私が所属しているAirion株式会社で勉強会があり、私は月ごとのLLM周りの論文で個人的に面白かったものをピックアップして話すことにしています。
今回は主に5月に出たLLM周りの論文を紹介していこうと思います。5月はRLの面白い論文が多かった印象です。
※ 論文についての説明はChatGPT(o3 + web research)でまとめたものをもとに修正・改変しています。
目次
1. Reinforcement Learning for Reasoning in Large Language Models with One Training Example
“1つの学習事例による大規模言語モデルの推論強化学習”
2. Absolute Zero: Reinforced Self-play Reasoning with Zero Data
"Absolute Zero:データゼロによる強化自己対戦型推論"
3. LLMs Get Lost In Multi-Turn Conversation
“大規模言語モデルはマルチターン対話で迷子になる”
4. Towards a Deeper Understanding of Reasoning Capabilities in Large Language Models
"大規模言語モデルの推論能力に対する深い理解に向けて"
5. When Thinking Fails: The Pitfalls of Reasoning for Instruction-Following in LLMs
"思考が失敗する時:LLMにおける指示追従型推論の落とし穴"
6. Learning to Reason without External Rewards
"外部報酬なしで推論を学習する"
7. Spurious Rewards: Rethinking Training Signals in RLVR
"偽の報酬:RLVRにおける訓練信号の再考"
8. The Climb Carves Wisdom Deeper Than the Summit: On the Noisy Rewards in Learning to Reason
"頂上ではなく登る過程が知恵を深める:推論学習におけるノイズの多い報酬について"
9. ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models
"ProRL:長期強化学習が大規模言語モデルの推論の限界を広げる"
✅ 1. Reinforcement Learning for Reasoning in Large Language Models with One Training Example
“1つの学習事例による大規模言語モデルの推論強化学習”
[Submitted on 29 Apr 2025 (v1), last revised 25 May 2025 (this version, v2)]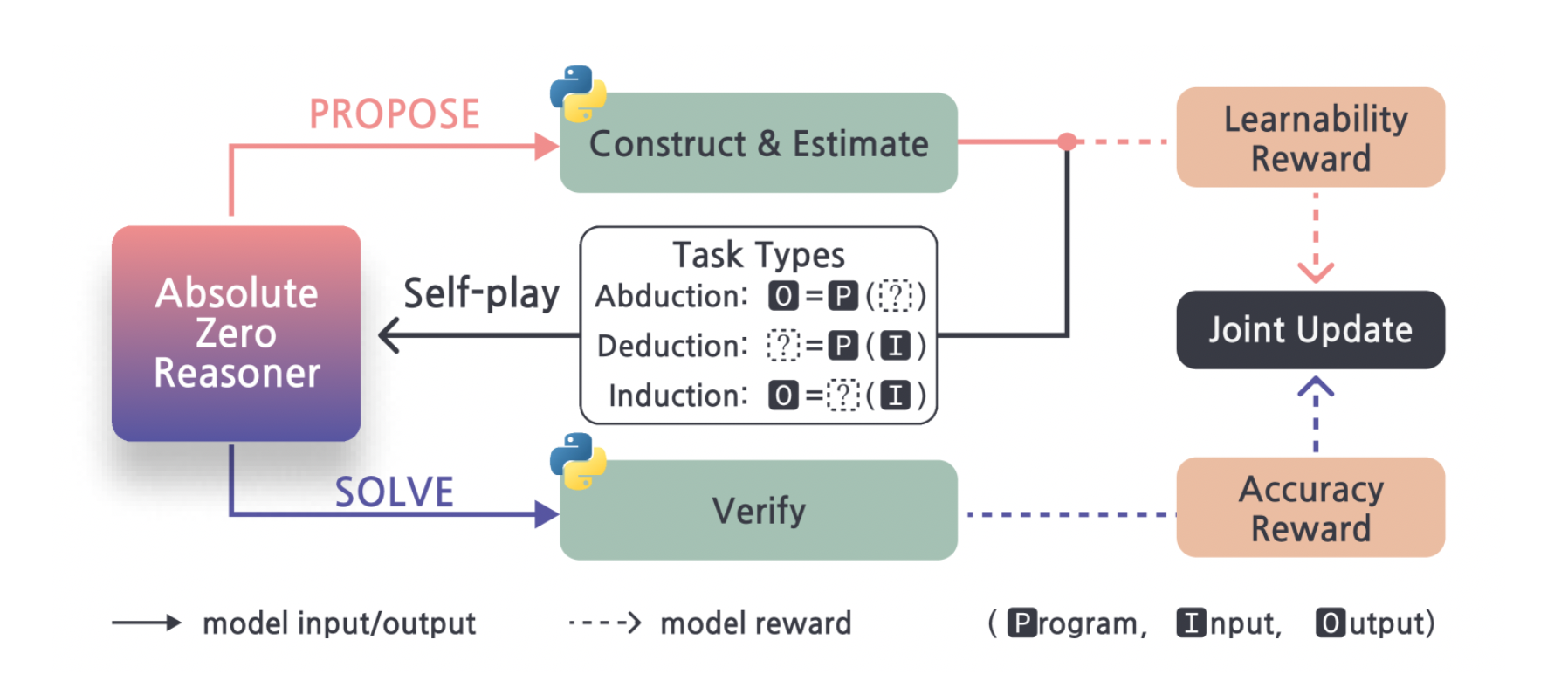
1.1 概要
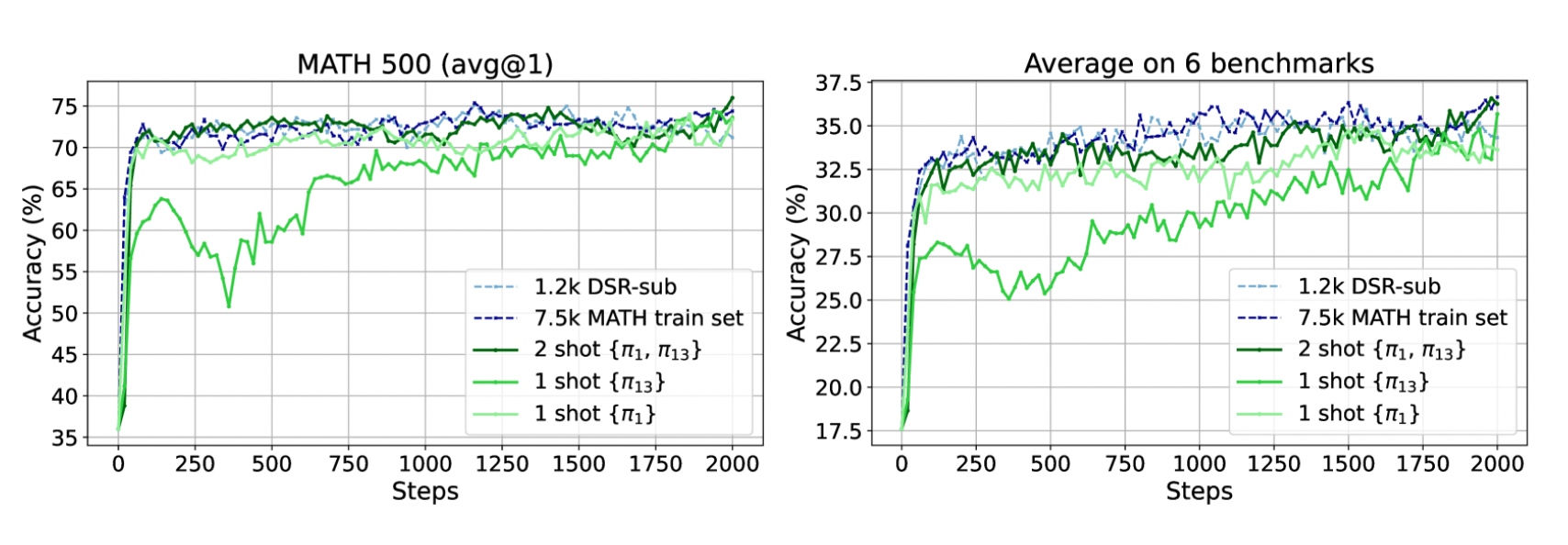
本研究では,検証可能な報酬(Verifiable Reward)を用いた“1-shot RLVR”(1つのトレーニング例だけで行う強化学習)により,LLMの数学的推論能力を飛躍的に向上させる手法を提案している。Qwen2.5-Math-1.5Bモデルに対し,1つの重要な例題を用いたRLVRを適用したところ,MATH500ベンチマークにおいて正答率を36.0%から73.6%へとほぼ2倍に引き上げ,6つの数学的推論タスク平均でも17.6%から35.7%へと同等の大幅改善を達成した。さらに,DeepScaleRの1.2kサブセットを用いた従来手法と同等の性能を,データ量1例のみで再現できた点が特筆される。
1.2 背景
近年のLLMは,大規模データを用いることで数学的推論タスクに挑戦しているが,実際には数千~数万件の例が必要となり,データ収集やコスト面で制約が大きい。一方で,人間は少数の例を学ぶだけで同様の推論が可能であり,LLMにも極少数ショットで性能を高める方法の探索が求められていた。そこで本論文は,「最小限のデータでRLを通じて推論能力を引き出す」ことを目的とし,特に「1例のみで報酬を与える」ことを主眼とした点が従来研究と異なる。
1.3 手法(1-shot RLVR)
-
検証可能な報酬の設計
- 数学問題に対してモデルが生成した解答を,正解か否かで明確に判定できる仕組みを報酬関数として用いる。
(正答時に高報酬,誤答時には低報酬)
- 数学問題に対してモデルが生成した解答を,正解か否かで明確に判定できる仕組みを報酬関数として用いる。
-
クリティカル例(Critical Example)の選定
- MATH500の検証セットから複数の候補例を抽出し,それぞれを1-shot RLVRした際の性能向上を検証して,最も有効な1つの例を特定した。
-
強化学習アルゴリズムと損失
- GRPO(Generalized Reward-Poisson Objective)およびPPO(Proximal Policy Optimization)を適用し,特に方策勾配損失(policy gradient loss)が性能向上の主因であることを検証した。
- また,探索を促すためにエントロピー損失を適切な係数で導入し,1例のみでも多様な解答候補を模索できるよう工夫した。
1.4 主な実験結果
-
Qwen2.5-Math-1.5Bの劇的改善
- MATH500: 36.0% → 73.6%
- 6タスク平均: 17.6% → 35.7%
- これは,DeepScaleRの1.2kサブセットで得られる結果と実質的に同等である。
-
他モデル・他例でも再現性あり
- Qwen2.5-Math-7B,Llama3.2-3B-Instruct,DeepSeek-R1-Distill-Qwen-1.5Bなど他のLLMでも,約30%以上のMATH500性能向上が得られた。
- GRPOおよびPPOの両方で大幅な改善が確認され,手法の汎用性が示された。
-
2例以上の場合の変化
- 2つの例を使うと,MATH500: 73.6% → 74.8%,6タスク平均: 35.7% → 36.6% というわずかな改善が得られ,1-shotとほぼ同等のデータ効率を維持した。
-
