この記事はNTTComアドベントカレンダー12日目の記事となります。
初めまして,kirikeiと申します。普段はNTT Communicationsでデータ分析ツールのスクラム開発や,機械学習モデルの説明性(いわゆるXAIの分野)や因果推論に関する研究をしています。あとは趣味でAWSやAzure,GCPなどの機械学習サービスを検証していて,こんな記事やこんな記事も書いています。
今回はその例に漏れず,現在開催中のAWS最大のイベントre:Inventで,先日(この記事を書く4日前?)発表のあったモデルの説明性やデータのバイアスを計算できるSageMakerの新機能であるAmazon SageMaker Clarifyを早速検証・紹介させて頂きます。(タイムリー!)
Amazon SageMakerとは?
Amazon SageMakerとは,AWSで提供されている機械学習エンジニアのための機械学習モデルの学習や実験管理,モデルの管理,モデルのデプロイを効率的に行うためのプラットフォームです。機械学習エンジニアが悩みがちなインフラ周りの雑務を一手に引き受けてくれる素敵なサービスです。
SageMakerには複数のインターフェースが存在し,モデル選択して簡単に学習してくれるGUIと,機械学習エンジニアが最もよく使っているであろうJupyterLabやJupyter NotebookからSDKを叩いて学習を行うインターフェースが用意されています。
また,昨年からJupyterLabのインターフェースをさらにパワーアップさせ,Jupyter-Likeなインターフェースから実験管理やモデルの管理まで行える統合環境のSageMaker Studioも利用可能になっています。
SageMaker全体に関して,詳しくはAmazon Web Service Japanのスライドを,SageMaker Studioについてはわかりやすく書かれたQiita記事があるのでそちらを参照下さい。
- SageMaker Studioのインターフェースはこんな感じ。ここからSDKを叩いて(例えば
XX.fitとかXX.deployとかを実行すると指定したリソースの学習コンテナが立ち上がって学習が行われ,モデルがデプロイされてエンドポイントを作成できたりします)

Amazon SageMaker Clarifyとは?
Amazon SageMaker Clarifyとは,冒頭でも述べた2020年のre:Inventにて発表されたSageMakerの新しい機能のことで,機械学習モデルの実用化において重要となる機械学習モデルの説明性や,モデルやデータのバイアスを評価できるところが特徴です。
機械学習モデルの説明を行うクラウドサービスとしてはGCPのExplainable AIや,Azureのazureml.interpretが先行していましたが,AWSからも今回リリースされることとなり,それぞれクラウド3社が説明性に関する機能をそれぞれの機械学習サービスに携えたことになります。それだけ注目されている分野だということがわかります。
機械学習モデルの説明性とは?
ニューラルネットワークをはじめとするパラメータ数が多く非線形なモデルは,どの入力が出力に寄与しているかを把握するのが困難であり,産業などで利用する際のモデルの信頼性に問題を抱えています。その中で研究されているのが機械学習モデルの説明性に関する研究であり,Explainable AI,通称XAIとも呼ばれます。今回は中身までは触れませんが,Qiita内に素晴らしい記事もあるので,興味のある方は参照下さい。
Clarifyでは説明性の手法の中でスタンダードになりつつあるSHAPを利用して各特徴が出力に対してどれくらい寄与しているのかを数値化,可視化しています。この手法はニューラルネットワークやGBTを含むどのようなモデルにも利用できるという利点があります。
バイアスとは?
