はじめに
Autonomous Databaseにデータ・パイプラインの機能が追加されました。
Autonomous Databaseのデータ・パイプラインには大きく分けて2つの機能があります。
・データ・ロード
一定間隔で継続的にオブジェクト・ストア内のファイルを表にロード
・データ・エクスポート
一定間隔で継続的に表の内容をオブジェクト・ストアにエクスポート
今回は、データ・パイプラインを用いた表へのデータ・ロードを検証してみました。
1. 事前準備
データ・パイプラインを用いたデータ・ロードには、オブジェクト・ストアのバケットにあるファイルと、そのデータのロード先となる表が必要です。
今回は、オブジェクト・ストレージのPipelineTestというバケットに以下のような内容のemployee1.csvをアップロードし、ロード先の表としてemployee表を用意しました。
鈴木さん,38,1000000
田中さん,51,2500000

SQL> CREATE TABLE EMPLOYEE(
2 name VARCHAR2(128),
3 age NUMBER,
4 salary NUMBER
5 );
表が作成されました。
SQL>
2. パイプラインの作成
準備が整ったので、早速パイプラインを作成します。
パイプラインの作成にはDBMS_CLOUD_PIPELINE.CREATE_PIPELINEプロシージャを使用します。
今回はMY_PIPELINEという名前のデータ・ロードのためのパイプラインを作成します。
SQL> BEGIN
2 DBMS_CLOUD_PIPELINE.CREATE_PIPELINE(
3 pipeline_name => 'MY_PIPELINE',
4 pipeline_type => 'LOAD',
5 description => 'Load employee data from object store into a table'
6 );
7 END;
8 /
PL/SQLプロシージャが正常に完了しました。
SQL>
パイプラインの詳細設定にはDBMS_CLOUD_PIPELINE.SET_ATTRIBUTEプロシージャを使用します。
今回はMY_PIPELINEという名前のデータ・ロードのためのパイプラインを作成します。
各パラメータは以下のような値を設定します。
| パラメータ | 値 |
|---|---|
| pipeline_name | 設定するパイプライン名 |
| credential_name | クラウド・ストレージへのアクセスに使用するクレデンシャル |
| location | クラウド・ストレージのURL |
| table_name | データのロード先の表の名前 |
| format | ファイルのフォーマット |
| priority | 処理の優先度(パラレル実行の並列度) |
| interval | データ・ロードの実行間隔 |
SQL> BEGIN
2 DBMS_CLOUD_PIPELINE.SET_ATTRIBUTE(
3 pipeline_name => 'MY_PIPELINE',
4 attributes => JSON_OBJECT(
5 'credential_name' VALUE 'OCI$RESOURCE_PRINCIPAL',
6 'location' VALUE 'https://objectstorage.ap-tokyo-1.oraclecloud.com/n/xxxxxxxxxxxx/b/PipelineTest/o/',
7 'table_name' VALUE 'employee',
8 'format' VALUE '{"type": "csv"}',
9 'priority' VALUE 'MEDIUM',
10 'interval' VALUE '15')
11 );
12 END;
13 /
PL/SQLプロシージャが正常に完了しました。
SQL>
パイプラインMY_PIPELINEの詳細設定が完了しました。
パイプラインは作成して詳細設定をしただけでは動作しません。
そのため、employee表はまだ空です。
SQL> col name for a30
SQL> SELECT * FROM employee;
レコードが選択されませんでした。
SQL>
3. パイプラインのテスト実行
クラウド・ストレージ内のファイルのファイル・フォーマット等が問題ないか確認するために、パイプラインのテスト実行を行うためのプロシージャDBMS_CLOUD_PIPELINE.RUN_PIPELINE_ONCEが用意されています。
pipeline_nameにテスト実行を行うパイプラインの名前を指定して、DBMS_CLOUD_PIPELINE.RUN_PIPELINE_ONCEを実行します。
SQL> BEGIN
2 DBMS_CLOUD_PIPELINE.RUN_PIPELINE_ONCE(
3 pipeline_name => 'MY_PIPELINE'
4 );
5 END;
6 /
PL/SQLプロシージャが正常に完了しました。
SQL>
テスト実行が正常に完了したので、employee表のデータを確認してみます。
SQL> SELECT * FROM employee;
NAME AGE SALARY
------------------------------ ---------- ----------
鈴木さん 38 1000000
田中さん 51 2500000
2行が選択されました。
SQL>
クラウド・ストレージ内のemployee1.csvの内容がemployee表にロードされていることが確認できました。
