TL;DR
- オートエンコーダの一種である条件付き変分オートエンコーダ(Conditional Variational Autoencoder; CVAE)を、TensorFlowサンプルの改造で実装しました
- 実装したCVAEにMNISTデータを学習させて遊びました
- サンプルコードは以下のリポジトリで公開しています
github.com/kn1cht/tensorflow_v2_cvae_sample
| sample-cvae-mnist.ipynb | Google Colab | GitHub |
| sample-cvae-mnist-manifold.ipynb | Google Colab | GitHub |
 生成した2D Manifold
生成した2D Manifold
はじめに
**条件付き変分オートエンコーダ(CVAE)**は、ラベルに対応したデータを生成できる(半)教師ありの生成モデルです。
「AutoEncoder, VAE, CVAEの比較 〜なぜVAEは連続的な画像を生成できるのか?」に紹介されている通り、変分オートエンコーダ(VAE)にラベルを入力する処理を追加するだけで実現できます。
ChainerやPyTorch、TensorFlow 1系での実装例はネットで見つかりますが、TensorFlow 2系で書いた例はないようです。そこで、TensorFlow自体の勉強も兼ねて書いてみたものを記事化します。
実装にあたってTensorFlow公式によるVAEのサンプルをなるべく変えずに改造したため、変更部分を追うことで中身の理解の一助になれば幸いです。
環境
モデルの解説
すでに分かりやすい解説が存在するのでここではサラッと述べます。
オートエンコーダ(AutoEncoder; AE)
もともとは次元削減を行う教師なし学習として提案されました。AEはEncoderとDecoderという2つのモデルからなり、Encoderが入力$\boldsymbol{x}$を$\boldsymbol{z}$に圧縮し、Decoderが$\boldsymbol{z}$から$\boldsymbol{x}$を再現しようとします。
中間で登場する$\boldsymbol{z}$は潜在変数と呼ばれ、データの特徴を少ない次元で表現したものと言えます。
AEは、入力をそのまま復元する以外にも、ノイズ除去や異常検知に応用できます。
変分オートエンコーダ(Variational Autoencoder; VAE)
確率分布を取り入れることで、データ生成にも使えるようにしたのがVAEです。Encoderで多変量ガウス分布のパラメータ$\mu$と$\sigma$を推定し、求まった確率分布から$\boldsymbol{z}$を作ります。$\boldsymbol{z}$が連続的な確率分布から得られるようになるので、データセットに存在しないデータをも生成できるようになるというわけです。
実際の学習では、誤差逆伝播ができるようReparametrization Trickという近似手法で$\boldsymbol{z}$を求めています。また、求めた分布と標準正規分布のKLダイバージェンス(カルバック・ライブラー・ダイバージェンス)を目的関数に含めることで、正則化を行います。
VAEで最大化する目的関数です。右辺第1項がDecoderで得られる出力の対数尤度の期待値、第2項が正則化項です。
\mathcal{L}(\boldsymbol{x},\boldsymbol{z}) = \mathbb{E}_{q(\boldsymbol{z}|\boldsymbol{x})}[\log p(\boldsymbol{x}|\boldsymbol{z})] - D_{KL}[q(\boldsymbol{z}|\boldsymbol{x})||p(\boldsymbol{z})]
条件付き変分オートエンコーダ(Conditional Variational Autoencoder; CVAE)
Encoder、Decoderそれぞれにラベル$y$を入力として追加することで、ラベルを指定してのデータ生成を可能としたのがCVAEです。ラベルの情報を与えるので教師あり学習になりますが、工夫すれば全てにラベルを必要としない半教師あり学習としても使えるようです。
目的関数は以下のようにVAEから変わります。といっても、Encoder/Decoderが$y$を考慮するようになるだけであり、実装上はVAEの目的関数のままでOKです。
\mathcal{L}(\boldsymbol{x},\boldsymbol{z},y) = \mathbb{E}_{q(\boldsymbol{z}|\boldsymbol{x},y)}[\log p(\boldsymbol{x}|\boldsymbol{z},y)] - D_{KL}[q(\boldsymbol{z}|\boldsymbol{x},y)||p(\boldsymbol{z}|y)]
CVAEの実装
それではCVAEを実装します。元論文によるとVAE(M1モデル)とCVAE(M2モデル)を組み合わせることで半教師あり学習も可能ですが、本記事ではそこまではせず全データにラベルを対応させて学習します。
コード全体を以下のリポジトリに公開しています。
TensorFlow公式VAEサンプル
VAEについては、TensorFlowの公式チュートリアルにサンプルが収録されています。
Google Colaboratoryで公開されているので、ポチッと実行すればいい感じに動きます。
注意したいのは、ここではConvolutional Variational AutoencoderをCVAEと呼んでいて、本記事で説明してきたCVAEとは別物ということです。こちらのサンプルのモデルは、畳み込み層が入っているというだけで、普通のVAEです。
このMNISTを学習してくれるVAEを改造し、Conditional VAEを実現します。
VAEからCVAEへ
上記のサンプルコードからモデルを定義している部分を抜き出したものをvae.py、そこから作成したCVAEのコードをcvae.pyとしてリポジトリに置いています。
差分を見たほうが分かりやすいので、以降は両者のdiffを掲載しながら説明していきます。
CVAE.init()
--- vae.py
+++ cvae.py
- def __init__(self, latent_dim):
+ def __init__(self, latent_dim, label_size):
super(CVAE, self).__init__()
- self.latent_dim = latent_dim
+ (self.latent_dim, self.label_size) = (latent_dim, label_size)
