はじめに
この内容は、自身の知識の整理が主な目的です。
実装した内容は、公式ドキュメントや色々な人の実装例を参考にしていますが、
なにぶん、知識不足により間違った理解があるかもしれません。。
その時は、遠慮なくご指摘頂けると幸いです。。
環境:
python 2.7.13
Keras 2.0.7
theano 0.9.0
scikit-learn 0.18.2
やること
RNNのシンプルな例を使って、Kerasでの実装方法を学ぶ。
Kerasでの簡単なRNNの実装例はCNNと比べて少なかったので、(ここくらい?)
自分で例を作ってみようと思いました。
やることは、Peter's notesの例とほとんど同じですが、
可変長の数字の並びを入力として、その総和を出力とします。
例)
| no | 入力(X) | 出力(y) |
|---|---|---|
| 1 | 1,3,0,2 | 6 |
| 2 | 0,4,3,1,2,1 | 11 |
この場合、過去の情報を保持しながら、学習する必要があるので、簡単に作れて良いサンプルデータになるかと思って選びました。(あと、簡単に訓練データが作成できるので。)
1)教師データの作成
ここはKerasと関係ない部分です。
data_num = 2000
np.random.seed(14)
min_length = 2
max_length = 4
min_num = 0
max_num = 3
def make_data():
i = 0
xdata = []
ydata = []
while i < data_num:
length = np.random.randint(min_length, max_length + 1)
data = np.random.randint(min_num, max_num + 1, length)
xdata.append(list(data.reshape(length, 1)))
ydata.append(sum(data))
i += 1
return xdata, ydata
lengthで指定範囲のランダム値をとり、それを一つのdataの長さとします。
dataには、指定範囲のランダム値をlengthの長さ分、持ちます。
data.reshape(length, 1) としているのは後の処理のためです。
Kerasではinput_shapeで入力データの次元を指定する必要があります。
なので、データをベクトルから一次元の行列に変換しています。
2)前処理・データ分割
主処理の最初、さっきのモジュールを呼び出します。
xdata, ydata = make_data()
maxlen = max([len(x) for x in xdata])
xdata = sequence.pad_sequences(xdata, maxlen=maxlen)
ydata = np.array(ydata).reshape(data_num, 1)
X_train, X_test, y_train, y_test = model_selection.train_test_split(
xdata, ydata, test_size=0.1, random_state=0)
後、可変長の長さの最大値を取得します。
ここが、少し悩んだとこなのですが、入力が可変長の場合でも、
kerasに処理させる場合、長さを固定長に統一(masking)する必要があるみたいです。
(公式ドキュメントに明記している訳ではなかったので、必須ではないかもしれません。)
次の行で、その値を使って可変長データをpaddingしています。
イメージはこんな感じです。
| no | padding前 | padding後 |
|---|---|---|
| 1 | 1,3,0,2 | 1,3,0,2,0,0 |
| 2 | 0,4,3,1,2,1 | 0,4,3,1,2,1 |
| *長さを「6」で揃える。 |
あと正解データも、後のためにベクトルから一次元の行列に変換します。
最後に、訓練データとテストデータに分割します。
ここでは、scikit-learnのライブラリを使用しました。
3)モデルの構築
Kerasを使って、モデルを構築します。
in_out_dims = 1
hidden_dims = 16
model = Sequential()
model.add(InputLayer(batch_input_shape=(None, maxlen, in_out_dims)))
model.add(
SimpleRNN(units=hidden_dims, return_sequences=False))
model.add(Dense(in_out_dims))
model.add(Activation("linear"))
model.compile(loss="mean_squared_error", optimizer="rmsprop")
今回は、SimpleRNNを選択しました。
これは、LSTMを用いた場合、どのくらい精度が異なるか比較するためです。
batch_input_shape=(None, maxlen, in_out_dims)ですが、
公式ドキュメントには
shapeが(batch_size, timesteps, input_dim)の3階テンソル.
(オプション)shapeが(batch_size, output_dim)の2階テンソル.