エントロピー損失単独の効果
- 正答報酬を与えずにエントロピー損失のみを適用しても,Qwen2.5-Math-1.5BのMATH500性能が27.4%向上することが確認され,探索促進が極めて重要であることを示唆した。
1.5 興味深い現象
-
ポストサチュレーション一般化(Post-Saturation Generalization)
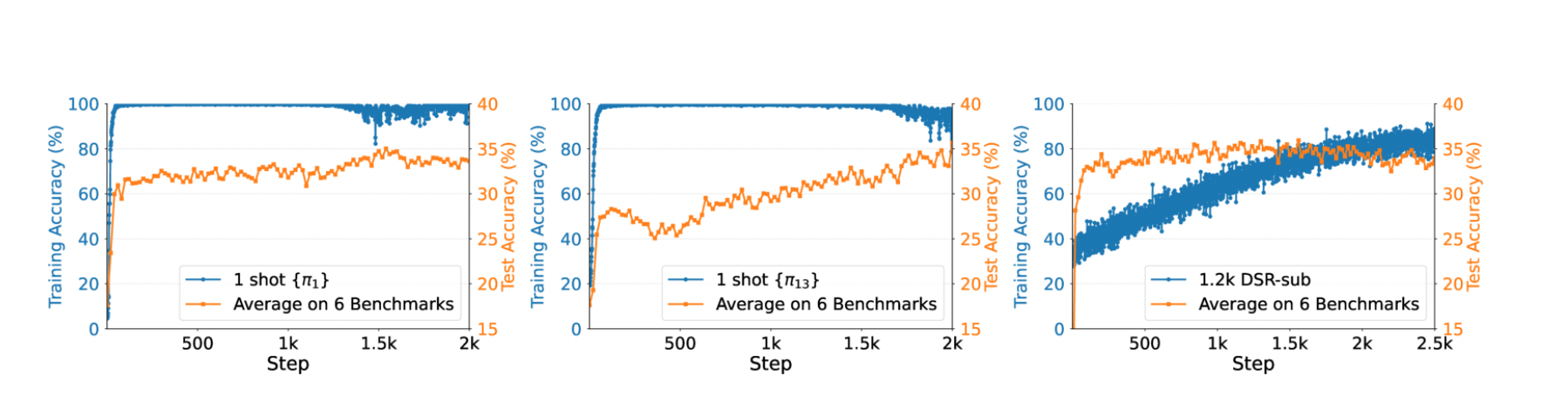
トレーニングデータ上では精度がほぼ100%に到達した後も,テストセットの性能がさらに向上し続けるという,通常の「過学習」とは逆の挙動が観察された。 -
クロスドメイン一般化(Cross-Domain Generalization)
- 1つの数学例でRLVRしたモデルが,他の数学的ベンチマークや異なるドメインのタスクにおいても平均10~20%程度の性能向上を示し,少数の例だけで汎用的な推論能力が強化される可能性が示された。
-
自己内省の頻度増加(Increased Self-Reflection)
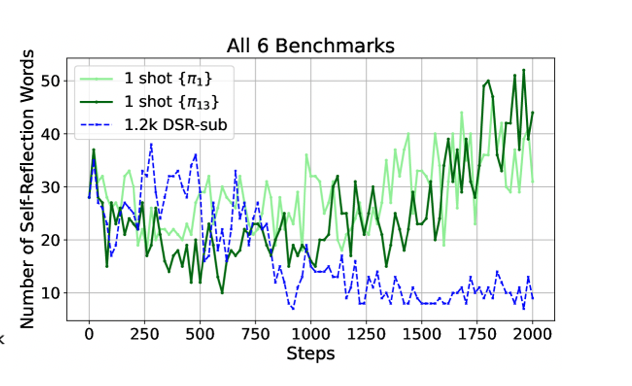
1-shot RLVR後に,モデルが自らの解答過程を振り返る自己内省(self-reflection)の回数が増加し,誤答時にも詳細な理由付けや再考を試みる傾向が強まったことが報告された。
1.6 意義と今後の展望
-
データ効率性の大幅な向上
- 従来は数千~数万件を要した数学的推論タスクへのチューニングが,たった1例で同等の成果を達成したことは,リソース制約のある環境や専門的ドメインへの適用可能性を大きく広げる。
-
政策勾配の役割と探索
- 政策勾配損失を中心に据えた1-shot RLVRのメカニズムは,少数データの下でも有効な方策を導き出せることを示したため,今後は軽量かつ安定した政策勾配アルゴリズムの研究が期待される。
-
さまざまなドメインへの応用
- 数学だけでなく,物理・化学・プログラミングコード生成・検証など,他分野でも「検証可能な報酬」を構築できるタスクに対して,1-shot RLVRを展開できる可能性がある。
-
モデル圧縮や高速化との組み合わせ
- 1-shot RLVRにより推論能力を高めた小規模モデル(1.5B程度)を活用することで,実運用環境での低レイテンシ推論やエッジデバイス対応が現実的になる道が開かれる。
✅ 2. Absolute Zero: Reinforced Self-play Reasoning with Zero Data
“Absolute Zero:データゼロによる強化自己対戦型推論”
[Submitted on 6 May 2025 (v1), last revised 7 May 2025 (this version, v2)]
2.1 概要
本論文では、外部データを一切用いずに自己提案と自己検証による反復学習を行う新たな強化学習パラダイム「Absolute Zero」を提案します。提案手法であるAbsolute Zero Reasoner(AZR)は、コード実行環境を報酬検証源とし、問題生成と解答を自己完結的に行うことで、数学およびコーディングベンチマークで最先端の性能を達成します。さらに、AZRはモデル規模やモデルクラスを問わず適用可能であり、従来の人手による専門的データを用いたゼロ設定モデルを上回る汎化性能を示しています。
2.2 課題設定と背景
- 従来の強化学習による推論強化(RLVR : Reinforcement Learning with Verifiable Rewards)では、人手作成の問題・解答データを大量に必要としていた。
- しかし、高品質データの収集コストやドメイン固有データの不足が学習のボトルネックとなり得る。
2.3 「Absolute Zero」パラダイムの提案
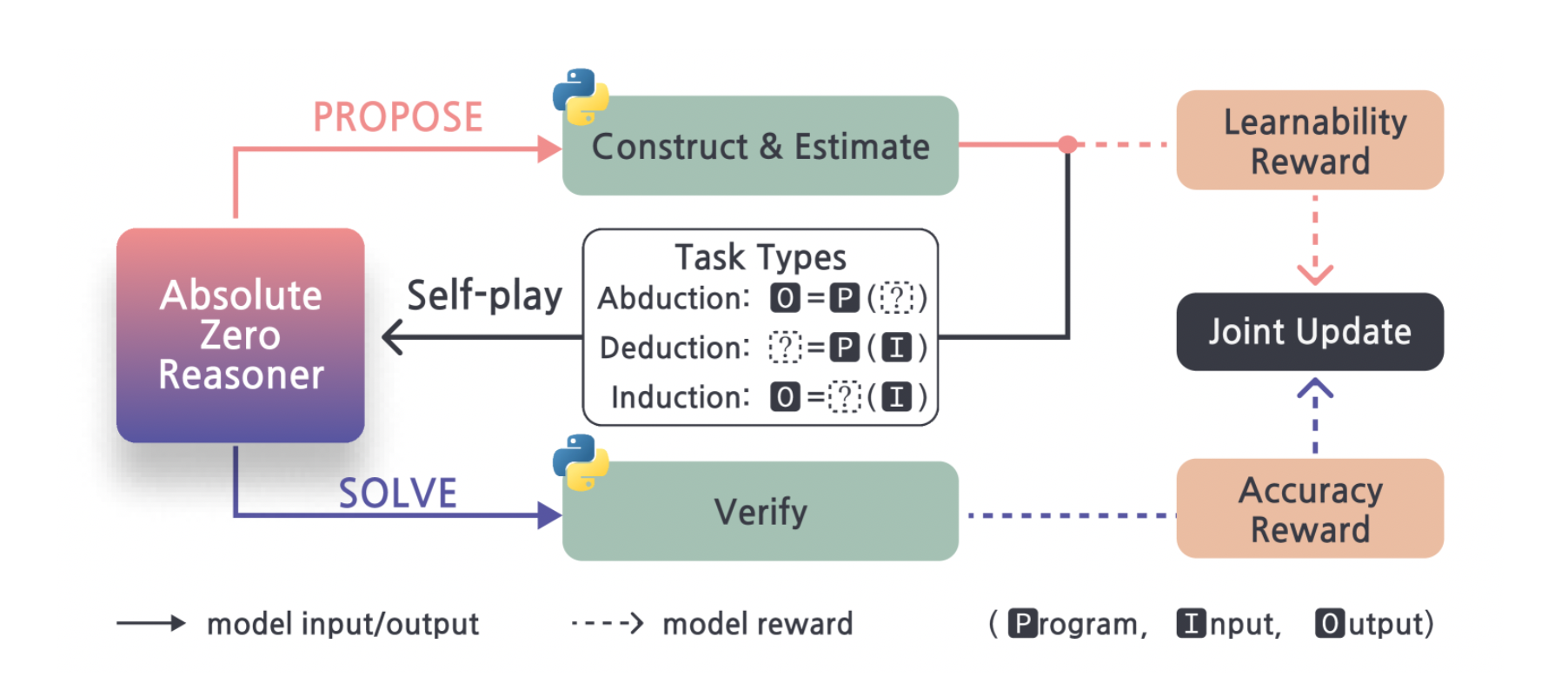
- モデル自身が外部データを一切使わずに学習カリキュラム(コーディング問題や数学問題)を自動生成し、自己検証を行うことで推論能力を強化する仕組みを構築
- 具体的には、(1)タスク生成モジュール、(2)コード実行エンジンによる検証、 (3)強化学習ループの三要素を組み合わせた「Absolute Zero Reasoner(AZR)」を実装
1. タスク生成の仕組み
- モデルは過去の学習履歴(正答・誤答の情報)をもとに「今もっとも学習効果が得られる問題」の難易度や形式を推定し、その場で問題文とテストケースを生成
- 生成されるタスクは主にコーディング課題(例:入出力形式のアルゴリズム問題)や数学推論問題(例:数式計算や証明問題)から構成される。
2. コード実行エンジンによる検証
- 生成したコーディング問題は、モデルが出力したコードをサンドボックス上のPython環境などで実行し、テストケースをクリアできたかどうかを自動で判定。
- 数学問題についても数式処理エンジンや数値検算を用いて解答の正誤を確認し、「正解=報酬1、誤答=報酬0」といった明確な報酬信号を取得する。
3. 強化学習ループ
- 自己生成タスクへの解答結果から得られた報酬をもとに、PPOなどのRLアルゴリズムでモデルのパラメータを更新。
- タスク生成→解答→検証→報酬→更新、というサイクルを繰り返すことで、モデルは自律的に推論能力を高めていく。
2.4 実験と評価結果
- コーディングベンチマーク(HumanEval、MBPPなど)および数学推論ベンチマーク(GSM8K、MATH)を用いて評価
- Qwen2.5-7B CoderをベースとしたAZRは、既存のゼロ設定モデル(PRIME-Zero, ORZなど)と比較して、コーディング+5.0%、数学+15.2%と、大幅な性能向上を達成。
- 小規模モデル(Qwen2.5-3B, Llama3.1-8B)でも同様に安定して性能が改善され、モデルサイズに依存せず有効であることを実証
2.5 主な貢献と意義
-
Zero Data 強化学習
- 外部データを一切使わず、モデル自身が自律的に学習カリキュラムを生成し続ける点で、データ収集コストやドメイン固有データ不足の問題を解消
-
検証可能な報酬設計
- コードエグゼキュータや数学検算エンジンを活用し、正誤判定を完全に自動化することで一貫性のある報酬を得る仕組みを実現
-
モデル汎用性
- 大規模/小規模を問わず、さまざまな言語モデルに容易に組み込める汎用的なRLフレームワークとして設計されている
