解説すること
- Amason SageMakerの一番最初の基礎事項のチュートリアル
- 1行1行のコードの裏で何をしているのか
- Amason SageMakerを中心とした機械学習エコシステムのとっかかりのイメージ
解説しないこと
-
SageMakerの全体像
- SageMakerはマネージドな機械学習フレームワークであり、インスタンスの管理を極力不要しつつフレキシブルな機械学習の実行環境を手に入れることができます。
- また、アノテーションのためのツールであるGroundTruth、MLパイプラインを組むためのSageMaker PipelinesなどMLの工程を効率化するさまざまなツールを提供しています。詳しくは下記のリンクを見てください。
- https://aws.amazon.com/jp/sagemaker/
-
SageMakerで何ができるのか・メリット
- AWS Japan SageMaker 事例祭り#8 を参考にしてください
-
SageMakerの動かし方
- 今回のチュートリアルは自分で動かせるものとします
-
SageMaker Studioを用いた学習
前提とする知識
- AWSの基本的なサービス(S3, EC2)
- Jupiter Notebook, Scikit-learn, pandasの経験
はじめに
機械学習ライブラリ、特にScikit-learnやKerasなどの普及に伴い、個人でも企業でも気軽に機械学習に取りかかれるようになりました。筆者の所属するメーカ系研究所でも、機械学習を用いたプロジェクトは(最小単位1人から)当たり前に行われています。
エンジニア一人一人が機械学習を気軽に扱える上で、この気軽さが弊害になることがあります。開発内容が属人化する、案件ごとに使い回しが効かない(逆にコピペを繰り返して収集がつかない)、学習したモデルやその際のパラメータ管理ができない(どのデータを用いてどんなパラメータで学習させたか追跡できない)、など。
これらの問題は機械学習のためのリソースやコードが一枚岩(モノリシック)になっており、差し替えが効かないことが要因の一つになっています。
機械学習、特にディープラーニングに関わる技術やサービスの進歩の速さは圧倒的なため、「新しく出てくる技術要素を(ほかに影響を与えないで)素早く入れ替えて試す」ということも重要になりますが、モノリシックな設計だと、一つのモジュールの変更がアーキテクチャ全体の変更を引き起こすこともあります。
Amazon SageMaker
Amazon SageMakerはAWSが提供する機械学習のマネージドサービスで、機械学習のワークフロー全体を扱うための統合ツールです。S3(データの格納)、EC2(計算の実行)など、機械学習に含まれる要素をマイクロサービス化し、統合することで機械学習の書くプロセスの負荷を軽くします。
機械学習の各プロセスをきっちり各部品に分けておいて、それらをAPIでつないだ方が部品の差し替えがききますもんね。
AWS: Amazon SageMaker すべての開発者とデータサイエンティストのための機械学習
AWS: マイクロサービス
JAWS-UG: [AI/ML] 機械学習における AWS を用いたマイクロサービスアーキテクチャ
マイクロサービス化の障壁
モジュール全体を疎結合にしてそれぞれの再利用性が向上するのは良いことです。ローカルPCで機械学習をやっているエンジニアも皆これをすれば良いでしょう。
ただしそこには障壁があって、(たとえSageMakerのようなフルマネージドサービスを使ったとしても)マイクロサービスの仕組みを理解し、用いることにはコストがかかることです。
(注:ML Opsが注目されていますが、マイクロサービス化がML Opsの必要条件ではないし、マイクロサービス化をしたら常に見通しの良いものができるわけではないです。
