概要
Databricksの機能の1つである構造化ストリーミングを利用したストリームデータの処理に関して具体的な例を挙げながら説明します。
ストリームデータ
ストリームデータとは
ストリームデータとは絶え間なく継続的に発生し続けるデータであり、ログファイル、ソーシャルメディア、センサーなどの様々なデータソースを持つデータを指します。
ストリームデータの処理方法
- Recompute
- データが生成される度にデータセット全体を書き換える
- 正確性を担保する一方で、サイズの大きいデータセットについては特に計算負荷が高く時間がかかる傾向にある
- Incremental processing
- 前回のプロセス実行から新規追加されたデータのみを処理対象とする
- 対象データが少ないため効率性が向上する
Spark Structured Streaming (構造化ストリーミング)
構造化ストリーミングでは、ソースデータ(ストリームデータ)をUnbouded Table(継続的に増加するテーブル)として扱います。
例えば、下記の図では新規ソースデータを新規レコードとしてテーブルに追加する様子を表しています
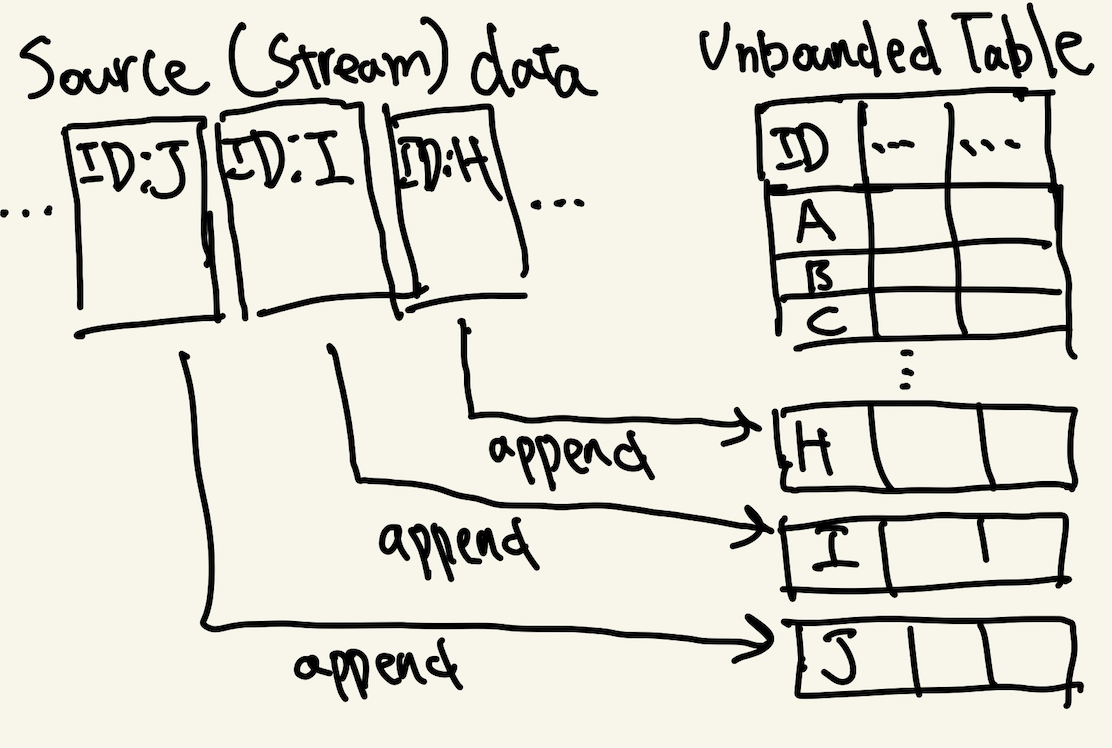
(図:ソースデータの扱いのイメージ)
またストリーミングの制約として、ソースデータは追加されるのみ(append-only)の性質を持つ必要があります。データが上書きされたり、削除されると効率性を重視するストリーミング処理をするメリットがなくなります。
データソースとしては、ディレクトリ、Cloud Storage、Kafka、Delta Lake Tableなどを対象とすることができます。
この記事ではDelta Lake Tableをソースとした処理を説明します。
Delta Lake Tableをソースデータとするストリーミング処理
Sparkを用いたストリーミング処理では、APIを使用してソースデータ(Unboulded Table)を読み込みStreaming DataFrameを作成します。このStreaming DataFrameを用いて書き込み先のテーブル(Target Table)にデータを追加または上書きします。
以下の図では、ソースデータ(Unbouded Table)に前回の処理から新規追加された3つのデータ(ID: H, I, J)を書き込み先のテーブル(Target Table)に追加している様子を表しています。
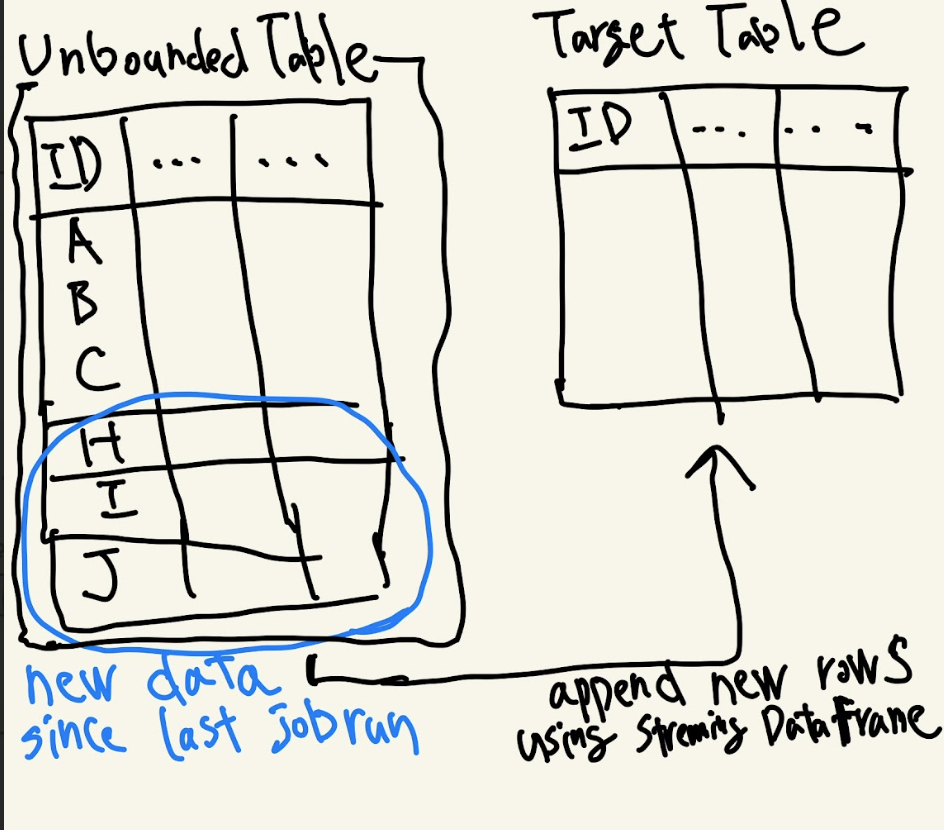
(図:新規データ追加のストリーミング処理のイメージ)
以下が上記の図に対応するPySparkのAPIを利用したソースコードとなります。
# Unbounded Table(source table)
# ソーステーブル(unbounded table)に対してStreaming DataFrameを定義。
# https://spark.apache.org/docs/latest/api/java/org/apache/spark/sql/streaming/DataStreamReader.html
stream_df = spark.readStream