テスト実行ですので、DBMS_CLOUD_PIPELINE.RESET_PIPELINEプロシージャを使用して、一度パイプラインをリセットし、employee表にロードされたデータを削除します。
SQL> BEGIN
2 DBMS_CLOUD_PIPELINE.RESET_PIPELINE(
3 pipeline_name => 'MY_PIPELINE',
4 purge_data => TRUE
5 );
6 END;
7 /
PL/SQLプロシージャが正常に完了しました。
SQL>
employee表のデータを確認してみます。
SQL> SELECT * FROM employee;
レコードが選択されませんでした。
SQL>
employee表の内容が、パイプラインをテスト実行する前の状態に戻りました。
4. パイプラインの開始
テスト実行によって、データのフォーマットやオブジェクト・ストアへのアクセスに問題が無いことがわかったので、データ・ロードが継続的に行われるようにDBMS_CLOUD_PIPELINE.START_PIPELINEプロシージャを使用してパイプラインの実行を開始します。
SQL> set time on
10:21:50 SQL> BEGIN
10:21:50 2 DBMS_CLOUD_PIPELINE.START_PIPELINE(
10:21:50 3 pipeline_name => 'MY_PIPELINE'
10:21:50 4 );
10:21:50 5 END;
10:21:50 6 /
PL/SQLプロシージャが正常に完了しました。
10:21:50 SQL>
パイプラインが正常に開始されました。
employee表のデータを確認してみます。
10:21:57 SQL> SELECT * FROM employee;
NAME AGE SALARY
------------------------------ ---------- ----------
鈴木さん 38 1000000
田中さん 51 2500000
2行が選択されました。
10:21:58 SQL>
employee表にemployee1.csvのデータがロードされたことが確認できました。
パイプラインが正しく実行されるか確認するために、バケットにemployee2.csvとemployee3.csvをオブジェクト・ストレージにアップロードします。
渡辺さん,22,1000000
松本さん,41,3000000
高橋さん,28,1800000
山口さん,33,3300000
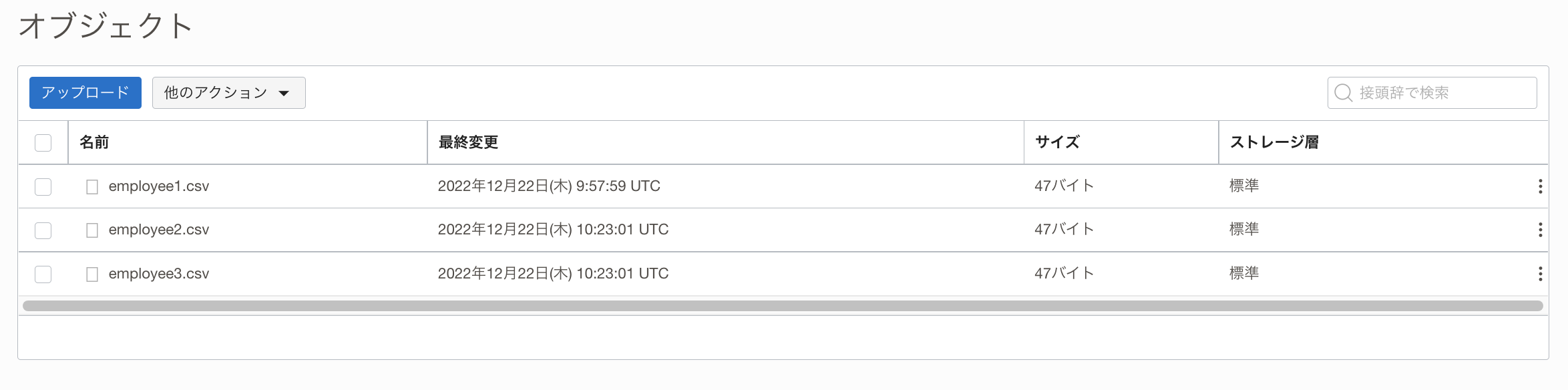
15分間隔でパイプラインが動作するように設定したので、15分以上待ちます。
再度、employee表のデータを確認します。
10:38:51 SQL> SELECT * FROM employee;
NAME AGE SALARY
------------------------------ ---------- ----------
鈴木さん 38 1000000
田中さん 51 2500000
渡辺さん 22 1000000
松本さん 41 3000000
高橋さん 28 1800000
山口さん 33 3300000
6行が選択されました。
10:38:51 SQL>
バケットに追加したemployee2.csvとemployee3.csvの内容がemployee表に追加されていることがわかりました。
5. パイプライン関連のディクショナリ
・USER_CLOUD_PIPELINES/DBA_CLOUD_PIPELINES
こちらのディクショナリ・ビューで、パイプラインの状態や各ファイルのロードの状態を格納している表の名前等を確認できます。
SQL> SELECT pipeline_name, pipeline_type, status, status_table
2 FROM USER_CLOUD_PIPELINES
3 WHERE pipeline_name = 'MY_PIPELINE';
PIPELINE_NAME PIPELINE_TYPE STATUS STATUS_TABLE
--------------- --------------- ---------- ------------------------------
MY_PIPELINE LOAD STARTED PIPELINE$18$61_STATUS
1行が選択されました。
SQL>
status_table列の表(ここではPIPELINE$18$61_STATUS)から、オブジェクト・ストアから各ファイルをロードした時の状態(COMPLETED/FAILD)とFAILDの場合のエラーの情報が確認できます。
SQL> SELECT id, name, status, error_code, error_message
2 FROM PIPELINE$18$61_STATUS;
ID NAME STATUS ERROR_CODE ERROR_MESSAGE
---------- ------------------------------ ---------- ---------- --------------------
1 employee1.csv COMPLETED
2 employee2.csv COMPLETED
3 employee3.csv COMPLETED
3行が選択されました。
SQL>
・USER_CLOUD_PIPELINE_HISTORY/DBA_CLOUD_PIPELINE_HISTORY
