はじめに
将来的に ShellSpec で jq コマンドなしに JSON データのテストを行えるようにしたかったのでその準備として手軽に出力フォーマットを変更できる SAX 風スリーミング対応の JSON パーサーを書きました。一応 POSIX 準拠 の awk で動いて(GNU 拡張は使っていません)のつもり。
**ただし私はおそらくこれを使いません。**というのも、これを書いている間に「別のアイデア」を思いつきそちらを使おうと思っているからです。設計が全く違っておりコードも完全に別物です(そのコードも公開します)。こちらの実装の方がシンプルで速いというメリットがありますが、別のアイデアの方は awk との親和性がより高くなっています。
この記事のコードは最低限の動作確認しかしておらずバグが含まれている可能性が高いので注意してください。要するにサンプルコードと考えてください。コードのライセンスは CC0 としますので、コピペして使うなり、加工して自分のコードとして使うなり、ご自由にどうぞ。
SAX ってなに?
詳しくは「SAXによるXML文書の操作」とかを参照してください。Simple API for XML の略で元々はその名の通り、XML データを扱うための API です。XML をパースしながら要素(タグ)の開始や終了時、要素の中身を見つけた時に発生するイベントから見つかったデータを参照することが出来ます。DOM とは異なり全てを読み込んで DOM ツリーを構築するのではなく、ストリーミングでデータを受け取りながら処理が可能になるため、省メモリでシェルスクリプトのパイプラインを使ったストリーミング処理に適合します。SAX 自体は XML の API ですが、このようなアイデアを使った処理を SAX ベースと言われることがよく有るような無いような気がします。
使い方
例えば以下のような注文データの JSON データから
{
"customer": {
"name": "Koichi Nakashima",
"tel": "000-0000-0000",
"email": "koichi@eample.com"
},
"details": [
{ "name": "商品1", "price": 100, "count": 5 },
{ "name": "商品2", "price": 1000, "count": 2 },
{ "name": "商品3", "price": 10000, "count": 1 }
]
}
以下のような出力が得られます。この出力形式はサンプルのコールバック関数によるもので、自由に変更することができます。実際にはこのようなリストに変換すると言うよりもコールバック関数で必要な所のみをシェルスクリプトで読み込みやすい形式で出力するというような使い方を想定しています。
@ <=> {
@."customer" <=> {
@."customer"."name": "Koichi Nakashima"
@."customer"."tel": "000-0000-0000"
@."customer"."email": "koichi@example.com"