2.6 今後の展望
- 現在はコーディングと数学問題に特化しているが、同様の自己生成+自己検証手法を自然言語理解や常識推論といった他ドメインに拡張可能性がある。
- タスク生成モジュールをさらに高度化し、メタ学習や複雑な探索戦略を組み込むことで、より効率的な「自己カリキュラム学習」が期待される。
- 有限の人手データとハイブリッドで運用し、レアドメインやデータ量が極端に限られた領域での学習効率向上も検討課題として挙げられている。
✅ 3. LLMs Get Lost In Multi-Turn Conversation
“大規模言語モデルはマルチターン対話で迷子になる”
[Submitted on 9 May 2025]
3.1 概要
この論文では,シミュレーション環境を用いて,大規模言語モデル(LLM)の「単一ターン(Fully-Specified)」対「マルチターン・未完全指示(Sharded)」設定での性能を比較し,後者では平均39%もの性能低下が生じることを示しています。性能劣化の要因を「適性(Aptitude)のわずかな低下」と「信頼性(Reliability)の大幅な悪化(Unreliabilityの増大)」の二つに分解し,特に誤った前提にもとづく早期の解答試行や,過去の(誤った)回答への過度な依存が主因であると分析しています。これにより,LLMはマルチターンの会話で「一度見当を誤ると挽回できずに迷子になる(Get Lost)」現象が明らかになりました。
3.2 目的
LLMが単一ターン評価では高精度を示す一方で、実際の対話のように情報が段階的に与えられる「マルチターン」環境では著しく性能が低下する現象を調査すること。
3.3 実験手法
完全指定されたタスク(数学問題やコーディングなど)を複数の部分指示(シャード)に分割し、モデルに段階的に入力して対話をシミュレーション。15種類の主要モデル(オープン・クローズド合わせて)を対象に、単一ターン時とマルチターン時の性能を比較。
3.4 主な発見
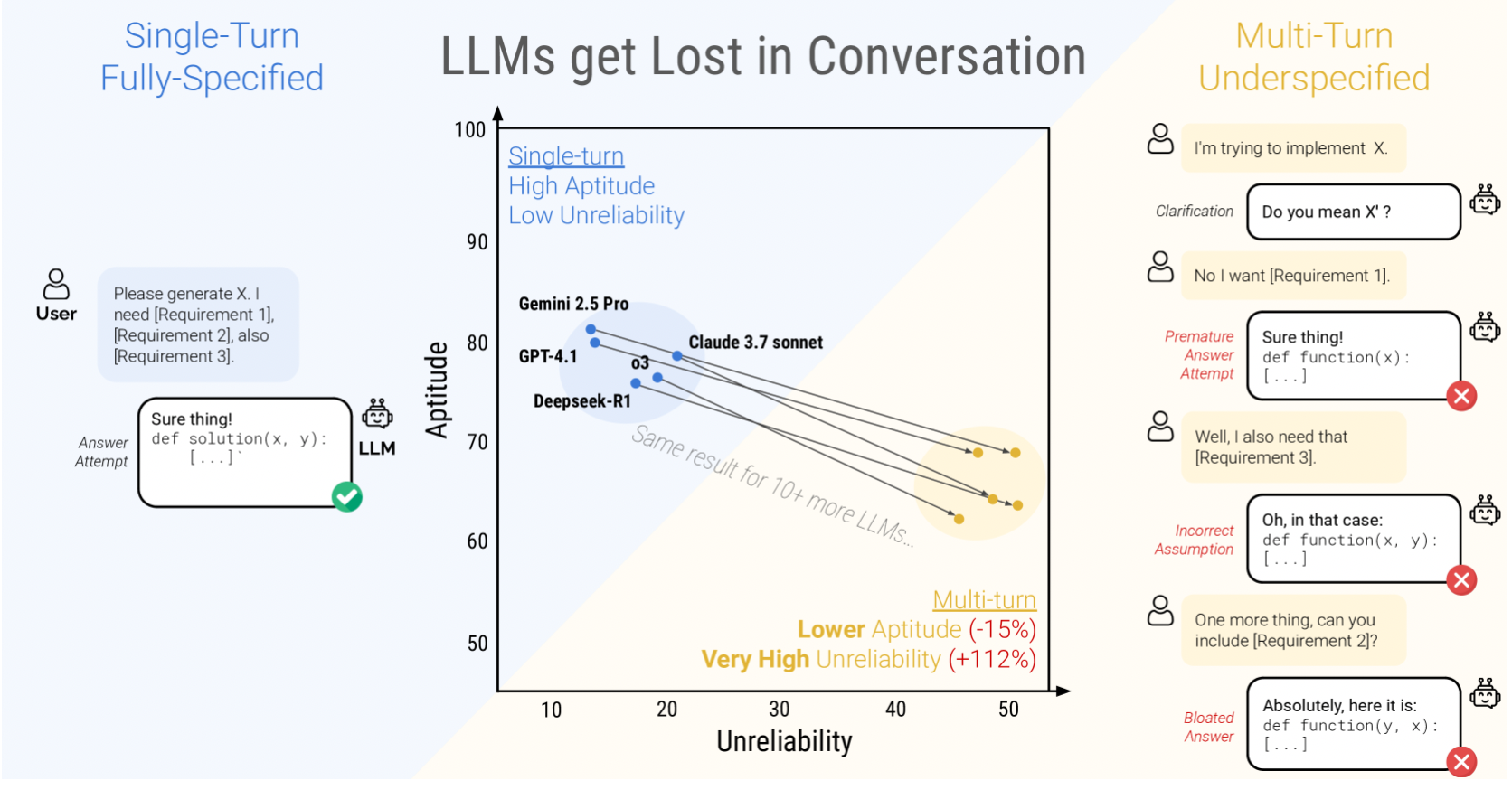
- マルチターン時の平均性能ドロップは約39%と大幅
- 能力自体(ベストケースでの性能)は単一ターンに比べてやや下がる程度だが(平均-15%)だが、誤った前提を立てたときに後続ターンで修正できない「信頼性低下」が大きく(平均+112 %)影響している。
- モデルは部分的指示でも「まるですべて分かっているかのように」早期に結論を提示し、その仮定が誤っていると以降の対話で回復不能になる、いわゆる「会話で迷子になる」現象が顕著。
- 温度調整や一度応答を結合し直すエージェント型の手法では誤った前提の問題を解消できず、マルチターン性能の向上には至らなかった。→ 既存の改善策の限界
3.5 示唆と今後の課題
- モデル開発では「マルチターン信頼性(誤った前提を抑え、ユーザの追加情報を正確に反映する能力)」を最優先で評価・改善する必要がある。
- 対話中に不確実性を検知して再質問を促す仕組みや、誤りを自己修正できる機能を組み込むことが求められる。
- 「対話修正成功率」などの新たな評価指標を開発し、創造的タスクや多言語・マルチモーダル環境、さらには実ユーザを交えたヒューマンインザループ実験での検証を進める必要がある。
✅ 4. Towards a Deeper Understanding of Reasoning Capabilities in Large Language Models
“大規模言語モデルの推論能力に対する深い理解に向けて”
[Submitted on 15 May 2025]
4.1 概要
本論文では、SmartPlayベンチマーク上で自己反省(Reflection)、ヒューリスティック変異(Oracle)、およびプランニング(Planner)といったプロンプト技術を用い、さまざまな規模のオープンソースLLMの動的環境下での適応能力を系統的に評価しています 。その結果、大規模モデルは小規模モデルより一貫して高い性能を示すものの、適切に設計されたプロンプトによって小規模モデルが性能差を埋められる場合がある一方で、得られる性能向上は不安定で大きなばらつきを伴うことが分かりました 。さらに、多段階推論や空間的計画を要する動的タスクにおいては、自己学習や真のエマージェント推論の証拠はほとんど見られず、従来の静的ベンチマークでは捉えきれない根本的な限界が浮き彫りになっています
4.2 研究目的
LLMを動的環境(2Dグリッドゲームやテキスト多段階タスク)における“エージェント”として評価し,従来の静的ベンチマークでは捉えにくい推論・適応能力を検証する。
4.3 検証手法
- 小規模モデル(3B〜7B)と大規模モデル(13B以上)を同一環境で比較し,成功率・ステップ数・安定性などを測定
プロンプト技法として以下の3つを比較:
- 自己内省(Self-Reflection)
-
ヒューリスティック変異(Heuristic Mutation)
→ 論文中では,エージェントが過去エピソードで用いたヒューリスティック(行動ルール)を保存する「Persistent Memory」を導入しています。各エピソード終了時に,環境から得られた報酬や行動ログをもとに「最も高い報酬を獲得したヒューリスティック」をPersistent Memoryに保持し,次のエピソードでそのヒューリスティックを出発点として利用します - プランニング(Planning)
4.4 モデルサイズとプロンプトの影響
- モデルが大きいほどベース性能は高いが,適切なプロンプト技法を用いれば小規模モデルの性能差を縮められる。
- 一方で,長すぎるCoT風プロンプトは小規模モデルの反応精度を低下させるが,大規模モデルでは基本的にほとんど影響がなく、むしろ安定化
- ただし、タスク難易度や報酬密度によっては大モデルでもプロンプト効果が不安定(Messenger での変動)で、過度な推論によって劣化する場合もある
4.5 各プロンプト技法の特徴と効果
-
自己内省(Self-Reflection)
- 小規模モデルでは誤答後の再評価が増え,成功率が向上。ただし応答が冗長化しステップ数が増加する場合あり
-
ヒューリスティック変異(Heuristic Mutation)
- 小規模モデルで最も安定して成功率を引き上げられる。大規模モデルでは生成コストが高く,過度に適用すると効率が落ちる可能性