self.encoder = tf.keras.Sequential(
[
- tf.keras.layers.InputLayer(input_shape=(28, 28, 1)),
+ tf.keras.layers.InputLayer(input_shape=(28, 28, label_size + 1)),
tf.keras.layers.Conv2D(
filters=32, kernel_size=3, strides=(2, 2), activation='relu'),
tf.keras.layers.Conv2D(
@@ -30,7 +31,7 @@ class CVAE(tf.keras.Model):
self.decoder = tf.keras.Sequential(
[
- tf.keras.layers.InputLayer(input_shape=(latent_dim,)),
+ tf.keras.layers.InputLayer(input_shape=(latent_dim + label_size,)),
tf.keras.layers.Dense(units=7*7*32, activation=tf.nn.relu),
tf.keras.layers.Reshape(target_shape=(7, 7, 32)),
tf.keras.layers.Conv2DTranspose(
まずはモデルの定義部分です。ラベル$y$の種類(MNISTなら10種類ですね)をlabel_sizeとして、Encoder/Decoderそれぞれ入力のサイズをlabel_size分だけ増やしています。
これで、One-hot表現に変換したラベルを入力と結合できるようになります。
CVAE.sample()
@tf.function
- def sample(self, eps=None):
+ def sample(self, eps=None, y=None):
if eps is None:
eps = tf.random.normal(shape=(100, self.latent_dim))
- return self.decode(eps, apply_sigmoid=True)
+ return self.decode(eps, y, apply_sigmoid=True)
sample()は、潜在変数とラベルを受け取ってデータを生成する処理です。
CVAE.encode()
- def encode(self, x):
- mean, logvar = tf.split(self.encoder(x), num_or_size_splits=2, axis=1)
+ def encode(self, x, y):
+ n_sample = x.shape[0]
+ image_size = x.shape[1:3]
+
+ y_onehot = tf.reshape(tf.one_hot(y, self.label_size), [n_sample, 1, 1, self.label_size]) # 1 x 1 x label_size
+ k = tf.ones([n_sample, *image_size, 1]) # {image_size} x 1
+ h = tf.concat([x, k * y_onehot], 3) # {image_size} x (1 + label_size)
+
+ mean, logvar = tf.split(self.encoder(h), num_or_size_splits=2, axis=1)
return mean, logvar
Encoderに入力を読み込ませる処理です。まず、ラベルyをOne-hot表現y_onehotに変換します。
それとは別に、形状が「画像サイズ(MNISTなら28×28)×1」で要素が全て1のテンソルkを作っておきます。
k * y_onehotを計算すると、broadcast機能によって「28×28×label_size」となりxと結合できる形になります。
(この部分はysasaki6023氏の実装を参考にさせていただきました。もっと雑にxとyを繋げてしまっても動きはするようです)
CVAE.decode()
- def decode(self, z, apply_sigmoid=False):
- logits = self.decoder(z)
+ def decode(self, z, y=None, apply_sigmoid=False):
+ n_sample = z.shape[0]
+ if not y is None:
+ y_onehot = tf.reshape(tf.one_hot(y, self.label_size), [n_sample, self.label_size]) # label_size
+ h = tf.concat([z, y_onehot], 1) # latent_dim + label_size
+ else:
+ h = tf.concat([z, tf.zeros([n_sample, self.label_size])], 1) # latent_dim + label_size
+ logits = self.decoder(h)
if apply_sigmoid:
probs = tf.sigmoid(logits)
return probs
Decoderにも、同様にzとy_onehotを繋げて渡します。yがNoneかどうかで場合分けしているのは、ラベルを渡さなくてもデータ生成を試せるようにするためです。
しかし、ラベルなしでの学習をしなかったので、結局よく分からない画像しか出てきませんでした……。
compute_loss()
-def compute_loss(model, x):
- mean, logvar = model.encode(x)
+def compute_loss(model, xy):
+ (x, y) = xy # x: image, y: label
+ mean, logvar = model.encode(x, y)
z = model.reparameterize(mean, logvar)
- x_logit = model.decode(z)
+ x_logit = model.decode(z, y)
cross_ent = tf.nn.sigmoid_cross_entropy_with_logits(logits=x_logit, labels=x)
logpx_z = -tf.reduce_sum(cross_ent, axis=[1, 2, 3])
logpz = log_normal_pdf(z, 0., 0.)
