はじめに
この記事はEnigmo Advent Calendar 2018の11日目です。
Enigmoでは、データウェアハウス(DWH)としてBigQueryを使っていて、サービスのアクセスログやサイト内の行動ログ、データベースのデータをBigQueryへ集約させています。
データベースからBigQueryへのデータ同期にはApache Airflowを使っていて、今日はその仕組みについて紹介します。
Apache Airflowとは
Airflowは、pythonでワークフロー(DAG)を定義すると、そのとおりにタスク(オペレーター) をスケジューリングして起動してくれるツールです。GCPでもGKE上でAirflowを動かすCloud Composerというサービスが提供されていてご存知の方も多いと思います。
データの処理の単位をオペレータで定義し、その処理の依存関係を反映したワークフローをDAGで定義してやればデータ処理のパイプラインを実現することが可能となります。
DBからBigQueryへのデータパイプライン
データの流れ
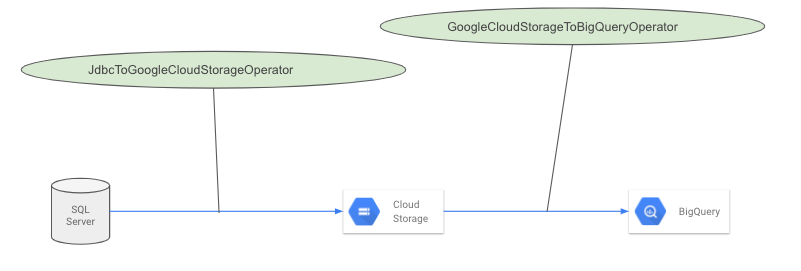
データの流れとしては、上の図の通り大きく2フェーズに分かれていて、まずはDB(SQL Server)からGoogle Cloud Storage(GCS)へデータをアップロードしています。その次にGCSからBigQueryへそのデータをロードしています。
それぞれのフェーズをAirflowのタスクの単位であるオペレーターで実現していて、さらに2つのオペレーターはそれぞれ同期するテーブルごと別のタスクとして存在し、それらをDAGという1つのワークフローの単位でまとめています。
SQL ServerからGCSへ
JdbcToGoogleCloudStorageOperator
SQL ServerからGCSへのデータの移動は JdbcToGoogleCloudStorageOperator というAirflowのオペレーターが担当します。
DBがMySQLの場合はMySqlToGoogleCloudStorageOperatorというAirflowに組み込みのオペレーターがあるんですが、バイマのデータベースはSQL Serverなので、JDBCのクライアントで同様の働きをするオペレーターを自前で作ったものが JdbcToGoogleCloudStorageOperator です。Airflowのプラグインとして公開しています。
このオペレータでの処理は、まずDBからSQLでデータを抽出し、一度JSONL形式のファイルとしてのオペレーターが動くサーバーのローカルに保存され、それがGCSへアップロードされるという流れです。BigQueryへロードするときにスキーマ定義が必要なので、データファイルとは別にスキーマ定義のファイルもJSON形式でGCSへアップロードされます。
スケジューリングと更新差分抽出の仕組み
DAGのスケジューリング間隔は1時間に設定しています。するとAirflowは時間を1時間ごとに期間を分けてDAGにその期間の開始時刻(execution_date)、終了時刻(next_execution_date)をテンプレートのパラメーターとして渡してくれます。それらを
データ抽出SQLのWHERE句のところでレコードの更新日時を記録するカラム(下の例ではupdated_at)を基準に期間指定すると、その期間に更新があったレコードだけが抽出され、BigQuery側へ送られる仕組みです。
select * from table1
where "{{execution_date.strftime('%Y-%m-%d %H:%M:%S')" <= updated_at
and updated_at < "{{next_execution_date).strftime('%Y-%m-%d %H:%M:%S')}}"
もし間隔を変えてもDAGを編集することなくSQLがその期間に合わせて変わってくれるので便利です。
GCSからBigQueryへ
GoogleCloudStorageToBigQueryOperator
GCSからBigQueryへはその名の通りAirflow組み込みのGoogleCloudStorageToBigQueryOperatorというオペレーターがやってくれます。
BigQuery側のデータセットは同期元DBのデータベース単位、テーブルは同期元DBのテーブル単位に分けています。BigQuery側のテーブルはDB側のレコードの更新日ごとに日付分割しています。
BigQueryの更新はDMLは使わずに、ファイルを読み込みジョブで更新されます。そうするとDB側のレコードが更新されるとBigQuery側には重複してレコードが溜まっていくのですが、それは後述の重複除外ビューで解決しています。
BigQuery側でレコードの重複を除外
BigQuery側のテーブルでは、次のようなSQLでビューテーブルを作ることで、同期元のDBでレコードが何度も更新されても常に最新のレコードしか現れない仕組みになっています。
この例は、主キーがidで更新日時のカラムが updated_at の場合のSQLです。同一idに対して常に最新のupdated_at をもつレコードしかこのビューには出てきません。
SELECT *
FROM (
SELECT *, ROW_NUMBER() OVER (
PARTITION BY id
ORDER BY updated_at DESC) etl_row_num
FROM
`db1.table1_*`)
WHERE etl_row_num = 1
Airflowで便利だった機能
Airflowの機能でこの仕組みをつくるのに助けられた機能がいくつかあったので紹介します。書ききれてないですが、ほかにもたくさんあります。
Catchup
DAGのスケジュールを過去の期間にさかのぼって実行してくれる機能なんですが、非常にありがたかったです。
過去のデータの移行でも差分同期の仕組みがそのまま使えましたし、一度に同期せずに、期間を区切って少しずつデータを持っていけたので、同期元のDBにも負荷をかけずにすみました。
Connection、Variable
Connectionは接続先となるDBやGCPへの認証情報を一元管理してくれ、一度設定すればどのDAGからアクセスできて便利でした。次のPoolも同じなんですが、設定はGUIでもCLIでも設定できるので、ansibleなどのプロビジョニングツールでも設定できたのもありがたかったです。
Variableも単なるキーと値を設定できるだけなんですが、DAGを汚すことなくdevやproductionなどリリースステージごとに値を切り替えられて便利でした。
Pool
タスクの同時実行数を制限する機能です。Poolはユーザーが定義でき、そのPoolにオペレーターを紐付けるとそのオペレーターはそのPoolのslot数を超えて同時実行されません。データ抽出のタスクが1つのDBに対して多数同時実行されてしまうとそのDBのコネクションも同時に消費され、枯渇しかねませんが、このPoolで上限数を設定できたので安心でした。
まとめ
最初は手っ取り早くcronとスクリプトで作ってしまおうと思ったのですが、すこしなれるまで時間はかかったもののAirflowで作って良かったです。開発が進むにつれ、特にプロダクション環境で動かすにあたっていろいろ考慮すべきことが出てくると思うのですが、作りながらほしいと思った機能が先回りされているかのように用意されていてとても助かりました。全て使いきれてないですが、ワークフロー運用のノウハウがたくさん詰まった良いプロダクトだと思いました。