-
プランニング(Planning
- “Reflection + Planner” は小モデルで顕著に効く場合と大きく悪化する場合があり,Hanoi・Messenger では大モデルが低下するケースも
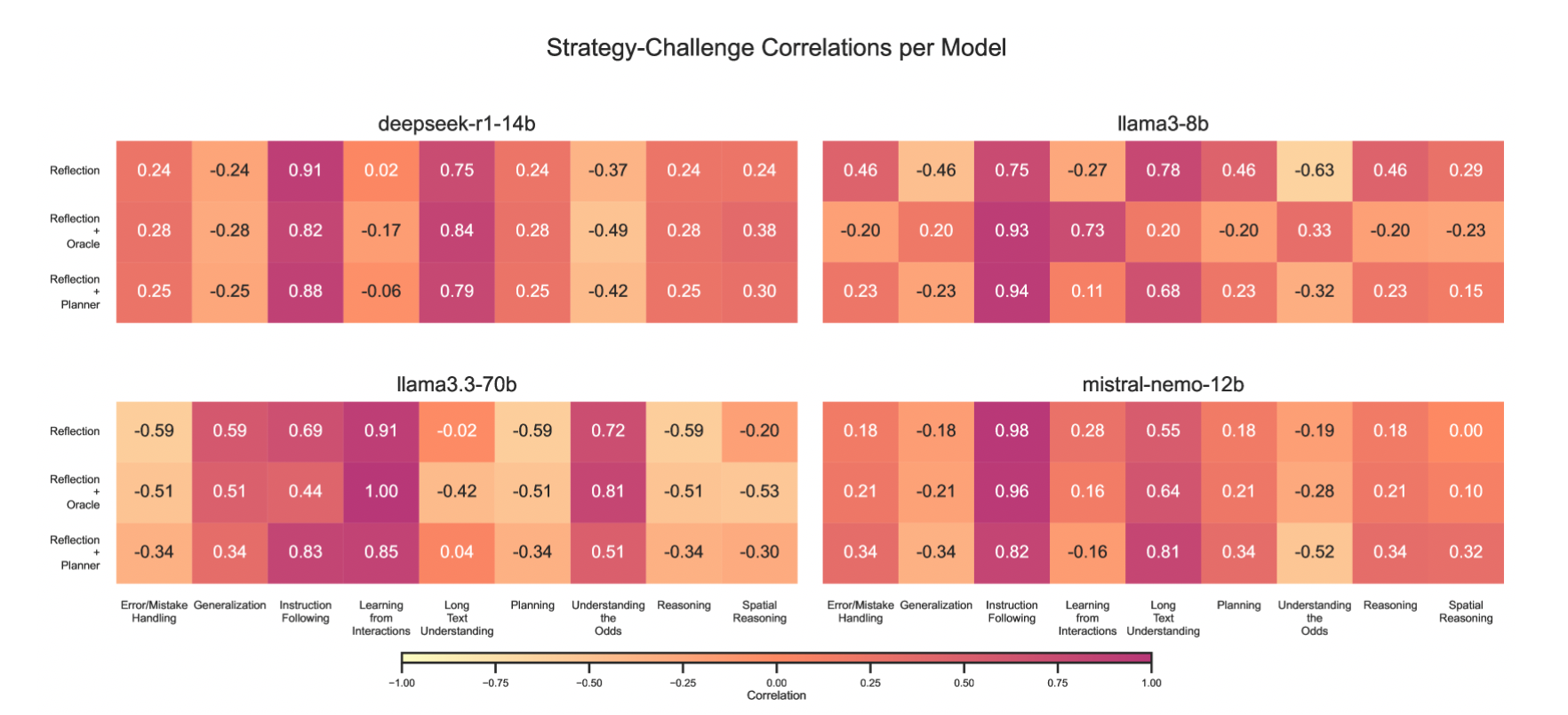
↑ 各プロンプト技法がBaseプロンプトに対して示した性能向上と、各チャレンジの次元(特性)との間のピアソン相関係数のヒートマップ。各環境ごとに3回の評価を実施して得られたもの。(Oracleはヒューリスティック変異のことを指す)
4.6 結果
- Tower of Hanoi(3枚)では大規模モデルが人間に近いスコア2.0に到達し、小規模モデルも高度なプロンプト技法により一時的に追いつける
- 一方、Messengerのような長文情報を把握しつつ、空間構造と敵の位置変化をリアルタイムに予測・反映しながら、回避戦略を含む柔軟な行動判断を行うタスクでは、人間の成功率が100%なのに対し,モデルは規模に関わらず安定性に欠け,依然大きく劣ることが示された
- 高度なプロンプト技法を使っても,「モデルが自律的に新しい思考パターンを生み出した」わけではなく,「提示されたヒントを再構成しているにすぎない」という結論
今回論文中で使用されたベンチマークは SmartPlay という「動的に変化する環境」において,ヒューリスティックやプランニング,自己内省などのプロンプト技法を駆使しながら連続的に意思決定を行うベンチマーク群
例)Messenger(メッセンジャー)
- マップ上に立っている「届け先の人物(ゴール)」と,「障害物・敵」が配置された環境で,テキストで与えられる複数の同義語を含む指示を正しく解釈して,最短経路かつ敵を回避しながらメッセージを届けるタスクである
- ここでは,「長文テキスト理解」「空間的ナビゲーション」「動的な回避戦略」を同時に考慮し,途中で変化する敵の位置を逐次的に予測しながら意思決定を行う必要がある
4.7 示唆と今後の課題
-
動的評価の重要性
- 静的ベンチマークだけでなく,環境変化に対応できるかを測る動的タスクが不可欠
-
プロンプトとモデル設計のトレードオフ
- 小規模モデルのブーストには有用だが,計算コストやレスポンス速度とのバランス調整が必要
-
Emergent Reasoningの探究
- 現状のプロンプト技法では限界があるため,アーキテクチャやオンライン学習など根本的な改変が求められる。
-
他ドメインへの応用
- ゲーム以外にもロボット制御や対話エージェントなど,動的意思決定が必要なタスク全般への展開が期待される
✅ 5. When Thinking Fails: The Pitfalls of Reasoning for Instruction-Following in LLMs
“思考が失敗する時:LLMにおける指示追従型推論の落とし穴”
[Submitted on 16 May 2025 (v1), last revised 20 May 2025 (this version, v2)]
5.1 概要
この論文では,チェイン・オブ・ソート(CoT)による明示的推論が,命令遵守タスク(IFEvalおよびComplexBench)の正確性を大きく低下させることを,多数のモデルを用いた評価実験により明らかにしています。詳細なケーススタディとattention解析を通じて,CoTが単純な制約トークンへの注意を逸らすメカニズムを示し,新たに「制約アテンション」指標を提案しています。さらに,Few-Shot in-context learning,自己省察,自己選択的推論,分類器選択的推論の4つの緩和策を検証し,特に分類器選択的推論が失われた性能を最も効果的に回復することを実証しています
5.2 問題提起
- Chain-of-Thought(CoT)などの推論強化プロンプトを使うと、LLMの命令遵守能力(instruction-following accuracy)が大きく低下するケースがある。
- 従来、CoTは複雑推論タスクで効果を示してきたが、ルールやフォーマットといった「命令そのものを正しく守るタスク」では逆に誤りを誘発しやすい。
5.3 評価ベンチマーク
- IFEval:単純かつルール検証可能なタスク集。特定キーワードの挿入や指定フォーマットの厳守が求められる。
- ComplexBench:複数の制約が組み合わさった複雑タスク群。手順やフォーマットを複合的に守る必要がある。
これらを、14種類のモデルで「CoT適用前後」で比較した結果を用いた。
5.4 主な実験結果
-
命令遵守率の低下
- IFEvalでは、CoTを適用すると全モデルで命令遵守率が低下
- ComplexBenchでも、CoTによる恩恵(一部手順整理や詳細説明)は見られたものの、多くのモデルで制約逸脱が増え、総合スコアは低下
-
Constraint Attentionの導入
- 「命令関連キーワードに向けるAttentionの総量」を定量化する指標を提案
- CoT適用時には命令トークンへの注意が減少しており、これが命令逸脱を引き起こす一因であることを数値的に示した
5.5 提案された緩和策(Mitigation Strategies)
-
In-context Learning(ICL)
- タスク例をプロンプトに並べ、命令を守るフォーマットを学ばせる手法。14 モデル中 4 モデルで +0.7〜+8.3 pp、他はごく小幅改善または悪化。論文中では「modest improvements」と評価
-
Self-reflection
- CoT出力の最後に「自分の回答は指示どおりか」を自己チェックさせる手法。IFEval で +2.2〜+16.6 pp、ただし小型モデルで悪化もあり。ComplexBench では半数以上で悪化
-
Self-selective Reasoning
- モデル自身に「今のタスクでCoTが必要か否か」を判定させ、不要と判断した場合は推論ステップをバイパス。IFEval で 10/14 モデルが改善(最大 +10.8 pp)、 ComplexBench では全モデル改善だが +0.3〜+10.8 pp 程度。論文中では「moderate gains」 と評価
-
Classifier-selective Reasoning
