわちシェルスクリプト以外の言語でも同じデータ構造が最適解となるはずです。「何のためのそのようなデータ構造にしたのですか?」の答えが「Unix コマンドの制限を回避するためにこのようにしなければいけない」であったとしたら、それはプログラムに依存したデータ構造であり最適なデータ構造ではありません。これではプログラムを変えるとデータ構造まで変えなくてはいけなくなってしまい変更に弱いソフトウェアになってしまいます。
餅は餅屋と言う言葉がありますが、高度なデータ管理はデータ管理の専門家に任せるのが一番です。Unix コマンドが SQLite に勝てるかもしれないものと言ったらせいぜい排他制御がいらず高度なデータ管理も不要なシーケンシャルな全件読み込み、いわゆるバッチ処理的なプログラムぐらいです。そういうときにだけ Unix コマンドを使えば良いのです。
Unix コマンドによるデータ管理は欠点が多すぎる!
まず最初に断っておきますが、私は Unix (POSIX) コマンドで問題を解決することが「不可能」だとは言っていません。頑張って何かを作ればある程度の問題は解決できます。しかしその開発コストは高くバグを混入する確率も高くデメリットの方が多くなってしまいます。
ある程度の問題は解決出来るからといって DBMS に相当する部分を全部作っていたらいくら時間があっても足りません。ライブラリやコマンドを作るのは大変で時間がかかる作業です。SQLite のソースコードは 14 万行です。そもそもチームで開発するのであれば、どちらにしろ開発した本人以外は他人が作ったライブラリやコマンドを使うことになります。それならばオープンソースで採用実績が多いコマンドやライブラリを使った方がはるかに良いです。すでによく知られた解決策があるのであればそれを使うべきです。でなければ単なる 独自技術症候群 となるでしょう。
ここに挙げた Unix コマンドでデータ管理行う場合の欠点は、軽く考えただけで思いついた程度の例にすぎません。他にもあると思いますし複雑に絡みあった実際の開発ではもっと大きな問題に発展する可能性も秘めています。
Unix コマンドは OS ベンダーがそれぞれ開発しているから互換性が低い
Unix (POSIX) コマンドは本質的に互換性が低いコマンドです。なぜなら各 OS ベンダーがそれぞれ個別に開発または拡張しているからです。SQLite のように実装が一つしかない場合は互換性問題は発生しません。
そもそもなぜ POSIX が必要になったかと言うと互換性が低くて困ったからです。POSIX が登場して互換性問題は解決したのではないか?と思うかもしれませんが解決していません。実は POSIX は POSIX コマンドの仕様を厳密に定めたものではなく、ある程度互換性があるものを文書化しただけです。「ある程度」というのがポイントで完全な互換性がない部分に関しては POSIX で規定はするものの POSIX に準拠したアプリケーションの開発者がやらなければいけない要件として「各 OS での非互換部分に対応しなければならない」と書かれています。この話については「POSIX準拠とは本当はどういうことなのか?「POSIXで規定されたものだけを使う」ではありません」で詳しく解説しています。POSIX コマンドは最初から完全な互換性がないと分かっているコマンドなので、POSIX コマンドを使ってどの環境でも動かすのは大変なのです。
少し前のブラウザの世界を知っている人であれば、多数のブラウザの実装がある = 互換性問題が酷いということを知っていると思います。それが解決したのはブラウザベンダーとは独立している標準化団体 W3C があったからではなく、各ブラウザの実装メーカーが協力して互換性問題を解決しようとした WHATWG の努力の結果です。残念ながら Unix コマンドにそのような流れは生まれていません。OS ベンダー中立でなければいけない POSIX の限界とも言えます。WHATWG のように OS ベンダーが協力して互換性問題を解決する流れが生まれればいいのですが。
ランダムアクセスできないから検索・更新・ソートなどが遅い
以下は一千万件のデータから、目的のデータを検索する例です。この例では Unix コマンド(awk)は sqlite3 に比べると 233 倍も遅い です。データの件数が増えれば増えるたびに Unix コマンドでは検索速度が遅くなってしまいます。
$ sqlite3 db "CREATE TABLE tbl(id INTEGER, value TEXT);"
$ seq -f '%0.0f,abcde' 10000000 | sqlite3 -csv db ".import '| cat -' tbl"
$ sqlite3 db "create index tbl_id on tbl(id);"
$ seq -f '%0.0f abcde' 10000000 > db.txt
$ time sqlite3 db "SELECT value FROM tbl WHERE id = 1234567;"
abcde
real 0m0.004s
user 0m0.004s
sys 0m0.000s
$ # $1 == 1234567 より正規表現の方が速かった
$ time mawk '$1 ~ /^1234567$/ { print $2 }' db.txt
abcde
real 0m0.932s
user 0m0.900s
sys 0m0.032s
「そんなの当たり前だろ!この比較はフェアじゃない!」とすぐに気がつく方は正しくプログラミング技術の基礎を学んでいます。しかし「コマンドを打ったら結果が出る」のように内部の技術的な仕組みを理解せずにブラックボックスとして扱ってる人にとっては、sqlite3 も awk も同じコマンドなわけで、なぜこのような差が生まれるのかを理解できません。私が危惧しているのはそこです。場合によっては sqlite3 よりも awk が速い場合もあります。どちらが一方の技術が常に優れているということはまずありません。どのような場合にこのような結果になるのか、その理由を理解するにはプログラミング技術の基礎を学ぶ必要があります。でなければ作為的に作られた検証結果に騙されてしまうでしょう。検証結果を見ることは重要ですが、その検証方法が正しいかは基礎知識がないと判断できません。
さて、このような大きな差がでるのは、ただのテキストファイルにはインデックスデータがないからです。インデックスはソートにも使われます。ソートは時間がかかるデータ処理ですがインデックスを作成することでソート済みのデータを持つのと等しい状態が得られるため高速になります。インデックス相当のものがないのであれば作ればいいと思うかもしれませんが意味がありません。なぜならシェルスクリプトと Unix コマンドではランダムアクセスが出来ないからです。ファイルをすべてを読み込まずに途中の該当のデータだけを読み込むことは出来ません。
これを回避するためにプライマリーキーに相当する部分をファイル名にしてランダムアクセスっぽいことを実現することを思いつくかもしれませんが、それが使えるのはキーから値を取得する KVS のような使い方をする場合のみです。ファイル名をプライマリーキーにする方法では、B-Tree インデックスを用いて数値や日付を二分探索で探索するようなことを簡単に実現する方法はありません(アルゴリズム的には実装できなくもないような気がしますが十分な速度がでるとは思えません)。また小さなファイルを多数作ることになるので別の問題が発生します。詳しくは「速度を出すために大量のファイルと複雑な仕組みが必要になる」で解説します。
Unix コマンドはファイルをシーケンシャルに読み書きする場合なら速いですが、データ管理にはランダムアクセスが必要であるためデータが大量にある場合に十分な速度ができません。シーケンシャルな読み書きが速かったとしてもランダムアクセスは遅いのです。
テキスト形式はデータ管理に適切なファイル形式ではない
Unix コマンドによるデータ管理が遅い理由はひとえにテキスト形式であることが原因です。テキスト形式はファイルのランダムアクセスが出来ないため、例えばデータファイルが 1 GB のファイルになってしまうと、その中の 1 行だけ参照または書き込みしたい場合でも 1GB のファイルすべてを読み書きしなくてはいけません。これが Unix コマンドが遅い根本的な理由です。
ファイル形式には適切な形式を選ばなければいけません。Unix コマンドがテキストファイルしか扱えないという理由でバイナリファイルを避けるのは、Unix コマンドの制限を回避するためにファイル形式を選ぶことになってしまっているため、適切なファイル形式を選ぶという基本的な考えから外れています。(おそらく)すべての有名な DBMS はそのデータ形式としてバイナリ形式を利用しているでしょう。それがデータ管理にとって適切なファイル形式だからです。一言で言うのならデータベース用のデータはテキストファイルで保存しては駄目ということです。(注意 CSV ファイルなどのテキストファイルの利用を否定しているわけではありません。小規模であれば CSV でも十分ですし、データ交換用であれば CSV から DBMS に取り込んだり、CSV に出力するという使い方に問題はありません)
Unix コマンドはテキストデータを扱いますが、だからといってファイルまでテキストファイルにする理由はありません。例えば POSIX コマンドでもある zcat コマンドが読み込むファイル形式はテキストファイルを圧縮したバイナリファイルです。テキストファイルのままではファイルを圧縮する目的を達成できない(効果が低い)ので適切なファイル形式としてバイナリファイルを使っています。そして重要なのは zcat があつかうファイルがバイナリファイルであっても、他のコマンドとパイプでつないで連携することが可能であるということです。パイプの本質を正しく理解してさえいればバイナリファイルとテキストファイルの境界をたやすく乗り越えることが出来ます。
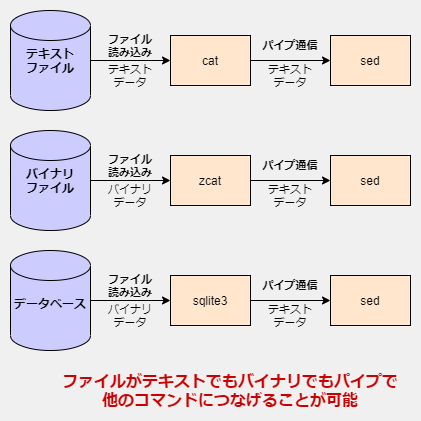
「テキストファイルでなければ Unix コマンドとの連携はできない」というのは大きな勘違いです。多くの Unix コマンドがテキストファイルしか読めないというだけで zcat コマンドなり sqlite3 コマンドなりを使えば、バイナリファイルからテキストデータを抽出することができます。そして他のテキストファイルを読み込む Unix コマンドへ、パイプを使ってテキストデータを渡すことが出来ます。
改行文字やスペースをあつかうのが苦手
Unix コマンドは改行文字やスペースが含まれているデータをあつかうのが苦手です。それらは行やフィールドを区切る文字として扱われます。さらに厄介なことに複数のスペースであっても一つのスペースと同じように扱うコマンドもあります。
# 複数のスペースを一つとみなす
$ echo "a b c" | awk '{ print $2 }'
b
# シェルも同様
$ echo "a b c" | while read -r a b c; do echo "$b"; done
b
# ただし cut は複数のスペースを一つとはみなさない
$ echo "a b c" | cut -f 5 -d " "
b
このような Unix コマンドの違いを考慮するのは面倒なので可能な限り awk コマンドに一元化するというのは良い考えです。複数のコマンドをパイプでつなげるよりもプロセス間通信が少なくなるためデータ処理も効率化します。
複数のスペースを一つのスペースまとめられるのを防ぐ方法は「区切り文字をスペース以外にする」「データの中の改行やスペースを別の文字にエスケープする」の二つが考えられます。データとして改行が入る場合は前者は使えません。またどちらを使用してもエスケープ処理が必要になります。例えば区切り文字を , に置き換えた場合、今度はデータの中の , を \54(8進数)にエスケープしなければいけませんし、データの中の改行やスペースをエスケープする場合、改行は \n、スペースは \40(8進数)になるでしょう。エスケープの方法は、この例のように C 言語スタイルでも良いし別の独自方法を使っても構いませんが、いずれにしろ文字や長さが変わってしまいます。これによって別の問題が発生します。
例えば \n というエスケープされた改行文字が含まれたテキストファイルを sed 's/n/N/g' のように小文字を大文字に変換する処理を行ってしまうと改行文字まで \N に変わってしまいます。grep で数値の部分にマッチさせたいと思った場合 \40(スペース)や \54(カンマ) にマッチしてしまいます。もちろんこれを避けるような正規表現を書けば良いのでしょうかなりややこしくなりますし、データ形式に依存した正規表現なのでプログラムとデータの独立性が失われることになってしまいます。またデータの中の , が \54 に変わってしまうということは文字列の長さが 1 バイトから 3 バイトに代わるということです。これでは awk の length() や substr() でうまく扱うことができません。エスケープの代わりに制御文字に置き換える方法もありますが、データの中に制御文字を入れることができなくなってしまいます。さらにエスケープを行うとソートの順番にも影響を与えてしまうでしょう。このような特殊なエスケープ文字が含まれたファイルを Unix コマンドで正しく扱うのは困難です。
2022-04-03 追記 awk の罠を一つ書き忘れていました。それは \ を \\ に gsub 関数を使ってエスケープするときその書き方が awk の実装によって移植性がないという罠です。回避方法はそんなに難しくはないですが、見落としやすい点です。詳しくは「問「awk で \ を \ に置換せよ」⇒答「gsub(/\/, "\\")」・・・はい残念、間違いでーす。答えは「gsub(/\/, "\\\\")」 でーす。けどこれも動きませーん。」を参照してください。
シェルスクリプトで扱う場合もいちいち VAR=$(printf "$data") のような感じで元に戻さなければデータとして扱えません。面倒な上に何よりこのコード(コマンド置換)はサブシェルを伴うためかなり遅くなります。となるとデータの中に改行文字やスペースが含まれるような場合に取れる手段は全面的に awk を使って処理するしかありません。データ操作を行う時に awk でエスケープした文字を元に戻してから処理をし、そしてエスケープして出力しなければなりません。これではコードは複雑で読みづらいものとなってしまい、データ処理の速度も遅くなってしまいます。
空文字と NULL の扱いが難しい
前項と近い話ですが、空文字や NULL の扱いも難しいです。例えばユーザー登録で必須ではない項目には空文字か NULL が入ることでしょう。しかしこれをファイルに保存するのは困難です。テキストファイルには NULL という概念はないので空文字と区別して保存することができません。また空文字の場合 1 <sp> 空文字 <sp> 3 は 1 <sp><sp> 3 として記録されることになります。連続したスペースは一つとして解釈されてしまうので項目の位置がずれてしまいます。この問題を解決するには前項と同じく「区切り文字をスペース以外にする」か「空文字や NULL を別の文字にエスケープする」必要があります。