.table("unbounded_table")
# Streaming DataFrameの内容をターゲットテーブルに出力する
# https://spark.apache.org/docs/latest/api/python/reference/pyspark.sql/api/pyspark.sql.DataFrame.writeStream.html#pyspark.sql.DataFrame.writeStream
sstream_df.writeStream
.trigger(processingTime="10 minutes")
.outputMode("append")
.option("checkpointLocation", "/Volumes/A_catalog/A_schema/A_volume/A_dir")
.table("target_table")
(図:上記の処理を定義したソースコード)
上記のコードの解説
はじめにソーステーブルに対してStreaming DataFrame を作成しています。ここではspark.readStreamでDataStreamReaderを作成し、tableメソッドを使用することでStreaming DataFrame を作成しています
作成したStreaming DataFrameに対して以下の設定をしてターゲットテーブルにレコードを追加しています。
- trigger: ストリーミングの書き込み操作のトリガーを定義。ここでは10分間隔で書き込みが実行されるように設定しています
| Mode | 利用方法 | 動作 |
|---|---|---|
| Continuous | .trigger(processingTime="10 minutes") | 10分間隔で実行。 デフォルトでは500ms間隔で実行する |
| Triggered | # deprecated .trigger(once=True) | 1つのmicro-batchで全データを処理。処理完了後にプロセスを停止する |
| Triggered | availableNow=True | 複数のmicro-batchで全データを処理。処理完了後にプロセスを停止する |
※ micro-batchとは:Sparkではデータを小さなチャンクに分割し、複数ジョブとして処理します。このジョブのことをmicro-batchといいいます。
https://spark.apache.org/docs/3.5.1/structured-streaming-programming-guide.html
- outputMode:ターゲットテーブルに対する書き込み処理の動作を指定する
| Mode | 利用方法 | 動作 |
|---|---|---|
| Append (default) | .outputMode("append") | 前回のジョブ実行から追加された新規データのみターゲットテーブルに追加する |