This Week in Programming: Forget Microservices, Monoliths Are the Way Forward
とりあえずオレオレ方式でなんとなく済んでいる人にとってはこのコストを支払う障壁は思ったより大きいものになります。SageMakerのチュートリアルを実行したことはあるが、コードの先頭やそこかしこに(自分のコードにはない)呪文がでてきて混乱します。
「とりあえず呪文だ、そういうことにしよう」そう自分に言い聞かせますが、やはり混乱します。
なんとなくできたのは良いが**「これ、いつもよりメンドくさくない?」**となってしまってメリットが感じられなくなりがちです。(自分はそうだった)
すでにscikit-learnなどを自分のマシンで動かしたことがあり、SageMakerのメリットを求める人は
「SageMakerで何ができるかもわかる、どうやればいいかも(チュートリアルを進めれば多分)わかる。だけど一体何をやってるの?どうしてそんなコードが出てくるの?実際裏では何をやっているの?」
と思ってしまいます。
逆に、(機械学習をやるにはこうしておけばよい、という天下り的思想のもと)SageMakerで初めて機械学習を始める人にとっては、チュートリアルはレベルが高すぎると感じます。
今回話すこと
上記のような、機械学習を独自にやってきた人、これからSageMakerで機械学習を始める人、双方にとっても参入障壁があり、解決すべき問題があると考えます。つまり、マイクロサービス化した結果複雑になっているところをうまく可視化してあげて参入コストを下げる、ことです。
チュートリアルの解説
機械学習モデルの構築およびトレーニング、デプロイ with Amazon SageMaker
を用います。
やり方はAWSコンソールからSageMaker Notebookを立ち上げて順に実行するだけです(やったことある人も多いでしょう)。これを普段ローカルでやる学習フェーズと関連させて説明していきます。
文中にコードを入れていますが、話の流れをわかりやすくするために、チュートリアルのコードの切り取り方とは意図的に変えているところがあります(コードの内容自体は変えていません)。ご了承ください。
なお、今回は、学習したモデルのデプロイや学習結果の評価については言及しません。あくまで、学習までのプロセスでSageMakerが(他のマイクロサービスを巻き込みながら)何をしているのかについて説明します。
注:ここが一番重要なところですが、私自身の勉強の備忘として記している節もあります。認識違いや誤解をまねく表記などありましたら、ぜひご指摘ください
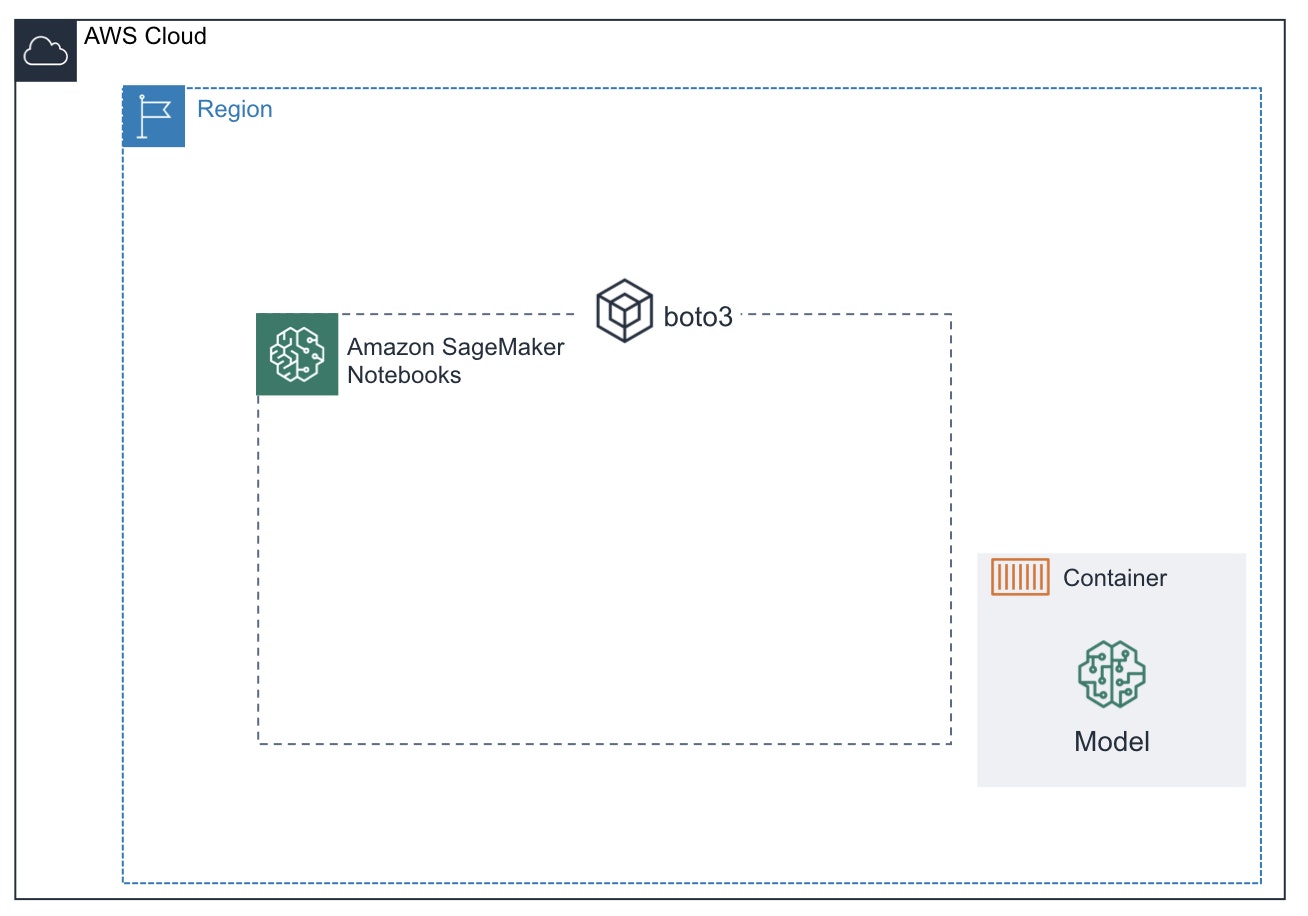
ローカルPC上での学習フェーズ
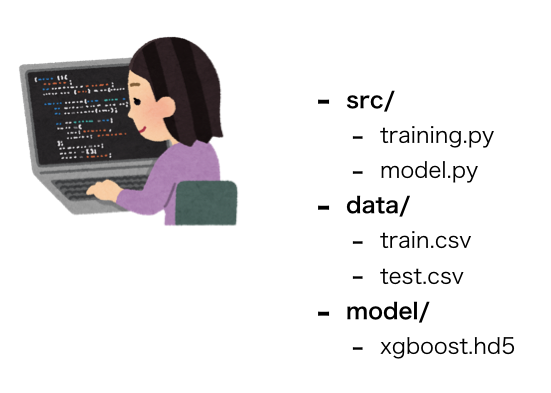
特に情報量のない画ですが、ローカル上で機械学習を行う時によくある構成を書きました。
単一のマシン上で、
- 計算資源(PC自体)
- データ格納場所
- 学習データ(dataフォルダ)
- 学習済みモデル(modelフォルダ)
- 学習アルゴリズム(model.py)
- 学習の際のスクリプト(training.py)
が一つのリソース上に存在しています。
これだけだと特に問題はないのですが、新しいデータが出てきた時、新しいアルゴリズムを試す時、計算リソースを増やしたい時、共同で開発したい時、などにリソースをどう共有(分散するか)困ります。
これに対して、SageMakerを用いたAWSのアプローチがどうなっているかを説明します。
最初に(学習とは関係ない)下準備がありますが、少しだけ我慢してください。。
SageMakerを用いた機械学習の学習フェーズ
下準備:必要な情報の取得・指定
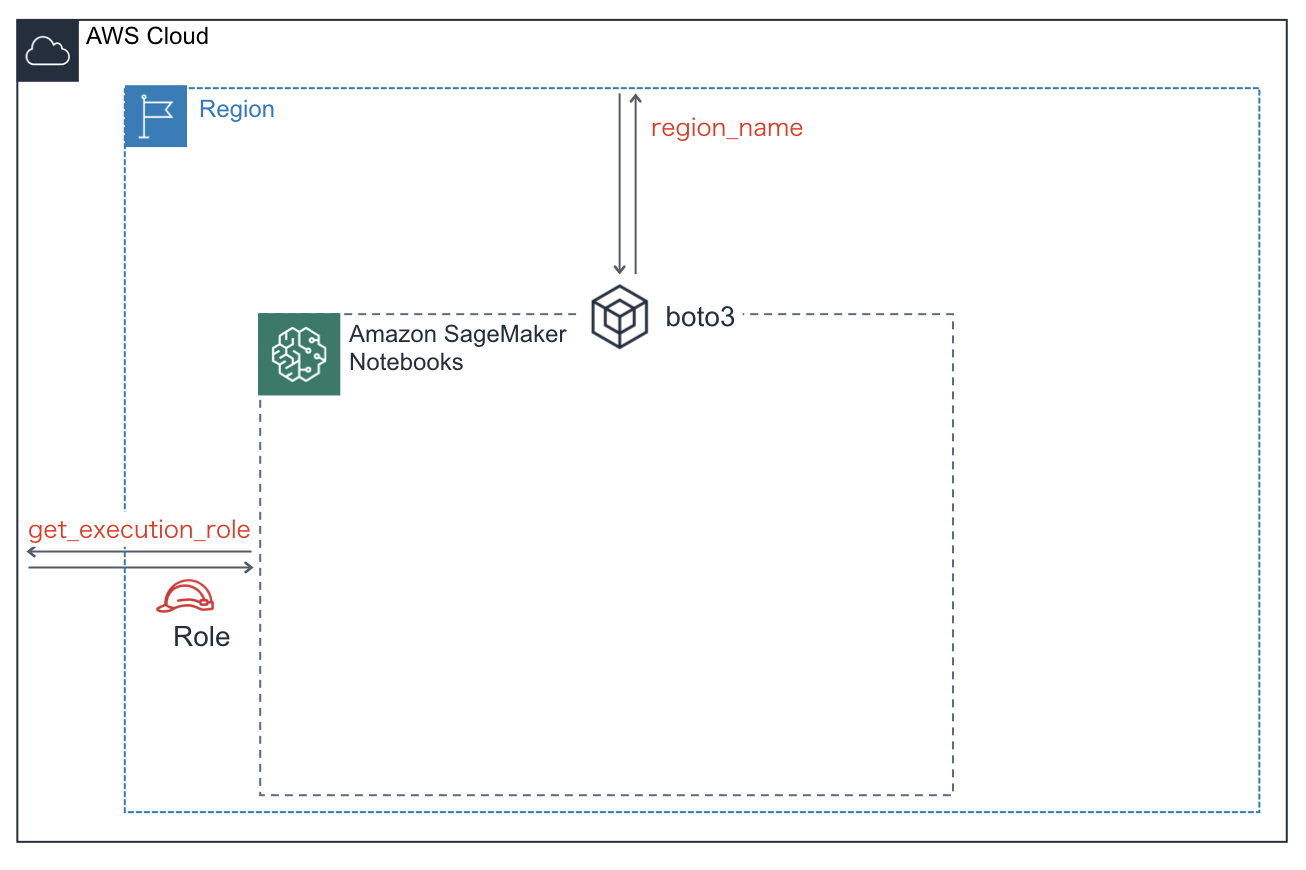
