Cloud Firestoreとは
Cloud Firestore(以下Firestore)はGoogleが提供しているNoSQLドキュメント指向データベースです。柔軟なデータ構造、高機能なクエリ処理、リアルタイムアップデート、オフラインサポートなどが特徴です。GCPとFirebaseから提供されています。GCPから提供されているバージョンでは、前のバージョンであるCloud Databaseとの互換性を持つDatastoreモードとネイティブモードを選択できます。Datastoreモードではいくつかの機能が制限されます。詳細はネイティブ モードと Datastore モードの選択 | Cloud Datastore ドキュメント | Google Cloud。
Firestoreを始める
ここではTypeScriptプロジェクトでFirestoreを始める方法を紹介します。
FirebaseコンソールでFirestoreを有効にしたら、プロジェクトのHTMLにスクリプトを追加します。
<script src="https://www.gstatic.com/firebasejs/5.10.1/firebase-app.js"></script>
<script src="https://www.gstatic.com/firebasejs/5.10.1/firebase-firestore.js"></script>
npmでインストールすることもできますが、上記のようにしておくことでアプリケーションとSDKのキャッシュを分けることが出来て便利です。
TypeScript用の型定義をインストールします。
$ npm i -D @firebase/app-types @firebase/firestore-types
次にアプリケーションの初期化時にFirestoreの初期化をします。HTMLに直接書いてしまっても問題ありません。
<script>
firebase.initializeApp({
apiKey: "### FIREBASE API KEY ###",
authDomain: "### FIREBASE AUTH DOMAIN ###",
projectId: "### CLOUD FIRESTORE PROJECT ID ###"
});
</script>
使用するときはFirestoreインスタンスを作成してメソッドを呼び出します。
// async関数を使用した例
(async () => {
try {
const db = firebase.firestore();
const docRef = await db.collection("users").add({
first: "Ada",
last: "Lovelace",
born: 1815
});
console.log("Document written with ID: ", docRef.id);
} catch (error) {
console.error("Error adding document: ", error);
}
})();
基本的なデータ構造
Firestoreのデータ構造はドキュメントとコレクションから構成されます。全てのドキュメントはコレクションの要素です。ドキュメントは、スキーマレスで、各ドキュメントにどのような値を入れるかは完全に自由に決めることができます。ドキュメントはJSONのようなものと考えると良いでしょう。コレクションには値を直接入れることは出来ません。また、コレクションをコレクションの要素にすることも出来ません。ドキュメントの配下にはコレクションを定義することができ、それをサブコレクションと呼びます。ドキュメントとサブコレクションは、関係を持っているだけで独立しており、ドキュメントを削除してもサブコレクションは削除されません。
データ型
ドキュメントのフィールドに使用できるデータ型がいくつか用意されています。詳細はサポートされているデータ型をご覧ください。
データの追加、読み取り
データの追加
データの追加は、CollectionReferenceのaddメソッドか、DocumentReferenceのsetで行います。最初に紹介したaddメソッドの用法は以下と等価です。
(async () => {
try {
const db = firebase.firestore();
const docRef = db.collection("users").doc(); // この時点ではまだ通信されない
await docRef.set({
first: "Ada",
last: "Lovelace",
born: 1815
});
} catch (error) {
console.error("Error adding document: ", error);
}
})();
docメソッドは引数に何も入れなければユニークなIDを返します。引数にIDを入れるとそのIDのDocumentReferenceを返します。DocumentReferenceを生成する段階では、通信は発生しません。
データの読み取り
ドキュメントを1回読み込む
(async () => {
try {