学習時の目的関数の処理です。上述の通り目的関数の実装はVAEから特に変わらないため、引数にyが増えるだけです。
train_step()
@tf.function
-def train_step(model, x, optimizer):
+def train_step(model, xy, optimizer):
"""Executes one training step and returns the loss.
This function computes the loss and gradients, and uses the latter to
update the model's parameters.
"""
with tf.GradientTape() as tape:
- loss = compute_loss(model, x)
+ loss = compute_loss(model, xy)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
学習を1ステップ回す処理です。
入力データセットの準備
TensorFlowのデータセット機能(tf.data.Dataset)で、MNISTの画像とラベルがペアになった入力を作ります。
筆者はTensorFlow初心者なので、公式サンプルを見て「この通りにtrain_datasetをシャッフルしてしまったら画像とラベルの対応が崩れるよな……?」とか悩んでググっていました。そんなニーズを満たす機能は当然用意されていて、こちらのチュートリアルで懇切丁寧に解説されています。
train_dataset_x = tf.data.Dataset.from_tensor_slices(x_train)
test_dataset_x = tf.data.Dataset.from_tensor_slices(x_test)
print(train_dataset_x, test_dataset_x)
train_dataset_y= tf.data.Dataset.from_tensor_slices(y_train)
test_dataset_y = tf.data.Dataset.from_tensor_slices(y_test)
print(train_dataset_y, test_dataset_y)
まずは、画像とラベルをシャッフルせずにデータセットへ変換します。
train_dataset_xy = tf.data.Dataset.zip((train_dataset_x, train_dataset_y))
train_dataset_xy = train_dataset_xy.shuffle(train_size).batch(batch_size)
test_dataset_xy = tf.data.Dataset.zip((test_dataset_x, test_dataset_y))
test_dataset_xy = test_dataset_xy.shuffle(train_size).batch(batch_size)
print(train_dataset_xy, test_dataset_xy)
それぞれのデータセットができたら、tf.data.Dataset.zip()でまとめると**(画像, ラベル)のペア**になります。ここからシャッフルやミニバッチ化を行っても、両者の対応は崩れません。イテレーションすると、(画像のテンソル,ラベルのテンソル)のタプルが出てくるので、一緒に使うこともそれぞれ使うことも可能です。
CVAEで遊ぶ
CVAEができたので、MNISTデータを学習させて遊んでみました。
この節のコードは、リポジトリ及びGoogle Colaboratoryで公開しています。Google Colabの方は、実際に動かしていただくこともできます。
| sample-cvae-mnist.ipynb | Google Colab | GitHub |
| sample-cvae-mnist-manifold.ipynb | Google Colab | GitHub |
ハイパーパラメータ