- Self-selectiveの代わりに専用分類器を訓練し、「CoT要否判定」の精度を高めるアプローチ。ほぼ全モデルで最良または同等の成績。改善幅は +0.2〜+11.1 pp 程度。「highly effective」と評価
5.6 結論と今後の展望
- CoTは「万能の性能向上策」ではなく、特に命令や制約を厳密に守るタスクでは逆効果を招くことがある。
- “Constraint Attention”のように、注意機構のシフトを定量化する評価軸を導入することで、CoT適用時の問題を早期に検出しやすくなる。
- 今後は、タスク特性に応じて推論ステップを選択的に切り替える仕組みや、CoT中でも命令関連トークンへのAttentionを維持するプロンプトデザインなど、「推論強化のメリットを維持しつつ命令逸脱を抑える」ための新たな手法開発が重要になる。
✅ 6. Learning to Reason without External Rewards
“外部報酬なしで推論を学習する”
[Submitted on 26 May 2025]
6.1 概要
この論文では、外部の正解データや検証器を一切用いずにモデル自身の内部信号(自己確信度)だけで強化学習を行う新たな枠組み「Reinforcement Learning from Internal Feedback(RLIF)」を提案しています。具体的には、Group Relative Policy Optimization(GRPO)の報酬信号を自己確信度スコアに置き換えた手法「INTUITOR」を導入し、完全に教師なしでの学習を実現しています。実験では、数学問題(MATH, GSM8K)においてRLVR(GRPO)と同等の性能を達成するとともに、コード生成タスク(LiveCodeBench, CRUXEval-O)への汎化性能で大幅な改善を示しました。これにより、検証可能な外部報酬が得られない領域でもスケーラブルに自己強化学習が可能であることを実証しています。
6.2 背景と課題意識
- 従来の強化学習(RL)手法(RLHF や RLVR)は、人手ラベルやドメイン固有の検証器(数学問題の正誤チェック、テストスイートなど)に強く依存していた。
- しかし、外部報酬が用意できないタスクや、専門知識で解答を構築できない領域では、これらの手法を適用しづらいという問題があった。
6.3 RLIF の提案
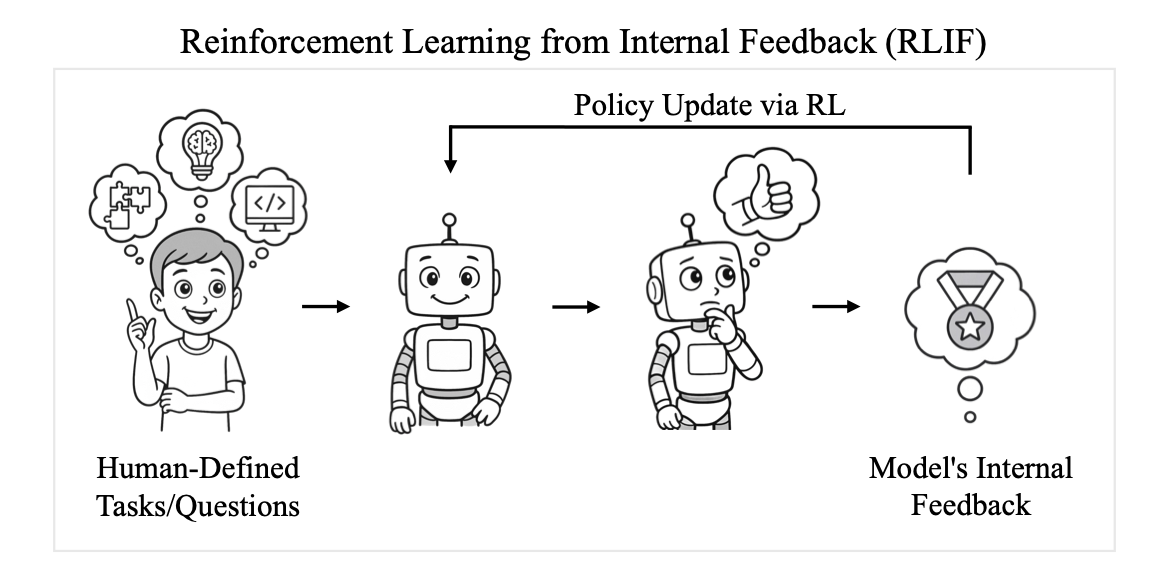
- 本論文では、外部報酬を一切用いず、「モデル自身が持つ内発的信号(自己確信度)」 を報酬として学習を行う新たな枠組み RLIF(Reinforcement Learning from Internal Feedback) を提案
- 自己確信度(Self-Certainty)は、モデルが回答時に出力するトークン分布と一様分布との KLダイバージェンスを平均し「どれだけ自信を持って次トークンを予測しているか」を数値化した指標
6.4 Intuitor:RLIF の具体的手法
- Intuitor は既存の GRPOアルゴリズムをベースに、外部報酬の代わりに 自己確信度(Self-Certainty)を相対的な報酬として用いる。これにより、自己確信度が上がるような回答生成を強化する。
- 学習ループの流れ:
- 同一プロンプトに対して複数の回答サンプルを生成
- 各サンプルの自己確信度を計算し、高いものほど「良い回答」としてランキング付け
- GRPO のランキング情報をもとに方策(Policy)を更新
6.5 実験と主な結果
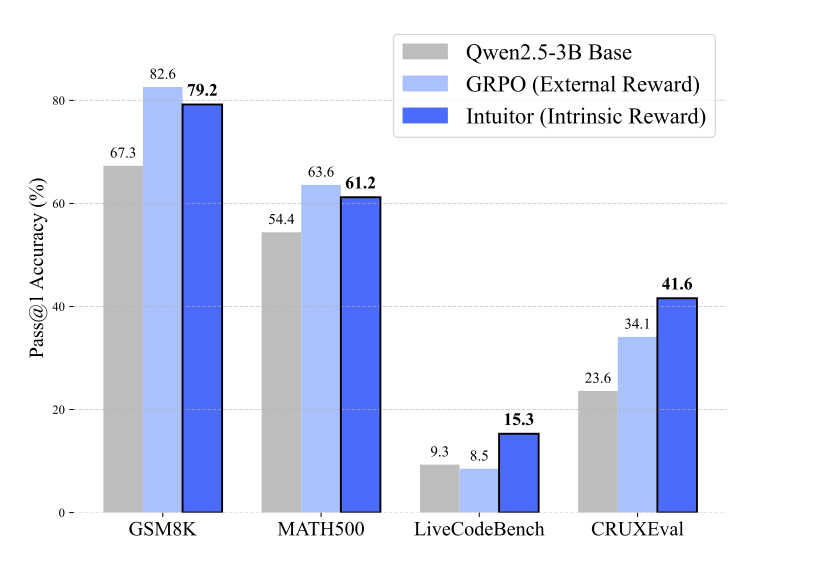
-
LiveCodeBench v6(コード生成)
INTUITOR(RLIF)適用により、Qwen2.5-3B でコード生成精度が +65% の相対改善(GRPO はほぼ横ばい) -
CRUXEval-O(コード生成)
INTUITOR は +76% の相対改善を達成し、GRPO の +44% を大きく上回った。 -
Qwen2.5-1.5B(小型モデル)
事前学習モデルではほぼ解答不能だったものが、INTUITOR チューニングにより 0% → 9.9% まで向上
6.6 意義と今後の課題
-
意義
- 専門家ラベルやテストケースが不要になるため、事前検証データの調達コストが大幅に低減。
- 医療や法務など「人間が正解を検証しづらい領域」においても、モデルが自律的に自己改善できる可能性を示唆。
-
課題
- Self-Certainty が高い=「正しい回答」とは限らず、モデルが誤った回答に過度に自信を持つリスクがある。
- 誤信を防ぐ仕組み(内発的信号の精緻化やほかの自己評価指標の併用)が今後の研究テーマ
- より大規模モデルへの適用検証や、Attention の一貫性など他の内発的指標との組み合わせも今後の重要課題
✅ 7. Spurious Rewards: Rethinking Training Signals in RLVR
“偽の報酬:RLVRにおける訓練信号の再考”
May 28, 2025
7.1 概要
この論文では、Qwen2.5-Math 系モデルに対して「正解と無関係な」フォーマット報酬やランダム報酬、さらには誤答報酬を与えても、MATH-500 や AMC ベンチマークで地上真値報酬に近い性能向上(最大約27%)が得られることを示しています 。しかし同様のスプリアス報酬は Llama3 や OLMo2 といった他モデルではほとんど効果を示さず、モデルによって事前学習時に獲得した推論パターンの有無が結果を左右することが分かりました 。詳細な解析からは、Qwen2.5-Math が「コードを用いた推論」を事前学習で既に身に付けており、RLVR がそのコード理論パターンを強化することで性能が向上していると考察しています。
7.2 研究の背景と目的
-
RLVR(Reinforcement Learning with Verifiable Rewards)とは
- 数学問題など「正誤が厳密に検証できるタスク」に対して、モデルの出力を検証可能な報酬信号として与えることで学習を行う手法
- これまでの常識としては、「正しい(ground-truth)報酬が不可欠」とされてきた。
-
スプリアス報酬(Spurious Rewards)の仮説
- ① あえて間違った報酬(誤答に報いる、ランダムな報酬)を与えても、RLVR は性能を向上できるのではないか?