role = get_execution_role()
prefix = 'sagemaker/DEMO-xgboost-dm'
my_region = boto3.session.Session().region_name # set the region of the instance
ロール
SageMakerを利用するために(正確にはSageMaker上でEstimatorインスタンスを作成するに)ロール情報を取得・指定する必要があります。下記に引用したように、ロールとはAWS上でできることとできないこと(つまり権限)を定めたIDです。
特定のアクセス権限を持ち、アカウントで作成できる IAM アイデンティティです。IAM ロールは、IAM ユーザーといくつかの類似点を持っています。ロールとユーザーは、両方とも、ID が AWS でできることとできないことを決定するアクセス許可ポリシーを持つ AWS ID です。ただし、ユーザーは 1 人の特定の人に一意に関連付けられますが、ロールはそれを必要とする任意の人が引き受けるようになっています。
SageMaker Notebookからロール情報を取得するためには、SageMaker APIのget_execution_roleを実行します。これにより、現在開いているノートブックインスタンスに紐づいたロール名(IAMロールARN)が取得できます。
参考
AWS公式:ロールに関する用語と概念
AWS公式:ID (ユーザー、グループ、ロール)
AWS公式:Amazon リソースネーム (ARN)
S3のprefix
学習データ、また学習されたモデルはノートブック外のストレージ(S3)に保存します。また、そのためにS3ストレージ(バケット)を(もし存在しないのであれば)作成する必要があります。
今回のチュートリアルでは、S3のフォルダ構成を以下のようにします。
- s3://{bucket_name}/
- sagemaker/
- DEMO-xgboost-dm/
- train/
- train.csv
- output/
- xgboost-YYYY-MM-DD-hh-mm-ss-xxx/
- output/
- model.tar.gz
- output/
- xgboost-YYYY-MM-DD-hh-mm-ss-xxx/
- train/
- DEMO-xgboost-dm/
- sagemaker/
バケット名(bucket_name)は
- グローバルに一意
- 3文字以上63文字以内
- 大文字、アンダースコア(_)を含まない
- 小文字もしくは数字から始まる
などの制約があります。
Bucket Restrictions and Limitations
bucket_name直下のフォルダ構成を整えるためにprefixを指定します(今回は"sagemaker/DEMO-xgboost-dm")
リージョン名
ノートブックインスタンスが存在するリージョン名を取得します。リージョン名を取得するためにはBoto3を利用します。Boto3とはPythonからAWSを操作するためのSDK(ソフトウェア開発キット)です。
このチュートリアルではリージョン名は
- S3バケット作成時
- 機械学習アルゴリズムを格納したコンテナの選択時
に用いられます。
AWS公式:リージョン、アベイラビリティーゾーン、および ローカルゾーン
AWS公式:AWS SDK for Python (Boto3)
学習データの準備
さて、ここから機械学習に必要なデータを準備していきます。
機械学習を行うにあたり、まず準備するものは学習データです。今回は(AWS)外部のサーバよりデータをダウンロードし、学習に用います。
学習データのダウンロード

try:
urllib.request.urlretrieve ("https://d1.awsstatic.com/tmt/build-train-deploy-machine-learning-model-sagemaker/bank_clean.27f01fbbdf43271788427f3682996ae29ceca05d.csv", "bank_clean.csv")
print('Success: downloaded bank_clean.csv.')
except Exception as e:
print('Data load error: ',e)
urllibライブラリのurlretrieveメソッドを使ってbank_clean.csvをダウンロードします。ファイルはNotebooks内(正確にはノートブックと同じディレクトリ)のローカルフォルダにコピーされます。
try:
model_data = pd.read_csv('./bank_clean.csv',index_col=0)
print('Success: Data loaded into dataframe.')
except Exception as e:
print('Data load error: ',e)
train_data, test_data = np.split(model_data.sample(frac=1, random_state=1729), \
[int(0.7 * len(model_data))])
pd.concat([train_data['y_yes'], train_data.drop(['y_no', 'y_yes'], axis=1)], \
axis=1).to_csv('train.csv', index=False, header=False)
ダウンロードしたデータを学習データ、テストデータに分割します。
**SageMakerでは、入力データとラベルデータを同一のフォルダにまとめる必要があるようです。**ダウンロードしたbank_clean.csvでは、最後の2列に正解ラベル(2値)のone-hot-encodingが格納されています。
2値分類の場合、正例ラベルをテーブルの先頭行にもってきます。
最後にcsvに書き出します。
学習データをS3にアップロード
データを外部サーバよりダウンロードし整形して学習データを用意しました。この状態では学習データはNotebook上のローカルフォルダにあります。このデータをS3にアップロードする必要があります。
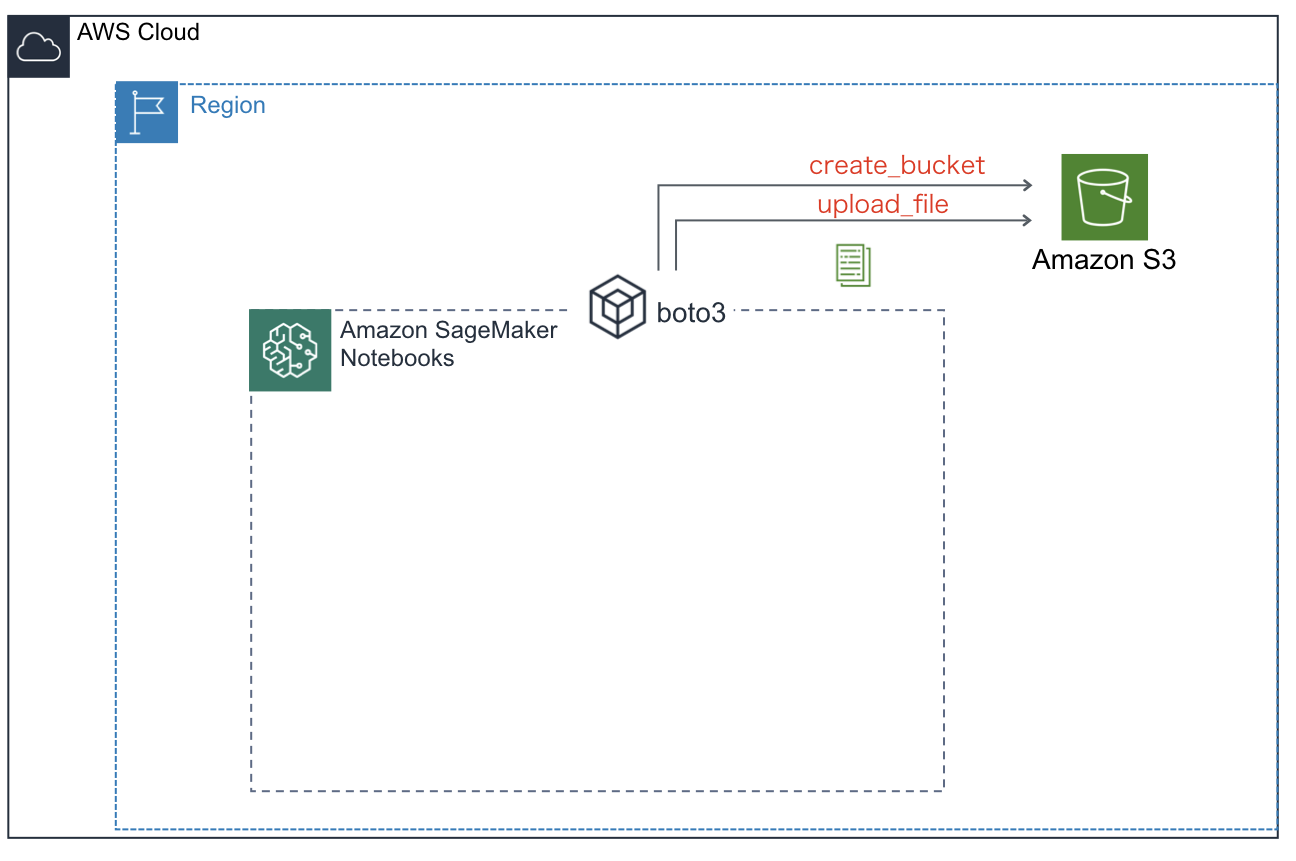
S3バケットの作成
作成したデータをアップロードするためのS3バケットを作成します。Boto3を用います。
bucket_name = 'your-s3-bucket-name' # <--- CHANGE THIS VARIABLE TO A UNIQUE NAME FOR YOUR BUCKET
s3 = boto3.resource('s3')
try:
if my_region == 'us-east-1':
s3.create_bucket(Bucket=bucket_name)
else:
s3.create_bucket(Bucket=bucket_name, CreateBucketConfiguration={ 'LocationConstraint': my_region })
print('S3 bucket created successfully')
except Exception as e:
print('S3 error: ',e)
まず、Boto3上でS3用のリソース(S3を操作するためのインスタンス "s3")を作成します。このインスタンスよりcreate_bucketメソッドを実行してバケットを作成します。作成時にはリージョンを指定します。リージョンがus-east-1かどうかで作成の方法が異なるようです。