const db = firebase.firestore();
const docRef = docRef = db.collection("cities").doc("SF");
const docSnapshot = await docRef.get();
if (docSnapshot.exists) {
console.log("Document data:", doc.data());
} else {
console.log("No such document!");
}
} catch (error) {
console.log("Error getting document:", error);
}
})();
コレクションを1回読み込む
(async () => {
try {
const db = firebase.firestore();
const querySnapshot = await db.collection("cities").where("capital", "==", true).get();
querySnapshot.forEach((doc) => {
console.log(doc.id, " => ", doc.data());
});
} catch (error) {
console.log("Error getting documents: ", error);
}
})();
トランザクション
数値フィールドを取得してそれをインクリメントして保存したい場合などに、トランザクションを利用できます。トランザクションが失敗するとエラーが返されデータベースには何も書き込まれません。
アトミックオペレーション
一括書き込みを使用すると、複数のデータの作成、編集、削除を一括して行うことができます。一括書き込みには、最大500個の操作を含めることが出来ます。
詳細: 一括書き込み
セキュリティルール
セキュリティルールを使用すると、データベース内のドキュメントおよびコレクションへのアクセスを制御できます。以下はセキュリティルールの例です。
service cloud.firestore {
// よく使用する条件式はJavaScript風の関数にすることが出来ます。
function isSignedIn() {
return request.auth.uid != null;
}
match /databases/{database}/documents {
match /organizations/{organizationId} {
allow read: if isSignedIn();
allow create: if isSignedIn() && request.data.owners[request.auth.uid] == true;
allow update, delete: if isSignedIn() && resource.data.owners[request.auth.uid] == true;
}
}
}
request変数にはリクエスト内容が、resource変数には操作対象のドキュメントに関するデータが格納されています。
詳細: Cloud Firestore セキュリティ ルールを使ってみる | Firebase
データベース設計手法
画面から始める
データを正規化して読み取るデータを動的に決めることが出来るRDBでは、どのようなデータが返ってくるかはSQLを実行する時に初めて決定するので、データベースを設計する段階ではあまり意識しません。しかし、NoSQLでは高速化のためにデータは正規化せずにクライアントが欲しい状態で格納しておくのが一般的です。そのため、データベースを設計する段階でどのようなデータが必要か決めておく必要があります。
代表的なリレーションシップ
以下の記事では、Firestoreで実現出来るリレーションシップがまとめられています。
Cloud Firestoreを実践投入するにあたって考えたこと - Qiita
基本はサブコレクション
ほとんどのアプリケーションでは1:Nのデータ構造が必要になります。Firestoreで1:Nのデータ構造を表現する方法はいくつかありますが、最初に検討するのはサブコレクションです。ある親リソースに多数の子リソースを対応させたい場合で、親リソースの詳細画面でのみ子リソース一覧を表示させたい場合は、サブコレクションで要件を満たすことができます。サブコレクションのセキュリティルールは親リソースと共通化出来ます。(2019/5/16追記 間違いです。出来ません。再帰ワイルドカード構文で任意の深い階層のルールを一括で指定することは出来ます。詳細: 階層データ)

困ったらキー参照型モデル
全ての親リソースの子リソースを一覧して表示したいとします。この場合は、前項のサブコレクションでは対応できません。(後述するCollection Groupでは場合によって対応できます。)(2019/5/14追記 Collection Groupでもクエリでフィルタすることで対応できます)そのような要件が発生したら、子リソースをサブコレクションでは無く、親リソースと同じ階層のコレクションにします。そして、子リソースには親リソースの一意に識別できる情報(IDなど)をフィールドとして持たせます。この方法でも1:Nのデータ構造を実現できます。