とあります。
timestepsは可変長文字列の固定幅、input_dimは入力次元(1次元)を指定します。
次に、Inputの入力をRNNレイヤーに渡します。
return_sequencesは、
「出力系列の最後の出力を返すか,完全な系列を返すか 」を指定します。
LSTMを積み重ねる場合、Trueとするみたいです。(今回は出力層に繋げるのでFalse)
後、入力の総和を出力としたいので、活性化関数は線形関数(y(x)=x)とします。
4)学習
callbacks = []
# Early-stopping
callbacks.append(EarlyStopping(patience=0, verbose=1))
# CSVLogger
callbacks.append(CSVLogger("simple_RNN_history.csv"))
# fitting
history = model.fit(X_train, y_train, batch_size=100, epochs=100, validation_split=0.1, callbacks=callbacks)
callbacks関数でEarly-stopping,CSVLoggerを追加しています。
Early-stoppingは過学習を防ぐための早期打ち切り関数、
CSVLoggerは学習履歴をCSV出力するための関数です。
Kerasの処理はこれだけです。
5)結果の確認
誤差は学習とともに減少しています。
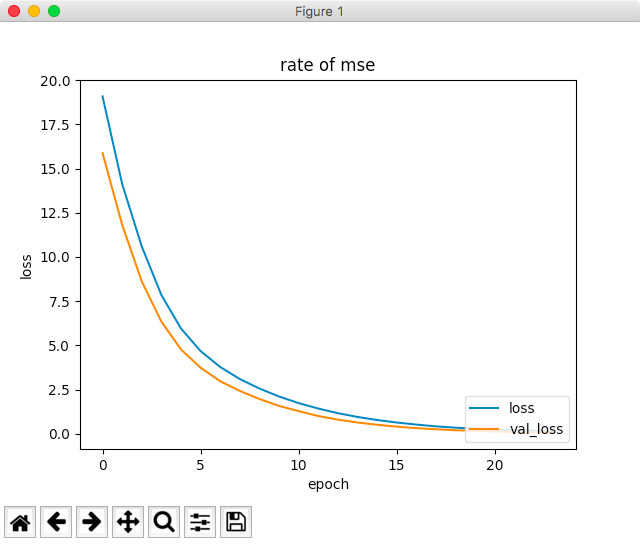
*epochs=100に設定しましたが、23回目で早期打ち切りとなっています。
最終的なval_lossは、0.11くらいです。
6)教師データとの比較
val_loss自体は減少しましたが、実際の値と比べないとよく分かりません。
数件比べてみました。
| precdict | true |
|---|---|
| [ 3.70650864] | [ 4] |
| [-0.08745918] | [0] |
| [ 7.8017683 ] | [8] |
| [-0.08745918] | [0] |
| [ 6.66305399] | [7] |
| [ 5.0816884 ] | [5] |
良い感じです。
次に可変長の最大幅をもう少し広げてみます。(4→12)
RNNは、誤差逆伝播の際、時間を遡るほど、勾配消失(爆発)しやすいと言われています。
可変長の最大幅を広げると学習が困難になる(精度が下がる)のか見たいと思います。
7)最大幅を広げた結果
誤差はこちらも減少しています。(綺麗な曲線ではありませんが。。)
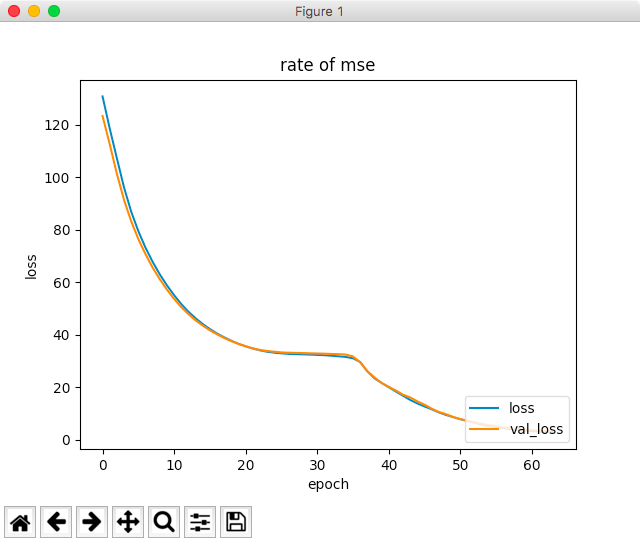
今回は、63回目で早期打ち切りとなり、最終的なval_lossは、3.29くらいでした。
数件比べてみました。
| precdict | true |
|---|---|
| [17.03078651] | [ 22] |
| [14.13138199] | [14] |
| [ 11.11346722] | [11] |
| [7.76618958] | [7] |
| [6.90901232] | [6] |
| [ -1.77918458] | [0] |
1行目が大きくずれてます。。
val_lossを比べても長さに比例して精度は悪化しました。
これだけで「勾配消失が発生した!」と断定はできませんが、可能性は高いのではと思います。
今回のソース
# -*- coding: utf-8-*-
import numpy as np
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers import InputLayer
from keras.layers.core import Dense, Activation
from keras.layers.recurrent import SimpleRNN
from keras.callbacks import EarlyStopping
from keras.callbacks import CSVLogger
from sklearn import model_selection
data_num = 2000
np.random.seed(14)
min_length = 2
max_length = 12
min_num = 0
max_num = 3
def make_data():
i = 0
xdata = []
ydata = []
while i < data_num:
length = np.random.randint(min_length, max_length + 1)
data = np.random.randint(min_num, max_num + 1, length)
xdata.append(list(data.reshape(length, 1)))
ydata.append(sum(data))
i += 1
return xdata, ydata
xdata, ydata = make_data()
maxlen = max([len(x) for x in xdata])
xdata = sequence.pad_sequences(xdata, maxlen=maxlen)
ydata = np.array(ydata).reshape(data_num, 1)
X_train, X_test, y_train, y_test = model_selection.train_test_split(
xdata, ydata, test_size=0.1, random_state=0)
in_out_dims = 1
hidden_dims = 16
model = Sequential()
model.add(InputLayer(batch_input_shape=(None, maxlen, in_out_dims)))
model.add(
SimpleRNN(units=hidden_dims, return_sequences=False))
model.add(Dense(in_out_dims))
model.add(Activation("linear"))
model.compile(loss="mean_squared_error", optimizer="rmsprop")
callbacks = [EarlyStopping(patience=0, verbose=1), CSVLogger("simple_RNN_history.csv")]
# fitting
history = model.fit(X_train, y_train, batch_size=100, epochs=100, validation_split=0.1, callbacks=callbacks)
では、この問題がLSTMで解消されるのか??
次回は、LSTMでの学習を行ってみたいと思います。