S3へ学習データのアップロード
Boto3を使って先ほど作成した学習データをS3バケットへアップロードします。
boto3.Session().resource('s3').Bucket(bucket_name).Object(os.path.join(prefix, 'train/train.csv')).upload_file('train.csv')
なお、このチュートリアルでは出てきませんが、Boto3を使わずにSageMaker APIを用いてアップロードすることも可能です。
sagemaker_session.upload_data('./train.csv', bucket=bucket_name, \
key_prefix="{}/train".format(prefix))
追記:S3バケットを明示的に作成せずに、SageMakerから自動でデフォルトのバケットを作成する方法もあるようです。
学習モデル(アルゴリズム)の用意
データの準備ができたので、学習に用いるモデル(アルゴリズム)を選択します。SageMakerで機械学習モデルを選択するときには
- 組み込みアルゴリズム
- 独自のアルゴリズムやモデルを用いて自作
- Amazon Marketplaceからの購入
があります。今回は1を用います。
1. 組み込みアルゴリズム
XGBoostやK最近傍法など、よく用いられるアルゴリズムはSageMakerの組み込みアルゴリズムとして提供されています。ユーザーは組み込みアルゴリズムのコンテナイメージを指定することで簡単に使うことができます。組み込みアルゴリズムのリストは以下
Amazon SageMaker 組み込みアルゴリズムを使用する
このチュートリアルではコンテナイメージ名をリージョンに応じて直接指定しています。
containers = {'us-west-2': '433757028032.dkr.ecr.us-west-2.amazonaws.com/xgboost:latest',
'us-east-1': '811284229777.dkr.ecr.us-east-1.amazonaws.com/xgboost:latest',
'us-east-2': '825641698319.dkr.ecr.us-east-2.amazonaws.com/xgboost:latest',
'eu-west-1': '685385470294.dkr.ecr.eu-west-1.amazonaws.com/xgboost:latest'} # each region has its XGBoost container
この方法でも良いのですが、一体どこからこの(もしくは他の)イメージ名を取得するんだ?と思いますよね(この辺りがAWS公式の痒いところに手が届かない感があります)
実際は、SageMaker APIからアルゴリズム名をしてすることで、対応するコンテナイメージ名(URI)を取得することができます。
from sagemaker.amazon.amazon_estimator import get_image_uri
container = get_image_uri(boto3.Session().region_name, 'xgboost')
この方法でも問題なく動きました。(notebookの実行時にrepo_versionを指定しろとwarningが出るかもしれません)
組み込みアルゴリズムのイメージ名の取得方法に関しては以下
AWS公式:組み込みアルゴリズムの共通パラメータ
組み込みアルゴリズムの活用方法は以下のクラスメソッドさんのブログが大変参考になりました。(ただし公開されてから1年以上たっており、一部情報が古い可能性もあります)
Amazon SageMakerの組み込み(built-in)アルゴリズムとは…?