| Complete | .outputMode("complete") | ターゲットテーブルを上書きする |
appendは制限なく追加されるデータをターゲットテーブルに追加したい場合に使用し、completeは最新の集計結果などをターゲットテーブルに書き込みたい場合に使用します。
- checkpointLocation: ストリーミング処理のメタデータ(実行状況)を保持するパスを特定します。Volumes、DBFS、cloud storage like Amazon S3 or Azure Storageなどをパスに指定できます。このパスを指定することで、失敗したジョブを再開する際に、最初からではなく失敗した箇所からの処理を可能にします。またストリーミング処理ごとにパスを分離する必要があります
Spark Structured Streamingが提供する2つの保証
-
Fault Tolarance
checkpointingとwrite-ahead logsと呼ばれるシステムによって、失敗した箇所からのリトライを可能にします。 -
Exactly-once semantics
ストリームに含まれるレコードは1度のみ処理されます。これはジョブ失敗が発生、リトライを行っても重複データがターゲットテーブルに書き込まれないことを意味します。
Spark Structured Streamingが提供しない機能
データのソートや重複排除などはシンプルなAPIでは実現できなく、windowing関数やwatermarkingのような機能を使用する必要があります。
Spark Structured Streamingの実装
このセクションではサンプルデータを用いて具体的にどのようにストリームデータを処理するかを説明していきます。
内容
あるECサイトを運営するデータエンジニアが、トランザクションログをソースデータとしてストリーミング処理を実行します
使用するデータ
- トランザクションデータ
-
transaction_log_1.json
-
データの説明
- transaction_id: トランザクションID
- customer_id: 顧客ID
- product_id: 商品ID
- quantity: 商品数
- type:アクションタイプ(ex. add_to_cart:カートに入れる、remove_from_cart:カートから外す、purchased:購入)
- action_timestamp: アクションが発生したタイムスタンプ
-
Notebookでの操作
以下のコードをセルとするNotebookを作成して実行をしていきます
1 . トランザクションログのソースデータを保持するテーブルを作成します
%sql
CREATE OR REPLACE TABLE k_suzuki_catalog.streaming_sample_1.transactions_log (
transaction_id STRING,
customer_id STRING,
product_id STRING,
quantity BIGINT,