後の問題は前項と同じです。特殊な文字はエスケープしなければ正しく扱う事はできませんし、エスケープしたらしたで、今度は Unix コマンドで扱うのが難しくなってしまいます。全面的に awk に依存することになり、それでも複雑で遅いという問題は解決できません。
独自テキスト形式はテキスト形式のメリットが失われる
データに、改行やスペース、空文字や NULL が入るとどうしてもシェルや Unix コマンドが想定している「スペースで各項目が区切られた行単位のデータ」にはならず、独自ルールのエスケープが必要になります。これはテキストファイルであるものの JSON や YAML と同じように独自の構造を持った独自テキスト形式に他なりません。それを扱うパーサーが必要となり、独自形式なので汎用のライブラリは存在せず自分でパーサーを作る必要があります。
独自テキスト形式は、通常と異なるケース、例えば改行やスペースを検索する場合どうするのか?といった独自テキスト形式特有のコードが必要なわけで、Unix コマンドで普通に扱えるとは言えません。less や cat でも読めるのがテキスト形式のメリットですが、一部の文字がエスケープされてしまうので結局読みづらくなってしまいます。独自テキスト形式はテキスト形式であるというメリットが失われてしまっているのです。
独自テキスト形式に対応したツールがない
独自テキスト形式は自分で考えた形式であるため、当然それに対応したツールは世の中に有りません。YAML や JSON であれば、それをテキストエディタで見やすく色付けしてくれるプラグインなどがあったりしますが、独自テキスト形式は自分で作ることになります。もしそのファイルを他の言語から参照する場合、やはり独自テキスト形式を扱うためのコードを書かなければいけません。汎用のテキスト形式ではなく独自テキスト形式を作ってしまうことの弊害です。
独自テキスト形式を使うぐらいなら、CSV (RFC 4180) や JSON lines 形式を使ったほうが良いでしょう。Unix コマンドからはそのまま扱えませんが、より厳密に決められた汎用のテキスト形式であるため、これらを読み書きするツールはあるはずです。CSV 等は less や cat で読みづらいと思うかもしれませんが、これも読みやすいように整形してくれるツールを使えばよいだけです。汎用の形式であればそのようなツールを見つけるのは容易いことでしょう。
速度を出すために大量のファイルと複雑な仕組みが必要になる
ファイルのランダムアクセスが出来ないという問題を回避するために一データを一ファイルに保存することを思いつくかもしれません。プライマリーキーをファイル名にすれば速くなりますがそれでは 1000 万件のデータだと 1000 万個ものファイルを作らねばなりません。通常のファイルシステムはそのような大量のファイルには耐えることが出来ません。どのくらいまで耐えられるかはファイルシステムによって異なるので一概には言えません。大量のファイルを作る場合 inode の数に注意する必要があります。正しく見積もれないと inode が枯渇してしまい容量は空いていても書き込みができなくなります。間を取って 1 万件毎などの単位でファイルを分けようと考えると思いますが、実際にはパフォーマンスは件数ではなくファイルサイズで決まるので件数では判断できません。一定の件数やサイズで分割する場合、データ更新時に増えたり減ったりしたら適切な件数やサイズで再分割する仕組みを作らなければならなくなるでしょう。
またプライマリーキー(ファイル名)からの取得は速くても、それ以外の項目での検索が遅いという問題を解決することは出来ません。全ファイルを調べなければなりませんしファイルが多いとファイルのオープンとクローズで時間がかります。それらの多数のファイルをソートするのにも時間がかかります。join コマンドでファイルの結合(SQL の JOIN 相当)をする場合には小さなファイルに分割した状態ではできません。これらの問題を解決するにはデータファイルとは別に一時ファイルを作る必要があり全データ分の書き込みが必要です。一時ファイルによる書き込みデータ量の多さは SSD の寿命も気になります。要件が増えるたびに本来のデータとは別にいろんなファイルが必要となり複雑な仕組みを作らねばなりません。
データの追加や削除が行われるたびに、いろんなファイルの整合性を正しく取らなければいけませんし、さらに追加や削除が行われている最中にデータにアクセスされたら?何かしらの理由で途中でコンピュータが停止したら?そういったことに考慮しつつ、すべてを完璧に行うのはとても大変であることは言うまでも有りません。これらの問題は SQL を使えばたった一行もしくは数行で解決します。
join コマンドはインストールされてない環境がある
Unix コマンドを使って RDBMS 的なデータ処理をしたい場合に便利なのが join コマンドです。このコマンドは POSIX で規定されており、どこでも動きそうに思えますが、実際は動かない環境があります。それが BusyBox です。BusyBox は組み込み環境でよく使われている他、Alpine Linux でも使われています。
もちろん Alpine Linux でも CoreUtils をインストールすれば使うことが出来るのですが、追加のインストールが必要なくどの環境でも動くようにしたい場合は使うことが出来ません。どちらにしろインストールする必要があるのであれば sqlite3 をインストール(または実行ファイルをコピー)しても大差ありません。
join コマンドは2つのファイルしか結合できず事前ソートが必要
join コマンドは SQL の JOIN 相当のことができますが、2 つのファイルを結合することしか出来ません。結合に使えるフィールドは一つだけですし、しかも事前にソートされた状態でなければいけません。sort コマンドは大きいデータでも少ないメモリでソートできるように一般的に内部でマージソートが使われています。マージソートを使うためディスクへの書き込みで遅くなります。sort コマンドはすべてのデータを受け取らないとソートできないためパイプを使った並列化の効果が妨げられるという問題もあります。またランダムアクセスできないという問題に対処するため複数のファイルに分割していたりすると、事前に全てを結合してソートした状態の一時ファイルを作らなければいけません。手間が多い上に出来ることは SQL の結合の劣化版です。
一時ファイルを作るには時間がかかります。その間に他のプロセスから書き込みがあるかもしれません。排他制御も必要になります。しかも時間がかかる一時ファイルの生成の間、他のプロセスは書き込みができなくなります。場合によっては読み込みもできなくなります。データが小さいうちはなんとかなるでしょうが、データが増えるたびにブロックされる時間が問題になってきます。
ソートを行う場合は、文字の照合順序(環境変数 LC_ALL または LC_COLLATE)に気をつける必要があります。sort コマンドで使う照合順序と join コマンドで使う照合順序が異なっているとソートされた状態になりません。POSIX によると C (POSIX) ロケール以外は移植性があるとは限らないということになっているので、C ロケール以外でソートするのは危険です。sort コマンドはロケールに対応しているが join コマンドは対応していないという環境があるかもしれません。
他にも空文字と NULL の区別をつけられないという問題もあります。SQL でいう LEFT JOIN 相当のことをすると片方が NULL になることがありますが、テキストデータである以上 NULL と空文字の区別はつけられません。-e オプションで NULL になったときの値を指定することが出来ますが、元から空文字であった場合も置き換えられてしまいます。
# a.txt と b.txt はソート済みである前提
$ cat a.txt
a 1
b 2
c 3
d 4
$ cat b.txt
a 11
b
c 13
# NULL と空文字が区別つかない
$ LC_ALL=C join -1 1 -2 2 -o 1.1,1.2,2.2 -a 1 -e - a.txt b.txt
a 1 11
b 2 -
c 3 13
d 4 -
FULL JOIN を行おうと思ったら以下のように複雑な書き方が必要になります。一応説明すると二つのファイルのキーを重複なしで取得し、それに対してそれぞれのファイルを二回に分けて結合しています。cut によるファイルの全件読み込み + sort による全件の読み込み(+ マージソートが使われるので内部で一時ファイルに書き込む場合がある) + join 一回目の全件のデータ処理 + join 二回目の全件のデータ処理で速度もかなり遅くなるでしょう。
cut -f 1 -d " " a.txt b.txt | LC_ALL=C sort -u \
| LC_ALL=C join -1 1 -2 1 -o 1.1,2.2 -a 1 -e - - a.txt \
| LC_ALL=C join -1 1 -2 1 -o 1.1,1.2,2.2 -a 1 -e - - b.txt
このような制限と注意事項と分かりづらいコードが必要になる join コマンドよりも SQLite の方が速くて簡単で安心なのは言うまでも有りません。join コマンドが必要となった時点で SQLite を使うことを考慮すべきでしょう。
フィールド番号によるコードはメンテナンス性も低い
上記の join の例からもわかると思いますが、単純なテキストファイルにはフィールド名というものがなくフィールド番号を使ってコードを書かなければいけないので可読性が低くなります。join コマンドであれば以下のように書くなどの工夫をしていればどうにか対応できるかもしれません。DRY を考慮して一つのフィールド定義ファイルにでもして置くと良いでしょう。
JOIN_KEY_A=1
JOIN_KEY_B=1
A_KEY=1.1
A_VALUE=1.2
B_VALUE=2.2
. ./fields.sh
join -1 "$JOIN_KEY_A" -2 "$JOIN_KEY_B" -o "$A_KEY","$A_VALUE","$B_VALUE" -a 1 -e - a.txt b.txt
同様の問題は awk でも発生します。 { print $2 } のようににフィールド名ではなく番号で指定しなければいけません。これに関しても以下のように対策方法はあります。awk でもライブラリのようなことは出来るのでフィールド定義ファイルを作ることも出来ます。
BEGIN { value=2 }
{ print $value }
echo "a b c" | awk -f fields.awk -f main.awk
# または
echo "a b c" | awk "$(cat ./fields.awk)"'{ print $value }'
工夫をすれば可読性を上げることは出来るとは言えやはりハック感があります。
フィールド名でアクセスできるかフィールド番号でアクセスできるかは重要な問題です。例えばソースコード全体から name を参照しているところを見付け出すにはどうすればよいでしょうか?番号ではファイルの構造が変わったときの影響範囲は分かりづらいものとなってしまいます。小さなシェルスクリプトならフィールド番号でもどうにかなりますが、大きくなると破綻します。シェルスクリプトには型がないのでせめて名前でアクセスしたいものです。
コマンド名が直感的ではなく分かりづらいコードになる
Unix コマンドを多数使ったテキスト処理は分かりづらいコードになりやすいです。それは多くの Unix コマンドが帯に短したすきに長しなコマンドになっているのが原因だと考えています。
Unix コマンドは単純な機能を持っているように見えますが、実際には複数の機能を持っています。tr コマンドは文字の置換と -d オプションによる文字の削除の二つの機能を備えていますし、sort は -u オプションで uniq 相当の機能を持っています。実際に行われる処理を把握するには短いオプションの意味を覚えなければいけません。
sed や awk に至っては多数の機能を持っています。これは sed や awk が言語相当のものだからです。例えば sedの s は sed 専用の命令であり sed でしか使えないものです。このような小さな言語はミニ言語と呼ばれたりします。awk に至ってはチューリング完全なプログラミング言語です。しかし sed や awk なしに高度なテキスト処理を行うのは難しいでしょう。これは Unix コマンドが機能不足であることを意味しています。
cut、tr、sed、grep で行う処理はおそらく awk コマンド一つに集約することが出来ると思いますが、それでも足りないのが SQL の JOIN や集計機能 (group by) やソート (order by) に相当する機能です。awk だけで出来ない場合、複数の Unix コマンドを巧妙に組み合わさなければなりません。これではシェルスクリプトが複雑になってしまうのは仕方ない話だと思います。
複数の Unix コマンドを組み合わせたデータ処理の大部分は、awk 言語よりもデータ管理に適した SQL という言語で実現することが出来ます。awk 言語での実装は不可能ではないと思いますが手続き型言語で本来テキスト処理を行うものであるため、データ管理を行うには機能不足で長いコードが必要になるでしょう。宣言型プログラミング言語でデータ管理に最適化された専用言語である SQL は十分な機能を備え awk よりもはるかにシンプルに記述することができます。
CSV や JSON を扱うのが苦手
Unix コマンドには CSV や JSON を扱うコマンドがありません。CSV は awk で扱えそうな気がしますがデータの中に改行やカンマが含まれていると困ります(GNU 拡張を使えば出来るような話を聞きましたが)。JSON データは行志向となっておらず(行志向の JSON Lines であっても)一部の文字はエスケープされていたりします。
ということでちゃんと扱おうと思ったら CSV を扱うコマンドや jq コマンド等を使った加工が必要となります。もちろん awk を使って CSV パーサーや JSON パーサーを実装することは可能ですがライブラリやコマンドを自作してそれをインストールして使うぐらいなら、よく知られたコマンドをインストールして使う方が楽で信頼性も高いです。
さて、では CSV や JSON がファイルに保存されているとして、そのデータに対して検索や集計処理を行うにはどうすれば良いでしょうか?例えば「ある商品は月曜日にいくつ売れたか?」みたいな問い合わせです。データ構造をよく設計しない限り、このような問い合わせに柔軟に対応したり高速にデータ処理したりすることは難しく、多くのコードが必要になるでしょう。不可能ではないけれど大変だから苦手であるという理屈です。
日付・時刻の処理が苦手(時間がかかる)
例えば 1 万件のデータの中から一週間以内のデータを取得したいといった時、ランダムアクセスができない Unix コマンドでは全件のデータの中からデータの絞り込みを行わないといけません。さらに日付データが 20220301 のような形式で保存されている場合、180 日前の日付がであるかそれぞれ計算する必要があります。これはデータ処理に時間がかかるということを意味します。計算のコストを考えるとデータベースには YYYYMMDD 形式ではなく Unix タイムで記録するのが良いでしょう。
