この記事はNTTコミュニケーションズアドベントカレンダーです。前の記事は@BootCamp_2019の認めたくないものだな… Neural Networkの力学系表現というものをでした。
@kirikeiと申します。データサイエンティストの傍らデータ分析(の特に説明性)に関わる研究をやってます。普段はこれやこれのようなデータ分析系や論文解説記事を挙げることが多いです。
今回は最近提供開始となった**Googleの可視化ツール What-if Tool**を紹介します。
この記事でやること
- What-if Toolについての概要説明と導入
- What-ifを使ってTitanicデータを可視化してみる
- What-ifのモデル比較機能を利用してモデルの様子を確認
What-if Toolとは?
Googleの研究グループが作成しているJupyter上でインタラクティブに実行できる分析可視化ツールのことです。(詳しくはこちら)
What-if Toolのいいところ
可視化ライブラリといえばmatplotlibやseaborn, plotlyが有名ですが,What-if Toolはそれと比較して
- モデルの結果の比較ができる
- 2軸以上の複数軸でのデータの可視化ができる
という2点が差別化ポイントとなります(詳しくは後のTitanicの例で実際に解説します)。一方で,弱いポイントとしては
- Scatterのみに対応しているため,matplotlib時系列データへの対応や柔軟なグラフの作成ができない
が挙げられますが,他のツールにない機能をたくさん持っているのと,動的で対話的なUIは使っていて楽しいので,とにかく使ってみましょう。
What-if Toolの導入
手軽にColabで試すなら公式のチュートリアルを使い,可視化された部分の機能のみを見てみるなら公式デモが早いと思います。
また,Githubに導入方法も書いてあり,Colabであれば
!pip install witwidget
こちらをColab上から実行すれば完了です。