type STRING,
action_timestamp BIGINT)
LOCATION 's3://xxx/structured_streaming/transactions_log/';
2 . 1で作成したテーブルにサンプルデータを挿入します。下記のコードではJSONファイルがS3(s3://xxx/databricks_raw_data/streaming_data/transaction_logs/transaction_log_1.json)に存在する前提となっています。
%sql
COPY INTO transactions_log
FROM 's3://xxx/databricks_raw_data/streaming_data/transaction_logs/'
FILEFORMAT = JSON
FORMAT_OPTIONS ('inferSchema' = 'true')
COPY_OPTIONS ('mergeSchema' = 'true')
データの確認をします
%sql
SELECT * FROM transactions_log;
3 . Streaming処理の作成
3-1. transactions_logテーブルに対してStreaming DataFrameを作成
%python
stream_df = spark.readStream.table("transactions_log")
3-2. Streaming DataFrameからtemporary viewを作成
temporary viewに対しては通常のViewと同じようにSQL Statementを実行可能です。
%python
stream_df.createOrReplaceTempView("transactions_log_streaming_tmp_vw")
3-3. temporary viewに対してSQL Statementを発行します。この発行により、ストリーミングを開始されます。新規データがテーブルに追加されるとtemporary viewにも随時反映されます。
%sql
SELECT * FROM transactions_log_streaming_tmp_vw
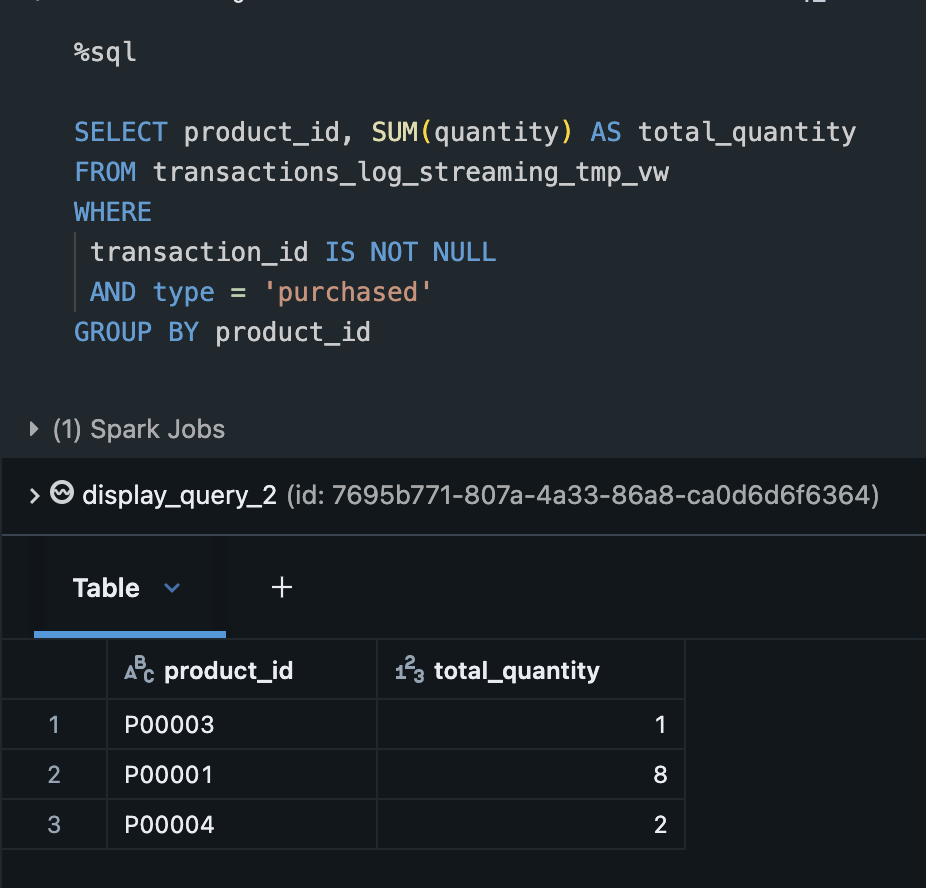
temporary viewに対して集計関数が適用できることを確認します。ここでは商品ごとの売上数を集計しています。
%sql
SELECT product_id, SUM(quantity) AS total_quantity
FROM transactions_log_streaming_tmp_vw
WHERE
transaction_id IS NOT NULL
AND type = 'purchased'
GROUP BY product_id
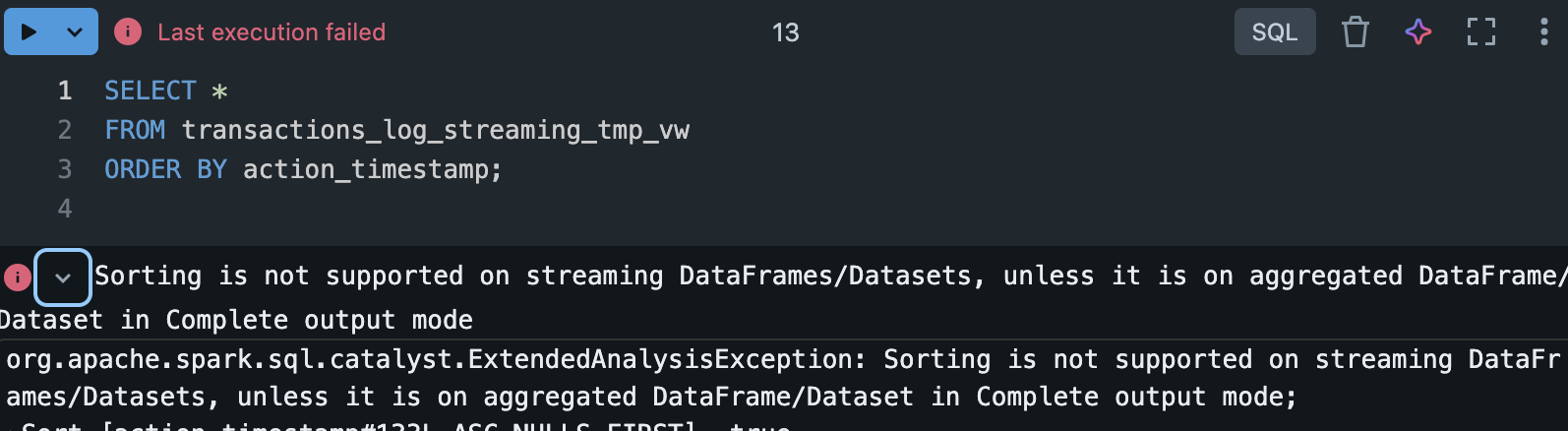
一方でソートを適用するとエラーが発生します。これは上記で記載した一部のSQLの関数がサポートされていないためです。
%sql
SELECT *