日時の計算だけなら大したことでは有りません。私も以前「シェルスクリプトでUNIX時間⇔日付の相互変換を行う関数(POSIX準拠)」の記事で書きましたが、UNIX タイムから通常の日付形式でも、通常の日付形式から UNIX タイムへも、ある計算式を使うだけで簡単に変換できるので、シェルスクリプトだけでも実装できますし awk で実装することも出来ます。しかしデータ管理となるとその先があります。
重大な問題は Unix コマンドでは日付や数値のインデックスが使えないという点です。「何日前」といった範囲での絞り込みは DBMS では B ツリーインデックス、つまり数値(Unix タイム)の順番でデータを並び替え二分探索で対象データの範囲を絞り込みます。このようなデータ処理はファイルのランダムアクセスが出来ない Unix コマンドで行うのは困難で高速にデータ処理することが出来ません。キーをファイル名にする方法では B ツリーインデックスにはなりません。
Unicode に完全対応できない(多数の awk 実装は Unicode 非対応)
Unix コマンドは Unicode に完全対応できておらず、文字列の長さや文字の位置を扱う処理でどこでも動く移植可能な方法は(おそらく)ありません。この事実は SQL の length()、substr() 相当のデータ処理を awk では移植性がある方法で実装することができないということを意味します。
以下の例は同じ Ubuntu 18.04 環境上での substr の実行結果です。
$ echo あいうえおかきく | LANG=ja_JP.UTF-8 LC_ALL=ja_JP.UTF-8 gawk '{ print substr($0,4,3) }'
えおか
$ echo あいうえお | LANG=ja_JP.UTF-8 LC_ALL=ja_JP.UTF-8 mawk '{ print substr($0,4,3) }'
い
$ echo あいうえお | LANG=ja_JP.UTF-8 LC_ALL=ja_JP.UTF-8 original-awk '{ print substr($0,4,3) }'
い
$ echo あいうえお | LANG=ja_JP.UTF-8 LC_ALL=ja_JP.UTF-8 busybox awk '{ print substr($0,4,3) }'
い
LC_ALL をちゃんと設定していることに注目してください(LANG は必要ありませんが念の為です)。それでも gawk しか正しく Unicode 文字を扱えていません。
awk が Unicode を扱えない問題は substr() だけではなく文字列全てに当てはまります。文字列の長さや正規表現の .(任意の一文字にマッチ)でさえ正しく扱えません。これでは OS に標準でインストールされている awk を使って安心してデータ管理を行う事ができません。もちろん gawk をインストールすればよいのですが、それならば SQLite をインストールしたほうが良いでしょう。
awk の代わりに別のコマンドを使うということを考えるかもしれませんが、Unicode に対応していないのは awk だけではありません。BusyBox の sed も Unicode に対応していません。
$ echo あいうえおかきくけこ | LANG=ja_JP.UTF-8 LC_ALL=ja_JP.UTF-8 sed 's/...\(...\).*/\1/'
えおか
$ echo あいうえおかきくけこ | LANG=ja_JP.UTF-8 LC_ALL=ja_JP.UTF-8 busybox sed 's/...\(...\).*/\1/'
い
# 文字の途中で切られている場合、エラー (sed: write error) になります。
さらに cut も対応していません。
# GNU
$ echo あいうえおかきくけこ | LANG=ja_JP.UTF-8 LC_ALL=ja_JP.UTF-8 cut -c 4-9
いう
# BSD (macOS)
$ echo あいうえおかきくけこ | LANG=ja_JP.UTF-8 LC_ALL=ja_JP.UTF-8 cut -c 4-9
えおかきくけ
このことから Unix コマンドだけでどの環境でも正しく Unicode 文字列を扱うのは極めて大変であるということがわかると思います。awk はフィルタコマンドとしての用途があり、できれば Unicode をまともに扱えるようにしたいので、そのうちクロスプラットフォームな Unicode を扱える awk 用ライブラリを作れればいいなとは思っています。(探せば見つかるかな?)
2022-04-03 追記 この問題については「【注意】POSIX awk は日本語文字 (UTF-8)を正しく扱うことが出来ません」でも記事にしています。
整合性を保つのが難しい
DBMS には整合性を保つための制約を定義することができます。例えば NOT NULL 制約、UNIQUE 制約、CHECK 制約、外部キー制約などです。しかし Unix コマンドというかテキストファイルにはそのような制約を定義することはできません。つまり制約は全てアプリケーション側で実装することになります。
大変な作業ですし、もしアプリケーションにバグがあれば、ちょっとのミスで壊れたデータを作ってしまい、それに気がつかずに不正なデータ処理を行ってしまう可能性があります。
プログラマがミスをしなければいいと思うかもしれませんが人間はミスをする生き物なのでミスを防ぐための仕組みがあった方が良いのは言うまでもありません。制約によってバグを完全に防ぐことは不可能ですが、整合性が保てないような大きな問題を防ぐことは出来ます。
移植性がある排他制御のコマンドがない
シェルスクリプトで排他制御を行うのであれば flock コマンドを使うのが一番です。一つ問題点があるとすれば、これは移植性があるコマンドではなく使えない環境があります。ただし macOS や FreeBSD でも使える flock の実装を作っている方がいるのでこれを使用すると良いでしょう。(注意 私は試していません)
flock を使わなくてもシェルスクリプトと Unix コマンドだけで自分で作れると思うかもしれませんがこれは悪い考えです。flock 相当のものを実装するには OS の API であるファイルの排他ロックや共有ロックの機能が必要です。これはプロセスが生存している間だけファイルにロックを掛けることができます。しかしシェルスクリプトと Unix コマンドでは OS の API を利用できないので、一時ファイル(いわゆるロックファイル)を使って似たような処理を行うしか有りません。しかしこれはプロセスの生死と無関係なのでプロセスが異常終了した場合の対応が大変になってしまいます。
例えばロックファイルでのロック中に想定外の OS シャットダウン(停電など)が発生したら OS 再起動時に残っているロックファイルの削除処理を行わなければならないでしょう。これは再起動時に行えば良いので比較的簡単です。しかし OS のシャットダウンを伴わないアプリケーションのバグなどでロックファイルを削除せずにプロセスが終了してしまった場合、永遠にロックファイルが残ってしまいます。これに対処するには cron などで長時間ロックされた状態を検出し削除するという対処療法を思いつきますが、一体どれくらいの時間残っていた場合に削除すればよいのでしょうか?短すぎると問題なくデータ処理が行っているのに、誤判断でロックファイルが削除されてしまいますし、長すぎると長時間他のプロセスで読み書きができなくなってします。cron の設定をするのは面倒ですし、どっちみち cron をインストールするぐらいなら flock をインストールした方が良いです。
他にはロックファイルにプロセス ID を記録していてプロセスの生存確認を行う方法が考えられます。一秒間隔でチェックすれば、CPU の負荷も小さく長時間ロックされることもなく、比較的な安全な実装になるかもしれません。次の問題は共有ロックをどうするかです。共有ロックをかけているプロセス一覧を管理ファイルに記録すればどうにかなりそうな気はします。例えば Excel とかはそのようなロックファイルを作りネットワーク共有した状態でも共有アクセスを実現しているようです。できるかもしれません。しかし、うーん、やっぱり面倒ですよね。複雑なコードはバグを入れる可能性も高くなります。
うまくやれば flock 相当のものを作れるかもしれませんが、正しく行うのは難しくロックをかける時のパフォーマンスは悪くなります。信頼性が必要とされない場合であればそれでも構わないと思いますが、業務システムのような信頼性が重視される用途では flock と同じようなものをシェルスクリプトと Unix で作るのは悪い考えです。flock はただインストールするだけで使えるのですからそれを使いましょう。あまり有名なプロジェクトではないかもしれませんが、オープンソースなので将来使えなくなるようなことはありません。心配ならフォークしておきましょう。いざとなったら自分でメンテナンスできます。
トランザクションの仕組みがない
Unix コマンドにはトランザクションの仕組みがありません。トランザクションではデータ処理が失敗した時に、それまで変更していたデータを元に戻さなければいけません。これを簡単に解決するにはデータを書き込む際に常に一時ファイルに書き込み、完了時に mv でリネームする方法です。
この方法の問題点はの一つ目は書き込むファイルサイズです。ファイルが 1 GB あれば、それだけのファイルを一時ファイルに書き込むことになます。時間はかかるし SSD の寿命が心配になります。二つ目の問題は一つのトランザクションで複数のファイルに書き込む場合です。一つ目のファイルは mv できたが二つ目のファイルは mv できてない可能性があります。例えば停電です。mv は同じファイルシステム上であれば高速に処理できるため確率は低いですが、それでも発生する可能性はありますし、それが発生すると中途半端な状態になってしまいます。これを防ぐには一つのディレクトリの中に一時ファイルを作ることです。そうすれば一つのディレクトリを mv すればよい・・・ように思えますが、さてそのような事が可能なデータ構造(ディレクトリ構造)はどのようなものになるでしょうか?難しいですね。
またトランザクションを利用する場合は排他制御も必要になることに注意してください。なぜならプロセス A がデータ処理している間に、プロセス B が同じデータを更新してしまったら、プロセス B のデータ処理の後にプロセス A が更新してしまう可能性があるからです。流れとしては排他制御を行って書き込みが行われるファイルのすべて別のファイルに書き込んで最後に mv することになるでしょう。ここでもファイルサイズが大きければロックされる時間が長いと言う問題が発生します。これはファイルのランダムアクセスが出来ないのが根本理由です。ファイルを小さく分割しても意味がないことに注意してください。更新の内容によっては全体をロックする必要があるからです。例えば特定の条件にマッチする全データのフラグを書き換える場合などです。
トランザクションが失敗したときに残るゴミデータのクリーンアップも必要です。下手すればこのデータがストレージを圧迫してしまうでしょう。ただロックファイルのクリーンアップ処理よりは問題は少ないです。なぜならゴミデータが長時間残っていても実害は少ないからです。1 日後でも 1 週間後でも十分長い時間たった後で削除すれば十分です。しかし直ちに実害がないようなものは問題発覚が遅くなるため、長い時間経ってから問題が発生することが多く見逃しやすいバグの一つです。技術的に難しいというよりも注意が必要で手間がかかるため自分で実装するようなものではありません。
障害発生等でデータが壊れやすく修復しにくい
単純なテキストファイルではデータが壊れたかどうかを検出する手段がありません。もしシステム障害で一部のデータが壊れたとしてもそれを検出することが出来ず、壊れたまま動いてしまう可能性があります。もし何かしらの理由でデータが壊れたとしたら、それをいち早く検出、通知することで被害を少なくする必要がありますがテキストファイルでは不可能であるため、時間が経ってからプログラムがおかしな動きをしたりおかしなデータを見つけたりして後から気づくことになるでしょう。DBMS だからといってあらゆるデータの破損を検出することが出来るとは限りませんが、それでもクリティカルな問題は検出できると期待できます。
システム障害が発生した後の復旧は自動的に行われなければなりません。可能な限り短い時間で復旧させるためです。しかしテキストファイルでは壊れたかどうかすらわからないため、テキストファイルを目視で壊れていないか確認するぐらいしか手段がありません。小さいシステムなら可能かもしれませんがデータが何 GB もある場合、目視確認は時間がかかりすぎるため現実的に不可能です。そもそも一体何を根拠に壊れたと判断するのかはわかりません。文字化け程度ならわかるかもしれませんが、複雑な構造を持った大量のデータを相手に手動で直せるはずがありません。複数のファイル感に結局不安があるままシステムを稼働することになってしまうでしょう。そして壊れていることに気づいたときには手遅れです。
悪意がある人やマルウェアなどによる不正アクセスやデータ流出を防げない
テキストファイルはそのまま平文でデータが保存されているため、悪意がある人やマルウェアがデータベースに記録されている個人情報を盗むのは容易いです。高いセキュリティが欲しい場合テキストファイルは役に立ちません。
SQLite にはデータベースを暗号化する機能があります。公式の暗号化は有償ですが無料の実装もあるようです(参考 SQLite with encryption/password protection)。SQLite にはありませんが、他の多くの DBMS は DBMS 自体にユーザー管理の機能を持っています。あるデータセットには読み込みの権限だけを与えるなどしてデータの利用は可能だが、変更はできないと言ったことや、見せるデータの範囲を制限したりすることができます。
シェルスクリプトはローカルのファイルにアクセスするしかないため、これでクラスタリングなどを行おうとするとフロントエンドに全データを複製しなければならなくなるでしょう。そのデータの同期が大変という別の問題は置いといて、フロントエンドは利用者が直接アクセスするため攻撃の経路が増えてしまいます。ネットワークファイルシステムを使うという方法もありますが、全データをシーケンシャルにアクセスするしかないシェルスクリプトと Unix コマンドではさらに遅くなります。
クライアント・サーバー型であればデータベースを論理的に一つのサーバーに分離することが可能であるため、攻撃の経路を絞り込むことが出来できます。そしてファイアウォールや IDS・IPS などの導入によって攻撃を検知したり防御しやすくなります。
アプリケーションプログラムとデータが切り離せない
速度を出すための複雑なディレクトリ構造やエスケープが使われている特殊なファイル形式は、業務ルールの変更による仕様変更に弱いです。もしそれを開発した人がプロジェクトからいなくなった場合、他の人はそれをメンテナンスすることができるでしょうか?