@."customer" <=> }
@."details" <=> [
@."details".0 <=> {
@."details".0."name": "商品1"
@."details".0."price": "100"
@."details".0."count": 5
@."details".0 <=> }
@."details".1 <=> {
@."details".1."name": "商品2"
@."details".1."price": "1000"
@."details".1."count": 2
@."details".1 <=> }
@."details".2 <=> {
@."details".2."name": "商品3"
@."details".2."price": "10000"
@."details".2."count": 1
@."details".2 <=> }
@."details" <=> ]
@ <=> }
例えば次のような出力を得たい場合は
name,price,count,subtotal
"商品1",100,5,500
"商品2",1000,2,2000
"商品3",10000,1,10000
total count:8 total price:12500
このような、コールバック関数を書きます。これは awk のコードです。
function node(keys, v) {
if(match(keys, /^@.\"details"\.[0-9]+\."name"$/)) {
name = v
}
if(match(keys, /^@.\"details"\.[0-9]+\."price"$/)) {
price = v
}
if(match(keys, /^@.\"details"\.[0-9]+\."count"$/)) {
count = v
}
}
function walk(keys, v) {
if(match(keys, /^@$/) && v == "{") {
total_count = 0; total_price = 0
print "name,price,count,subtotal"
}
if(match(keys, /^@.\"details"\.[0-9]+$/) && v == "{") {
name = ""; price = 0; count = 0;
}
if(match(keys, /^@.\"details"\.[0-9]+$/) && v == "}") {
subtotal = price * count
total_count += count; total_price += subtotal
print name "," price "," count "," subtotal
}
if(match(keys, /^@$/) && v == "}") {
print "total count:" total_count " total price:" total_price
}
}