機械学習モデルのバイアスと聞くと機械学習を生業にしている方はバイアスとバリアンスを思い浮かべるかもしれませんが,SageMaker Clarifyの文脈では一般的な用語としてのバイアスのことを示します。例えば特徴量に男女のラベルがあった時に,本来は男女に差が出ないデータにもかかわらずデータ中の男女の数のインバランスによって結果に影響してしまうようなことを言います(研究的にはfairnessが近いと思われます。)
Clarifyではデータのバイアス(pretrain-bias)とモデルのバイアス(posttrain-bias)を評価することができます。前者は目的変数に対してある特徴がどれくらいセンシティブか,具体的には目的変数をバイナリのラベル(または閾値)で分けた分布と興味のある特徴をバイナリ(または閾値)で分けたときのデータ分布がどの程度離れているかを数値化します。
Kaggleのデータで試してみた
SageMaker ClarifyのサンプルコードはGithubで公開されていますが,これをそのままやるのは面白くないので,今回は別のデータとしてKaggleのHouse Pricesを用います。
このデータは,家に関する様々な属性(家のクオリティや築年数,売り方,場所,etc...)の情報から家の値段がいくらになるかを予測するデータです。
下準備としてSageMakerにアクセスしてノートブックインスタンスを立ち上げておき,Kaggleのページからtrain.csv,test.csvをダウンロードしてJupyterLabにアップロードしておきます。以下のコードはSageMaker上のJupyterLabまたはSageMaker Studioで実行します。
データ可視化からモデルの学習まで
まず,利用するパッケージやデータを格納するS3のバケットや実行リージョンを定義しておきます。今回はs3バケットにhouse-price-sagemaker-clarifyという名前をつけておきます。
from sagemaker import Session
session = Session()
bucket = session.default_bucket()
prefix = 'sagemaker/house-price-sagemaker-clarify'
region = session.boto_region_name
# Define IAM role
from sagemaker import get_execution_role
import pandas as pd
import numpy as np
import urllib
import os
from sklearn.model_selection import train_test_split
role = get_execution_role()
データの中身を確認します。
train_df = pd.read_csv('train.csv', index_col=0)
test_df = pd.read_csv('test.csv', index_col=0)
train_df.head()

見ての通り,今回のデータはテキストのカテゴリカルデータが多いので,最低限の前処理としてバイナリに変更しておきます。
all_df = pd.get_dummies(pd.concat([train_df, test_df], axis=0))