きっちりとしたドキュメントが作成されていれば良いですが(とはいえドキュメントが大量にあったら読むのが大変です)が、ディレクトリ構造やファイル形式に明確な基準がなく、その場の思いつきで雑に設計されていれば、それをコードから読み解かなければなるでしょう。例えばデータにタブが含まれていたらどうするのか?ファイルの区切り文字は何なのか?なぜファイルが分割されている理由はなんなのかなどです。
SQLite は RDBMS なので広く知られた開発手法(正規化など)が使われていると想定できますが、ディレクトリとファイルの使い方は自由であるがゆえに制約が有りません。後任者がそのコードを引き継げるのかどうか、自分たちで開発した部分が多くなればなるほど、それは困難な作業になり、作り直したほうが早いとさえ思えるような状況になってしまうでしょう。
Unix コマンド自体は同じように使えたとしても、Unix コマンドを使って自分たちで作ったシステムはそうでは有りません。独自に作られたシステムは開発した担当者がいなくなればなるほどメンテナンスは難しくなります。可能な限り独自で作る部分を減らすことがメンテンス性を上げることにつながります。DBMS 相当のものまで Unix コマンドを駆使して作ると属人化しやすいシステムが出来上がってしまいます。
パイプで多数のコマンドをつなぎすぎるとパイプ間通信のオーバーヘッドが大きくなる
Unix コマンドは言語である awk を除いて小さい機能しか持っていないため、複数のコマンドをパイプでつなぎがちです。当然ですがパイプ通信にはオーバーヘッドがあります。パイプ通信は OS (カーネル)の機能です。すなわちユーザーランドから呼び出しが遅いシステムコールを呼び出さねばなりません。パイプの使用が少なければさほど問題はありませんが、Unix コマンドの場合パイプを多用しがちであるためパイプ通信のオーバーヘッドが処理速度に影響してきます。
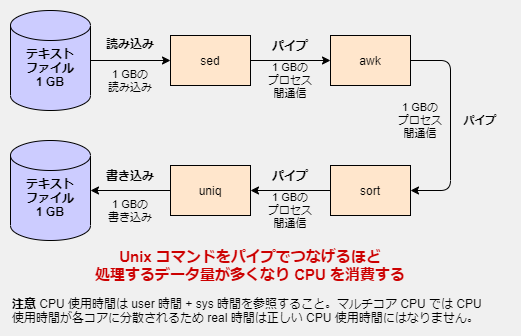
この影響には気が付きにくいことがあります。それは最近の CPU がマルチコア対応だからです。パイプでつないだコマンドは並列で実行されます(パイプライン並列化)。そのためパイプで繋いだコマンドの数が CPU コア数を下回るような小さい実験では余っている CPU コアに処理が振り分けられ実時間が短くなります。しかし実時間が短くなったのは余っていた CPU コアを使ったからなので、CPU の総合計使用時間は増えています。
もちろん実時間が短いことは多くの場合はメリットになのですが、シェルスクリプトを並列で多数起動したりして多数のプロセスを並列で実行しているような場合(例えばウェブアプリにおける CGI はアクセス毎にスクリプトが起動される)はパイプライン並列化にこだわる意味が小さく、CPU 使用時間のオーバーヘッドは逆に実時間まで遅くなってしまうことがあります。パイプは気軽に使える並列化の方法ですが、万能ではなく状況に応じて使い分けるものであり、CPU の性能を引き出すのは難しいです。
シェルスクリプトのパイプラインを使った処理のベンチマークを行う場合、time コマンドの user と sys を確認することを忘れないように注意してください。並列実行で短くなった real(実時間)の影にパイプ間通信(と次項のコマンド起動)のオーバーヘッドが潜んでおり、並列で起動するプロセス数が多くなるとパフォーマンス低下を引き起こすことがあります。
# sort コマンドは内部で並列処理を行っている
time sort data.txt > /dev/null
real 0m4.471s # 実時間
user 0m23.193s # CPU 使用時間の総合計(ユーザー)
sys 0m0.396s # CPU 使用時間の総合計(カーネル)
コマンド起動やファイル読み書きのオーバーヘッドが大きい(メモリを活用できない)
注意 この問題は SQLite を使っても解決しません。
Unix コマンドのシーケンシャルアクセスしかしないという性質は、少ないメモリで動作するというメリットがあります。これは Unix コマンドが誕生した 30 年前の時点において重要なことだったに違いありません。今でも組み込みコンピュータなどでは省メモリであることは重要です。しかし今日においてデスクトップやサーバーコンピュータにおいては数十 GB の大容量のメモリを搭載しているということはごく普通の話になっています。
SSD が登場したとはいえメモリに比べてストレージからの読み書きは時間がかかります。またコストの問題から SSD ではなくあえて HDD を使用する場合もあります。この遅いストレージを避けるためクライアント・サーバー型の DBMS では、データをメモリに読み込んで、メモリだけで処理を行い、ストレージへの読み書きを最小化します。しかしこのような手法は Unix コマンドでは使うことができません。なぜならコマンドは起動し処理を実行した後、プロセスは終了してしまいメモリは解放されてしまうからです。ファイルキャッシュによるメモリ使用はありますが、DBMS 内のデータの効果的なメモリ配置は失われます。
クライアント・サーバー型の DBMS やその他のミドルウェアというのは常にプロセスを起動しており、シェルスクリプトのコマンド実行のオーバーヘッドやファイル読み書きのオーバーヘッドを減らすことで高速化を図っています。ではシェルスクリプトからそのミドルウェアを利用すればいいのでは?と思うかもしれませんが、シェルスクリプトと Unix コマンドはプロセス間通信にパイプしかサポートしておらず、ミドルウェアとの通信で一般的に使われるネットワーク通信に対応していません。正確いえば bash、ksh、zsh はネットワーク通信に対応しているのですが TCP プロトコル止まりで他の言語のような高レベルのライブラリはほとんどありません。
この問題はシェルスクリプト全般に当てはまるので sqlite3 コマンドを呼び出す SQLite でもこの問題は解決できません大規模システムにおいてハードウェアの性能を引き出すにはシェルスクリプト以外の言語を使い、コマンド起動やファイル読み書きのオーバーヘッドを回避できるミドルウェアを使用するのが高性能なシステムを実現する方法です。
まとめ コマンドセットを独自開発するぐらいなら SQLite を使う
以上、シェルスクリプトと Unix コマンドを使って DBMS 相当のデータ管理をすることがどれだけ大変であるかを解説してきました。これらの問題に解決する方法の一つは Unix コマンドに変わる包括的なコマンドセットを見つけるか自分で作ることです。完全なコマンドセットがあればシェルスクリプトと Unix コマンドを使っても簡単にデータ管理はできるようになるでしょう。しかし残念ながらそのような包括的なコマンドセットはありませんし、自分で作るのはとても大変な作業であり現実的では有りません。
実は過去にこのような包括的なコマンドは存在していました。それが「NoSQL という名前のソフトウェア」です。世間一般で言われている NoSQL 型のデータベースのことでは有りません。そのような名前のオープンソースの Unix コマンドセットありました。また同じジャンルの商用のコマンドセットである /rdb というものもありました。どちらも Unix コマンドの連携として RDBMS を実現するものなのですが、どちらもプロジェクトは終了しています。詳しくは「あなたは世界初の「NoSQL」はシェルスクリプト用のRDBMSだと知っていますか?」を参照してください。やはり Unix コマンドの延長上で RDBMS を実現するというアイデアは筋が悪いのだと思います。
そこで代わりになるのが SQLite です。基本的に sqlite3 コマンド一つでデータ管理の全てを行うことが可能であるため、シェルスクリプトと Unix コマンドの制約を受けません。内部で最適な構造のファイルを使い最適なデータ処理を行うことが出来ます。sqlite3 コマンドは既存の Unix コマンドとの連携もできるためシェルスクリプトと Unix コマンドで苦手なデータ管理を SQLite に任せることが出来ます。
自分で頑張って DBMS を作るか、それともそのような開発コストがかかる部分は SQLite にまかせて、自分が本当に作らなければいけないアプリケーションの開発に力を注ぐかです。すでにあるものを再発明した所で、新しく得られるものは何も有りません。ただ時間を無駄に消費するだけです。本当に作るべきものはなにかというその目的を見失わないようにしてください。
SQLite で解決できるシェルスクリプトの問題
ここでは Unix コマンドの問題点を SQLite がどれだけ簡潔に解決するかを解説したいと思います。
SQLite は POSIX 準拠アプリケーションでどの環境でも動く
SQLite は POSIX で規定されている僅かな C 言語の標準関数しか使っていない POSIX 準拠のアプリケーションです。そのためどの環境でも簡単に動作します。さらに Windows 向けのバイナリもあるので、実際には POSIX の範囲を超えてどの環境でも動くコマンドです。(Windows 用のバイナリはこちらから SQLite Download Page)
余談ですが Windows 用の BusyBox を使うと WSL や Cygwin を使うことなくシェルスクリプトと基本的な Unix コマンドが含まれた実行環境を手に入れることができます。BusyBox も SQLite もどちらも小さなサイズの単一の実行ファイルで配布されておりインストーラーでインストールすることなく実行ファイルをコピーするだけで動くので Windows 上でもシェルスクリプトを使ったデータ管理ができます。
SQLite はインストール・ビルドが簡単で面倒な設定は一切不要
SQLite は通常はインストールされていませんが、殆どの環境でパッケージが用意されているのでインストールは簡単です。パッケージが用意されてなくとも簡単にコンパイルすることができます。sqlite3 コマンドは一つの実行ファイルなので(ターゲット環境にビルドしていれば)単純に実行ファイルをコピーしても動作します。
実行ファイルをコピーしなければ使えないことが気になるかもしれませんが、シェルスクリプトを動かすならどちらにしろそのシェルスクリプトをコピーしなければいけないわけで、ついでに sqlite3 コマンドもコピーするだけです。すなわち実行環境に標準で SQLite がインストールされていないことは何も問題になりません。実行ファイルをどこかのサーバーにでもアップロードしておけば、それをダウンロードするだけなので、git clone やインストールスクリプト等でたくさんの補助コマンドセットをインストールしたりするよりもはるかに簡単です。ビルド済みの実行ファイルは公式サイトでも配布されています。
ソースコードからのビルドは以下の手順です。依存関係が殆どないので一般的なビルド環境さえあれば以下を実行するだけで 1 分程度で完了します。(詳細は How To Compile SQLite 参照)
# 事前にインストールが必要なパッケージはわずか(以下は Debian の場合)
# apt-get update && apt-get -y install wget unzip gcc libreadline-dev
wget https://www.sqlite.org/2022/sqlite-amalgamation-3380100.zip
unzip sqlite-amalgamation-3380100.zip
cd sqlite-amalgamation-3380100/
gcc -Os -I. -DSQLITE_THREADSAFE=0 -DSQLITE_ENABLE_FTS4 \
-DSQLITE_ENABLE_FTS5 -DSQLITE_ENABLE_JSON1 \
-DSQLITE_ENABLE_RTREE -DSQLITE_ENABLE_EXPLAIN_COMMENTS \
-DHAVE_USLEEP -DHAVE_READLINE \
shell.c sqlite3.c -ldl -lm -lreadline -lncurses -o sqlite3
またクライアント・サーバー型の MySQL や PostgreSQL とは違い、設定作業は一切不要(SQLite Is A Zero-Configuration Database)です。awk コマンドの代わりに使うような感じで sqlite3 コマンドを使うことが出来ます。
SQLite はファイルの管理・バックアップが簡単
SQLite はデータベースファイルが単一ファイルとなっているためファイルの管理やバックアップが簡単です。普通のファイルと同じようにコピーするだけです。別のサーバーに同じデータベースを複製しようと思った場合、たった一つのファイルをコピーするだけです。
Unix コマンドを使った場合、パフォーマンスを挙げたりするために複雑なディレクトリ構造と多数のファイルを作ることになるためファイルの管理が面倒になりますが SQLite ではそのようなことが有りません。
SQLite のデータベース形式は互換性が高く長期保存に適している
SQLite のデータベース形式は長期保存に推奨できるとの米国議会図書館のお墨付きなので、将来、読み書きができなくなることも有りません。まあオープンソースの時点でそんなことはあるはずがないのですが、こうやってファイル形式が公開されていることは、他の言語で新たに完全な別実装を一から作ることも可能であるということです。
仕様が公開されておりフォーマットが厳密に定義されており、さらにパージョンアップなどで互換性がなくなることも有りません。将来のことはわからないとは言うものの、少なくとも 2050 年までは互換性をなくさずにサポートを続けると公表されています。(Long Term Support)
もしバイナリファイルで保存することに不安があるのであれば、テキストファイルの形でダンプするだけです。
ソフトウェア(シェルスクリプト)の寿命が長くなる
ソフトウェアは劣化することがありませんが、ソフトウェアにも寿命はあります。その要因はいくつかあります。例えば
- コンピュータのハードウェアサポートが終了した
- OS のサポートが終了した
です。ハードウェアサポートが終了したのであればハードウェアを交換しなければいけませんし、OS のサポートが終了したのであれば、どちらにしろアップデートしなければいけません。
- SQLite のサポートが終了した
これれに関しては 2050 年までのサポートと、完全な下位互換性を維持することを約束している ので問題になりません。オープンソースで無料で使えるので何も問題はないでしょう。
- 利用している外部サービスが終了したり仕様が変更になった
例えば Twitter に依存しているソフトウェアは Twitter が終了したり仕様が変更になったら動かなくなります。利用している側はどうしようもありませんが、これを回避するのであれば複数のサービスに対応するとか乗り換えやすく作っておくと所でしょうか。そのためにはソフトウェアの設計をうまく抽象化(ラッパー関数などで具体的なサービスを隠蔽するなど)しておく必要があります。コストがかかるのでどこまでやるかの見極めは必要です。
- 会社が倒産したりプロジェクトが終了した
悲しいですが実際ある話です。いくら良いソフトウェアを作ったとしてもそのユーザーがいなくなればソフトウェアの寿命です。
さてこれらは外部要因なので基本的にはどうしようもありません。ソフトウェアの開発者に関しての寿命の要因には以下のようなものがあります。
- ソフトウェアが変更に耐えられなくなった
ソフトウェアは使われている限り変更し続けるものです。使われているのにメンテナンスなしで放置できるようなソフトウェアはありません。従って保守しやすい(変更しやすい)ソフトウェアが寿命が長いソフトウェアです。十分に設計されてしまうとすぐに変更に耐えられなくなってしまいます。それがソフトウェアの寿命です。まさにこの寿命を伸ばすための本がオライリーから出版されています。「レガシーコードからの脱却 ―ソフトウェアの寿命を延ばし価値を高める9つのプラクティス」9つのプラクティスだけを目次より囲繞します。
- プラクティス1 やり方より先に目的、理由、誰のためかを伝える
- プラクティス2 小さなバッチで作る
- プラクティス3 継続的に統合する
- プラクティス4 協力しあう
- プラクティス5 「CLEAN」コードを作る
- プラクティス6 まずテストを書く
- プラクティス7 テストでふるまいを明示する
- プラクティス8 設計は最後に行う
- プラクティス9 レガシーコードをリファクタリングする
個人的には継続的インテグレーションやテストやリファクタリングに注目したいところですが、とりあえず今は「「CLEAN」コードを作る」です。この CLEAN というのは以下の頭文字をとったものです。
- Cohesive (凝集性)
- Loosely Coupled (疎結合)
- Encapsulated (カプセル化)