シェルスクリプトは JSON データを扱おうとした場合、分かりづらいコードが必要になったり遅かったりしますが、これを使うことで awk コードで簡単に処理できます。またその結果をシェルスクリプトに返することも比較的簡単に行うことが出来ます。(使いこなせば jq の方が短く書けると思うのですが、高度な使い方をすると独自の言語といっていい状態になるので難しいんですよ・・・)
コード
以下の 4 つのファイルから構成されています。メンテナンスしやすいように分けていますが実際に使うときは一つに結合した方が良いかもしれません。(参考 awkをプログラミング言語として使う時の技術)
- サンプルコード
-
parsejson.sh実際に実行するコマンド -
jsoncallbacks.awkJSON パース中に呼び出されるコールバック関数
-
- JSON パーサー
-
jsontokenizer.awkJSON をトークンに分割するスクリプト -
jsonparser.awkJSON トークンを解釈しコールバック関数を呼び出すスクリプト
-
# !/bin/sh
set -eu
# 意外とパフォーマンスに影響する(この方が速い)
export LC_ALL=C
# 使用する awk コマンドのパスを変えたり、ベンチマーク用に time を割り込ませる時に使う
# awk() {
#/usr/bin/time gawk "$@"
#/usr/bin/time /usr/bin/awk "$@"
#/usr/bin/time mawk "$@"
#/usr/bin/awk "$@"
# }
tokenize() {
awk -f jsontokenizer.awk "$@"
}
parse() {
awk -v ROOT="@" -v SEP="." -f jsoncallbacks.awk -f jsonparser.awk
}
tokenize "$@" | parse
function node(keys, v) {
print keys ": " v
}
function walk(keys, v) {
print keys " <=> " v
}
BEGIN { RS="\""; flag = 0 }
{
if (match($0, /(^|[^\\])(\\\\)*\\$/)) {
printf "%s\042", $0
next
}
if (flag) {
print "\042" $0 "\042"
} else {
gsub(/[ \r\n\t\v]/, "")
gsub(/[][{}:,]|[^][{}:,]+/, "&" ORS)
printf "%s", $0
}
flag = !flag
}
function next_token() {
if (getline != 0) return $0
exit 1
}
function expected_token(token) {
if ($0 == token) return
exit 1
}
function object(keys) {
if (next_token() == "}") return
while (1) {
key = $0