- ② 報酬の種類によって向上幅は異なるが、いずれも有意な改善が得られるはず
-
検証対象モデルとベンチマーク
- 主モデル:Qwen2.5-Math (1.5B, 7B)
- 比較モデル:Llama3 系、OLMo2 系など
- 主ベンチマーク:MATH-500(数学問題集)、※ 副次ベンチマーク:AMC(中難度数学競技)、AIME(高難度数学競技)
7.3 報酬の種類(Spurious Rewards の定義)
本研究では、以下の4種類の報酬形状を用いて RLVR を行い、それぞれの性能変化を比較した。
-
Ground-Truth 報酬
- 正答した場合にのみ報酬を与える「従来型」の報酬設計
-
多数決報酬(Majority Vote Reward)
- モデル自身があらかじめ 64 回ロールアウトして得た「最頻回答」を擬似ラベルにし,
そのラベルと一致した応答にだけ 1 を与える弱い報酬信号
- モデル自身があらかじめ 64 回ロールアウトして得た「最頻回答」を擬似ラベルにし,
-
フォーマット報酬(Format Reward)
- 解答を
\\boxed{…}の形で囲んだ「見た目のフォーマット」にだけ報酬を与え、正誤とは無関係とする。
- 解答を
-
誤答報酬(Incorrect Reward)
- 実際に誤答しているケースにのみ報酬を与え、正答には報酬を与えない。
-
ランダム報酬(Random Reward)
- モデルの出力に対してランダムに(0/1)報酬を付与し、正誤や形式には一切関係なく報酬を与える。
7.4 ベンチマーク別・報酬形状ごとの精度比較
1. 各モデルのMATH-500 における結果
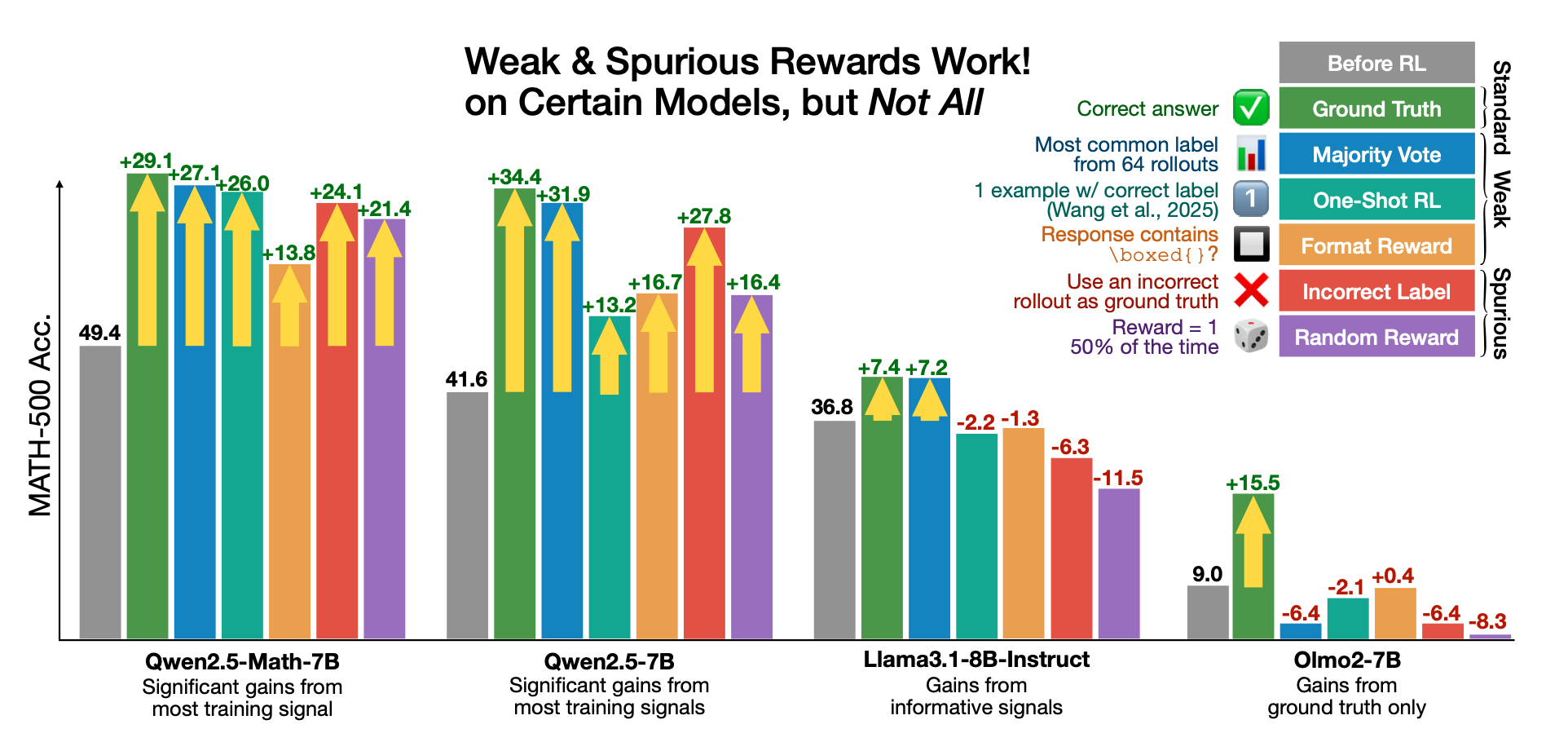
※ 上記の One-Shot RLは 1. Reinforcement Learning for Reasoning in Large Language Models with One Training Exampleのことを指しています
Qwen2.5-Math系
- 正しい報酬(Ground-Truth)が最も高い伸びを示すものの、誤答報酬 やランダム報酬 でも同程度の精度向上を示す。
- スプリアス報酬でも十分な性能向上が観測されたと言える。
- フォーマット報酬はやや抑えめだが、「数式を特定の形式で出力する」というシンプルな報酬だけでも学習効果があることを示す。
Llama3.1 / OLMo2 (汎用モデル)
- Qwen2.5-Math 系と比べて、汎用モデルではスプリアス報酬の場合はほとんどが精度低下
- これは「数学特化で事前学習された内部埋め込み」があるかどうかで、スプリアス報酬の効果が左右されるためと考えられる。
2. AMC・AIMEにおける結果(Appendixに記載)
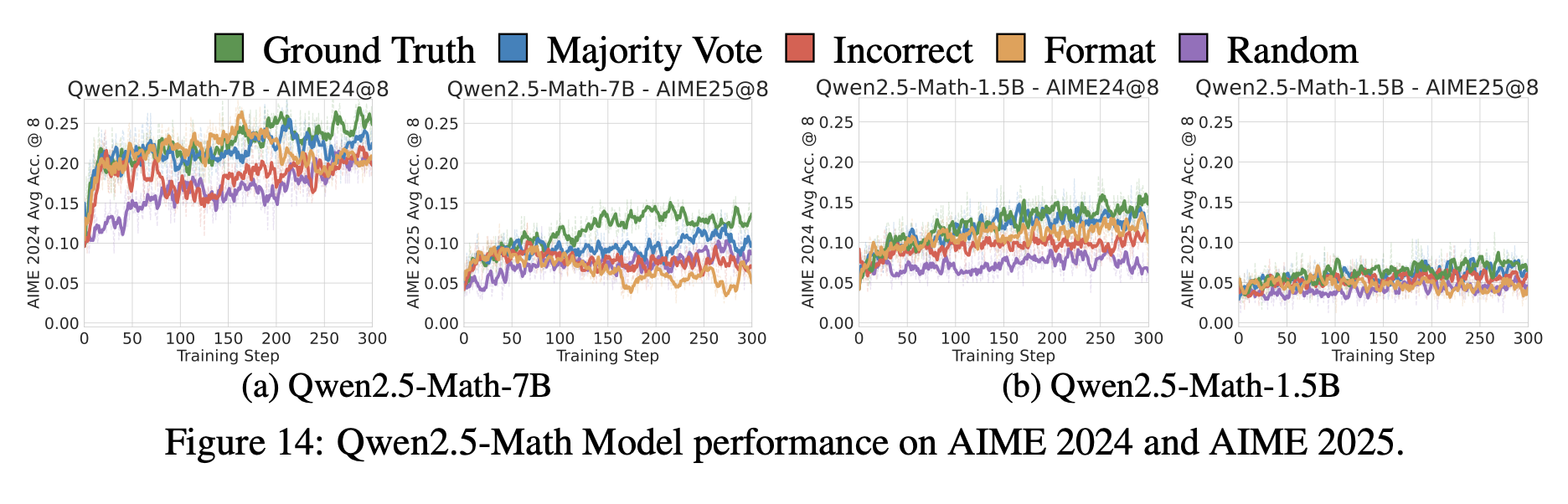
- AMC・AIMEベンチマークのいずれも avg@8 指標で結果を報告している。(上記グラフはAIME2024,2025)
- Qwen2.5-Mathではフォーマット・誤答・ランダムといったスプリアス報酬でも AMC@8 と AIME24@8 を向上させる一方、より OOD な AIME25 では効果が減少した。
- Llama3 や OLMo など他系列モデルは AMC/AIME での改善は同様に小さい。
7.5 なぜスプリアス報酬でも性能が向上するのか
-
探索性の向上(Exploration)
- 正答報酬だけだと「局所的に正解を追いかける」学習になりやすいが、誤答やランダム報酬を与えることで「多様な推論経路」を試し、結果として有用なルーチンを発見しやすくなる。
-
事前学習済みの内部埋め込み活用
- Qwen2.5-Math 系のように、もともと数学知識を多く含む事前学習モデルは、「誤った報酬をもらっても内部に備わった数学構造を活かして正解を生成する能力」を持つ。
-
報酬バイアスの緩和
- 正答報酬のみでは「正解以外は0」という極端なバイアスがかかるが、ランダム報酬や誤答報酬を混ぜることでモデルが“正誤にこだわりすぎない状態”となり、安定した学習が可能になる。
7.6 結論と今後の課題
結論
- 数学特化モデル(Qwen2.5-Math)の RLVR において、誤答報酬やランダム報酬を与えても、数学ベンチマーク(MATH-500)で二桁台の性能向上が得られた。
- ただし、汎用モデル(Llama3, OLMo2)ではスプリアス報酬の効果が小さいため、「事前学習時点で数学的知識をどれだけ埋め込んでいるか」が、スプリアス報酬の有効性を左右する重要要素であると考えられる。
今後の課題
-
他タスク・他ドメインへの拡張
- プログラミング問題や常識推論タスクなど、検証可能な報酬が得にくい領域でも同様の現象が起きるかを検証する必要がある。
-
報酬形状の自動最適化
- 固定的なスプリアス報酬ではなく、動的に報酬を設計・切り替えるためのメタ学習的アプローチの開発。
-
探索性と収束性のバランス解析
- 誤った報酬が過度な探索を誘発し、最適解への収束を妨げるリスクを抑えつつ、いかに高性能を実現するか。
-
モデル依存性のメカニズム解明
- なぜ数学特化モデルでは効果が大きく、汎用モデルでは小さいのか。内部埋め込みやAttention の振る舞い分析を行い、科学的に解明する必要がある。
✅ 8. The Climb Carves Wisdom Deeper Than the Summit: On the Noisy Rewards in Learning to Reason
“頂上ではなく登る過程が知恵を深める:推論学習におけるノイズの多い報酬について”
