PONOS Advent Calendar 2025 3日目の記事です。
初めに
BigQueryでのデータ変換を効率化するDataform。
前回はその概要とメリットを紹介しましたが、今回は具体的な実装方法と、作業効率をさらに高めるためのテクニックをご紹介します!
1. ワークスペースの初期設定とGit連携
Dataformを使うには、まず開発環境(ワークスペース)とGitリポジトリを連携させます。これにより、チーム開発とバージョン管理が可能になります。
① ワークスペースの作成: Google CloudコンソールでDataformを開き、「ワークスペースを作成」からBigQueryプロジェクトを指定します。
② Gitリポジトリとの接続: 作成したワークスペースに、GitHubやBitbucketなどのGitリポジトリを接続します。
③ 開発ブランチの作成: mainブランチから個人用の開発ブランチ(例:feature/my-new-kpi)を作成し、ローカル環境と同じように作業を開始します。
このシンプルな設定だけで、すべてのSQLコードがバージョン管理下に置かれ、変更履歴の追跡やコードレビューが容易になります。
Webベースで開発して常にクエリ構文チェックでミスを防ぐも良し
ローカル環境で使い慣れたエディタにて開発するのも良し
2. データ変換の基本:SQLXファイルの実装 📝
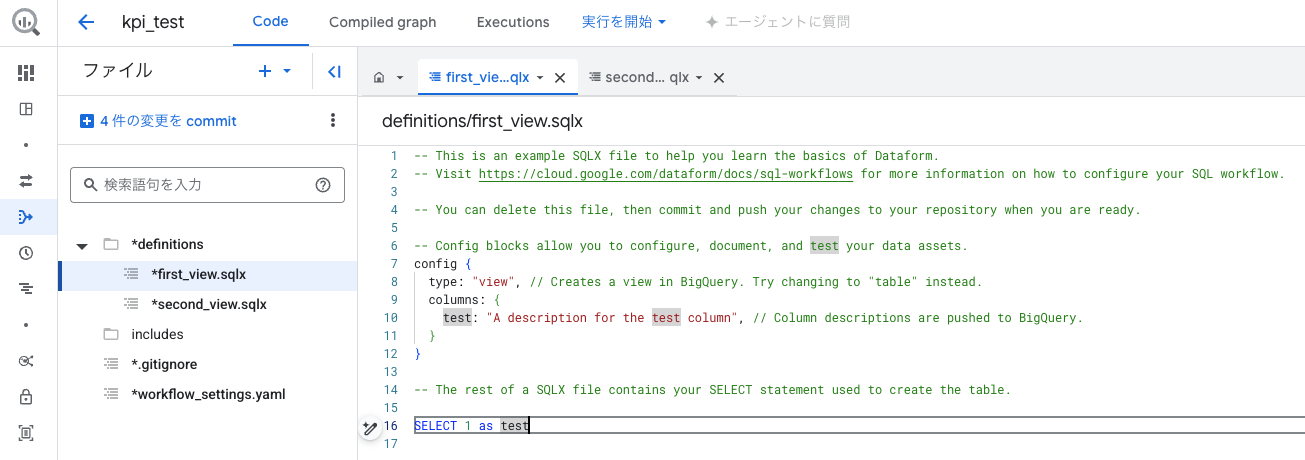
Dataformの心臓部は、通常のSQLに設定や依存関係を記述できる拡張言語 SQLX ファイルです。
2.1. 依存関係の定義 (ref()関数)
Dataformの最も強力な機能の一つが、依存関係の自動解決です。前処理されたテーブルを参照する際は、生のテーブル名を直接書くのではなく、ref()関数を使います。
✅ 実装例:前処理されたユーザーテーブルの作成
config {
type: "table",
description: "重複を除去しクレンジングされたユーザーマスタ",
}
SELECT
user_id,
min(registration_time) as registration_time,
max(last_login_time) as last_login_time
FROM
`raw_data.users`
WHERE
user_id IS NOT NULL
GROUP BY 1
✅ 実装例:KPIテーブルでの参照
config {
type: "table",
description: "日別KPI集計テーブル",
}
SELECT
t1.date,
count(t1.user_id) as daily_active_users,
sum(t2.sales_amount) as total_sales
FROM
${ref("clean_users")} as t1 -- clean_users.sqlx が先に実行されるよう自動で依存関係を解決
LEFT JOIN
${ref("raw_transactions")} as t2
ON t1.user_id = t2.user_id AND t1.date = t2.date
GROUP BY 1
ポイント: ${ref("...")}を使うだけで、Dataformがclean_users.sqlxの処理完了を待ってからdaily_kpi.sqlxを実行する DAG(有向非巡回グラフ)を自動構築します。
2.2. マテリアライゼーション戦略の指定
configブロックのtypeパラメータで、テーブルの作成方法を簡単に指定できます。
| type | 説明 | 用途 |
|---|---|---|
| "table" | 標準テーブルとして作成(CREATE OR REPLACE)。最も一般的。 | 永続的な中間テーブル、分析用最終テーブル。 |
| "view" | ビューとして作成。クエリ実行時に毎回実行される。 | データが頻繁に更新されるソース、一時的な参照。 |
| "incremental" | 増分テーブルとして作成。新しいレコードのみ追加。 | 巨大なログデータ、追加のみのトランザクションデータ。 |
| "assertion" | データ品質テスト(次項で解説)。 | データ品質のチェック。 |
3. データ品質を担保するテクニック:アサーションの活用 🛡️
データ変換パイプラインにおいて最も重要なのが品質保証です。Dataformのアサーションを使えば、SQLで簡単にデータ品質テストを定義できます。
✅ 実装例:主キーの重複チェック
config {
type: "assertion",
name: "assert_unique_user_id",
tags: ["quality_check"]
}
SELECT
user_id
FROM
${ref("clean_users")}
GROUP BY 1
HAVING count(user_id) > 1 -- 1より大きい場合はエラー(=重複がある)
このアサーションは、clean_usersテーブルに対して実行され、もし結果が1行でも返された場合(重複レコードが存在した場合)、パイプラインの実行を失敗させることができます。これにより、品質の低いデータが分析環境に流れ込むことを防ぎます。
4. 共通ロジックの再利用:JavaScriptの活用 💡
Dataform Coreでは、SQLXファイル内にJavaScriptを埋め込むことができ、複雑なロジックや共通処理をモジュール化できます。
✅ 実装例:定数と共通処理の定義
// プロジェクト横断で使う定数を定義
const PROJECT_ID = "data-project-prd";
const AD_PLATFORM_LIST = ["google_ads", "facebook_ads"];
// 共通で使うWHERE句を関数化
function is_active_user(months) {
return `last_login_time >= date_sub(current_date(), interval ${months} month)`;
}
module.exports = {
PROJECT_ID,
AD_PLATFORM_LIST,
is_active_user
};
✅ 実装例:SQLXでの呼び出し
config {
type: "table"
}
-- JavaScriptモジュールをインポート
<script>
const constants = require("constants");
</script>
SELECT
user_id,
last_login_time
FROM
${ref("clean_users")}
WHERE
${constants.is_active_user(3)} -- 3ヶ月以内にログインしたユーザーを抽出
JavaScriptを使うことで、同じロジックを複数のSQLファイルにコピペする手間がなくなり、コードの保守性と可読性が大幅に向上します。
5. まとめ
今回は、Dataformの具体的な実装として、ref()による依存関係定義、マテリアライゼーション、アサーションによる品質担保、そしてJavaScriptによる共通化のテクニックを紹介しました。
次回はより実践的な運用テクニックを紹介する予定です。
明日公開されるのでお楽しみに!!