next_token()
expected_token(":")
next_token()
value(keys SEP key)
if (next_token() == "}") return
expected_token(",")
next_token()
}
}
function array(keys, idx) {
if (next_token() == "]") return
while (1) {
value(keys SEP idx)
if (next_token() == "]") return
expected_token(",")
next_token()
idx++
}
}
function value(keys) {
if ($0 == "{") {
walk(keys, "{")
object(keys)
walk(keys, "}")
} else if ($0 == "[") {
walk(keys, "[")
array(keys, 0)
walk(keys, "]")
} else if ($0 == "}" || $0 == "]") {
exit 1
} else {
node(keys, $0)
}
}
BEGIN {
if (SEP == "") SEP = "\t"
next_token()
value(ROOT)
}
コードの解説
サンプルコードの 2 つ (parsejson.sh, jsoncallbacks.awk) は特に説明する必要もないので省略します。処理は大きく分けて jsontokenizer.awk と jsonparser.awk の二つに分かれています。
jsontokenizer.awk
JSON データを受け取り、トークン毎に分けて出力する awk スクリプトです。
awk -f jsontokenizer.awk order.json
{
"customer"
:
{
"name"
:
"Koichi Nakashima"
,
︙
JSON データは長い一行のデータになっている場合もあり awk のデフォルトの改行毎に読み込む方法ではストリーミングでデータを処理できないので " 区切り (RS="\"") のデータとみなして処理しています。ホワイトスペースはこの段階で処理され 1 行が 1 トークンとなります。(正しい JSON であれば値に改行が含まれることはありません。)
jsonparser.awk
上記の JSON トークンを入力データとして、JSON データとして解釈するスクリプトです。JSON の構造は公式サイト で分かりやすく定義されており、それをそのまま awk のコードに落とし込んだだけです。ただし値の種類(文字や数値やnull)は区別せずに処理しています。(下記の画像は公式サイト JSON.org より)
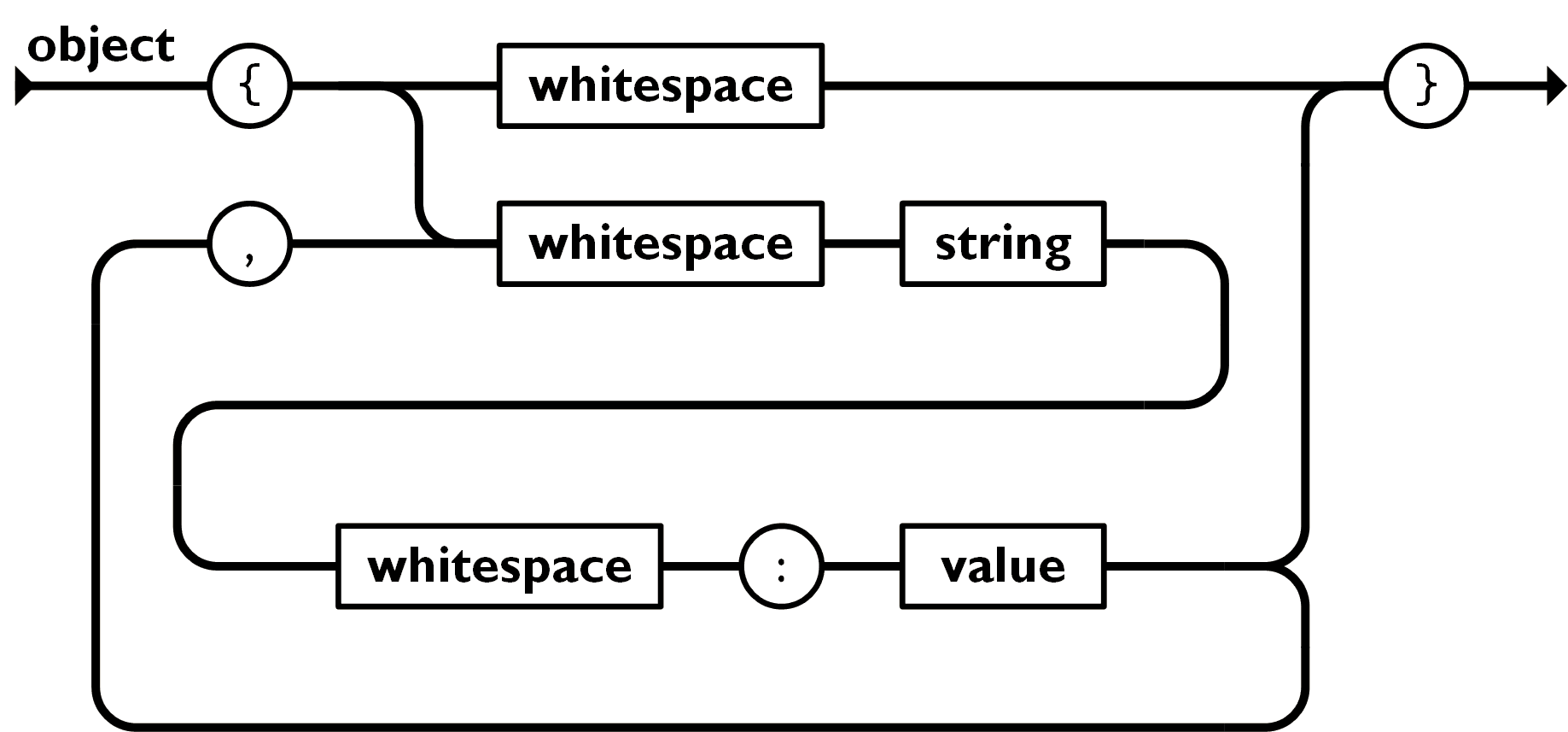
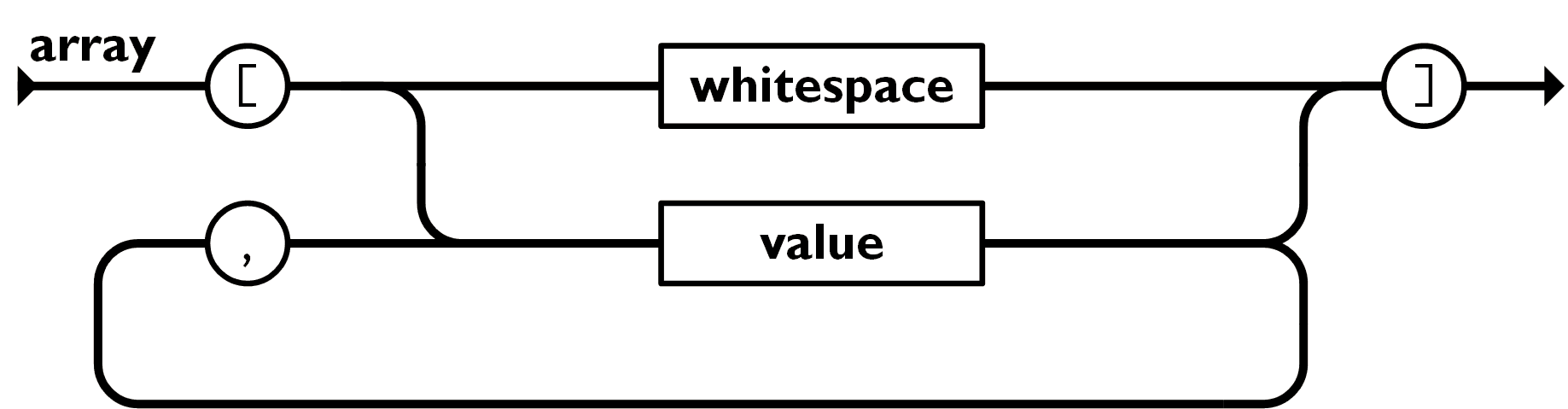
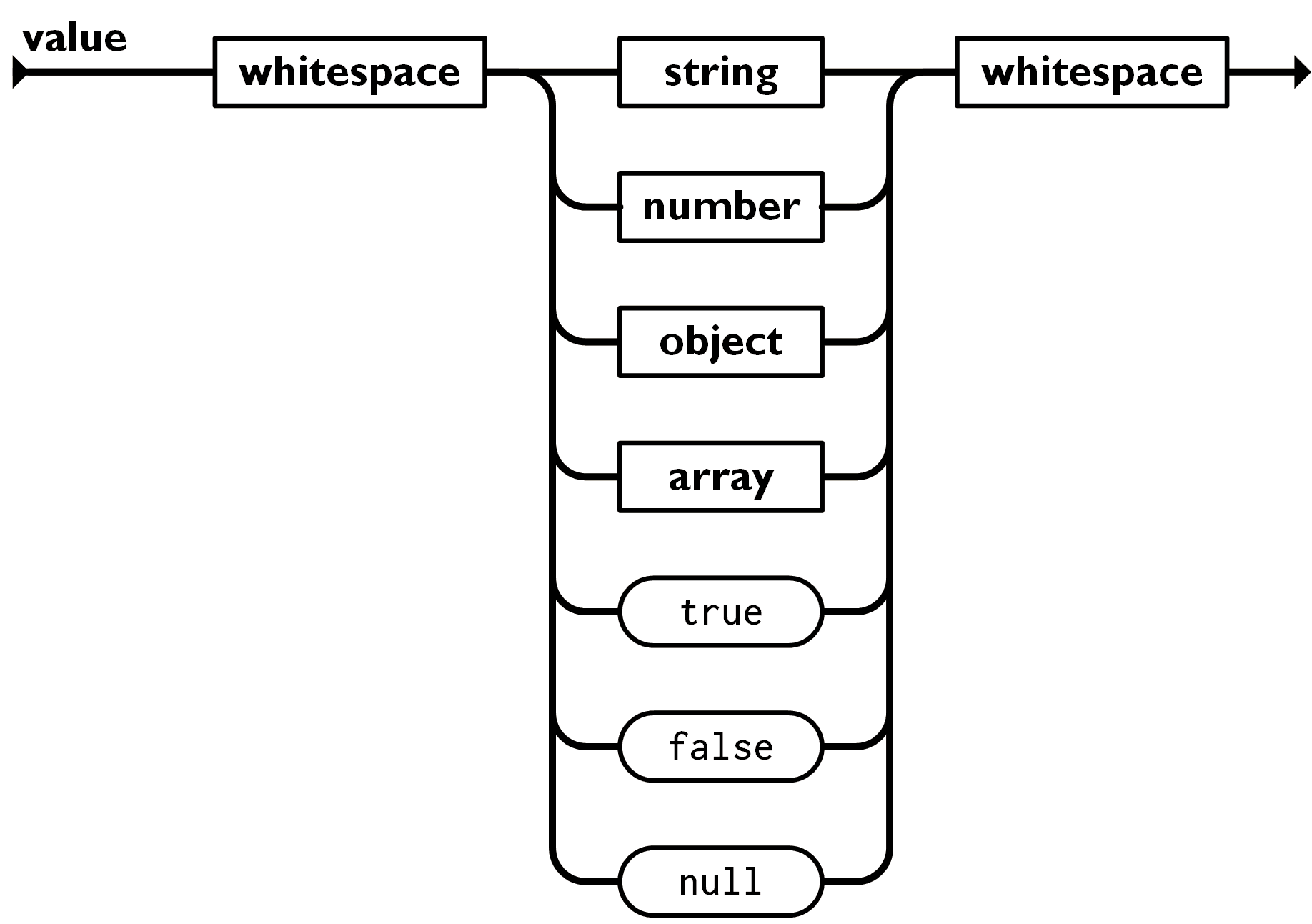
なぜこれを作ったのか?