[Submitted on 28 May 2025]
8.1 概要
この論文では、まず数学問題を対象に強化学習の報酬を意図的に最大40%ノイズ(正誤を反転)させても、Qwen-2.5-7Bモデルが未検証のままでも高速に収束し、正確報酬時の75%に迫る72%の精度を達成する驚くべき頑健性を示しています。さらに、“First, I need to…”などのキーフレーズ出現のみを報酬とするReasoning Pattern Reward(RPR)のみで学習しても、同程度(約70%)の性能向上が得られることから、LLMには事前学習で獲得された推論能力が埋め込まれていることを示唆しています。最後に、RPRを既存のノイズ報酬モデルに組み合わせることで、オープンエンドな質問応答タスクでも最大30%の性能向上を達成し、小規模モデルでも強い推論能力を引き出せることを明らかにしています
8.2 研究の背景と目的
- 従来のLLM向け強化学習(RL)は、数学問題など“正解・不正解が明確”なタスクを想定しており、報酬モデルにノイズがほとんどない前提で設計されてきた。
- 実際の応用では報酬モデルが必ずしも正確ではなく、誤った報酬(False Positive/False Negative)が与えられる「ノイズ報酬」環境が想定される。
- 本研究では、意図的に報酬を逆転させる(正答なのに報酬0、誤答なのに報酬1)ような高いノイズ環境下でも、LLMはどれだけ推論性能を向上できるかを検証することを目的とした。
8.3 数学タスクでのノイズ報酬実験
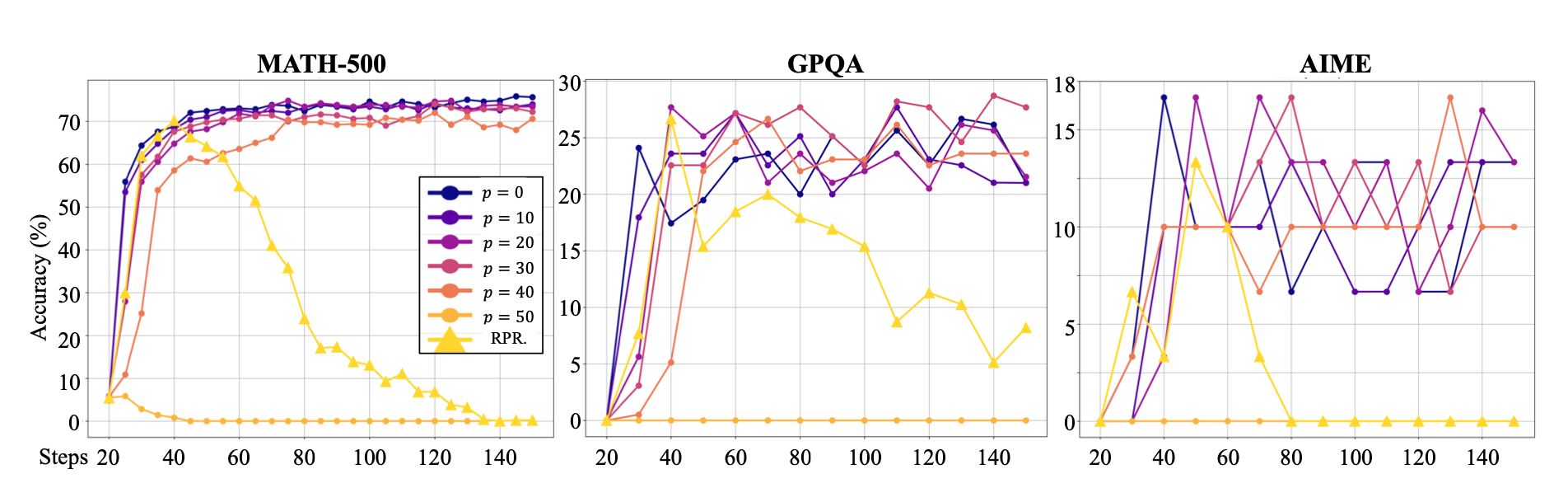
-
実験モデル・データセット
- Qwen-2.5-7Bを主軸に、MATH-500、GPQA、AIME 2024などで評価。訓練はPPO+GAEを用いる。
-
ノイズ報酬の設定
- タスク単位で報酬を逆転させる割合 $p%$ を $p = 0, 10, 20, 30, 40, 50%$ と変化させて学習を実施。
-
結果
- $p=0%$(ノイズなし)で約75.9%まで精度が向上。
- $p=40%$(報酬の4割を逆転)でも最終的に約72.0%まで精度が改善し、ノイズなしとの差はわずか約3.8ポイントにとどまった。
- $p=50%$(報酬がほぼランダム)では学習が崩壊し、性能向上はほぼ見られなかった。
-
考察
- 高いノイズ環境でも学習が成立する背景には、LLMが事前学習で既に持つ「推論パターン」を強化しているからと考えられる。
- 報酬が逆転しているケースでも、「We know that…」「First, I need to…」などの段階的な思考フレーズが出力され、それが最終的に正答に至るためのシグナルとなっている。
8.4 Reasoning Pattern Reward(RPR)の提案と成果
-
RPRの概要
- 出力文の「重要な推論フレーズ(例:First, I need to、We know that など)」の出現頻度のみを報酬として与え、正誤判定は一切行わない手法。
-
具体的な実装
- 事前に40個の典型的な推論フレーズをリスト化し、各フレーズの出現に対して0.025点ずつ報酬を付与。報酬の上限は1点にクリップ。
- 同一フレーズの過剰出現を防ぐための「繰り返しペナルティ」を導入。
-
実験結果
- Qwen-2.5-7BをRPRだけで学習した場合でも、MATH-500でピーク約70.2%の精度を達成。ノイズなしやノイズありPPOと同水準の成果を示した。
- 事前学習済みLLMの強固な推論能力を「出力パターンの最適化」によって引き出すことができることを示唆。
8.5 オープンエンドタスク(HelpSteer)への応用
-
実験設定
- オープンエンドな質疑応答タスクHelpSteerを使用。あえて報酬モデルの学習データを減らし、報酬モデル精度を約75%に劣化させた上で比較実験。
-
比較手法
- Vanilla RL(正解判定による報酬モデル、精度80~85%)
- Noisy RL(報酬モデル精度75%のままRLを適用)
- RPRキャリブレーション(報酬モデル75%+RPR付加)
-
結果
- 75%精度の報酬モデルのみではノイズが多すぎて学習が不安定化し、モデルによっては学習崩壊
- RPRキャリブレーションを併用した場合、純増率(Net Win Rate)で最大約30%の改善を達成。小型モデル(3Bクラス)でも安定して5 pt 程度のWin Rateを獲得し、実用レベルの性能を確保できた。
-
考察
- 報酬モデルがFalse Negative を出しても、「正しい推論パターン」に対してはRPRが報酬を与えるため、学習が継続できる。
- 報酬モデルの精度がある程度低下しても、RPRを追加するだけで実用域の性能を維持できる可能性が示された。
8.6 主要な知見と今後の展望
-
事前学習済みモデルの推論能力の重要性
- LLMは事前学習段階で十分な推論基盤を獲得しており、RLフェーズでは「推論プロンプトパターンの引き出し・最適化」が主な役割になる。
- 事前学習で推論能力が弱いモデル(例:Llama-3.1-8B)では、ノイズ報酬環境での学習はほとんど機能しない。
-
RPRの実用性
- 単純な「キーワードベースの報酬付与」方式にもかかわらず、小型モデルでも安定した学習を実現し、実装コストも低い。
- 主観的評価や顧客フィードバックなど、正誤判定が難しいタスクでも、まずは推論フレーズを強化することで報酬モデルをキャリブレーションできる。
-
今後の課題
- より複雑な自然言語推論・対話タスクへの応用に向けて、「構文構造に基づく推論プロセス評価」など、キーワードマッチングにとどまらない手法の検討