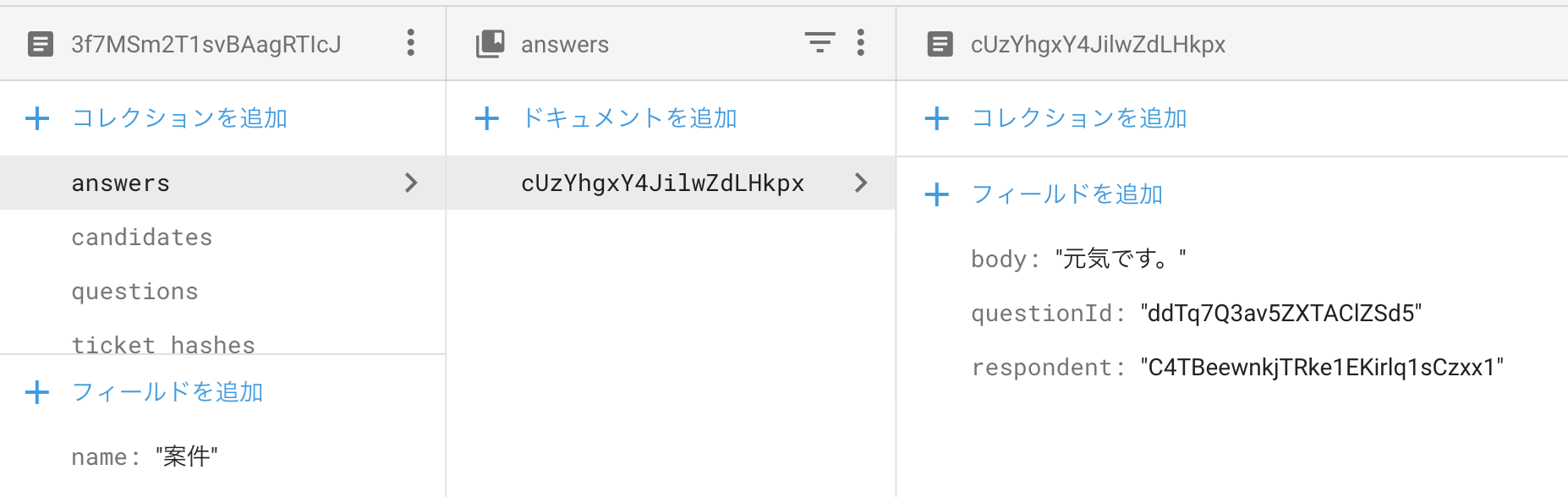
サブコレクションのメリット
ここまで聞くと、サブコレクションを使用するメリットがあまり感じられないかもしれません。サブコレクションのメリットは取得する時点で全ての親リソースのIDに矛盾がないことが保証されている点です。どういうことか例を見てみましょう。
ブログシステムのデータ構造を考えます。システムにはUserモデル、Postモデル、Commentモデルがあります。PostモデルはUserモデルと1:N(=User:Post)の関係で、CommentモデルはPostモデルと1:N(=Post:Comment)の関係にあります。
サブコレクションで概念的に表すと以下のようになります。角括弧はコレクションを、波括弧はドキュメントを表しています。
user: [
{
name: "Alice",
post: [
{
title: "Hello",
body: "Hi. My name is Alice.",
comment: [
{
body: "Hi. My name is Bob.",
}
]
}
]
}
]
一方キー参照モデルで表すと以下のようになります。
user: [
{
id: "user_1",
name: "Alice"
}
]
post: [
{
id: "post_1",
title: "Hello",
body: "Hi. My name is Alice.",
author: "user_1"
}
]
comment: [
{
id: "comment_id",
body: "Hi. My name is Bob.",
post_id: "post_1",
}
]
このようなデータ構造の時に、コメントの詳細画面を作成したいとします。サブコレクションで構築した場合は、/users/${user_1}/posts/${post_1}/comments/${comment_id}というパスで取得することが出来ます。キー参照モデルでは、/comments/${comment_id}というパスで取得することが出来ます。
ここで、親リソースも全て取得して表示したいという要件が発生したとします。サブコレクションで構築した場合は、コメントを取得する前の段階で親リソースのIDが全て分かっているのでコメントと同時に親リソースも取得できます。しかし、キー参照モデルではコメントを取得した後でないとポストのIDがわかりません。さらに、ポストを取得した後でないとユーザーのIDがわかりません。全ての親リソースを取得するためには「Commentを取得→Postを取得→Userを取得」といったように、順番にリクエストを送る必要があるのです。URLに親リソースのIDをパラメータとして付与すればいいじゃないかと思うかもしれませんが、キー参照モデルだと取得した親リソースたちのIDを確かめて本当に親なのか確認する処理を書かなければいけません。サブコレクションで構築した場合には、親リソースたちのIDを含めて子リソースのIDになっていると考えることができるため、親リソースが本当の親であるか確認する必要が無いのです。
1:1のデータ構造
Firestoreではフィールド毎にセキュリティルールを設定することが出来ません。そのような要件が発生したら別のコレクションに分けましょう。別のコレクションに分けるドキュメントを同一のIDにすると、クエリを使用しなくても取得することができます。これは2つのコレクション間で考えると、1:1のデータ構造を定義していることになります。クエリを使用できないセキュリティルールの中では、このような手法で別のドキュメントにアクセスします。

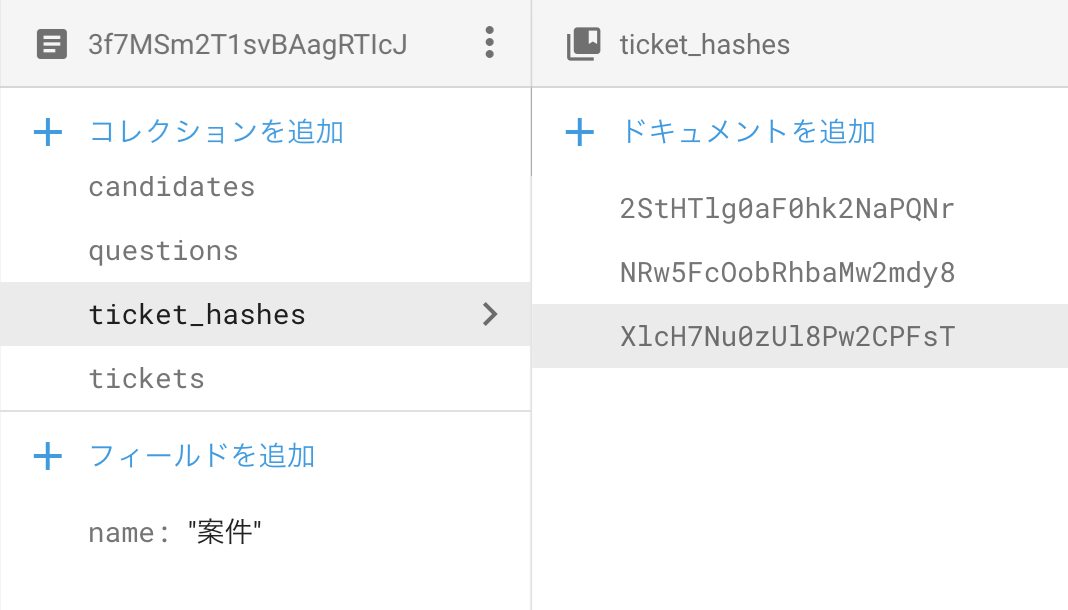
Cloud Functionsから操作する
Cloud FunctionsからAdmin SDKを使用してFirestoreを操作することで自由度の高い設計をすることができます。Admin SDKからFirestoreを操作する場合、セキュリティルールは適用されないので、アクセスコントロールが必要な場合は、自前でCloud Functionsの関数内にその処理を書かなければいけません。
ハッシュ値を計算して格納
例えばFirestoreに格納されたパスワードのハッシュ値をユーザーが入力したパスワードと比較したい場合などは、Firestoreだけでは実現できません。パスワードのハッシュ値を読み出し可能にするわけにはいかないからです。また、ハッシュ値の計算をクライアントで行うのも危険です。このような認証機能はCloud FunctionsなどからAdmin SDKを使用して、クライアントから操作不可能なコレクションを操作して行います。
以下はCloud Functionsからパスワードのハッシュ値を計算してFirestoreに格納する例です。
import * as functions from 'firebase-functions';