シェルスクリプトから JSON データを扱う場合 jq コマンドがよく使われます。もちろん jq を使ってもよいのですが ShellSpec でのテストという用途にはうまく適合しません。jq は基本的に JSON の変換器です。JSON データを受け取り別の JSON データまたは CSV などのその他の形式に変換するフィルタです。しかしテストでは、別の形式に変換することほとんどなく、特定のキーの値のチェックを行います。大抵の場合、複数の値をテストすることになるでしょう。jq をうまく使いこなせば、このような値を複数取得できると思いますが、やりたい内容に比べてそれを実現する jq のコードは分かりづらいものになってしまうことが多いと考えています。(テストコードを読んでも正しくテストされているかわからないのであれば本末転倒)
またテストを行う場合、特定のキーをシェルの変数に入れる必要があります(入れないでテストする方法もあると思いますが)。そのための機能が jq には欠けています。もちろん VAR=$(jq .customer.name data.json) のような形で変数に入れることは出来ますが、何度も jq コマンドの呼び出しと JSON データのパースが必要となるため遅くなってしまいます。私は一度の JSON データのパースで複数のシェル変数への代入を行いたいのです。
作ってるのはまだ JSON パーサーだけなので、以下のコードはまだ動きませんが複数のシェル変数への代入をする場合は、このような書き方ができるようにする予定です。(イメージです。実際はもう少し改良します)
BEGIN { idx = 0 }
function walk(keys, v) {
if(match(keys, /^@$/) && v == "{") {
idx++
}
}
function node(keys, v) {
if(match(keys, /^@.\"details"\.[0-9]+\."name"$/)) {
setvar("name" idx, v)
}
if(match(keys, /^@.\"details"\.[0-9]+\."price"$/)) {
setvar("price" idx, v)
}
if(match(keys, /^@.\"details"\.[0-9]+\."count"$/)) {
setvar("count" idx, v)
}
}
この setvar 関数は次のようなシェルスクリプトコードを出力します。
setvar("varname", "value")
↓
varname="value"
(もちろん文字列は適切にエスケープします)
この方法により read で一行毎に読み込み eval することで awk の出力をシェルスクリプトでストリーミングで処理することが可能になります。
他の理由としては jq コマンドなしに POSIX コマンドだけで動くようにしたかったとか、jq のストリーミング出力(--stream オプション)の挙動が謎すぎて扱うのが難しいなどという理由もありました。
また jq に変わるツールとして gron という、以下のように入力した JSON データを JSON データを構築するための 1 行毎の JavaScript コードに変換するツールがあります。
▶ gron testdata/two.json
json = {};
json.contact = {};
json.contact.email = "mail@tomnomnom.com";
json.contact.twitter = "@TomNomNom";
json.github = "https://github.com/tomnomnom/";
json.likes = [];
json.likes[0] = "code";
json.likes[1] = "cheese";
json.likes[2] = "meat";
json.name = "Tom";
「Make JSON greppable!」と書いてあるとおり、シェルスクリプトから grep しやすいというのが売りのようですが、私は grep を使おうと思わないんですよね・・・。ターミナルから実行して出力を眺めるぐらいなら良いと思うのですが、シェルスクリプトで特定の値を参照したコードを書くのは結構難しいと思います。例えば上記の json.contact.email と json.contact.twitter の 2 つの値を参照したいと思った時、grep で絞り込むことは出来ても、その出力からどうやって個別に値を取り出せば良いのか?改行が含まれている場合はどうするのか?で悩みます(遅い方法ならいくらでも思いつきますが)。ちなみに gron のようなツールは、この JSON パーサーを使えば簡単に実装することが出来ます。
他にも JSON の公式サイトでは awk で JSON を処理するための JSON.awk や rhawk やシェルスクリプトで実装された JSON.shや jwalk などが紹介されています。すべてをちゃんと調べたわけではありませんがいくつかはストリーミング処理も対応しているようです。特に JSON.awk はコールバック関数を備えており私が作ろうとしているものに近いように見えますが、私はもう少しシェルスクリプトとの相互運用性を高めたものにする予定でいます。そしてこの記事で紹介した JSON パーサーはそれのコアとして使おうと考えて書いたコードです。(冒頭で書いたようにこのコードは使わない予定です)
さいごに
この記事は「シェルスクリプトの実験のために作った POSIX 準拠 awk 実装の CSVパーサー (RFC4180対応)」の関連記事です。CSV パーサーと同じ要領で作れるだろ?と思って書いたら、全然別物になってしまいました。
「別のアイデア」の記事など、この記事に関するいくつかの関連記事を書く予定でいます。