TensorFlow公式サンプルでは、潜在変数全体を2次元画像で表す(2D manifold)ために潜在変数の次元(latent_dim)を2としていました。ただ、AutoEncoder, VAE, CVAEの比較 〜なぜVAEは連続的な画像を生成できるのか?の実験によれば次元数の大きいほうが鮮明な結果になっているので。最後のmanifold以外は潜在変数を64次元にします。
訓練・テストにはMNISTデータ全体(それぞれ60000, 10000)を使い、全ての訓練データに正解ラベルを付けて学習させました。エポック数は100(manifoldの方は50)、ミニバッチサイズは32としました。
画像の復元
MNISTの先頭から32枚の画像を復元させてみます。
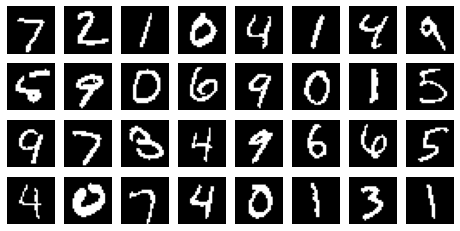
まずは画像及び正しいラベルを与えてDecoderにかけてみます。

細部はぼやけたものの、自然な数字が復元されました。
次に、32枚全てに**「8」のラベル**を与えてみます。ここで扱う32枚の入力に「8」のデータは含まれていないので、データセットに存在しないデータを生成することになります。

一部破綻してしまいましたが、半分くらいは8として許せる文字になっていそうです。CVAEが指定したラベルのデータを生成できることを確認できました。
筆跡の連続変化
VAEシリーズの特徴として、連続的なデータを生成できることがあります。VAEであれば、例えば「0」の潜在変数から「1」の潜在変数までを連続的に変化させることで、徐々に別の数字に変化する画像を作れます。

CVAEでは、潜在変数からはラベルの情報が取り除かれ、筆跡の違いを表現するようになると言われています。そこで、ラベルを固定して潜在変数を連続変化させて、筆跡が連続変化する画像を作ってみます。
入力は、前節と同様MNISTの先頭32枚から選びました。
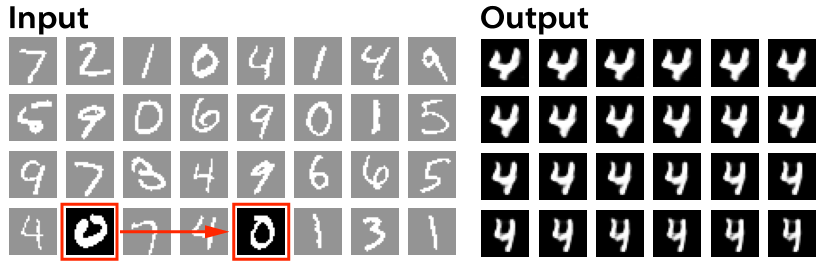
「線の太い0」から「線の細い0」までの潜在変数と、「4」のラベルで生成した連続画像です。下に行くにつれて線がだんだん細くなり、文字の縦横比も変化しました。
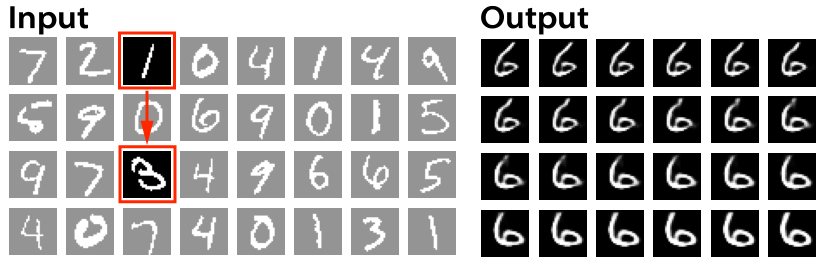
こちらは「右に傾いた1」から「左に傾いた3」までの潜在変数と「6」のラベルで生成した連続画像です。数字の傾きが徐々に変化するのが分かります。
2D Manifold
2次元の潜在変数の空間全体から画像を生成し、縦横に並べた画像は2D Manifoldと呼ばれます。VAEならこのような画像になります。

ラベルをいくつか指定してCVAEの2D Manifoldを生成させてみます。なお、潜在空間内の配置方向は学習のたびに変わるので、画像の向きに意味はありません。

「4」を指定した時の結果です。潜在変数が、文字の縦横比や傾きの情報を持っていることが分かります。
個人的に面白かったのが「2」の結果です。数字の下の部分をクルッと丸めて書くかどうかが分かれています。
CVAEでは潜在空間からラベルの情報が取り除かれ、筆跡の情報を保持するようになることが確認できました。
おわりに
本記事では、TensorFlow 2系のVAEサンプルを改変し、CVAEを実装しました。また、MNISTを学習したCVAEで画像の復元や連続変化などを試しました。
TensorFlow初心者なので、確実に動くサンプルコードを参考にしながら実装できたのはとても助かりました。書き方もそれなりに理解できた気がするので、今後はいろいろなデータを学習させてみることにします。
参考記事
-
Conditional variational AutoEncoderをTensorflowで実装する - Qiita
- TensorFlow 1系によるCVAEの実装報告です。実装の留意点が多数解説されています。
-
AutoEncoder, VAE, CVAEの比較 〜なぜVAEは連続的な画像を生成できるのか?
- オートエンコーダの基礎からVAE, CVAEまでが図入りで分かりやすく説明されています。潜在変数の次元を変えての復元や連続変化の実験結果も掲載されています。
-
深層生成モデルを巡る旅(2): VAE - Qiita
- 目的関数の式も載っている詳しめの記事です。β-VAE、VQ-VAEなどのさらに新しい成果も紹介されています。