train_df = all_df.iloc[:train_df.shape[0], :]
test_df = all_df.iloc[train_df.shape[0]:, :]
ここからはSageMakerを利用して学習まで一気に実行します。SageMakerで学習を行う場合は一旦学習データをファイルとしてS3にアップロードし,そのデータのURIを学習時に指定することで学習データを取ってきて学習を行います。詳しくはこちらの記事に詳しく書かれています。
# カラムの入れ替え。SageMakerは先頭カラムをTargetとして認識する
def to_csv(df, filename, is_train=True):
if is_train:
df = pd.concat([df[target_column], df.drop(target_column, axis=1)], axis=1)
else:
df = df.drop(target_column, axis=1)
df.to_csv(filename, index=None, header=None) # indexとheaderは不要
return df
train_df = to_csv(train_df, 'train_data.csv')
test_df = to_csv(test_df, 'test_data.csv', is_train=False)
# S3にアップロードするためファイルとして吐き出しておく
train_df = to_csv(train_df, 'train_data.csv')
test_df = to_csv(test_df, 'test_data.csv', is_train=False)
# s3へのアップロード
from sagemaker.s3 import S3Uploader
from sagemaker.inputs import TrainingInput
train_uri = S3Uploader.upload('train_data.csv', 's3://{}/{}'.format(bucket, prefix))
train_input = TrainingInput(train_uri, content_type='csv')
test_uri = S3Uploader.upload('test_data.csv', 's3://{}/{}'.format(bucket, prefix))
# XGBoostによる学習
# SageMaker SDKのEstimatorクラスを利用する。XGBのwrapperとなっている
from sagemaker.image_uris import retrieve
from sagemaker.estimator import Estimator
# 学習
container = retrieve('xgboost', region, version='1.2-1') # XGBが使えるコンテナイメージの指定
# モデルの定義
xgb = Estimator(container,
role,
instance_count=1,
instance_type='ml.m4.xlarge', # 学習インスタンス(今回はもりもり)
disable_profiler=True,
sagemaker_session=session)
xgb.set_hyperparameters(max_depth=5,
