はじめに
Autonomous Databaseにデータ・パイプラインの機能が追加されました。
Autonomous Databaseのデータ・パイプラインには大きく分けて2つの機能があります。
- データ・ロード:一定間隔で継続的にオブジェクト・ストア内のファイルを表にロード
- データ・エクスポート:一定間隔で継続的に表の内容をオブジェクト・ストアにエクスポート
今回は、データ・パイプラインを用いた表へのデータ・エクスポートを検証してみました。
データ・ロードについては @500InternalServerError さんの [OCI]Autonomous Databaseのデータ・パイプライン機能(DBMS_CLOUD_PIPELINE)を試してみた(データ・ロード編)にあります。
エクスポートデータ・パイプラインはデータベースのテーブルやクエリーの結果から、定期的に新しいデータをオブジェクトストアにエクスポートするためのデータ・パイプラインです。エクスポートパイプラインの使用例としては、以下のようなものがあります。
- アプリケーションで生成された新しい時系列データを、定期的にデータベースからオブジェクトストアにエクスポート。
エクスポートパイプラインには3つのオプションがあります。
- 新しいデータを追跡するために、日付またはタイムスタンプ列をキーとして、表の増分データをオブジェクトストアにエクスポートする。
- 新しいデータを追跡するために、日付またはタイムスタンプ列をキーとして、クエリ結果の増分データをオブジェクトストアにエクスポートする。
- 日付またはタイムスタンプ列を参照せずにデータを選択するクエリを使用してまたは表全体のデータをオブジェクトストアにエクスポートする(パイプラインは、スケジューラの実行ごとにクエリが選択したすべてのデータをエクスポートするようにする)。
事前準備
- Autonomous Databaseでクレデンシャルの作成
OCIチュートリアルの クレデンシャル情報の登録参照 - エクスポート対象表
前回からの増分をエクスポートする場合は、判別する日付またはタイムスタンプ列があること
データ・パイプラインの作成
パイプラインの作成にはDBMS_CLOUD_PIPELINE.CREATE_PIPELINEプロシージャを使用します。
今回はMY_PIPELINE1という名前のデータ・エクスポートのためのパイプラインを作成します。
BEGIN
DBMS_CLOUD_PIPELINE.CREATE_PIPELINE(
pipeline_name => 'MY_PIPELINE1',
pipeline_type => 'EXPORT',
description => 'Export order data from table into object store file'
);
END;
/
PL/SQLプロシージャが正常に完了しました。
データ・パイプラインの属性を設定
DBMS_CLOUD_PIPELINE.SET_ATTRIBUTEプロシージャを使用して、パイプラインの属性(詳細)設定します。
例えば、エクスポート対象を表またはクエリ結果を指定するパラメータ
- table_nameパラメータを指定すると、表の行がオブジェクトストアにエクスポートされます。
- queryパラメータを指定すると、クエリはSELECT文を指定し、必要なデータのみがオブジェクトストアにエクスポートされるようにします。
(table_nameパラメータまたはqueryパラメータのいずれかが必要です)
BEGIN
DBMS_CLOUD_PIPELINE.SET_ATTRIBUTE(
pipeline_name => 'MY_PIPELINE1',
attributes => JSON_OBJECT('credential_name' VALUE 'DEF_CRED_NAME',
'location' VALUE 'https://objectstorage.ap-tokyo-1.oraclecloud.com/n/<namespace>/b/<bucket名>/o/',
'table_name' VALUE '<table名>',
'format' VALUE '{"type": "csv"}',
'priority' VALUE 'LOW',
'interval' VALUE '2')
);
END;
/
PL/SQLプロシージャが正常に完了しました。
-
location:エクスポート先オブジェクトストアの場所を指定します。
-
table_name:エクスポートするデータを含むデータベース内の表を指定します。
-
format:エクスポートするデータの形式を記述します。(csv,json,xml)
-
priority:データベースからデータを取得する際の並列度を決定します。
- HIGH:データベースのOCPU数を使用して処理される並列ファイル数を決定します。
- MEDIUM:Mediumサービスの同時処理数制限を使用して、同時処理数を決定します。デフォルト値は4です。
- LOW:パイプライン・ジョブをシリアル実行します。
-
interval:パイプライン・ジョブの連続した実行間の時間間隔を分単位で指定します。デフォルトの間隔は15分です。
-
key_column:新しいデータをエクスポートする場合は、識別できる日付またはタイムスタンプの列をに指定します。