- Assertive (断定的)
- Nonredundant (非冗長)
詳細は長くなるので避けますが、コードは依存しているものが少なくなるほど変更が簡単になります。この記事の話に置き換えれば多数の Unix コマンドに依存するよりも、一つの SQLite に依存した方が良いということです。SQLite をライブラリとしてみれば自分で DBMS を作るのに比べて、カプセル化されて疎結合な状態になりますし、重複コードを減らし冗長性を避けることもできます。コードを CLEAN な状態に保っていればソフトウェアの寿命は長くなります。
ソフトウェアの寿命を伸ばすには保守可能なコードでなければいけません。ソフトウェアの寿命で悩んでいる人はぜひ読むことをおすすめします。
他の言語と共通で使えるデータベースファイル
SQLite は多くの言語で使うことが出来ます。これはシェルスクリプトからデータを投入し Python などの他の言語から参照や更新が出来るということを意味しています。テキストファイルでも同じだと思うかもしれませんが、それは複雑なファイル形式やディレクトリ構造を持ってない場合に限った話です。テキストファイルであっても特殊なエスケープ処理を行っていたり、正規化のようにファイルを複数に分割している場合、それらの構造を理解してないと正しく扱えません。
高度なデータ管理では、何かしらの独自のファイル形式とディレクトリ構造を使うことになるので、シェルスクリプト以外の言語で参照する場合は、その独自のファイル形式とディレクトリ構造を読み書きするコードを書かなければいけなくなります。更新も行うのであればトランザクションや排他制御なども実装する必要があります。ただでさえデータ管理のコードを書くのは面倒くさいのに同様のコードを言語ごとに書くなんて嫌ですよね?
このような場合に SQLite のデータベースファイルを共通のファイル形式として使えば、言語を横断してデータ管理を行うことが出来ます。これはグルー言語としてのシェルスクリプトの役割、複数の言語で作られたコマンドを連携させるという用途に非常に適しています。
SQL は可読性に優れ機能が豊富でメンテナンス性が高い
SQL はデータ管理のために専用に開発された宣言型プログラミング言語なので、データ管理に最適化されています。可読性がよく、速度が速く、メンテナンス性が高いです。Unix コマンドは機能が不足しているため、高度なことをしようとしたらほぼ必ず手続き型言語として awk を使いデータ管理のための面倒なロジックを書かなければならないでしょう。
例えば、ユーザーテーブルにユーザーを登録し、最終ログインから 6 ヶ月(正確には 180 日)以上たったユーザーを無効(active フラグを false)にして、無効になっているユーザー数を返す処理を行うとしましょう。
CREATE TABLE users(id INTEGER PRIMARY KEY AUTOINCREMENT, name TEXT, last_login DATETIME, active BOOLEAN DEFAULT true);
BEGIN;
INSERT INTO users(name, last_login) VALUES("佐藤", date('now','-100 days'));
INSERT INTO users(name, last_login) VALUES("田中", date('now','-200 days'));
INSERT INTO users(name, last_login) VALUES("鈴木", date('now','-300 days'));
COMMIT;
# サンプルコードとして意図的に別トランザクションにしています
UPDATE users SET active = false WHERE last_login < date('now','-180 days');
SELECT count(*) FROM users WHERE active = false;
SQL であればわずかこれだけです。トランザクション処理は SQL の実行時に自動的に行われます。無駄がありませんし、簡単な英語を知ってさえいれば自然に読むことができます。
同じことをシェルスクリプトと Unix コマンドでやろうとしたらこのようになるでしょう。(コードはイメージです。実際には動きません。)
#!/bin/sh
set -eu
cleanup() {
rm -f ./users.autoincrement.tmp ./users.tmp
}
trap 'cleanup' EXIT
# lib.awk には SQLite の date 関数と互換の関数が定義されているものとする
AWKLIB=$(cat ./lib.awk)
exec 9>./lock
# 排他ロック(ロックできるまで待つ)
flock 9
# 書き込めない可能性があるため一時ファイルに書き出してからリネーム
id=$(cat ./users.autoincrement)
echo $((id + 3)) > ./users.autoincrement.tmp
mv ./users.autoincrement.tmp ./users.autoincrement
# トランザクションのために別ファイルを作成する
cp ./users ./users.tmp
awk -v id="$id" "$AWKLIB"'
BEGIN {
print id + 1 "佐藤", date("now","-100 days") true;
print id + 2 "田中", date("now","-200 days") true;
print id + 3 "鈴木", date("now","-300 days") true;
}
' >> ./users.tmp
mv ./users.tmp ./users
flock -u 9
# 排他ロック(ロックできるまで待つ)
flock 9
# トランザクションのために別ファイルに出力する
awk "$AWKLIB"'
$3 < date("now","-180 days") {
print $1 $2 $3 false
next
}
{ print $0 }
' < ./users > ./users.tmp
mv ./users.tmp ./users
flock -u 9
# 読込中に書き換えられると困るので共有ロック
flock -s 9
cut -f 4 -d " " users | grep false | wc -l
flock -u 9
長く読みづらいコードとなってしまいます。排他制御やトランザクションをちゃんとやるとこれぐらい必要なのです。autoincrement 用のファイルも処理中に他のプロセスからの読み書きがあると困るので排他制御が必要になります。例えば現在の番号が 10 だとして、同時に別のプロセスが読み込んで同じ 10 で処理を開始してしまうのはまずいです。他のプロセスが読み込まないように排他ロックを使う必要があります。awk は機能が少ないため日付関数を自分で作る必要があります。件数を数えている最中に書き換えられるのも困るため読み込みだけでも共有ロックが必要です。そういう複雑なことをいちいち考えなければなりません。
またこのコードはプロセスが異常終了した場合の処理を含めていますが、ハードウェア障害などによる予期せぬ電源断がおきてしまえばトランザクションファイルが残ってしまいます(おそらく残っていても問題と思いますが)。日付周りの awk 用関数は省略しているので少なくとも何十行かは追加でコードが必要になります。
これがデータ管理の専用言語と、テキスト処理のコマンドを駆使した場合の違いです。個別の小さなサンプルコードだと気づきにくいこともちゃんと動くレベルのもので比較すればすぐに問題がわかります。これを見れば誰もが **「Unix コマンドでデータ管理するのは無理だな」**と思うのではないでしょうか。しかもここまで無理しても遅いままです。RDBMS (SQL) を使えば無理せずに高速で堅牢なものを作ることが出来ます。
出力形式を読みやすく変更でき Unix コマンドとの連携もできる
最新版 (3.38) では以下の出力形式をサポートしており、その後の処理で必要な形式で出力したり、表示を見やすく整形したりすることが出来ます。
sqlite> .help mode
.mode MODE ?OPTIONS? Set output mode
MODE is one of:
ascii Columns/rows delimited by 0x1F and 0x1E
box Tables using unicode box-drawing characters
csv Comma-separated values
column Output in columns. (See .width)
html HTML <table> code
insert SQL insert statements for TABLE
json Results in a JSON array
line One value per line
list Values delimited by "|"
markdown Markdown table format
qbox Shorthand for "box --width 60 --quote"
quote Escape answers as for SQL
table ASCII-art table
tabs Tab-separated values
tcl TCL list elements
OPTIONS: (for columnar modes or insert mode):
--wrap N Wrap output lines to no longer than N characters
--wordwrap B Wrap or not at word boundaries per B (on/off)
--ww Shorthand for "--wordwrap 1"
--quote Quote output text as SQL literals
--noquote Do not quote output text
TABLE The name of SQL table used for "insert" mode
box や list を使うと各項目の位置を揃えることが出来るため見やすくなります。一つ問題点としてデータに Unicode 文字が入る場合、全角幅が必要なものでは半角扱いいなってしまうため位置揃えがおかしくなってしまいます。
このような場合は column コマンドと連携させることで位置を揃えることが出来ます。以下は sqlite3 上で Unix コマンドと連携させる方法のサンプルにもなっています。
sqlite> .headers on
sqlite> .mode tabs
sqlite> .once |column -t
sqlite> SELECT * FROM ken LIMIT 10;
f1 f2 f3 f4 f5 f6 f7 f8 f9 f10 f11 f12 f13 f14 f15
01101 060 0600000 ホッカイドウ サッポロシチュウオウク イカニケイサイガナイバアイ 北海道 札幌市中央区 以下に掲載がない場合 0 0 0 0 0 0
01101 064 0640941 ホッカイドウ サッポロシチュウオウク アサヒガオカ 北海道 札幌市中央区 旭ケ丘 0 0 1 0 0 0
01101 060 0600041 ホッカイドウ サッポロシチュウオウク オオドオリヒガシ 北海道 札幌市中央区 大通東 0 0 1 0 0 0
01101 060 0600042 ホッカイドウ サッポロシチュウオウク オオドオリニシ(1-19チョウメ) 北海道 札幌市中央区 大通西(1〜19丁目) 1 0 1 0 0 0
01101 064 0640820 ホッカイドウ サッポロシチュウオウク オオドオリニシ(20-28チョウメ) 北海道 札幌市中央区 大通西(20〜28丁目) 1 0 1 0 0 0
01101 060 0600031 ホッカイドウ サッポロシチュウオウク キタ1ジョウヒガシ 北海道 札幌市中央区 北一条東 0 0 1 0 0 0
01101 060 0600001 ホッカイドウ サッポロシチュウオウク キタ1ジョウニシ(1-19チョウメ) 北海道 札幌市中央区 北一条西(1〜19丁目) 1 0 1 0 0 0
01101 064 0640821 ホッカイドウ サッポロシチュウオウク キタ1ジョウニシ(20-28チョウメ) 北海道 札幌市中央区 北一条西(20〜28丁目) 1 0 1 0 0 0
01101 060 0600032 ホッカイドウ サッポロシチュウオウク キタ2ジョウヒガシ 北海道 札幌市中央区 北二条東 0 0 1 0 0 0
01101 060 0600002 ホッカイドウ サッポロシチュウオウク キタ2ジョウニシ(1-19チョウメ) 北海道 札幌市中央区 北二条西(1〜19丁目) 1 0 1 0 0 0
より便利な外部ツールが利用できる
SQLite が普及している汎用的なツールであるという事実は、関連ツールも多く作られているということです。これは独自のファイル形式を作っている場合では起こらないことです。独自ファイルを扱うツールは全て自分で作るしかないからです。
私が便利そうだと思ったものは dbcli プロジェクトの litecli です。dbcli プロジェクトは各データベース(MySQL や PostgreSQL 等)の CLI ツールのより便利な拡張バージョンを提供しており、コード補完などの機能が追加されています。
これを使うと以下のような、見やすい出力を得られます。前項の例では column コマンドを使って位置揃えを行っていましたが、それが不要です。
db> SELECT * FROM ken LIMIT 10;
+-------+-------+---------+---------+--------------+----------------------+--------+--------------+----------------------------+-----+-----+-----+-----+-----+-----+
| f1 | f2 | f3 | f4 | f5 | f6 | f7 | f8 | f9 | f10 | f11 | f12 | f13 | f14 | f15 |
+-------+-------+---------+---------+--------------+----------------------+--------+--------------+----------------------------+-----+-----+-----+-----+-----+-----+
| 01101 | 060 | 0600000 | ホッカイドウ | サッポロシチュウオウク | イカニケイサイガナイバアイ | 北海道 | 札幌市中央区 | 以下に掲載がない場合 | 0 | 0 | 0 | 0 | 0 | 0 |
| 01101 | 064 | 0640941 | ホッカイドウ | サッポロシチュウオウク | アサヒガオカ | 北海道 | 札幌市中央区 | 旭ケ丘 | 0 | 0 | 1 | 0 | 0 | 0 |
| 01101 | 060 | 0600041 | ホッカイドウ | サッポロシチュウオウク | オオドオリヒガシ | 北海道 | 札幌市中央区 | 大通東 | 0 | 0 | 1 | 0 | 0 | 0 |
| 01101 | 060 | 0600042 | ホッカイドウ | サッポロシチュウオウク | オオドオリニシ(1-19チョウメ) | 北海道 | 札幌市中央区 | 大通西(1〜19丁目) | 1 | 0 | 1 | 0 | 0 | 0 |
| 01101 | 064 | 0640820 | ホッカイドウ | サッポロシチュウオウク | オオドオリニシ(20-28チョウメ) | 北海道 | 札幌市中央区 | 大通西(20〜28丁目) | 1 | 0 | 1 | 0 | 0 | 0 |
| 01101 | 060 | 0600031 | ホッカイドウ | サッポロシチュウオウク | キタ1ジョウヒガシ | 北海道 | 札幌市中央区 | 北一条東 | 0 | 0 | 1 | 0 | 0 | 0 |
| 01101 | 060 | 0600001 | ホッカイドウ | サッポロシチュウオウク | キタ1ジョウニシ(1-19チョウメ) | 北海道 | 札幌市中央区 | 北一条西(1〜19丁目) | 1 | 0 | 1 | 0 | 0 | 0 |
| 01101 | 064 | 0640821 | ホッカイドウ | サッポロシチュウオウク | キタ1ジョウニシ(20-28チョウメ) | 北海道 | 札幌市中央区 | 北一条西(20〜28丁目) | 1 | 0 | 1 | 0 | 0 | 0 |