AmazonSageMakerのXGBoostでMNISTの手書き文字を分類してみた
2.独自のアルゴリズムやモデルを用いて自作
上記の組み込みアルゴリズムにないものや、ニューラルネットワークの構造を考察したい場合などは、Sciit-learnやPytorchなどのライブラリを用いることができます。その場合、SageMakerが求めるモデルの形式にラップする必要があります。(今後記事にする予定です)
AWS公式:Amazon SageMaker での scikit-learn の使用
AWS公式:Amazon SageMaker で PyTorch を使用
Using Scikit-learn with the SageMaker Python SDK
3. Amazon Marketplaceからの購入
AWS Marketplace での Amazon SageMaker アルゴリズムとモデルの購入と販売
Marketplaceに公開されているモデルをコンソール上から利用してみる:Amazon SageMaker Advent Calendar 2018
学習
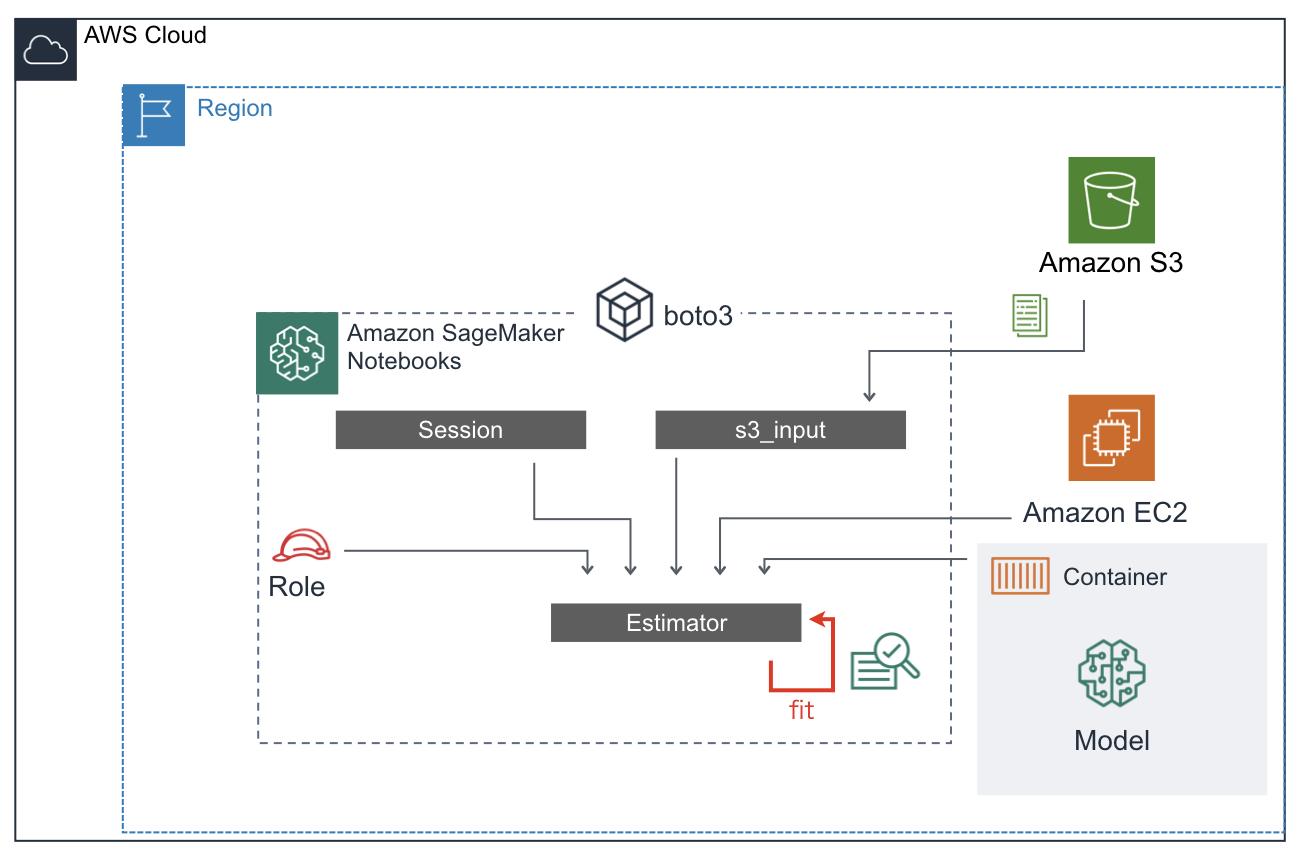
はい!前置きが長くなってしまいましたが下準備がやっとできました。準備してきたことをまとめます。
- 必要な情報
- ロール名
- リージョン名
- 学習データのアップロード
- S3バケットの作成
- S3バケットへのアップロード
- 学習アルゴリズムの準備
- 組み込みアルゴリズムのコンテナイメージURIの取得
さて、ここからSageMaker Notebook上で機械学習をおこなっていきましょう。と書きましたが**この言い方は正しくないです。**なぜなら、データはS3上にあるし、学習アルゴリズム(モデル)は外のコンテナイメージを引っ張ってきているし、計算を実行するインスタンスはNotebookが走っているインスタンスとは別に指定しています(後述)
じゃあ、Notebookは何をしているんでしょう。**ただ、みんなをまとめているだけです。**それぞれの所在を明らかにして、学習の指示を与えるだけです。(Notebook上でデータをダウンロードしたりS3にアップロードしたりしましたが、それらはあくまで前準備であって学習とは本質的に無関係です。)
なぜわざわざこんな周りくどいことをやるのでしょう?強大なコンピューティングパワーと広大な記憶領域を持つインスタンスを一つ用意して、そこで全て完結してしまえばラクじゃないでしょうか。そうすればこんなに長々とした呪文を打たなくて良いのに!