最後の実行タイムスタンプまたは日付は、エクスポート・パイプラインによって追跡され、key_columnの値と比較されて、オブジェクトストアにエクスポートする新しいデータを識別します。
BEGIN
DBMS_CLOUD_PIPELINE.SET_ATTRIBUTE(
pipeline_name => 'MY_PIPELINE1',
attributes => JSON_OBJECT('credential_name' VALUE 'DEF_CRED_NAME',
'location' VALUE 'https://objectstorage.ap-tokyo-1.oraclecloud.com/n/<namespace>/b/<bucket名>/o/',
'table_name' VALUE '<table名>',
'key_column' VALUE '<timestamp列名>',
'format' VALUE '{"type": "csv"}',
'priority' VALUE 'LOW',
'interval' VALUE '2')
);
END;
/
PL/SQLプロシージャが正常に完了しました。
データ・パイプラインのテスト
データ・パイプラインのテストとしてDBMS_CLOUD_PIPELINE.RUN_PIPELINE_ONCE プロシージャを実行して、パイプラインを一度だけ、オンデマンドで実行させます。 これは、繰り返されるスケジュールジョブを作成するものではありません。
BEGIN
DBMS_CLOUD_PIPELINE.RUN_PIPELINE_ONCE(
pipeline_name => 'MY_PIPELINE1'
);
END;
/
PL/SQLプロシージャが正常に完了しました。
Object Storageにファイルが出力されていることを確認します。

user_cloud_pipeline_historyビューや、user_cloud_pipelinesビューで、パイプラインの実行中ジョブの監視やトラブルシューティングを行うことが可能です。
select * from user_cloud_pipelines;
PIPELINE_ID PIPELINE_NAME PIPELINE_TYPE STATUS DESCRIPTION CREATED LAST_MODIFIED LAST_EXECUTION OPERATION_ID STATUS_TABLE ORACLE_MAINTAINED
----------- ------------------------ ------------- ------- --------------------------------------------------- ------------------------ ------------------------ ------------------------ ------------ ------------ -----------------
3 MY_PIPELINE1 EXPORT STOPPED Export order data from table into object store file 2023-01-08T08:09:13.151Z 2023-01-08T08:09:13.151Z 2023-01-08T08:13:37.112Z N
(オプション) パイプラインのリセット
パイプラインを開始する前に、DBMS_CLOUD_PIPELINE.RESET_PIPELINEプロシージャを使用して、パイプラインの状態をリセットすることができます。また、以下のように、PURGE_DATAオプションをTRUEに設定することでエクスポートしたオブジェクトストアのデータをパージすることもできます。
BEGIN
DBMS_CLOUD_PIPELINE.RESET_PIPELINE(
pipeline_name => 'MY_PIPELINE1',
purge_data => TRUE
);
END;
/
PL/SQLプロシージャが正常に完了しました。
データ・パイプラインを開始
DBMS_CLOUD_PIPELINE.START_PIPELINEプロシージャを使用して、パイプラインを起動します。
パイプラインが起動すると、エクスポートデータ・パイプラインとして、データがファイルとしてObject Storageバケットに出力されます。
BEGIN
DBMS_CLOUD_PIPELINE.START_PIPELINE(
pipeline_name => 'MY_PIPELINE1'
);
END;
/
PL/SQLプロシージャが正常に完了しました。
毎回すべてのデータをエクスポートした結果

毎実行エクスポートされています。
増分データをエクスポート

増分データがない時間はエクスポートファイルが出力されていません。
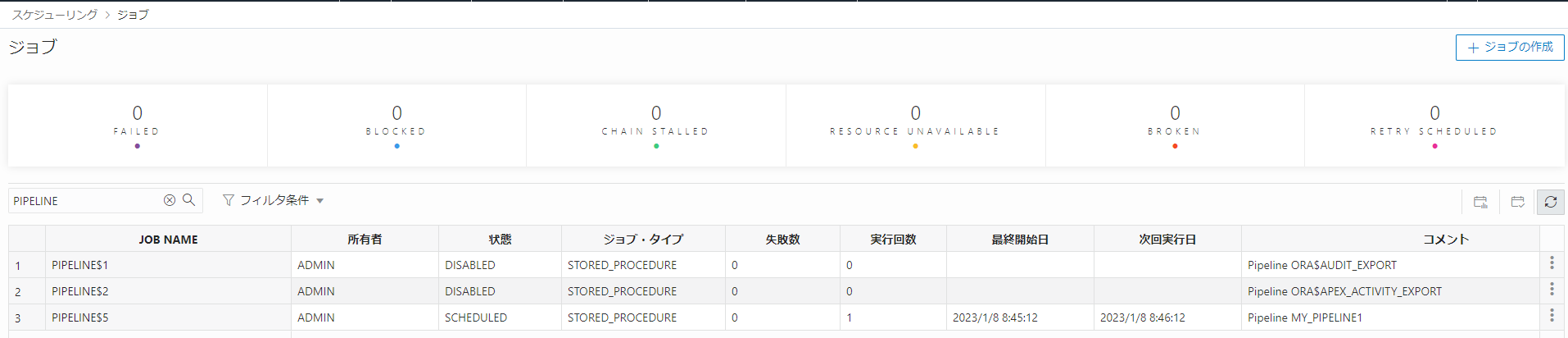
データ・パイプラインのジョブはDatabase Actionsからも確認可能
パイプライン関連のディクショナリ
パイプラインの状態の確認
SELECT pipeline_name, pipeline_type, status, status_table
FROM USER_CLOUD_PIPELINES
WHERE pipeline_name = 'MY_PIPELINE1';
PIPELINE_NAME PIPELINE_TYPE STATUS STATUS_TABLE