また,普段使いのJupyterLabやGCP AI Platform上のTensorflow Notebook Instanceを利用するのであれば,
!pip install witwidget
!jupyter labextension install wit-widget
!jupyter labextension install @jupyter-widgets/jupyterlab-manager
こちらを実行しましょう。
ただし,このWhat-if Toolは公式のGithub Repositoryを見ても分かる通り,Tensorboardのプラグインのようなので,TensorflowのInstallは必須となることに注意しましょう。
What-if Toolを試す
Titanicデータを可視化してみる
使うだけならば公式のチュートリアルがかなり詳しいのでそちらを使っていただいて構いませんが,それだと面白くないので,今回はKaggleで有名なTitanic号の生存予測データを可視化していきます。(今回使った環境は先に述べたGCPのAI Platformです。)
準備
事前にTitanic号の生存予測のデータをJupyterLab上にアップロードしておきます。また,上の章のコマンドに応じてWhat-if Tool(WIT)をダウンロードしておきます。
使うパッケージをimportします。可視化で利用するのはWitConfigBuilderクラスとWitWidgetクラスになります。まず学習データを可視化するためにPandas.DataFrameとして読み込んでおきます。
import pandas as pd
import numpy as np
import tensorflow as tf
from witwidget.notebook.visualization import WitConfigBuilder
from witwidget.notebook.visualization import WitWidget
train_df = pd.read_csv('./train.csv', sep=',', index_col='PassengerId')