| 01101 | 060 | 0600032 | ホッカイドウ | サッポロシチュウオウク | キタ2ジョウヒガシ | 北海道 | 札幌市中央区 | 北二条東 | 0 | 0 | 1 | 0 | 0 | 0 |
| 01101 | 060 | 0600002 | ホッカイドウ | サッポロシチュウオウク | キタ2ジョウニシ(1-19チョウメ) | 北海道 | 札幌市中央区 | 北二条西(1〜19丁目) | 1 | 0 | 1 | 0 | 0 | 0 |
+-------+-------+---------+---------+--------------+----------------------+--------+--------------+----------------------------+-----+-----+-----+-----+-----+-----+
他にも GUI ベースのツールなど多数の便利なソフトウェアがあります。
Unix コマンドの読み書き速度の遅さをカバーできる
Unix コマンドの最大の欠点(テキスト形式のファイルの欠点でもある)は、ファイルのランダムアクセスが出来ず、ファイルの頭からシーケンシャルに全てデータ処理することしか出来ないという点です。例えば 1GB のデータが有れば、それをすべて読み込まねばなりません。さらにそれらをパイプでつないだ複数のコマンドでデータ処理を行おうとする場合、データ量の分だけコマンド間のプロセス間通信が行われ、コマンド自体も 1GB のデータ処理を行わなければなりません。これは大きなパフォーマンス低下を引き起こします。
sqlite3 であれば、データファイルが 1 GB だろうと、1 TB だろうと、適切なインデックスが定義してあれば必要なデータにしかアクセスしないので高速にデータ処理を行うことが出来ます。単純な grep 相当の処理でさえ SQLite であれば(行全体でゃなく)検索対象のフィールドだけを検索対象にできるため高速になる場合があります。
この記事での冒頭で紹介した「シェルスクリプト+データベース活用テクニック Bourne ShellとSQLiteによるDBシステム構築のすすめ」では、このことを詳しく検証しています。P6 からの内容を要約すると
実験環境
- CPU: Intel Xeon E5-2620 v2 @ 2.10GB
- メモリ: 40960MB(注 4GB の間違いでは?)
- ディスク: 1 GB のシーケンシャル書き込み 約 13 秒(78.8MB/s)
テストデータ、読み仮名データの促音・拗音を小書きで表記するもの(zip形式) の CSV データを UTF-8、改行コード LF に変換したデータ 17 MB は小さすぎるのでおよそ 12 KB のダミーデータを各行の末尾につけたデータ。
- データ件数: 約 12 万
- テキストファイルサイズ: 1.5GB
- SQLite3 ファイルサイズ: 1.5GB(テキストファイルより 46 MB 大きい)
- 1 件あたりの大きさ: 12.6KB
1. time grep '東泉町' large.csv
2. time selite3 zip.sq3 "SELECT * FROM zip WHERE town LIKE '%東泉町%';"
3. time gawk -F, '$9 ~ /東泉町/{print $4,$5,$6}' large.csv
の比較結果では、grep が 3.68 秒、SQLite は 1.92 秒。これは行全体から検索するしかない grep が不利であるが、データが小さい場合はコマンドの起動に時間を要しない grep の方が速くなったとし、カラムを指定できる gawk を使った場合は 7.83 秒と遅くなったのはフィールド分割のコストであるという結論を述べています。
また、データ更新が必要な場合は
1. time gsed -i '/東泉町/s/,[^,]*$/,yes/' large.csv
2. time sqlite3 zip.sq3 "UPDATE zip SET random='yes' WHERE town LIKE '%東泉町%';"
3. sqlite3 zip.sq3 "CREATE INDEX zip_town ON zip(town);"
time sqlite3 zip.sq3 "UPDATE zip SET random='yes' WHERE town='%東泉町%';"
gsed を使った場合、およそ 1 分強で 1.5 GB のファイル書き込み時間のおよそ 2 倍かかったのに対し、SQLite であればわずか 2 秒。そして適切なインデックスを設定した場合、わずか 0.17 秒で書き込みが完了したというデータが示し、更新頻度があまりないシステムであれば、応答速度に不満はなくフィルタを駆使した手軽さが有利だが、更新が発生するシステムでは大きな問題が発生し RDBMS を使わない手はないと結論づけています。
パフォーマンスの検証は改めて自分でもやってみたいと考えていますが、とりあえず今はこれを引用しておきます。
Unix コマンドの互換性問題を回避できる
Unix コマンドの問題点の一つは同じ名前のコマンドを複数の OS ベンダーがそれぞれ別々に開発・改良したことです。POSIX の仕様を元に開発したのではなく POSIX 誕生より前にバラバラに開発されていたというのが正確です。OS ベンダーがバラバラに開発・改良したために互換性の問題が発生しました。それを解決するために生まれたのが POSIXです。しかし POSIX が登場して互換性問題は解決されたわけではありません。
それは POSIX の方針が互換性のために過去の実装の動きをなるべく変えないようにした = 同じ動きにしなくても良いようにしたからです。代わりに動きが違う部分を明文化することで、POSIX を参照した人に対して注意を促すという方針です。アプリケーション開発者は POSIX を参照することで互換性の問題点という「知識を得られる」から、移植性が高いアプリケーションを開発することが出来るという考え方なのです。POSIX の登場によって Unix コマンドの互換性問題が解決されたのではなく、移植性を高くするための方法を提示したのが POSIX です。
さらに注意すべきことは POSIX には「動作が違う可能性があるから注意せよ」とは書いてあっても実際の実装の動きは書かれていません。それは OS ベンダーが決めることであり POSIX の範囲外だからです。しかし各コマンドの実装の動作の違いをすべて把握できる人なんているのでしょうか?各 OS によるコマンドの動作の違いというのは本質的なプログラミング技術とは関係ありません。仕方なく覚えなければいけないバッドノウハウに類する知識です。各 OS のコマンドの違い詳しくなった所でプログラミングの技術力はあがりませんが、そういったことを覚えないといけないのがシェルスクリプトと Unix コマンドです。
一方 SQLite を開発してる所は一つしか無いので互換性問題は基本的に発生しません。SQLite は全ての環境で完全に同じように動きます。さらに SQLite は高い互換性を保つと明言していることも重要です。SQLite を使えばそのようなバッドノウハウを覚えるという非生産的な作業から開放され、ソフトウェアの本質的な開発に専念できるようになります。
詳しくは「POSIX準拠 とは本当はどういうことなのか?「POSIXで規定されたものだけを使う」ではありません」にて解説しています。
Unix コマンドの Unicode 非対応問題を回避できる
実は Unix コマンドの Unicode 対応は不完全です。シェルとそれぞれのコマンドは別個に開発されているプログラムであるため、それぞれのコマンドが Unicode 対応にする必要があります。そして全てのコマンドが Unicode に完全対応しているとは限りません。実は POSIX で実装が要求されているロケールは C (別名 POSIX)だけです。もちろん C では文字列をシングルバイト文字列として扱うため、例えば UTF-8 で漢字 1 文字が 3 バイト以上になったりします。
そもそも互換性の維持のため安易に Unicode に対応するわけにもいかないという話があります。今まで Unicode を 3 バイトとして扱っているコードは、Unicode に対応すると動作が変わってしまいます。Unicode に対応していないという問題は、シェルスクリプトの通常のユースケースにおいてはほとんど問題になりません。通常のユースケースとはシステム管理などです。システム管理コマンドなどでは ASCII 文字の範囲しか必要としないことが大半です。しかしデータ管理をしようと思ったら話は別です。データの中に Unicode が含まれることは多々あります。
具体的にどのような問題があるのか一例を紹介します。
# macOS (BSD) [Unicode 対応]
echo あいうえお | cut -c 4-6
えお
# Debian (GNU) または BusyBox [Unicode 非対応]
echo あいうえお | cut -c 4-6
い
# 「えお」と出力される [Unicode 対応]
$ echo あいうえお | gawk '{print substr($0,4,6)}' # gawk (Linux)
$ echo あいうえお | awk '{print substr($0,4,6)}' # nawk (macOS)
# 「いう」と出力される [Unicode 非対応]
$ echo あいうえお | original-awk '{print substr($0,4,6)}' # nawk
$ echo あいうえお | busybox awk '{print substr($0,4,6)}' # busybox
$ echo あいうえお | mawk '{print substr($0,4,6)}' # mawk
他にもシェルの ${#VAR} や sed の正規表現、grep -o などいろんなコマンドで Unicode の対応が実装によって異なっています。このような現状なので、シェルスクリプトで Unicode を扱う場合、いろんな環境での問題に対応する必要があります。そこで代わりに SQLite を使用します。SQLite は Unicode (UTF-8, UTF-16) に対応しています。
一方 SQLite であれば LC_ALL の値とは無関係に Unicode として扱われます。
$ LANG=C LC_ALL=C sqlite3 db "CREATE TABLE tbl(id INTEGER, value TEXT);"
$ LANG=C LC_ALL=C sqlite3 db 'INSERT INTO tbl VALUES(1, "あいうえお")'
$ LANG=C LC_ALL=C sqlite3 db 'SELECT substr(value,3,2) FROM tbl'
うえ
日付・時刻の計算や日時による高速な検索が可能
Unix コマンドは POSIX で規定された範囲(どの環境でも動く)では現在時刻の取得しかできません。GNU 版と BSD 版であれば日付の計算はできますが移植性は有りません。なぜこんなに不便でそれがいつまでも解決しないんだろうと思うかもしれませんが「OS のインターフェースとしてはそれだけで十分」「移植性が認められない」からです。OS ベンダーやる気になってお互いのオプションをサポートすれば良いのですが GNU も BSD もやる気はないようです。もっとも他の商用 UNIX でも対応しなければ POSIX は移植性があると認めないと思います。(注意 POSIX で規格化したものを OS ベンダーが実装するのではなく、実装に移植性が認められたら POSIX で採用するというのが POSIX の標準化の流れです)
日付の計算というのは理論的にはライブラリや別のコマンドで出来ることなので OS のインターフェースにするまでもありません。残念なことにシェルスクリプト用の実績がある日付関数ライブラリやコマンドはありませんが、自分でコードを書けばシェルスクリプトでも awk でも日付の計算を行うことはできます。(参考 「シェルスクリプトでUNIX時間⇔日付の相互変換を行う関数(POSIX準拠)」もう少しこれを使いやすくしたい思ってるんですが…)
しかしこのような問題も SQLite に日付計算の関数があるため解決します。日付関数は標準 SQL でも規定されており、多少の文法の違いはあれどどの RDBMS でも使用可能です。(参考 Date And Time Functions)
$ sqlite3 :memory: 'SELECT datetime()'
2022-03-20
# デフォルトは UTC で取得(環境変数の影響を受けない)
$ sqlite3 :memory: 'SELECT datetime()'
2022-03-20 07:52:11
# ローカルタイムを取得する
$ sqlite3 :memory: 'SELECT datetime("now", "localtime")'
2022-03-20 16:54:09
# 2 時間後
$ sqlite3 :memory: 'SELECT datetime("now", "+2 hours")'
2022-03-20 09:56:25
# 書式を変えて出力
$ sqlite3 :memory: 'SELECT strftime("%Y/%m/%d", datetime("2022-03-20"))'
2022/03/20
# Unix タイムで出力
sqlite3 :memory: 'SELECT unixepoch("2022-03-20")'
1647734400
ちなみに上記の :memory: というのは、in memory データベースでファイルを作らずメモリだけでデータ処理を行うモードです。調べてみると実行時間も十分速かったので sqlite3 コマンドがインストールされていれば、どの環境でも同じように動く date コマンドの代替として十分使えそうです。
$ time sqlite3 :memory: 'SELECT strftime("%Y/%m/%d", datetime("2022-03-20"))'
2022/03/20
real 0m0.003s
user 0m0.003s
sys 0m0.000s
$ time date -d 2022-03-20 +"%Y/%m/%d"
2022/03/20
real 0m0.002s
user 0m0.001s
sys 0m0.000s
もちろん日時を条件に検索したりもできますし、インデックスもちゃんと効くので日時を使った高速なデータ検索を行うことが出来ます。
JSON データを扱うことができる(jq の代替)
最近は多くのウェブサービスがデータ形式として JSON データを返します。しかし伝統的な Unix のコマンドは行志向を前提としており、行志向ではない JSON データを簡単に扱うことが出来ません。jq コマンドなどの新しいコマンドを使えば一行に加工することは可能ですが、それでは検索などがしづらいですしデータベース処理ができるように値をバラバラに保存するならばデータの持ち方を工夫しなければいけません。
フィルタコマンドとして使うのであれば jq コマンドを使ったほうが良いですが、データとして保存するのであれば SQLite を使って JSON データをそのまま値として保存することが出来ます。もちろん単に JSON を文字列として格納するだけではありません。特定のキーの値で抽出したり JSON データの加工もできます。(参考 JSON Functions And Operators)
$ sqlite3
sqlite> INSERT INTO users VALUES(1, '{"name":"佐藤", "kana":"sato"}');
sqlite> INSERT INTO users VALUES(2, '{"name":"鈴木", "kana":"suzuki"}');
sqlite> INSERT INTO users VALUES(3, '{"name":"高橋", "kana":"takahashi"}');
sqlite> SELECT json_extract(json, '$.name') FROM users;
佐藤
鈴木
高橋
JSON をあつかう関数は一通り揃ってるので、殆どのことは出来るはずです。また JSON の特定のキーに対してインデックスを作成することも出来ます。
sqlite> EXPLAIN QUERY PLAN SELECT json_extract(json, '$.name') FROM users WHERE json_extract(json, '$.kana') = "suzuki";
0|0|0|SCAN TABLE users
sqlite> CREATE INDEX users_kana_index ON users(json_extract(json, '$.kana'));
0|0|0|SEARCH TABLE users USING INDEX users_kana_index (<expr>=?)