これこそが、SageMakerの特徴で機械学習に関わるリソースとモジュールを分散することで各モジュールの再利用性を保っているのです。
一つ一つを理解するのは煩わしいのですが、一度SageMakerのフレームワークを理解しそれに従って組んでしまえば、AWSの持つ様々なマネージドサービスの恩恵を受けることができます。このチュートリアルだけでは理解しにくいですが、ML Opsの観点についても(例えばパラメータの管理や学習の進捗の把握など)恩恵を受けることができます。(今後、記事を書いていけたらと思います。)
sessionの作成
学習を行う際に用いるsessionインスタンスを作成します。
sess = sagemaker.Session()
sessionとは、Amazon SageMaker APIと(必要とされる)他のAWSサービスの相互通信を管理するのに必要なクラスです。トレーニングジョブ、エンドポイント、S3上の入力データなどAmazon SageMakerが用いるエンティティとリソースを操作するのに使われます。TensorflowなどでもSessionという概念は出てくるので馴染みがあるかもしれませんね。
s3_inputの作成(学習データのロード)
S3に格納しているデータを計算をおこなうEC2インスタンスに(Notebook経由で)送るために、Notebook上で学習データのアドレスをs3_inputインスタンスとして保持しておきます。データそのものを送っているわけではないので、パイプラインというかプレイスホルダーのようなものですかね(私見)
s3_input_train = sagemaker.s3_input(s3_data='s3://{}/{}/train'.format(bucket_name, prefix), content_type='csv')
Estimatorの作成
xgb = sagemaker.estimator.Estimator(con, role, train_instance_count=1,\
train_instance_type='ml.m4.xlarge', output_path='s3://{}/{}/output'\
.format(bucket_name, prefix), sagemaker_session=sess)