train_df.head()
ここでWITはtf.train.Exampleクラスを入力とするので,ヘルパ関数としてPandas.DataFrameをtf.train.Exampleに変換する関数を準備しておきます(この関数はチュートリアルより拝借しています)。
def df_to_examples(df, columns=None):
examples = []
if columns == None:
columns = df.columns.values.tolist()
for index, row in df.iterrows():
example = tf.train.Example()
for col in columns:
if df[col].dtype is np.dtype(np.int64):
example.features.feature[col].int64_list.value.append(int(row[col]))
elif df[col].dtype is np.dtype(np.float64):
example.features.feature[col].float_list.value.append(row[col])
elif row[col] == row[col]:
example.features.feature[col].bytes_list.value.append(row[col].encode('utf-8'))
examples.append(example)
return examples
train_examples = df_to_examples(train_df)
可視化
さらにWitConfigBuilderクラスをインスタンス化してWitWidgetクラスに食わせると可視化できます。
実際に見てみましょう。Datapoint editorタブでは以下のような画像が表示されます。なにやらカラフルで豪華な画面が現れます。各点はデータポイント(行)を表しています。色はColor選んだカラム(ここではParch)で色分けされています。
config_builder = WitConfigBuilder(train_examples)
WitWidget(config_builder, height=1000)

ここでColorをSurvived,Binning X-Axisを年齢で選択してみましょう。これにより以下のように画面がぬるっと変化します。

Survived=1,すなわち生き残った人は赤色に,生き残れなかった人は青色に着色されています。Binning X-axisでは選択されたカラムがX軸方向が適当なBinで分割されます。
図を眺めているAgeだけではSurvivedはあまり分かれていないことがわかります。強いて言えば56~64歳の人が生き残れなかったこと,8歳までの子供の生き残った率が高そうなのがわかるくらいでしょうか。
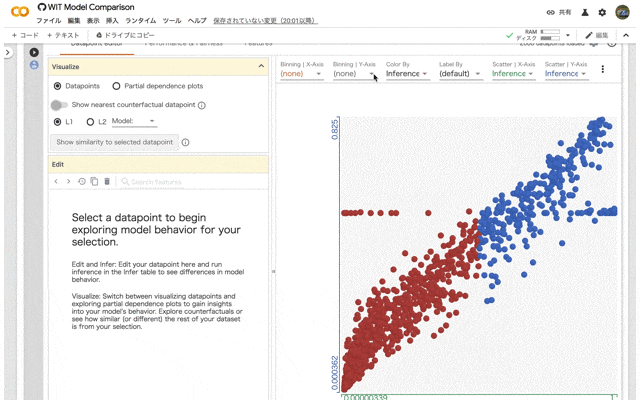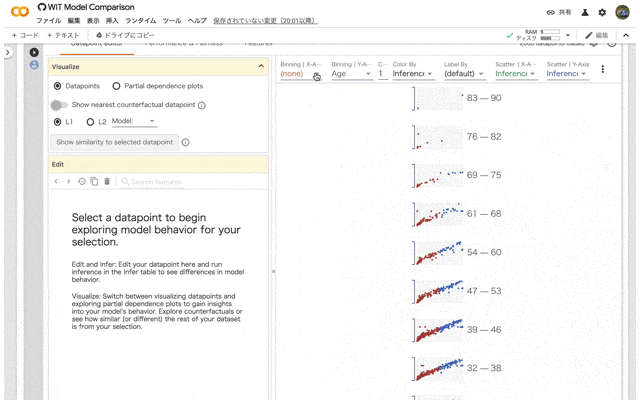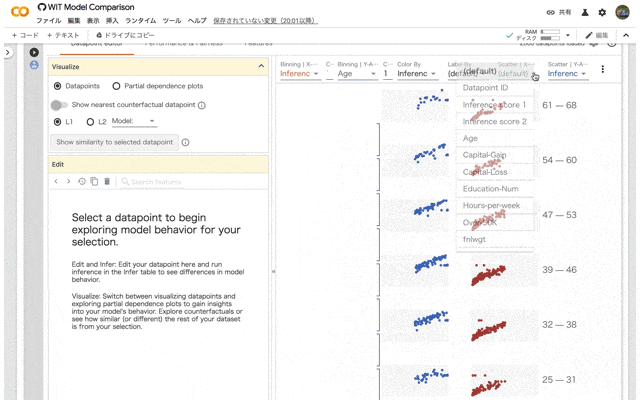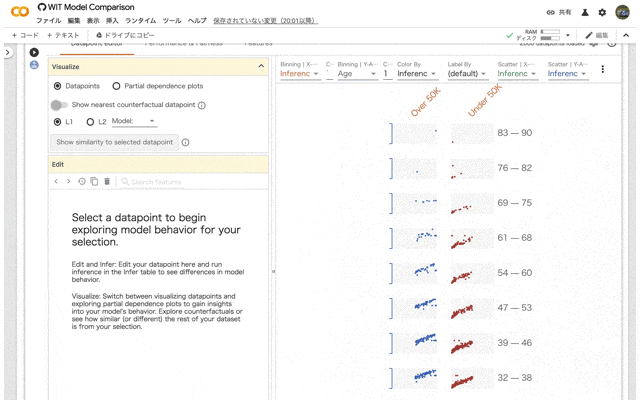
加えて,Binning Y-Axisを性別に変更してみます。
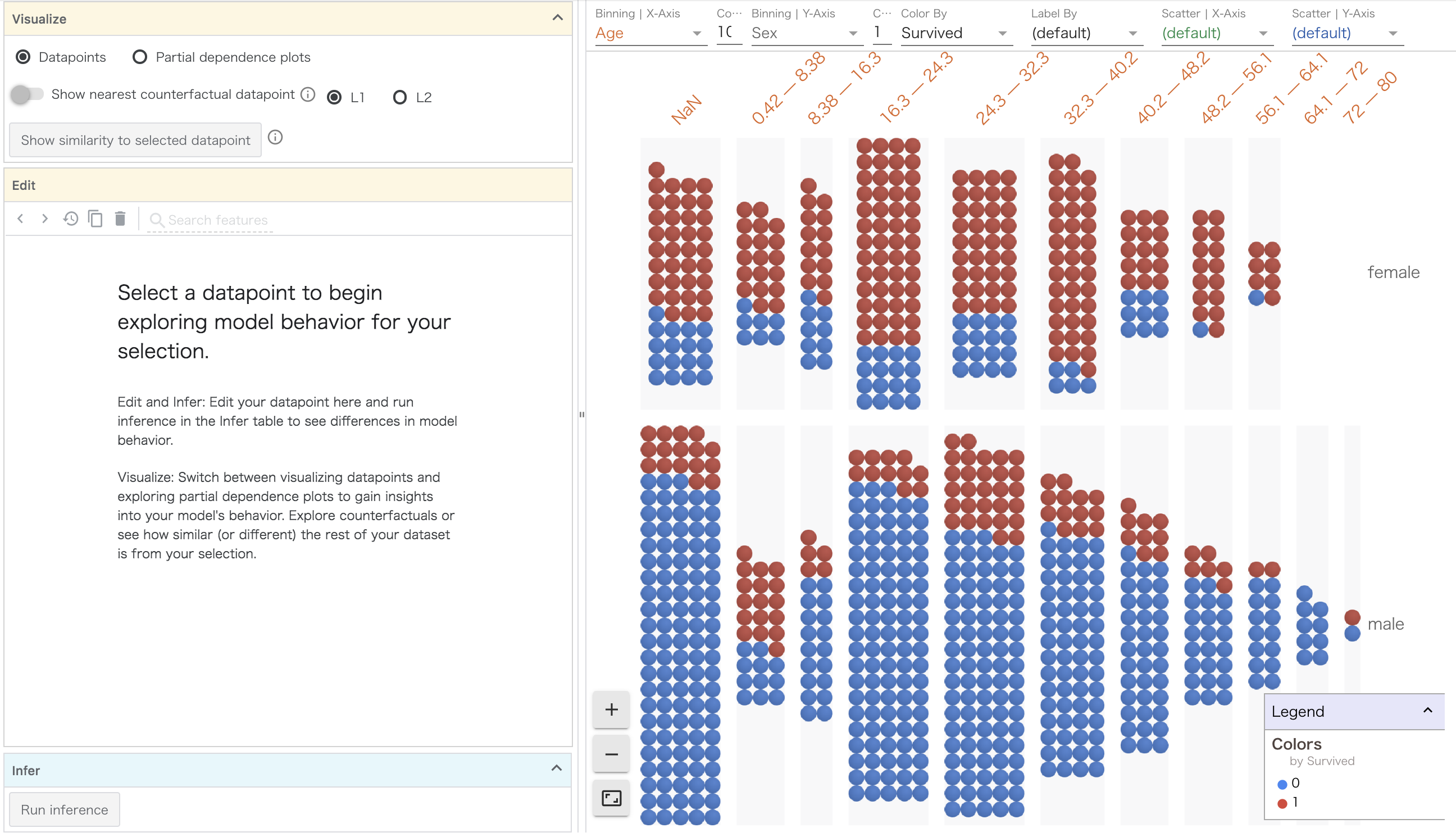
ここまで来ると傾向が結構見えてきますね。男性と女性でSurvivedの結果がかなり違ってきます。さらに年齢が高い女性の生存率はかなり高いようですね。年齢と性別を組み合わせることで新たな傾向が見えてきます。
ここでさらにBinning Y-Axis を運賃に変更してみます。
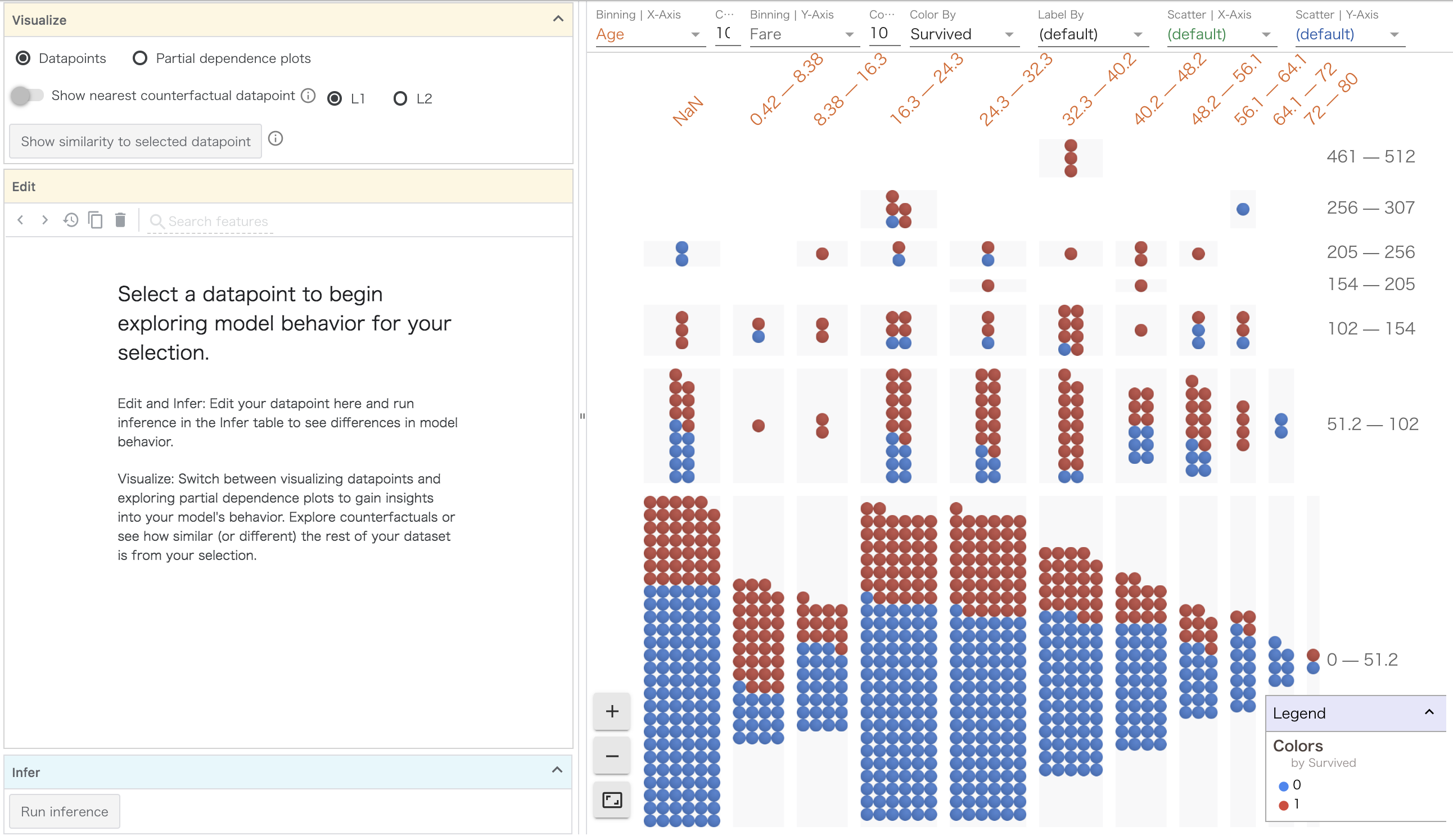
ここでは運賃が高い号車にいる人の生存率は高いことがわかります。一方で0歳〜8歳までの子供は低い運賃を払っていても生存率が高いです。これは仮説ですが,いわゆる子供料金が適用されているため,高い客室にいるが運賃は安く抑えられているからかもしれません!?