このような SQLite の機能を使えば JSON データで情報を提供しているウェブサービスから受け取ったデータを SQLite にそのまま入れて、いろんな条件での高速な検索やデータ分析を行うことができます。
余談ですが私は個人的に jq コマンドは分かりづらいと思っています。使いこなせれば高度なことをシンプルに記述することができるのですが、そのためには jq 言語という専用の言語を覚えなければならず、一度書いてもすぐに忘れてしまいます。また関数型言語は多くの人にとって馴染みが薄い言語だと思っています。これに関して私は jq とは全く異なる SAX 風のインターフェースを持った手続き型で書くことが出来るコマンドを開発しようと考えています。それを開発するにあたっての実験記事が「シェルスクリプトの実験のために作った POSIX 準拠 awk 実装の JSON パーサー (SAX風ストリーミング対応)」です。JSON データの取扱はデータ管理には SQLite を使えばよいのですがフィルタコマンドとしての役割をするコマンドは別に必要です。
CSV ファイルを扱うことが出来る(awk の代替)
SQLite は CSV ファイルの取り込みにも対応しています。RFC 4180 対応なので値に改行やカンマやクォートを含めることが出来ます。これは素の POSIX awk で扱うことが難しい CSV 形式ですがパーサーを書けば RFC 4180 に対応することは可能です。(参考 シェルスクリプトの実験のために作った POSIX 準拠 awk 実装の CSVパーサー (RFC4180対応))
しかしそのための上記のような awk スクリプトが必要になるわけで、awk スクリプトをインストールするぐらいなら SQLite をインストールした方が簡単かつ SQL のパワーを利用することが出来ます。集計関数(count とか sum など)相当の機能は awk で実装可能ですが関数としては用意されていないので面倒なコードを書く必要があります。
以下は CSV を取り込む例です。テーブル定義が面倒ですがフィールド名にこだわらないのであれば CREATE TABLE ken (f1, f2, f3, 略... , f15); で十分ですし、テーブルを定義がない状態からであれば CSV ファイルの一行目にフィールド名を入れておけばそれが使われます。
# 郵便番号データの CSV: https://www.post.japanpost.jp/zipcode/download.html
$ wget https://www.post.japanpost.jp/zipcode/dl/kogaki/zip/ken_all.zip
$ unzip ken_all.zip
# ファイルが SJIS なので UTF-8 に変換する必要がある
$ iconv -f sjis -t utf8 KEN_ALL.CSV > ken_all_utf8.csv
$ sqlite3 db
sqlite> CREATE TABLE ken (
jis_code TEXT NOT NULL,
postal_code5 TEXT NOT NULL,
postal_code7 TEXT NOT NULL,
pref_kana TEXT NOT NULL,
city_kana TEXT NOT NULL,
address_kana TEXT NOT NULL,
pref TEXT NOT NULL,
city TEXT NOT NULL,
address TEXT NOT NULL,
flag1 TEXT NOT NULL,
flag2 TEXT NOT NULL,
flag3 TEXT NOT NULL,
flag4 TEXT NOT NULL,
flag5 TEXT NOT NULL,
flag6 TEXT NOT NULL
);
sqlite> .import --csv ken_all_utf8.csv ken
sqlite> SELECT * FROM ken WHERE postal_code7 = "1050011";
13103|105 |1050011|トウキョウト|ミナトク|シバコウエン|東京都|港区|芝公園|0|0|1|0|0|0
sqlite> SELECT count(*) from ken WHERE postal_code7 LIKE "105%";
475
もう一つの面白い機能は The CSV Virtual Table です。これは CSV ファイルを SQLite のデータベースファイルに取り込むことなく CSV を使うことが出来る機能です。
# SQLite 本体のソースコード(ヘッダファイルが必要)
$ wget https://www.sqlite.org/2022/sqlite-amalgamation-3380100.zip
$ unzip sqlite-amalgamation-3380100.zip
$ cd sqlite-amalgamation-3380100/
# csv.c モジュール(最新版は https://www.sqlite.org/src/artifact?ci=trunk&filename=ext/misc/csv.c 参照)
$ wget https://www.sqlite.org/src/raw/d14709096280dc0e20c533f184568952bf4b8022ea80afc4aa9fec5ab3637bb3?at=csv.c -O csv.c
$ gcc -fPIC -shared csv.c -o csv.so -I .
スキーマを指定しない場合は自動的にフィールド名が定義されます。
$ sqlite3
sqlite> .load ./csv
sqlite> CREATE VIRTUAL TABLE ken USING csv(filename='ken_all_utf8.csv');
sqlite> SELECT * FROM ken WHERE c2 = "1050011";
13103|105 |1050011|トウキョウト|ミナトク|シバコウエン|東京都|港区|芝公園|0|0|1|0|0|0
sqlite> SELECT count(*) FROM ken WHERE c2 LIKE "105%";
475
ただしこの方法ではインデックスが定義できません。これは CSV ファイルが単純なテキスト形式であるがゆえの制限です。そのため Unix kコマンドと同じように検索は全件検索しかでず遅くなりますが awk の代わりとしての簡単な使い方としては便利かもしれません。SQL の(おそらく)すべての関数を使うことが出来ます。もちろん JSON の場合と同じくフィルタコマンドとして使いたい場合は awk による CSV パーサーの方が適切な場合があります。
補足 CSV ファイルをフィルタコマンドとして操作するのであれば q コマンドが便利かもしれません。検証してないので参考リンクを紹介するに留めますが、おや?よく見たら「SQLite データベースに対応している」と書いていますね。これは関連コマンドとして検証する価値が高いかもしれません。
- q - Run SQL directly on delimited files and multi-file sqlite databases
- CSVデータに対してSQLのwhere、order by、group by、joinができる
qコマンド(導入編) - CSVデータに対してSQLのwhere、order by、group by、joinができる “q” コマンド(活用編)
SQL を使うとシェルスクリプトのコードが減り別言語への移行も容易になる
SQL は通常、他のプログラミング言語に埋め込んで使います。最近は O/R マッパーを使うのでそれほど直接は書かなくなったかもしれませんが、直接呼び出す事もできますし O/R マッパーを使うほどでもないような使い方であれば直接 SQL を呼び出すこともあるでしょう。
なにかをシェルスクリプトで書いた時、それが次第に大きくなってメンテナンスしづらくなり、他の言語に置き換えるというのはよくある話です。シェルスクリプトを他のプログラミング言語に置き換える時に困るのは、Unix のコマンドをどうやって置き換えるかです。Python の subprocess のような Unix のコマンドを実行しやすくするライブラリはありますが、Unix コマンドを呼び出している以上 Unix コマンドの問題点から逃れることはできず、コマンドを呼び出すための余計なコードが追加されるだけで大きな改善はできません。シェルスクリプトを他の言語に置き換える場合は Unix コマンドの利用をなくして言語ネイティブのコードに置き換えることをおすすめします。こういう場合に Unix コマンドを使ったコードが沢山あると置き換えるのは大変になってしまいます。
SQLite を使うとこの問題に対してある程度対策することができます。SQL は他の言語でも使えるわけですから、SQL 自体はほぼそのまま使えます。SQL を使うことでシェルスクリプト特有の Unix コマンドを使ったロジックが少なくなり移行も楽になるでしょう。更に SQLite のデータベースファイルはそのまま使うことが可能なので、複数の言語を組み合わせたり段階的に移行したりすることも可能です。
余談ですが SQLite はブラウザの JavaScript でも使うことができます。以前あった SQLite をブラウザに組み込む Web SQL は断念されましたが、wasm の力を利用した SQL.js を使うとブラウザ上で SQLite を動かすことができます。
RDB なので技術書もノウハウも多く国家試験もある
普遍的な技術で理論が確立されている RDBMS は、その使い方が多くの人によって解説されています。SQLite そのものの技術書も和書でも何冊かありますし、洋書だと少し古いですがオライリーからもでています。また基本は RDB なので RDB や SQL に関する多数の技術書も参考にすることができます。SQL の文法や内部構造に違いがあったりしますが基本的な理論は同じなので応用するのはさほど難しいことではありません。SQL の書き方、高度なテクニック、アンチパターン、リファクタリング、各種揃っています。データ管理の手法に悩んだ時、それについて書かれた技術書やノウハウが多く存在しているということは重要なことです。
情報処理技術者試験 - 高度試験 データベーススペシャリストという国家試験もあります。試験があることからわかるように RDB はすぐにマスターできる簡単な技術とは言えませんが、データ管理やデータ分析のスペシャリストとしては覚える価値が非常に高い技術です。データベーススペシャリストの試験要綱・シラバスよりデータベースを扱うスペシャリストが持つべき技術・知識とはどのようなものであるかがわかると思います。なおデータベーススペシャリストの範囲は RDB だけではなく NoSQL などの知識も含まれ SQL などの実装技術だけではなくデータベース設計・運用・監視・保守・システム構成などより高度で広い技術が対象です。
大規模対応 DBMS へのマイグレーションが容易
Unix コマンドの限界を回避するために必要となる複雑なファイル・ディレクトリ構造の欠点の一つは他のデータベースサーバーへの移行が困難になるという所です。ファイル前提の設計であるため RDBMS にそのまま応用することができません。SQLite は RDBMS そのものなので、システムの規模が大きくなった時に MySQL などの他のデータベースサーバーへの移行が容易になります。基本的なテーブル設計はそのまま使いまわすことが出来ます。SQL に互換性がない場合がありますが殆どは単純な書き換えですみます。
ソフトウェアを長く使うのであれば、そのソフトウェアの将来の成長をある程度考慮する必要があります。プログラムと違いデータの寿命は長いため、それを保存するデータは独自構造のファイルに保存するのではなく寿命が長くより普及しているデータベースを採用すべきです。普及しているデータベースであれば、それを扱うツールやノウハウは世の中に広く存在しているため、SQLite から MySQL や PostgreSQL などの大規模システムに対応できるデータベースへと移行ツールを使って移行することが可能です。独自形式ではそうはいきません。
おまけ 空間データ・GIS データ(地理情報システム)への対応
SQLite そのものではなくサードパーティの拡張ので、また私が詳しくないのでおまけとして扱いますが、SQLite には空間データベースを扱う拡張があります。
ざっと調べたろところ SpatiaLite は SQLite を空間データベースとして扱う空間拡張モジュールのようです。GEOS(幾何計算ライブラリ)や Proj4(投影変換ライブラリ)を組み込んでおり空間データを扱うためのデータ型や、それを扱うための関数やインデックスの仕組みがあるようです。データベースの読み書きには spatiaLite コマンドという専用の CLI ツールを使います。
もう一つ GeoPackage というのもあって、これは SQLite のデータベースに空間データを保存するための仕様を定めたもののようです。ようは SQLite ベースのデータベースファイルだと思います。いろいろなアプリケーションが GeoPackage ファイル形式(拡張子 gkpg)に対応していて SpatiaLite もバージョン 4.2.0 から GeoPackage ファイル形式に対応した。というような関係のようです。
よくわかってないので詳しい解説はできませんが、地理情報を扱うような用途にも対応可能です。
SQLite を使うためのシェルスクリプトの課題
さて、ここまで SQLite をシェルスクリプトで使うメリットを述べてきましたが、課題がないわけではありません。注意点や改善しなければならない点はあります。ただしこれらがないから使えないという意味ではないです。これらがあればもっと使いやすくなるという話です。
シェルスクリプト用 SQLite ライブラリの作成
sqlite3 を呼び出せば SQL を実行することはできるのですが、やはりライブラリがあればより簡単に使うことができるはずです。特に気になるのは SQL インジェクション対策、プレースホルダ機能です。CLI インターフェースでも SQL Parameters がありますが、これは特殊コマンドの .parameter を使う方式で、文字列しか無いシェルスクリプトでは結局 .parameter で渡す値をエスケープする必要があります。.parameter 自体も使いやすいとは言えないので、これを簡単に使えるようなシェルスクリプト用のライブラリがあれば便利だと思います。