eta=0.2,
gamma=4,
min_child_weight=6,
subsample=0.8,
objective='reg:squarederror', # 回帰問題
num_round=800)
# 学習開始,URIからデータを取得し,指定したインスタンスで学習する
# 学習ログはCloudWatchに自動的に吐き出される
# 学習が終わるとインスタンスが勝手に落ちる
xgb.fit({'train': train_input}, logs='None', wait='True')
# モデルの登録
from sagemaker.serializers import CSVSerializer
from sagemaker.deserializers import CSVDeserializer
# モデルに名前をつけてモデル管理リポジトリに登録する
model_name = 'house-price-clarify-model'
model = xgb.create_model(name=model_name)
container_def = model.prepare_container_def()
session.create_model(model_name,
role,
container_def)
Clarifyの利用
ここからいよいよClarifyの利用です。ClarifyはSDKの中の1ライブラリとして用意されており,基本的にコンフィグを定義した後のrun_biasとrun_explainabilityでバイアスの数値化と説明の可視化をそれぞれHTMLやPDFのレポートにして(!)S3に出力してくれます。
また,最大のメリットはSageMaker最大の武器であるインフラを気にしなくて良いことこれに尽きます。説明やバイアスの計算も学習まではいかないものの計算時間がかかったりGPUを利用する必要があったりと,インフラと密接に関わっています。Clarifyではこの説明やバイアスの計算も学習と同じように,説明の計算プロセスをユーザが決めたリソースでコンテナに切り出して実行しているため,このSageMakerの思想がフルに生かされています。
バイアスの数値化
バイアスの数値化は先に述べたようにデータに対するバイアスとモデルに対するバイアスを計算しています。基本的にはある興味のある特徴に対して,目的変数がどのくらい敏感なのかを計算しています。具体的には,例えばバイナリな特徴(0or1)と目的変数(0or1)があった時,特徴が0だった時の目的変数が1,0の時のそれぞれの分布と,特徴が1だった時の目的変数が1,0の時のそれぞれの分布がどの程度異なるか(例えばKL Divergence)をバイアスとして評価しています。直感的にはこの分布が異なれば異なるほど特徴によって目的変数が変動していることがわかります。詳しくはこちらの公式ドキュメントに詳しく書かれています。
モデルのバイアスは上記の計算を目的変数ではなく予測値で行っているようです。元々の目的変数のバイアスと予測値のバイアスがどのように異なるかを比較することでモデルのバイアスが確認できるようです。こちらも詳しくは公式ドキュメントを参照して下さい。
今回扱うデータは目的変数が価格=連続値であるため,価格の上位80%を閾値に設定して,バイアスを測る説明変数はSalesCondition_Abnormal(通常の販売方法ではなく差し押さえやトレード,空売り)を選択しました。すなわち通常の販売方法でない場合に目的変数に違いがあるか,またはモデルの予測値に違いがあるかを見ていることになります。