- 自己教師あり学習とRPRの組み合わせによる、事前学習段階からの推論パターン学習の強化
- 報酬モデルそのものに「推論過程の理路整然度」などを自動評価させる仕組みを構築し、汎用的なノイズ耐性をさらに高める。
✅ 9. ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models
“ProRL:長期強化学習が大規模言語モデルの推論の限界を広げる”
[Submitted on 30 May 2025]
9.1 概要
本論文では、長期間にわたる強化学習(Prolonged RL, ProRL)を用いて,大規模言語モデルの推論能力の境界を拡張できることを示しています。具体的には、KLダイバージェンス制御や参照ポリシーのリセット、多様なタスク群を組み合わせた新たな訓練手法を導入し,ベースモデルでは完全に解けない問題に対しても高い正解率を達成しています。また,ProRLによって得られる性能向上は,ベースモデルの初期性能が低いタスクほど顕著であり,訓練時間の延長に伴い新奇な推論パターンが生成されることを「創造性指標」の上昇から裏付けています。これらの結果は,十分な計算資源と適切な手法があれば,追加データなしにモデルの推論境界を拡張できることを示唆しています。
9.2 目的・背景
- 従来の強化学習(RL)では、短期間の訓練でモデル内にすでに存在する高報酬候補を強調するだけにとどまりがちであり、本当に新しい推論戦略を獲得できるかは不明確だった。関連:Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
- 本研究では「長期的に安定したRL訓練」を行うことで、モデルが基礎モデル(base model)には持っていない新たな思考パターンを発見できるかを検証した。
9.3 ProRL の核となる仕組み
-
KLダイバージェンス制御
- 現在のポリシーとリファレンスポリシー(直近のモデル状態)との乖離を抑制することで、訓練途中での急激な変動を防ぎ、安定した最適化を実現。
-
リファレンスポリシーのリセット
- 一定ステップごとにリファレンスポリシーをモデルの最新パラメータで更新し、「KL制御で過去に固執しすぎない」ように工夫。
-
多様なタスク群の併用
- 数理論理問題やプログラミングタスクなど複数ドメインの問題を組み合わせ、特定タスクへの過剰適合を避けつつ新しい推論パターンを探索。
9.4 報酬設計の工夫
-
タスク適性に応じた報酬調整
- 基礎モデルが苦手とするタスクほどボーナス報酬を大きくし、難易度の高い問題に挑戦するよう促す。
-
中間思考段階への部分報酬
- 長いChain-of-Thought(CoT)で途中経路が妥当なら部分報酬を与え、モデルが考えの途中を疎かにしないように誘導。
9.5 実験結果
-
1. pass@k の大幅改善
ProRL 訓練済みモデルは基礎モデルに比べ、ほぼすべてのタスクで pass@1 や pass@5、pass@10 が平均15~30%ほど向上。

-
2. 新規推論戦略の獲得
- 基礎モデルではいくらサンプリングしても正解を得られなかった難問に、ProRL モデルは低い確率ながらも正答できるケースを多数確認。
- 基礎モデルではいくらサンプリングしても正解を得られなかった難問に、ProRL モデルは低い確率ながらも正答できるケースを多数確認。
-
3. 創造性指標の上昇
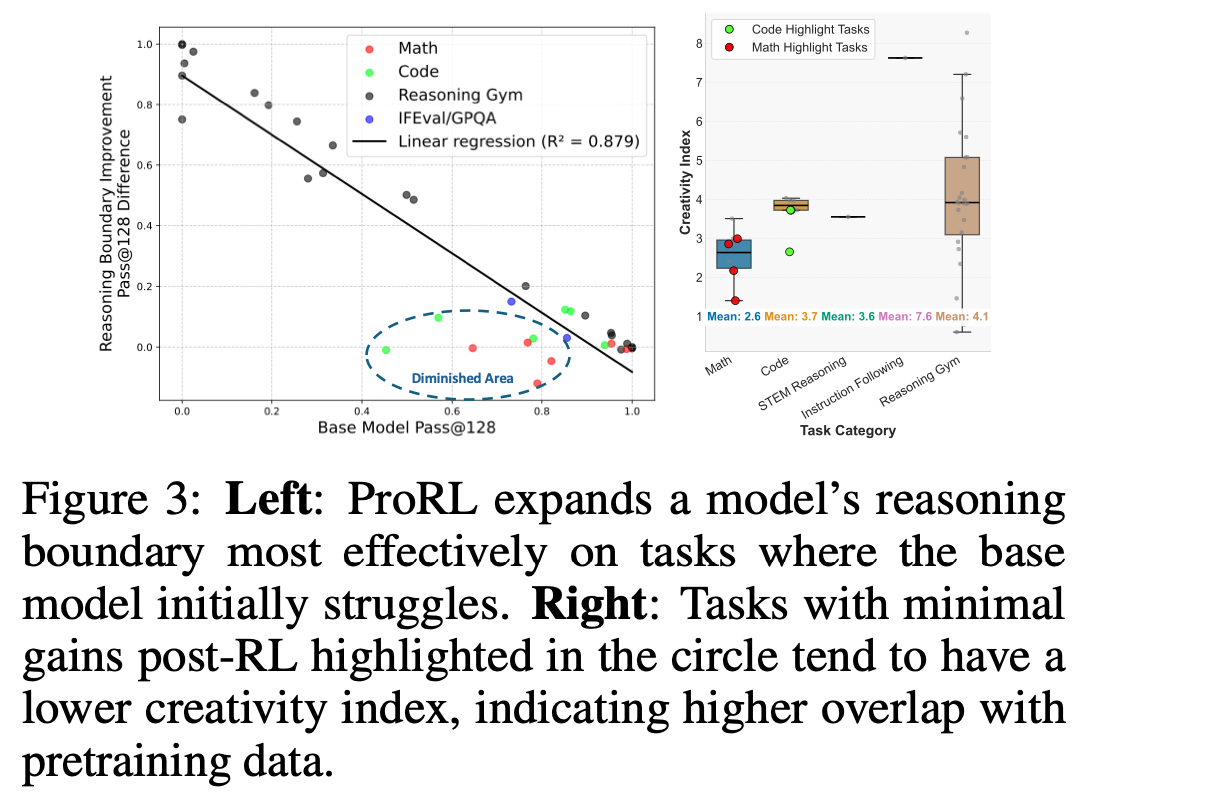
- 生成した思考経路のコーパス重複度が低く、既存パターンを組み合わせただけではない「未知の」推論が発見されている。(Figure1)
-
4. 訓練期間との相関
- 基礎モデルが苦手なタスクほど、訓練ステップ数を増やすほど pass@1 が顕著に向上。特に、基礎モデルの pass@1=0 の問題でも、訓練を重ねると 10%以上の成功率を示す事例あり。
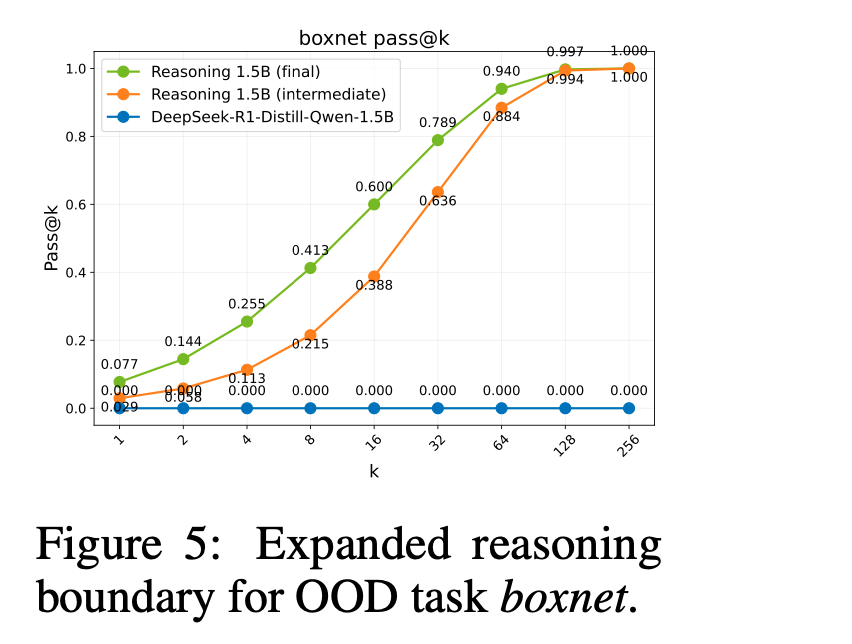
- 基礎モデルが苦手なタスクほど、訓練ステップ数を増やすほど pass@1 が顕著に向上。特に、基礎モデルの pass@1=0 の問題でも、訓練を重ねると 10%以上の成功率を示す事例あり。
-
5. 分布シフトの可視化
- 代表的タスクで pass@1 確率のヒストグラムが明確に右へシフトし、「単なる分布の尾の強化ではない」新規確率塊が生成されていることを示唆。
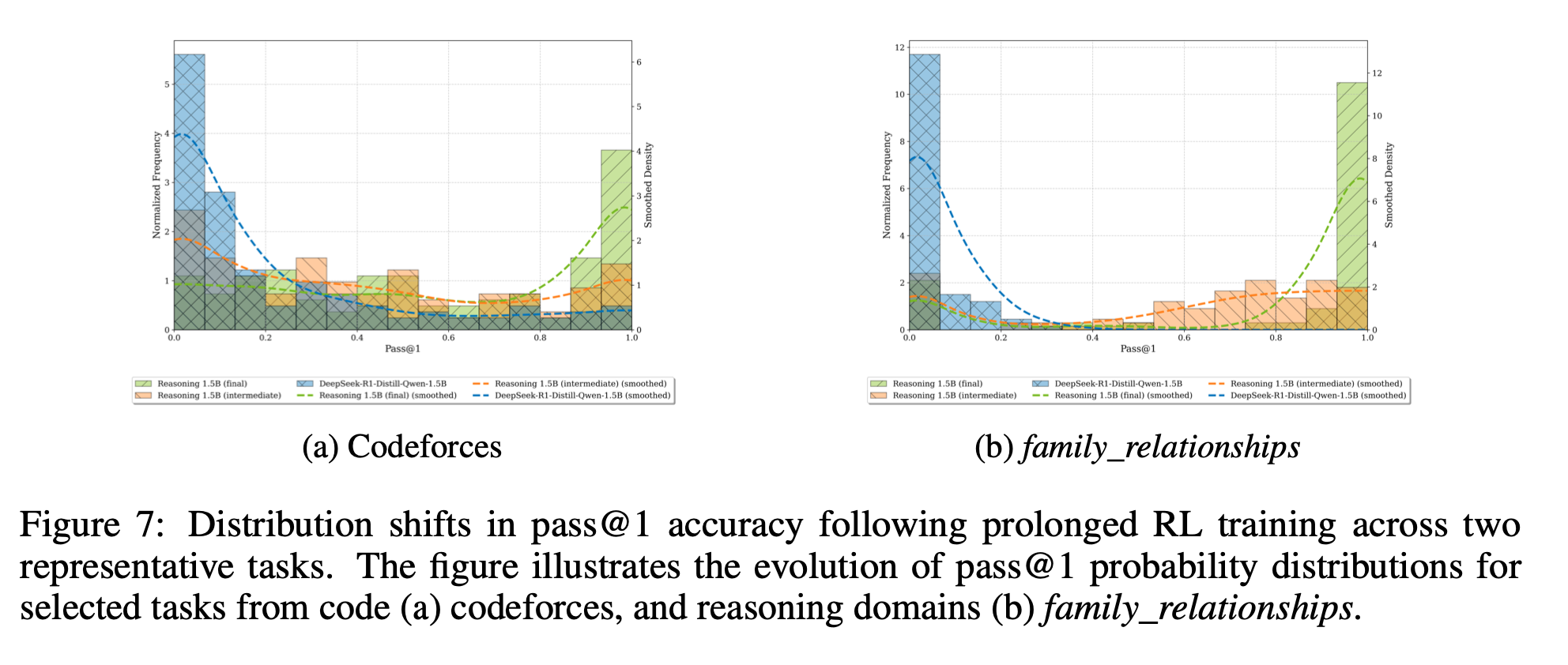
- 代表的タスクで pass@1 確率のヒストグラムが明確に右へシフトし、「単なる分布の尾の強化ではない」新規確率塊が生成されていることを示唆。
9.6 意義・示唆
- 本研究は「RL は基礎モデルにすでにある高報酬候補を強調するだけではなく、長期間の訓練を通じて本質的に新しい推論戦略を開拓しうる」ことを実証
- KL制御やリファレンスポリシーリセットによって、数千~数万ステップ規模の長期RLを安定化できる技術的基盤を構築
- 数理論理→家族関係推論→コーディングタスクなど、異なるドメインを横断して学んだ知見が相互に補完され、汎用的な推論能力の向上に寄与する傾向を確認
9.7 結論
- ProRL による長期的RL訓練は、基礎モデルにない全く新しい解法パターンを発見できる。
- 訓練期間(horizon)のスケーリングが性能向上に直結し、RL 訓練を時間をかけて継続することの有用性を示した。
- 多様なタスク群を組み合わせることで、特定タスクを超えたドメイン横断的な推論能力も得られる。