これに関して SQLite 側での対応の話は出ています。
- Feature request: implement .parameter bind KEY VALUE in sqlite3 CLI (shell)
- SQLite3 shell doing math operation on parameter substitution
- [PoC] CLI
-paramoption
-param オプションの実装はプレースホルダ機能を改善する手段の一つになりえると思いますが、複数のステートメントの実行などを考えると、シェルスクリプト用のライブラリが必要になると私は考えています。CLI インターフェースは SQLite 側で対応すべきですが、シェルスクリプト用のライブラリの開発となれば私の領分でしょう。やりたいことがまた増えてしまいました。
JSON Lines (jsonl) 対応
比較的新しい sqlite3 コマンドは JSON 出力に対応しているのですが、どうも JSON Lines には対応していないようです。行志向である JSON Lines はストリーミングデータの考えからいうとシェルスクリプトと相性が良いデータ形式です。ただし Unix コマンドで JSON Lines を扱うことはできないので何らかのツールが必要になります。
現在の sqlite3 コマンドは JSON 出力にしか対応していませんが、jq を使えば JSON Lines に変換できるはずです。おそらくストリーミング処理(jq --stream)もできます。しかし一旦 JSON で出力したデータをデータをまたパースして JSON Lines に変換するのは無駄が多いので sqlite3 自体で対応すべきでしょう。
私がなにか見落としているかもしれないので、もう少し詳しく調べてみて、それでも見つからなければ JSON Lines 対応の要望を出そうかと考えています。
インメモリデータベースを使ったフィルタコマンドの作成
ちょっとした私の思いつきですが。SQLite をデータベースではなく(フィルタ)コマンドとして使えないだろうかと考えています。上の方で少し書きましたが SQL の日付関数を使うと date コマンドの代替コマンドを作ることができます。
# GNU と BSD で書き方が違う
$ date +"%Y/%m/%d" -d "2022-03-20" # GNU
$ date -j -f "%Y-%m-%d" "2022-03-20" +"%Y/%m/%d" # BSD
2022/03/20
# date コマンドの非互換性を回避できる
$ sqlite3 :memory: 'SELECT strftime("%Y/%m/%d", datetime("2022-03-20"))'
2022/03/20
また以下のように実行すると 1 と表示された 3 秒後に 2 が出力されます。
{ echo 'select 1;'; sleep 3; echo 'select 2;'; } | sqlite3
このことからパイプを使って SQL を入力することが可能で、ちゃんとストリーミングで処理されているということがわかります。
データベースは本来はデータを蓄えてからデータ処理を行うものであるためフィルタコマンドとして使うのはパフォーマンス的に厳しいのではないかと思ってはいますが、それでもうまく使えば Unix コマンドの制限を回避できるコマンドを作れる可能性があると考えています。少しラップしてあげれば集計処理などは awk よりも可読性が良くなり、簡単に書くことができるようになりそうです。(集計は元よりストリーミング処理が不可能です。ストリーミング処理が可能な場合はこの方法は不適切でしょう)
# フィールドが増えるほど長くなるし計算式を書かねばならない
$ awk '{ f1+=$1; f2+=$2; } END { print f1 f2/NR }' data.csv
$ aggr 'sum(f1), avg(f2)' data.csv
# 内部的にインメモリで csv ファイルを一時テーブル data に保存し
# select sum(f1), avg(f2) from data; を実行する
SQLite の柔軟で寛容な型が、文字列しかないシェルスクリプトと相性がとても良いです。
N+1 問題を回避する書き方をまとめる必要がある
時々シェルスクリプトが遅いと批判されることがありますが、多くの場合、ループの中で過剰に外部コマンドやサブシェルを実行していることが原因です。これを私は「シェルスクリプト版 N+1 問題」と名付けようかと思っていますが、例えばシェルスクリプトで書くとこのようなものです。
od -tx1 -An /dev/random | head -n 10 | while read line; do
echo "$line" | sed 's/ //g'
done
上記の場合、10 行に制限するための head -n 10 を除くと 10 行分の sed コマンド呼び出しと、そのデータを取得する od コマンド呼び出しで 11 回の外部コマンド呼び出しが行われてしまいます。外部コマンドの呼び出しはかなり遅い処理であるため、ループを 1000 回程度にするだけでその遅さがはっきりわかります。
time { od -tx1 -An /dev/random | head -n 1000 | while read line; do echo "$line" | sed 's/ //g'; done } >/dev/null
real 0m3.833s
user 0m1.884s
sys 0m2.892s
これを外部コマンドの呼び出し回数を減らす書き方に改めるとパフォーマンスは大きく上がります。方法は二通りあって、一つはシェルスクリプトの言語機能で実装する方法、もう一つはパイプで直接つなげて一回のコマンド呼び出しで処理する方法です。この二つの方法は場合に応じて使い分けます。
time { od -tx1 -An /dev/random | head -n 1000 | while read line; do echo "${line// /}"; done } >/dev/null
real 0m0.099s
user 0m0.068s
sys 0m0.043s
time { od -tx1 -An /dev/random | head -n 1000 | sed 's/ //g'; } >/dev/null
real 0m0.026s
user 0m0.027s
sys 0m0.010s
N+1 問題とは Rails などのフレームワークをうまく使えていないときに内部でループの回数 N+1 回の SQL の実行が行われることですが sqlite3 コマンドを使った場合、まさに SQL の実行が N+1 回実行されてしまいます。SQLite は SQL の実行自体は速いようですが、sqlite3 コマンドの実行は遅いためパフォーマンスに影響してきます。この sqlite3 コマンドの起動回数を増やさないようにするためのノウハウが必要になります。
「常駐 SQLite3」とそのライブラリ化
「シェルスクリプト+データベース活用テクニック―Bourne ShellとSQLiteによるDBシステム構築のすすめ」には「常駐 SQLite3」という sqlite3 プロセスを起動したまま通信するという興味深いシェルスクリプトのテクニックが紹介されています。これを応用すると前項の N+1 問題を解決したり、それ以外でも sqlite3 コマンドを複数回呼び出すような処理を一つだけにできる可能性があります。
まだ十分理解していませんが、これをライブラリ化して使いやすくすれば sqlite3 コマンドを呼び出す処理のパフォーマンスを向上できる可能性があります。もしかしたら sqlite3 コマンド以外にも応用できるのではないかと思っていますが、まだちゃんと理解してないので詳細な解説は省きます。
SQLite と Unix コマンドの使い分け
Unix コマンドにはフィルタコマンドとしての役目がある
この記事では Unix コマンドの代わりに SQlite を使いましょうと書いてきましたが、すべてを SQLite に置き換えられるわけではありません。フィルタコマンドとしての用途はおそらく SQLite に置き換えることはできません。大雑把に言ってしまえば SQLite はファイルの読み書きを置き換える処理です。ファイルへの読み書きをせずに処理だけしたい場合には Unix コマンドを使うことになります。
大きなデータ、速度、信頼性の実現でファイル構造が複雑になるなら SQLite を使う
ファイルの読み書きであっても Unix コマンドの出力をほぼ無加工でファイルに保存できる場合は SQLite を使わなくて良いと思います。その程度なら複雑になりません。しかし「データの中に改行やスペースが含まれる」「ファイル一つでは完全なデータとして表現できない」のようにデータを保存する場合にシェルスクリプトや Unix コマンドの制約を回避するために特殊な加工を行うのであれば SQLite の出番です。またそうでなくとも「大量のデータが有る」「ランダムアクセスや検索速度が重要である」「複数プロセスからの同時アクセスが必要である」「ミッションクリティカルな重要なデータを扱う」といった、大規模データベースにおいてパフォーマンスや信頼性が重要な場合には SQLite を使うべきでしょう。
シーケンシャルアクセス(バッチ処理等)しか必要ないなら Unix コマンドを使う
シェルスクリプトも Unix コマンドもファイルを頭から連続的に読み込みことしかできません。この制約の中、DBMS と処理速度で太刀打ちできるものの一つはバッチ処理です。バッチ処理は一般的に同じデータにアクセスするプロセスがないので排他制御が不要で複雑な処理が必要ありません。トランザクションは単に元ファイルを上書きせずに新しいファイルに出力するだけです。また全てのデータにシーケンシャルにアクセスするのであればランダムアクセスできないといった制限が問題になることもありません。それに加えてファイル構造がシンプルであれば Unix コマンドを使って処理するのもよいでしょう。
さいごに
ソフトウェアには適材適所があります。どんな場合にも使えるものなんてありません。だから多くのツールが誕生し、多くの言語があるわけです。データ管理を行うのにそもそもシェルスクリプトが適切なのか?という話ももちろんあります。
Unix コマンドは古くから使われており、多くの環境で追加のインストールなしに動くかもしれませんが、それだけです。動くと言うだけで使いやすいとか性能が高いというわけではありません。Unix コマンドが OS に含まれてるのは互換性維持のためにすぎず、POSIX コマンドは、どの OS でも動くだろうというものを標準化し、移植性が高いアプリケーションを作るための指針を提供しているに過ぎません。
30 年のソフトウェアの発展の歴史で達成された多くの技術者の成果を無視して、古い Unix (POSIX) コマンドに囚われ続けているのはナンセンスです。互換性維持のために残されてる Unix は大きな進化ができず、この記事で証明したように数々の問題点があります。それは SQLite などで解決しているのですからその成果を利用しましょう。
ソフトウェアの開発はコストを考えなければいけません。最初の開発コストだけではなくその後のメンテナンスのコストも考える必要があります。メンテナンスというのは業務ルールの変更に応じて仕様を変更することであり、ビジネスが続く限りこの作業は続きます。シェルスクリプトや Unix コマンドを使ったところでメンテナンスが不要になるということはありませんが、自分が作る部分を減らすことでメンテナンスコストを下げることはできます。
ただし過度に他の人が作ったコマンドに依存するのもよくありません。そのコマンドがどれだけ使われているかメンテナンスが続けられるかを見極める必要があります。ただで使えるからと言って将来性がないコマンドを使うと自分でメンテナンスしなければならなくなります。それでは本末転倒です。だからより信頼できるソフトウェアを利用し、それを見極めるのも技術の一つです。
SQLite は依存するリスクが限りなく小さいソフトウェアの一つです。性能が高く互換性が高く長寿命で膨大な数の利用実績があります。それについては「利用者は数十億人!? SQLiteはどこが凄いデータベース管理システムなのか調べてみた」で詳しく解説しています。
SQLite は Unix コマンドの時代には解決できていなかった問題を解決した新しいソフトウェアです。自分で開発する部分を減らすことが、ソフトウェアを変更に強くし、ソフトウェアの寿命を長くすることにつながります。シェルスクリプトにおけるデータ管理の問題を解決したコマンドがすでにあるのですから、自分の仕事を楽にしてくれるその成果に敬意を払い、活用し、あとに続くものへ更に便利なソフトウェアを提供するのが我々プログラマーの使命です。
補足 delika 記事投稿キャンペーン
この記事を書き始めたのは二ヶ月ぐらい前で狙ったわけではないのですが、たまたま「delika 記事投稿キャンペーン」が開催されているのに気づいて、テーマ2『データに関する記事を書こう!』に内容がかすってる?かすってない?と思ったので応募してみました。
このテーマに合わせたタイトルにするなら「シェルスクリプトによる複数言語を組み合わせたデータ管理技術」と言ったところでしょうか。シェルスクリプトメインの内容なので大幅微妙にキャンペーンの趣旨とずれている感はありますが、SQLite を導入することでシェルスクリプトと複数の言語を組み合わせてのデータ活用を行う手法の解説とも言えるはずです。たぶん。
でもこの記事は よく読むと無駄に長いだけ で要約すると シェルスクリプトで SQLite を使いましょうと言ってるだけ でデータ分析も何もしてないんだよなー。他の人はみんな難しそうなことしてるし。んー、まあいいか。あ、delika はビジネスデータやオープンデータ活用する「データ共有プラットフォーム」らしいです。delika も 利用者が提供するデータを SQL を使ってサービス上で組み合わせたりするようなので、シェルスクリプトでのデータ管理に SQLite を使っていれば delika との間で技術的知識が応用できたり連携しやすくなるかもしれません。このように応用の幅が広いのが SQL なので、シェルスクリプトでも高度なデータ管理をするなら SQLite を使いましょう!