実行コードは以下となります。
from sagemaker import clarify
# clarifyを利用するインスタンスの設定
clarify_processor = clarify.SageMakerClarifyProcessor(role=role,
instance_count=1,
instance_type='ml.c4.xlarge',
sagemaker_session=session)
# レポートの出力先
bias_report_output_path = 's3://{}/{}/clarify-bias'.format(bucket, prefix)
# データの設定
bias_data_config = clarify.DataConfig(s3_data_input_path=train_uri,
s3_output_path=bias_report_output_path,
label=target_column, # targetとなるカラム
headers=train_df.columns.to_list(), # カラム名
dataset_type='text/csv')
# 対象となるモデルの設定
# 今回はXGBoost
model_config = clarify.ModelConfig(model_name=model_name,
instance_type='ml.c5.xlarge',
instance_count=1,
accept_type='text/csv')
predictions_config = clarify.ModelPredictedLabelConfig()
# 目的変数の閾値とラベルの設定
bias_config = clarify.BiasConfig(label_values_or_threshold=[train_df[target_column].quantile(q=0.8)],
facet_name='SaleCondition_Abnorml',
facet_values_or_threshold=[0]) # 興味のある特徴の値
# pre-biasとpost-biasを一緒に実行
# biasの測り方は一旦全てのメソッドを利用する
clarify_processor.run_bias(data_config=bias_data_config,
bias_config=bias_config,
model_config=model_config,
model_predicted_label_config=predictions_config,
pre_training_methods='all',
post_training_methods='all')
実行するとS3のバケット内にreport.pdfというファイルが現れ,中身には以下のような結果が表示されます。
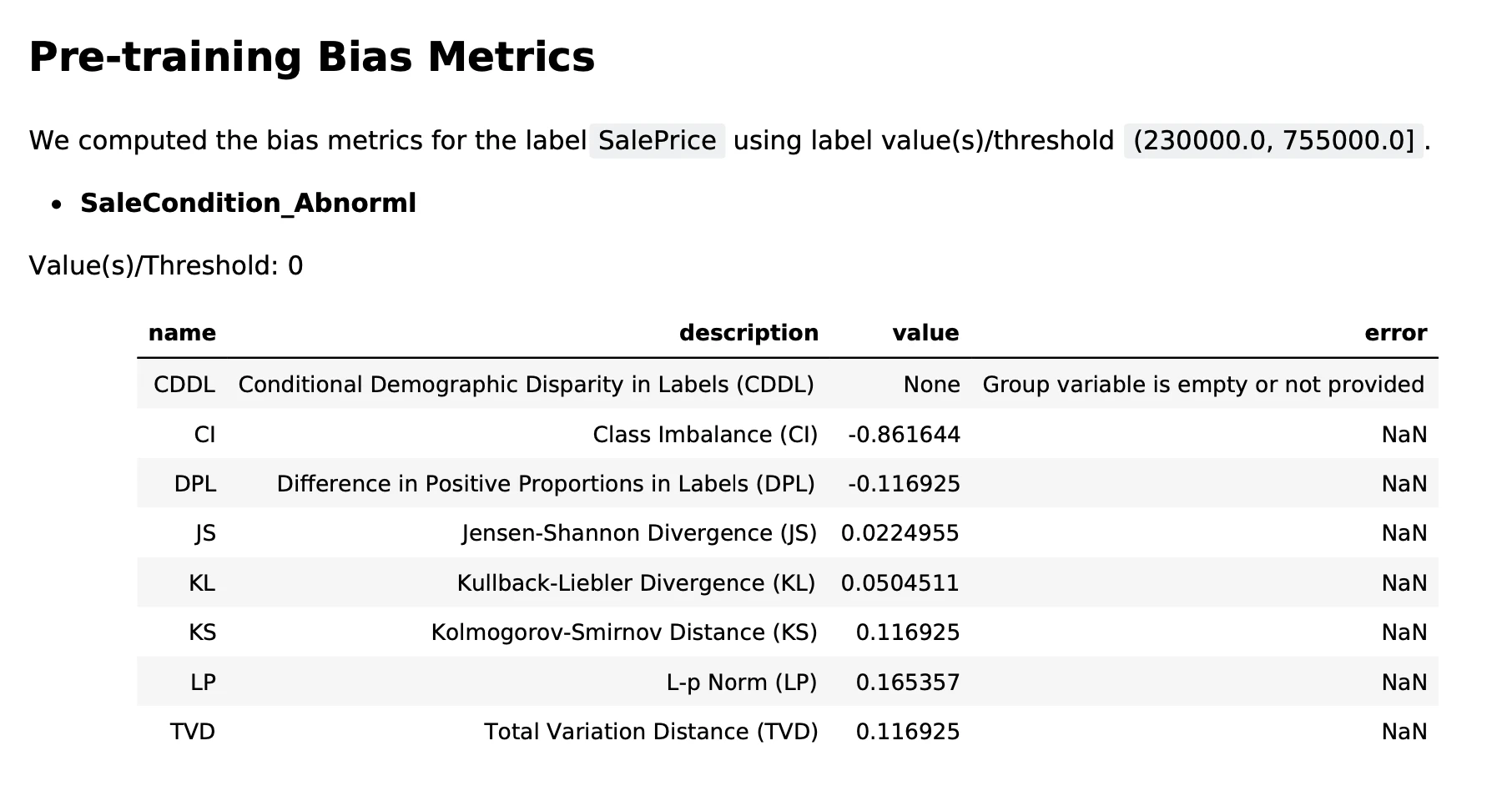
データのバイアスに関して,クラスはかなりインバランスになっているので,ラベルの数にかなり偏りはあるようです。ただし,その他の尺度はそれほど大きくない(基本的に距離の尺度なので0に近いほど分布が近い)ため,クラスに偏りはあるものの分布は似ているため,この特徴はそれほど大きな影響がないのかもしれません。