こちらのディクショナリ・ビューで、パイプラインの実行ログが確認できます。
SQL> SELECT start_date, pipeline_id, pipeline_name, status, error_message
2 FROM user_cloud_pipeline_history
3 WHERE pipeline_name = 'MY_PIPELINE'
4 ORDER BY start_date;
START_DATE PIPELINE_ID PIPELINE_NAME STATUS ERROR_MESSAGE
----------------------------------- ----------- --------------- ---------- --------------------
22-12-22 19:21:55.880970 +09:00 18 MY_PIPELINE SUCCEEDED
22-12-22 19:36:55.952198 +09:00 18 MY_PIPELINE SUCCEEDED
22-12-22 19:51:55.144443 +09:00 18 MY_PIPELINE SUCCEEDED
22-12-22 20:06:55.144830 +09:00 18 MY_PIPELINE SUCCEEDED
22-12-22 20:21:55.057670 +09:00 18 MY_PIPELINE SUCCEEDED
22-12-22 20:36:55.208550 +09:00 18 MY_PIPELINE SUCCEEDED
6行が選択されました。
SQL>
・USER_CLOUD_PIPELINE_ATTRIBUTES/USER_CLOUD_PIPELINE_ATTRIBUTES
こちらのディクショナリ・ビューで、パイプラインの設定内容が確認できます。
SQL> SELECT pipeline_name, attribute_name, attribute_value
2 FROM user_cloud_pipeline_attributes
3 WHERE pipeline_name = 'MY_PIPELINE';
PIPELINE_NAME ATTRIBUTE_NAME ATTRIBUTE_VALUE
--------------- -------------------- --------------------------------------------------------------------------------
MY_PIPELINE credential_name OCI$RESOURCE_PRINCIPAL
MY_PIPELINE format {"type": "csv"}
MY_PIPELINE interval 15
MY_PIPELINE location https://objectstorage.ap-tokyo-1.oraclecloud.com/n/xxxxx/b/PipelineTest/o
MY_PIPELINE priority medium
MY_PIPELINE table_name employee
6行が選択されました。
SQL>
6. パイプラインの停止
パイプラインを停止するには、DBMS_CLOUD_PIPELINE.STOP_PIPELINEを使用します。
SQL> BEGIN
2 DBMS_CLOUD_PIPELINE.STOP_PIPELINE(
3 pipeline_name => 'MY_PIPELINE'
4 );
5 END;
6 /
PL/SQLプロシージャが正常に完了しました。
SQL>
パイプラインの状態を確認します。
SQL> SELECT pipeline_name, pipeline_type, status, status_table
2 FROM USER_CLOUD_PIPELINES
3 WHERE pipeline_name = 'MY_PIPELINE';
PIPELINE_NAME PIPELINE_TYPE STATUS STATUS_TABLE
--------------- --------------- ---------- ------------------------------
MY_PIPELINE LOAD STOPPED PIPELINE$18$61_STATUS
1行が選択されました。
SQL>
パイプラインが停止状態(STOPPED)になりました。
7. パイプラインの削除
パイプラインを削除するには、DBMS_CLOUD_PIPELINE.DROP_PIPELINEを使用します。
SQL> BEGIN
2 DBMS_CLOUD_PIPELINE.DROP_PIPELINE(
3 pipeline_name => 'MY_PIPELINE'
4 );
5 END;
6 /
PL/SQLプロシージャが正常に完了しました。
SQL>
パイプラインが削除されたか確認します。
SQL> SELECT pipeline_name, pipeline_type, status, status_table
2 FROM USER_CLOUD_PIPELINES
3 WHERE pipeline_name = 'MY_PIPELINE';
レコードが選択されませんでした。
SQL>
パイプラインが削除されたことが確認できました。
まとめ
Autonomous Databaseのデータ・パイプライン機能(DBMS_CLOUD_PIPELINEパッケージ)を使用して、オブジェクト・ストア内のファイルを継続的に差分データ・ロードできることが確認できました。