import * as admin from "firebase-admin";
import * as bcrypt from "bcryptjs";
admin.initializeApp({
credential: admin.credential.applicationDefault(),
databaseURL: "### FIREBASE DATABASE URL ###",
projectId: "### FIREBASE PROJECT ID ###"
});
const fn = functions.region("asia-northeast1");
const db = admin.firestore();
const ORGANIZATIONS = "organizations";
const PROJECTS = "projects";
const TICKETS = "tickets";
const TICKET_HASHES = "ticket_hashes";
const CANDIDATES = "candidates";
export const createTicket = fn.https.onCall(async (data, context) => {
if (context.auth == null || context.auth.uid == null) {
throw new functions.https.HttpsError("unauthenticated", "unauthenticated error");
}
try {
const organizationSnapShot = await db
.collection(ORGANIZATIONS)
.doc(data.params.organizationId)
.get();
const organization = organizationSnapShot.data();
if (organization == null) {
throw new functions.https.HttpsError("not-found", "organization not found");
}
if (!organization.owners[context.auth.uid]) {
throw new functions.https.HttpsError("permission-denied", "permission denied");
}
} catch (error) {
throw new functions.https.HttpsError("internal", "internal server error");
}
try {
const salt = await bcrypt.genSalt(10);
const hash = await bcrypt.hash(data.password, salt);
const ticketRef = db
.collection(ORGANIZATIONS)
.doc(data.params.organizationId)
.collection(PROJECTS)
.doc(data.params.projectId)
.collection(TICKETS)
.doc();
const ticketHashRef = db
.collection(ORGANIZATIONS)
.doc(data.params.organizationId)
.collection(PROJECTS)
.doc(data.params.projectId)
.collection(TICKET_HASHES)
.doc(ticketRef.id);
const batch = db.batch();
batch.set(ticketRef, {
status: "unused"
});
batch.set(ticketHashRef, {
hash
});
await batch.commit();
const documentSnapshot = await ticketRef.get();
return {
id: documentSnapshot.id,
...documentSnapshot.data(),
};
} catch (error) {
console.error(error);
throw new functions.https.HttpsError("internal", "internal server error");
}
});
Collection Group
Collection Groupという機能を使用するとサブコレクションを含む特定のコレクションIDのコレクションを、データベース全体から取得することができます。一見便利そうですが、特定のコレクション配下の特定のコレクションIDのコレクションだけを取得したいといったことは出来ないため、用途は限定的です。
2019/5/14追記
出来るみたいです><
https://qiita.com/keito_jp/items/3a9a14c9e0fb951152f7#comment-d7326b01e5eb0ca7e8f6