xgb.set_hyperparameters(max_depth=5, eta=0.2, gamma=4, min_child_weight=6, \
subsample=0.8, silent=0, objective='binary:logistic', num_round=100)
与えられたアルゴリズムを用いて学習をおこなうためのEstimatorクラスのインスタンスを生成します。インスタンス作成に必要な情報(変数)は下記です。
- コンテナイメージ名(アルゴリズムを指定)
- ロール(権限を取得)
- EC2(学習リソースの確保)
- 学習済みモデルの出力先S3バケット
- Session(それぞれのエンティティおよびリソースを管理)
Estimatorインスタンス作成時にs3_inputは指定しません(もしそうだとすると、複数のデータセットを同じEstimatorインスタンスに供給できない)
ハイパーパラメータのセットはset_hyperparametersで指定します。
各組み込みアルゴリズムのハイパーパラメータは下記のトピックからアルゴリズムを選択することで確認できます。
AWS公式:Amazon SageMaker 組み込みアルゴリズムを使用する
学習
xgb.fit({'train': s3_input_train})
生成したEstimator(xgb)に対してfitメソッドを実行します。入力データ(のアドレス)はここで指定します。fitメソッドはscikit-learnやkerasなどで一般的ですね。SageMakerもそれに合わせています。
最後に
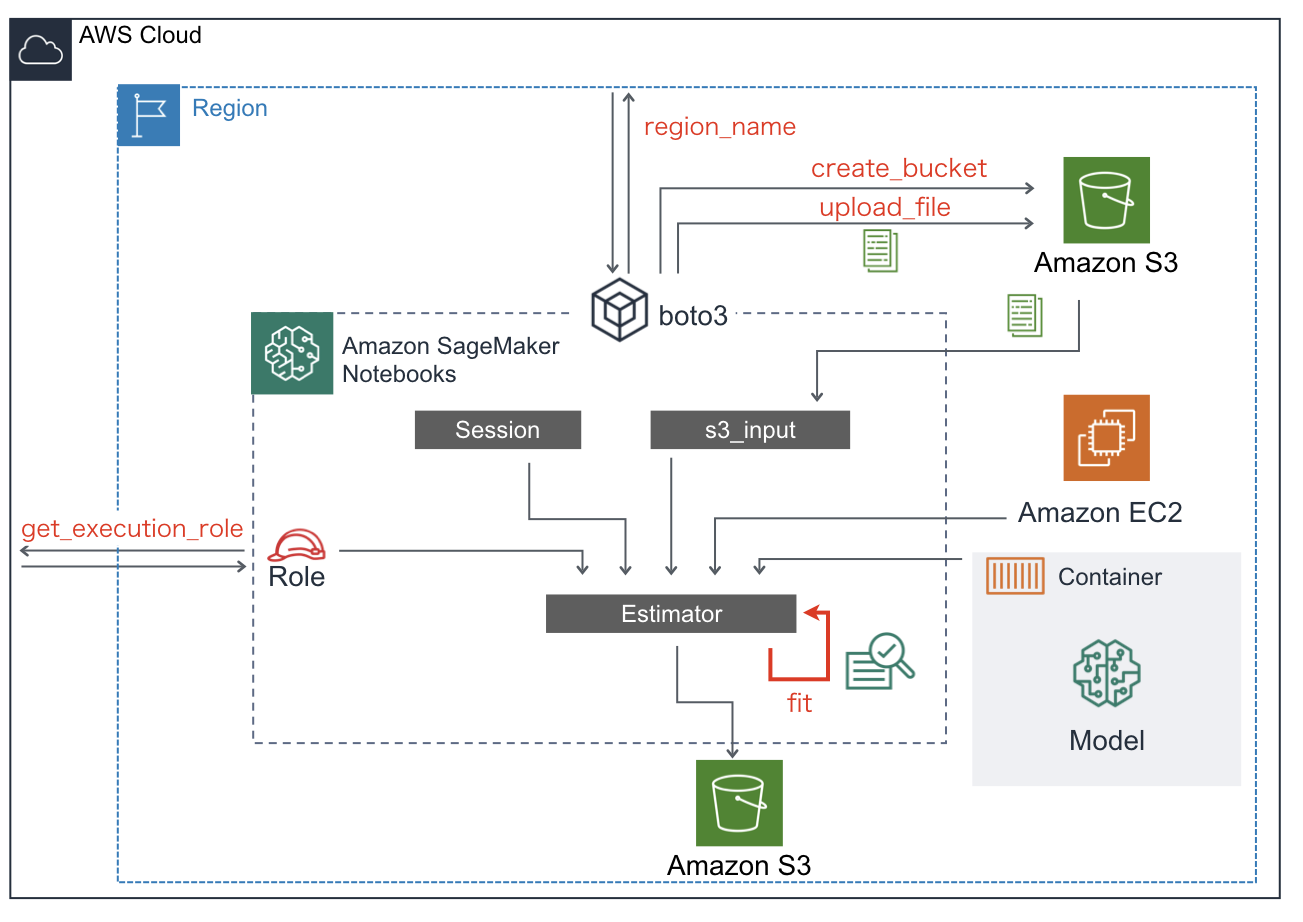
お疲れ様でした。今回のチュートリアルでのSageMakerおよび各サービスとの連携イメージを載せます。
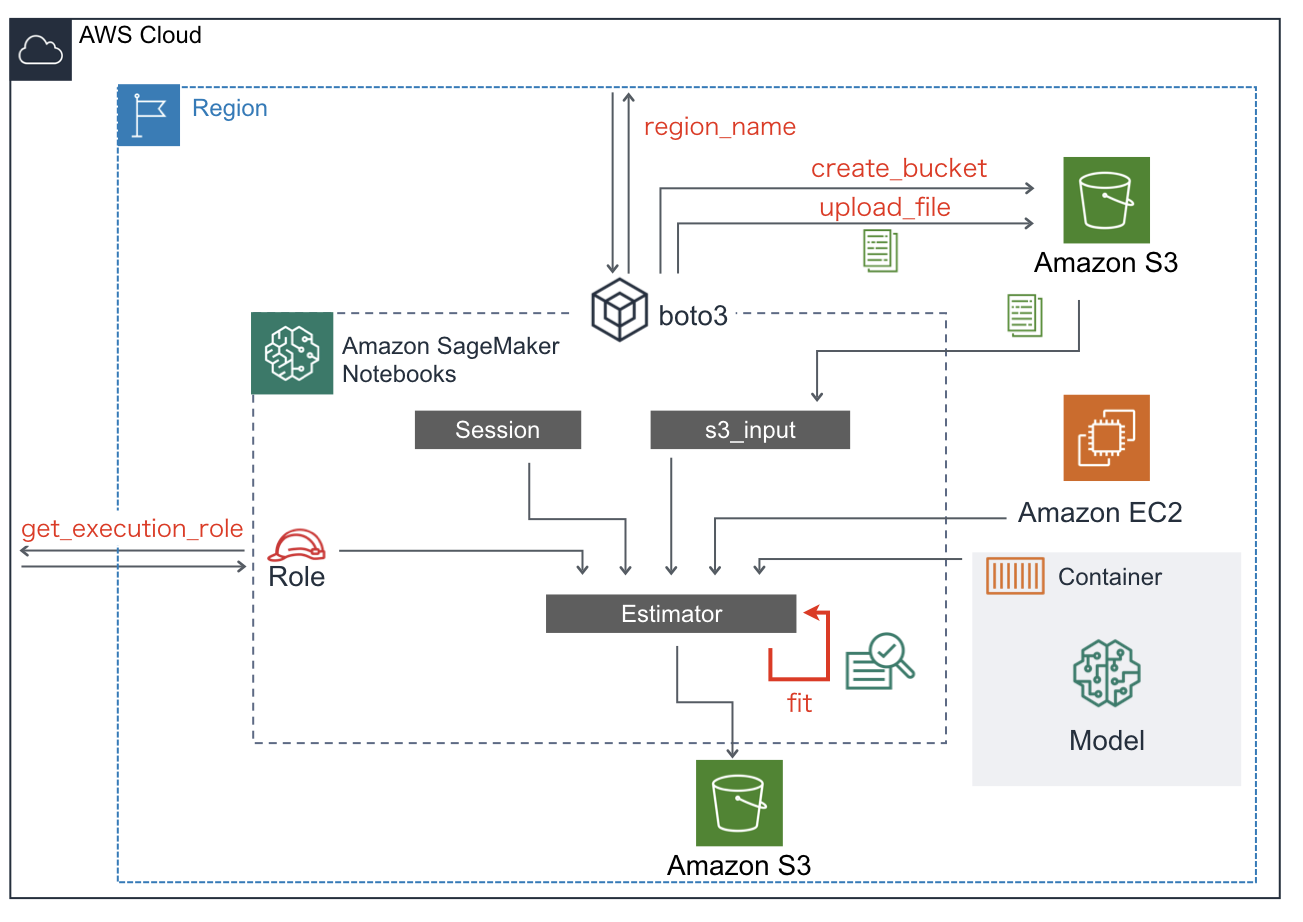
この図を理解できていれば、(上で要した)日本語の長い説明は不要ですね。長文を読んでいただきありがとうございました。
次は、
- 自作のアルゴリズムの作成方法
- SageMaker Studioの使用方法
について書いてみたいと思っています。