また,Featuresタブを見ることでデータの統計量がわかります。こちらはPandasなどでもよく見る図ですね。
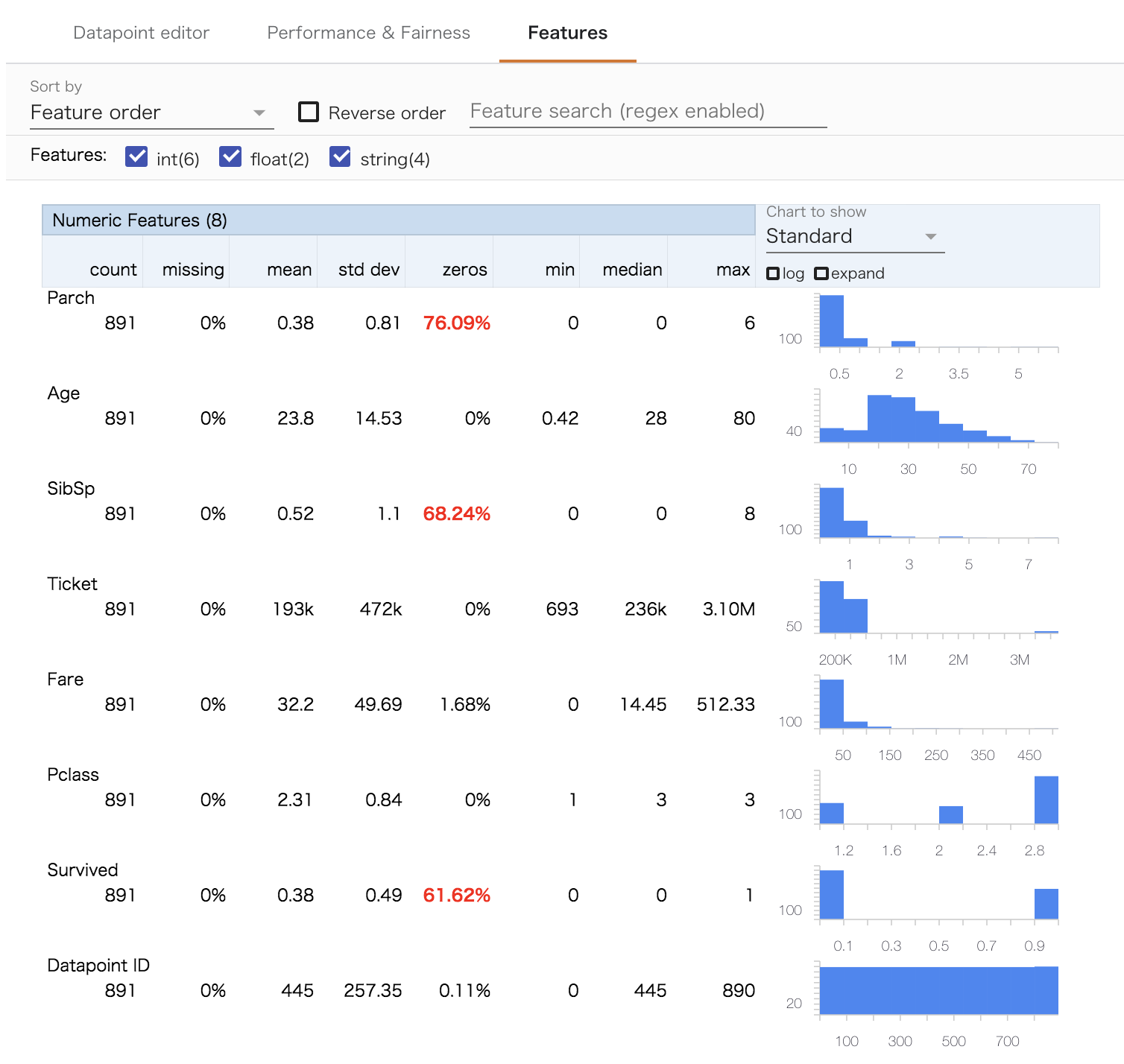
このような形で,モデルを使わずともWhat-if Toolでわかることはたくさんあります。
モデルの比較の準備
ここからはロジスティック回帰とMLPのモデルを作成して,各結果を見比べてみます。学習までのコードは以下です。tf.Estimatorを利用しますが,詳しくはtf.Estimatorのチュートリアルを参照してください。
# What-if Toolチュートリアルよりヘルパー関数群
# An input function for providing input to a model from tf.Examples
def tfexamples_input_fn(examples, feature_spec, label, mode=tf.estimator.ModeKeys.EVAL,
num_epochs=None,
batch_size=64):
def ex_generator():
for i in range(len(examples)):
yield examples[i].SerializeToString()
dataset = tf.data.Dataset.from_generator(
ex_generator, tf.dtypes.string, tf.TensorShape([]))
if mode == tf.estimator.ModeKeys.TRAIN:
dataset = dataset.shuffle(buffer_size=2 * batch_size + 1)
dataset = dataset.batch(batch_size)
dataset = dataset.map(lambda tf_example: parse_tf_example(tf_example, label, feature_spec))
dataset = dataset.repeat(num_epochs)
return dataset
# Creates a tf feature spec from the dataframe and columns specified.
def create_feature_spec(df, columns=None):
feature_spec = {}
if columns == None:
columns = df.columns.values.tolist()
for f in columns:
if df[f].dtype is np.dtype(np.int64):
feature_spec[f] = tf.io.FixedLenFeature(shape=(), dtype=tf.int64)
elif df[f].dtype is np.dtype(np.float64):
feature_spec[f] = tf.io.FixedLenFeature(shape=(), dtype=tf.float32)
else:
feature_spec[f] = tf.io.FixedLenFeature(shape=(), dtype=tf.string)
return feature_spec
def create_feature_columns(columns, feature_spec):
ret = []
for col in columns:
if feature_spec[col].dtype is tf.int64 or feature_spec[col].dtype is tf.float32:
ret.append(tf.feature_column.numeric_column(col))
else:
ret.append(tf.feature_column.indicator_column(
tf.feature_column.categorical_column_with_vocabulary_list(col, list(dtrain_df[col].unique()))))
return ret