------------- ------------- ------- ------------
MY_PIPELINE1 EXPORT STARTED
1行が選択されました。
パイプラインの実行ログの確認
SELECT start_date, pipeline_id, pipeline_name, status, error_message
FROM user_cloud_pipeline_history
WHERE pipeline_name = 'MY_PIPELINE1'
ORDER BY start_date;
START_DATE PIPELINE_ID PIPELINE_NAME STATUS ERROR_MESSAGE
------------------------ ----------- ------------- --------- -------------
2023-01-08T08:45:12.435Z 5 MY_PIPELINE1 SUCCEEDED
2023-01-08T08:46:12.619Z 5 MY_PIPELINE1 SUCCEEDED
2023-01-08T08:47:12.877Z 5 MY_PIPELINE1 SUCCEEDED
2023-01-08T08:48:12.970Z 5 MY_PIPELINE1 SUCCEEDED
2023-01-08T08:49:13.122Z 5 MY_PIPELINE1 SUCCEEDED
パイプラインの設定内容の確認
SELECT pipeline_name, attribute_name, attribute_value FROM user_cloud_pipeline_attributes
WHERE pipeline_name = 'MY_PIPELINE1';
PIPELINE_NAME ATTRIBUTE_NAME ATTRIBUTE_VALUE
------------- --------------- -----------------------------------------------------------------------------
MY_PIPELINE1 credential_name DEF_CRED_NAME
MY_PIPELINE1 format {"type": "csv"}
MY_PIPELINE1 interval 1
MY_PIPELINE1 key_column metrics_time
MY_PIPELINE1 location https://objectstorage.ap-tokyo-1.oraclecloud.com/n/<namespace>/b/<bucket名>/o/
MY_PIPELINE1 priority low
MY_PIPELINE1 table_name <table名>
7行が選択されました。
パイプラインの停止
DBMS_CLOUD_PIPELINE.STOP_PIPELINEプロシージャを使用して、パイプラインを停止できます。
BEGIN
DBMS_CLOUD_PIPELINE.STOP_PIPELINE(
pipeline_name => 'MY_PIPELINE1'
);
END;
/
PL/SQLプロシージャが正常に完了しました。
SELECT pipeline_name, status from USER_CLOUD_PIPELINES
WHERE pipeline_name = 'MY_PIPELINE1';
PIPELINE_NAME STATUS
------------- -------
MY_PIPELINE1 STOPPED
1行が選択されました。
パイプラインの削除
パイプラインを削除するには、DBMS_CLOUD_PIPELINE.DROP_PIPELINEを使用します。
BEGIN
DBMS_CLOUD_PIPELINE.DROP_PIPELINE(
pipeline_name => 'MY_PIPELINE1'
);
END;
/
PL/SQLプロシージャが正常に完了しました。
SELECT pipeline_name, status from USER_CLOUD_PIPELINES
WHERE pipeline_name = 'MY_PIPELINE1';
行が選択されていません0行が選択されました。
おわりに
Autonomous Databaseのデータ・パイプライン機能(DBMS_CLOUD_PIPELINEパッケージ)を使用して、継続的に表データの差分をObject Storageのファイルとしてをエクスポートできることが確認できました。
参考情報
- Using Oracle Data Pipelines for Continuous Data Import and Export in Autonomous Database
- About Data Pipelines on Autonomous Database
- Control Pipelines (Start, Stop, Drop, or Reset a Pipeline)
- Monitor and Troubleshoot Pipelines
- DBMS_CLOUD_PIPELINE Package
- [OCI]Autonomous Databaseのデータ・パイプライン機能(DBMS_CLOUD_PIPELINE)を試してみた(データ・ロード編)