FROM transactions_log_streaming_tmp_vw
ORDER BY action_timestamp;
3-4. 商品ごとの売上数を集計結果をtemporary viewとして作成します
%sql
CREATE OR REPLACE TEMP VIEW product_sales_counts_tmp_vw AS
SELECT product_id, SUM(quantity) AS total_quantity
FROM transactions_log_streaming_tmp_vw
WHERE
transaction_id IS NOT NULL
AND type = 'purchased'
GROUP BY product_id
3-5. temporary viewに対してStraming DataFrameを作成して、ターゲットテーブル:product_sales_countsにデータを書き込みます。書き込みが内容のセルを実行するとストリーミング処理が実行されます。
%python
result_stream_df = spark.table("product_sales_counts_tmp_vw")
%python
result_stream_df.writeStream \
.trigger(processingTime='10 seconds') \
.outputMode("complete") \
.option("checkpointLocation", "/Volumes/xxx_catalog/streaming_sample_1/stream_checkpoints/product_sales_counts") \
.table("product_sales_counts")
このデータの操作では以下の設定をしています
- 10秒間隔でデータを処理
- バッチ処理ごとにターゲットテーブルを上書きする
- checkpointLocationにVolumesのディレクトリを指定
- ターゲットテーブルをproduct_sales_countに指定
上記のセルを実行後に、テーブルにデータが書き込まれていることを確認します
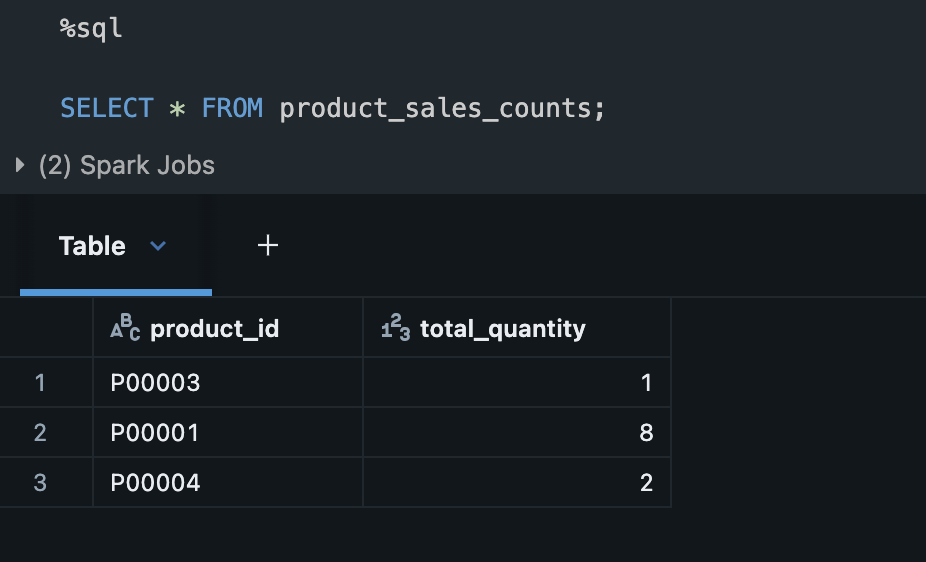
3-6. ソーステーブルに新規レコードを追加します。
%sql
INSERT INTO transactions_log(transaction_id, customer_id, product_id, quantity, type, action_timestamp)
VALUES
("00020", "S00001", "P00001" ,2, "add_to_cart", 1754022655),
("00021", "S00001", "P00001" ,2, "purchased", 1754023255),
("00023", "S00002", "P00003", 2, "add_to_cart", 1754282455),