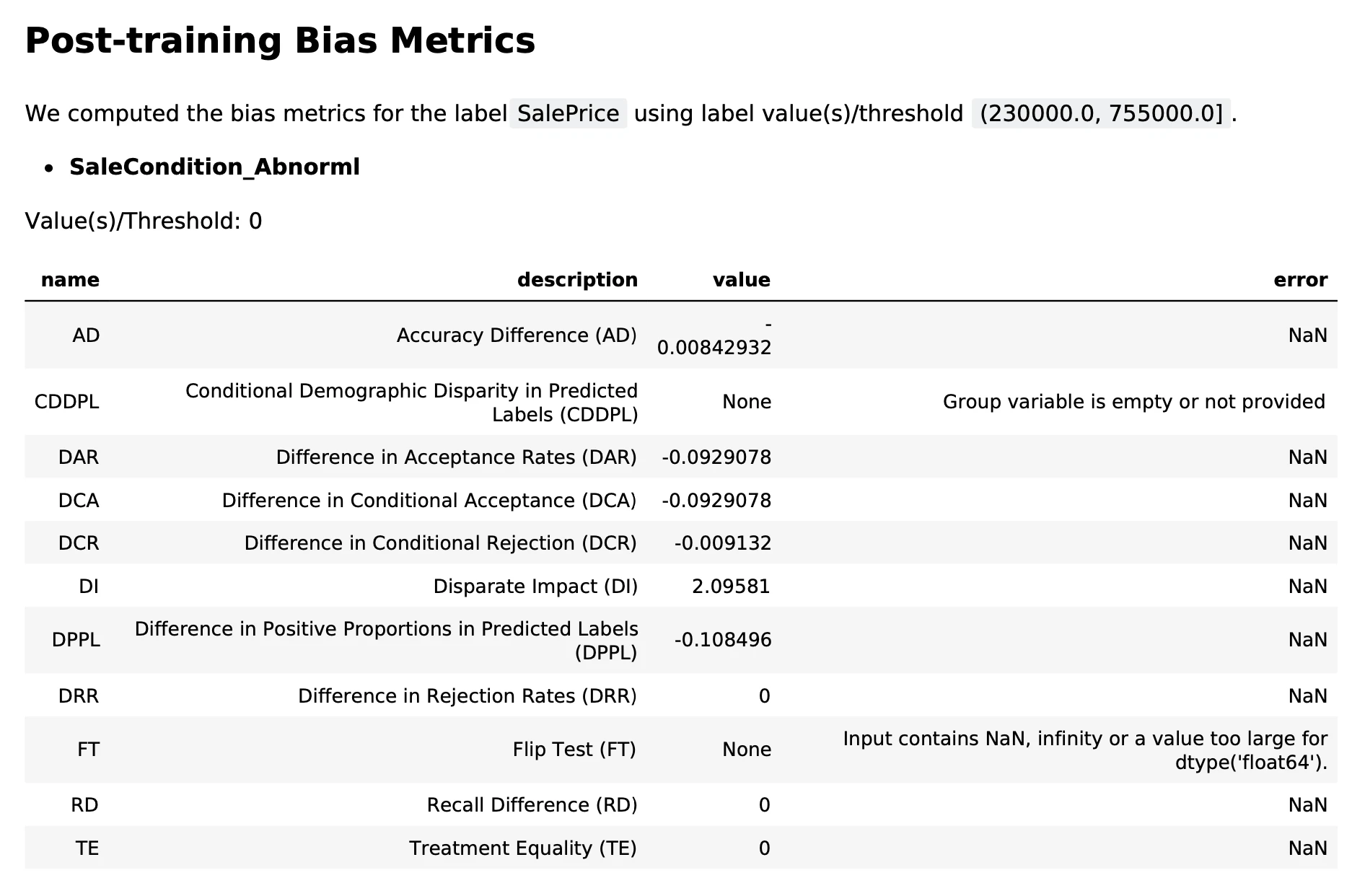
モデルのバイアスに関してもDisparate Impactは大きいですが,基本的には0に近い値を取り,公式ドキュメントによるとバイアスは小さそうです。よって元のデータのバイアスが小さいことも考えるとモデルにバイアスが混入している可能性は低いと言えるかもしれません(ただし厳密には検定などが必要だと思われます。)
説明の可視化
次はモデルの説明,すなわち入力の出力に対する重要度を可視化します。先に述べた通りよく使われるSHAP(Kernel SHAP)を利用して重要度を抽出しています。こちらもClarifyでは設定後にrun_explainability一発で実行してくれるので大変簡単です。
# Kernel SHAPに利用するハイパーパラメータ
shap_config = clarify.SHAPConfig(baseline=[test_df.iloc[0].values.tolist()],
num_samples=100,
agg_method='mean_abs')
# 格納先
explainability_output_path = 's3://{}/{}/clarify-explainability'.format(bucket, prefix)
# 説明に利用するデータ
explainability_data_config = clarify.DataConfig(s3_data_input_path=train_uri,
s3_output_path=explainability_output_path,
label=target_column,
headers=train_df.columns.to_list(),
dataset_type='text/csv')
# 説明性の計算
clarify_processor.run_explainability(data_config=explainability_data_config,
model_config=model_config,
explainability_config=shap_config)
実行を行うと下記のようなレポートが同様に現れます。
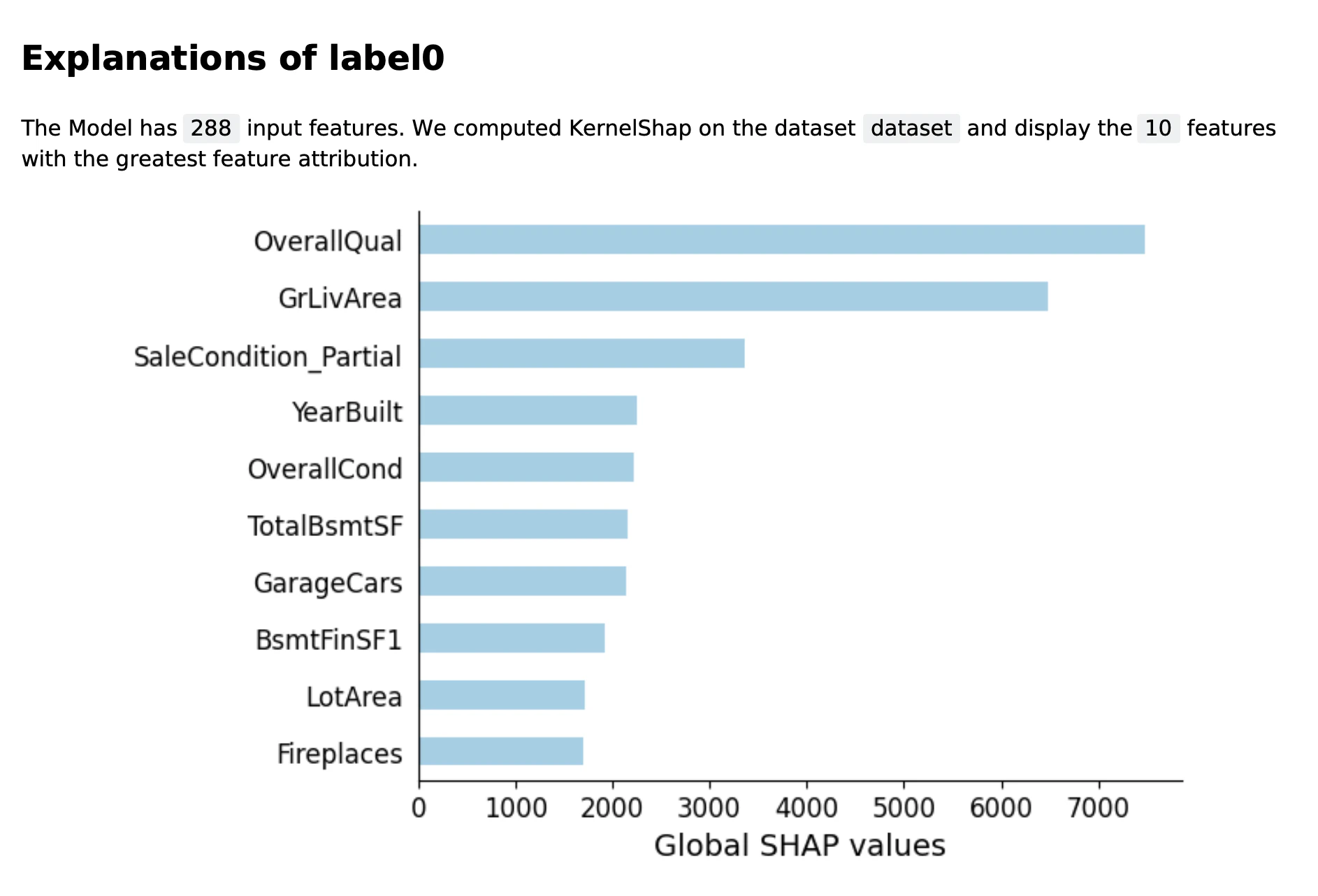
重要度の高い特徴トップ10が順に可視化されます。これをみるとカテゴリカルデータよりも値に依存するようですね。あと築年数やクオリティなど,直感的にも価格に関係のありそうな項目をモデルは重要視しているようです。
所感とまとめ
今回新しく発表のあったClarifyですが,SageMakerユーザとしては他の学習やデプロイの実行と似たようなインターフェースで作られており,特に悩むことなく実行することができました。今後は学習→デプロイのパイプラインの中にClarifyで説明やバイアスをいれるというビジョンが見えてきます。一方でバイアスは値の意味の理解が必要であり,ユーザの知識がなかなか必要になると感じました。
説明性を研究している自分としてはこれだけ説明性が身近になる,当たり前に使われるのは非常に嬉しいですね!(説明性も色々問題あったりするけどそれはまた別の機会で。)
アドベントカレンダー,次はNTT Communicationsにおけるブロックチェーン技術の第一人者,@nitkyさんの記事になります!ご期待ください!!(期待してます!)