# Parses Tf.Example protos into features for the input function.
def parse_tf_example(example_proto, label, feature_spec):
parsed_features = tf.io.parse_example(serialized=example_proto, features=feature_spec)
target = parsed_features.pop(label)
return parsed_features, target
# get_dummies後の型変換用
def to_numpy_type(df):
for f in df.columns:
if df[f].dtype == 'float64':
df[f] = df[f].astype(np.float64)
elif df[f].dtype == 'int64' or 'uint8':
df[f] = df[f].astype(np.int64)
return df
# 年齢のNullは平均で埋める
train_df.loc[train_df['Age'].isnull(), 'Age'] = train_df['Age'].mean()
# EmbarkedのNullは一番多いCで埋める
train_df.loc[train_df['Embarked'].isnull(), 'Embarked'] = 'C'
# 複雑なカラムは削除
train_df.drop(['Name', 'Cabin', 'Ticket'], axis=1, inplace=True)
dtrain_df = pd.get_dummies(train_df)
label_column = 'Survived'
input_features = ['Pclass', 'Age', 'SibSp', 'Parch', 'Fare', 'Sex_female',
'Sex_male', 'Embarked_C', 'Embarked_Q', 'Embarked_S']
# ======= 以下,What-if Toolチュートリアル参照 =========
features_and_labels = input_features + [label_column]
# tf.train.Exampleへ変換
dtrain_df = to_numpy_type(dtrain_df)
dtrain_examples = df_to_examples(dtrain_df)
# ロジスティック回帰学習
num_steps = 5000
# Create a feature spec for the classifier
feature_spec = create_feature_spec(dtrain_df, features_and_labels)
# Define and train the classifier
train_inpf = functools.partial(tfexamples_input_fn, dtrain_examples, feature_spec, label_column)
classifier = tf.estimator.LinearClassifier(
feature_columns=create_feature_columns(input_features, feature_spec))
classifier.train(train_inpf, steps=num_steps)
num_steps_2 = 2000
classifier2 = tf.estimator.DNNClassifier(
feature_columns=create_feature_columns(input_features, feature_spec),
hidden_units=[128, 64, 32])
classifier2.train(train_inpf, steps=num_steps_2)
ここまでで準備は終了です。
モデルごとの推論結果と説明変数との関係の可視化
ここで結果を可視化してみます。本来はtest.csvを対象にしたいのですが,Grand Truthとなるラベルが存在しないので,便宜的に学習データで結果を可視化してみます。(Trainを分ければいいのですが,今回は可視化のデモということで...)