("00024", "S00002", "P00003", 2, "purchased", 1754283055),
("00025", "S00002", "P00004", 3, "add_to_cart", 1754282456),
("00026", "S00002", "P00004", 3, "purchased", 1754283058),
("00020", "S00001", "P00002" ,2, "add_to_cart", 1754282456),
("00021", "S00001", "P00002" ,2, "purchased", 11754282458)
;
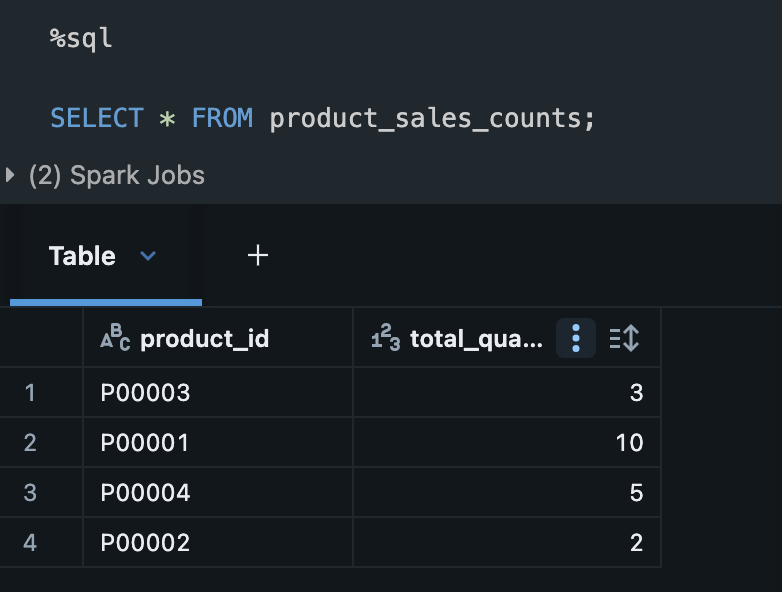
上記レコード追加後のストリーム処理が終わったら、下記のSQLを実行しテーブルが上書きされていることを確認します。
%sql
SELECT * FROM product_sales_counts;
3-7. 上記の同様のストリーミング処理をPythonのAPIで実現してみます
product_idごとに売上個数を計算し、total_quantityとしてエイリアスを作成しStreaming Dataframeを作成します。
%python
import pyspark.sql.functions as F
output_stream_df = stream_df.groupBy("product_id") \
.agg(F.sum("quantity").alias("total_quantity"))
Streaming Dataframeの中身を確認します。このセルを実行すると、ストリーミング処理が開始されます。
%python
display(output_stream_df)
集計結果を保持するStreaming Dataframeをテーブル:product_sales_counts_pythonに書き込みます。
checkpointLocationの値を1つ目のwriteStreamで指定した値とは違うパスを指定しなければいけないのが注意するポイントです。(ストリーム処理ごとに分離する必要があるためです)
%python
output_stream_df.writeStream \
.trigger(availableNow=True) \
.outputMode("complete") \
.option("checkpointLocation", "/Volumes/xxx_catalog/streaming_sample_1/stream_checkpoints/product_sales_counts_python") \
.table("product_sales_counts_python") \
.awaitTermination()
%sql
SELECT * FROM product_sales_counts_python
まとめ
以上がSparkのAPIを用いたストリームデータの処理方法の説明となります。詳細な実装方法は公式ドキュメントをご参照ください。気になった点、ミスなどあればコメントお願いします。