背景
文書(テキスト)間の類似度を計算する処理は、検索やレコメンドなど様々な分野で使われていると思います。
現在(2020年9月時点)、文書間の類似度を計算する方法は、次のようにコサイン類似度から計算する方法と、距離から計算する方法の大きく2種類に分類することができます。両者とも、単語の分散表現を利用するというのが前提にあります。
- 単語の分散表現を利用して文書をベクトル化し、そのベクトル空間上で文書間のコサイン類似度を計算する
- 文書に含まれる単語の分散表現をベクトル空間上にマッピングし、そのベクトル空間上で文書間の距離を計算する。
1の手法については、文書に含まれる単語の分散表現の(加重)平均を取り、各文書をベクトル化します。そして、そのベクトル空間上でコサイン類似度を計算するという手法です。クックパッドやマイクロアドをはじめ、実際のビジネスの現場でも幅広く使われています。
2の手法については、WMD(Word Mover's Distance)という手法が一番有名だと思います。まず、文書に含まれる単語の分散表現をベクトル空間上にマッピングします。そして、ある文書に含まれる単語群と別の文書に含まれる単語群の距離を計算し、距離の長さによって類似度を測るというものです。gensimにWMDを計算する関数が用意されており、比較的簡単に実装することができます。
WRDとは
WRDはWMDを改良したアルゴリズムで、東北大学の乾研究室が発表したものです。WRDの特徴は、単語の分散表現のノルムと偏角を分けて考えるというところにあります。具体的には、ノルムは単語の重要度を表し偏角は単語の意味を表すと考え、これらを別々に取り扱っています。別々に取り扱う方法については、論文に掲載されている下記の図をご覧頂ければイメージが付きやすいと思います。
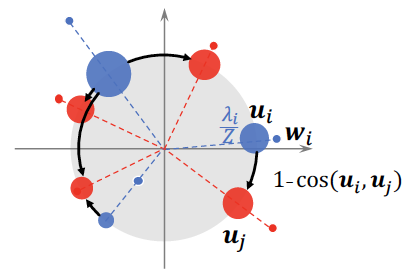
上記の図の通り、文書に含まれる単語の分散表現を超級平面上に射影します。その際、点の大きさをノルムに比例したものとします。こうすることで、重要度が高い単語は点が大きくなり、重要度が低い単語は点が小さくなります。そして、ある文書に含まれる単語群と別の文書に含まれる単語群のアライメント1を取るのに必要な力を距離、とWRDでは定義します。つまり、意味が異なる単語同士の場合であっても、重要度が高い場合は距離が長くなりますが重要度が低い場合は距離はさほど長くなりません。結果的に、意味が似ている文書間はWRDが小さくなり、意味が似ていない文書間はWRDが大きくなります。
詳細は論文をご覧下さい。繰り返しになりますが、単語の分散表現のノルムと偏角を分けて考えるというのは画期的な考え方だと思います。背景で紹介した文書のベクトル化でも、結局はノルムと偏角を混ぜて考えていますので。
WRDの実装
実装が公開されていなかったので、実装をGitHubに公開しました。是非、試してみて下さい。計算コストが高いという欠点はありますが、文書をベクトル化してコサイン類似度を計算するという方法よりも精度は高くなると思います。
-
単語と単語の対応関係を取ること ↩