初めのデータの可視化と異なるのはWitConfigBuilderクラスをインスタンス化するときにset_XXXでモデルとラベルの名前を与えているところです。
train_examples = df_to_examples(dtrain_df.)
# Setup the tool with the test examples and the trained classifier
config_builder = WitConfigBuilder(train_examples).set_estimator_and_feature_spec(
classifier, feature_spec).set_compare_estimator_and_feature_spec(
classifier2, feature_spec).set_label_vocab(['Dead', 'Survived'])
WitWidget(config_builder, height=1000)
これにより以下のような画面が現れました。何やらかっこいい。

このData point Editorタブでは,デフォルトでデータ点の色はInference Label 1,すなわちロジスティック回帰で得られた予測ラベルが振られていて,横軸と縦軸はそれぞれのモデルの予測スコアが与えられています。横軸のスコア,すなわちロジスティック回帰のスコアで色付けされているので,X軸の真ん中で綺麗に分かれています。
ColorをGrand TruthであるSurvivedに変更してみます。

赤い点が左側に寄ってきましたね。すなわちこの左側に寄ってきた赤い点群がロジスティック回帰で間違ったものとなります。さらにPclassでBin分割してみます。

見て分かる通り,どうやらロジスティック回帰のモデルはPclass2に関してはうまく分類できているようですが,3では特に間違っている様子が伺えます。(Pclassは本当はOne-hotにすべきですが,そのままにしたのが原因かも。)
閾値による評価値の変動の比較
さらに,Performance&Fairnessタブを選択して, Ground Truth FeatureでSurvivedを選択すると,下の図のように各モデルの再現率,適合率,F値,ROC曲線,PR曲線,混合行列が自動で表示されます。

ここで閾値のスライドバーを変化させて見ると...

なんと,PR曲線とROC曲線の点が閾値に沿って動的に移動し,F値などの評価指標も自動で再計算されます。また,グラフをマウスオーバーするとその地点の評価値が表示されます。
異常検知など,再現率を重要視した閾値を選びたいときなど,かなり実用的ですね。
データの編集と推論
さらにData Point Editorに戻ってみます。このタブの名前の通り,モデルを評価する時はデータを自由に編集して,推論値をその場で得ることができます。例えば画面上のデータ点をクリックすることで左側のパネルにデータの各特徴の値と推論スコアが表示されます。(わかりにくいですが,画面上の黄色い点が選択した点です。)

生存確率はロジスティック回帰では0.313,ニューラルネットでは0.818と偏った値になっています。
この状態で,左側のパネルの値を男性から女性に変更して(Sex_femaleを1,Sex_maleを0にする),Run Inferenceを実行します。すると...

選択したデータ点は右上の方に移動します。さらに,生存確率はロジスティック回帰で0.875,ニューラルネットで0.874とどちらのモデルでも大きな値に変動しています。これにより,ニューラルネットはロジスティック回帰に比べて(このデータ点で言えば)男女のパラメータを重要視することがわかります。
この機能によりモデルがどのように表現を習得しているかが掴めますね。
まとめ
今回はWhat-if Toolを紹介させていただきました。EDAはデータ分析の基本なのですが,描画にもコーディングのコストがかなり高いため,億劫になりがちですが,このツールによってそれもかなり緩和されました。さらに,モデルの振る舞いをここまで低コストかつインタラクティブに表現してくれるツールはなかなかないのではないかと思います。
非常に長々とした拙文を読んでいただきありがとうございました!
次のアドベントカレンダーの記事は@yuto_k2c さんです!