環境
macOS Catalina 10.15.1
やってみたこと
- Dockerfile で DB サーバー (PostgreSQL) と分析サーバー (jupter notebook) のイメージを取得
- Docker compose で docker file を連結
- DB サーバーから取得したデータで K-Means 法を実施
- 分析データを DB サーバーへ保存
フォルダの構成
docker-compose.yml が docker compose 起動時に起点となる。
このコードをもとに、他のファイルは参照される。
(root)
|--.env
|--run.ipynb
|--docker-compose.yml
|--Dockerfile-db
|--Dockerfile-jupyter
|--input_data
| |--iris.csv
|--scripts
| |--initdb
| | |--01_init_database.sql
| | |--02_init_table.sql
docker-compose.yml
docker-compose.yml は、tab キーでインデントを作ると読み込まれないので注意。
インスタンスや環境変数を別のファイルに作ることで、イメージの追加や起動時の設定などを環境に合わせてカスタマイズできる。
version: '3'
services: #生成されるインスタンスをそれぞれ定義
db:
env_file: ./.env #別のファイルで環境変数を定義
build:
context: .
dockerfile: ./Dockerfile-db #別の dockerfile でイメージを定義
volumes: #PostgreSQL の保存先を定義
- ./pgdata_store:/var/lib/postgresql/data
- "${SCRIPTS_SRC}:/opt/analysis"
restart: always
ports:
- "5432:5432"
networks: #jupyter と連結するために宣言
- mlnet
environment:
- POSTGRES_USER=${DB_USER}
- POSTGRES_PASSWORD=${DB_PASSWORD}
jupyter:
env_file: ./.env
build:
context: .
dockerfile: ./Dockerfile-jupyter
restart: always
volumes:
- "${SCRIPTS_SRC}:/opt/analysis"
depends_on:
- db
ports:
- "8888:8888"
networks: #Postgres と連結するために宣言
- mlnet
volumes:
pgdata_store:
driver: local
networks: #bridge はホストの任意のポートをコンテナのポートにマップできる。
mlnet:
driver: bridge
.env
# docker-compose.yml にて利用する環境変数を定義
COMPOSE_PROJECT_NAME=ml
# DB 接続情報
DB_HOST=db
DB_PORT=5432
DB_NAME=analysis
DB_USER=postgres
DB_PASSWORD=postgres
# volume mount
SCRIPTS_SRC=./
# Jupyter インスタンスにて利用する環境変数を定義
NOTEBOOK_PASSWORD=analysis
# タイムゾーンの設定
TZ=Asia/Tokyo
# 言語指定。文字化けを防ぐ。
LANG=ja_JP.utf8
Dockerfile-db
# 公式イメージを取得
FROM postgres:11.2-alpine
# Docker 起動時に実行される scripts をコンテナのディレクトリへコピー
COPY scripts/initdb/* /docker-entrypoint-initdb.d/
scripts/initdb/* は 01_init_database.sql (database の生成)および 02_init_table.sql (データ定義言語:DDL の設定)を指す。
ファイル名に数字の prefix を付けることで、その数字の順番に実行されるようになる。
01_init_database.sql
CREATE DATABASE "analysis" encoding "UTF8";
02_init_table.sql
# 01_init_database.sql で作成した analysis database に入る
\c analysis
# 作成済みの table を消しておく
DROP TABLE IF EXISTS iris_input;
DROP TABLE IF EXISTS iris_cluster;
# 入力データ用 table を作成する
CREATE TABLE iris_input(
id serial NOT NULL,
data_version varchar(16) NOT NULL,
sepal length numeric NOT NULL,
sepal width numeric NOT NULL,
petal length numeric NOT NULL,
petal width numeric NOT NULL,
create_timestamp TIMESTAMP NOT NULL,
primary key(id, data_version)
);
# 分析済みデータ用 table を作成する
CREATE TABLE iris_cluster(
id serial NOT NULL,
data_version varchar(16) NOT NULL,
cluster_id numeric NOT NULL,
pca1 numeric NOT NULL,
pca2 numeric NOT NULL,
create_timestamp TIMESTAMP NOT NULL,
primary key(id, data_version)
);
初期設定の table に入力できるのは、ここで設定した column のみ。
存在しない column は修正・追加する必要がある。
column 名を間違えると table に入力できない。
Dockerfile-jupyter
FROM jupyter/scipy-notebook:65761486d5d3
USER root
# pip で必要なパッケージをインストールするために OS のパッケージマネージャーを最新化
RUN apt-get update
RUN apt-get install -y python3-dev libpq-dev
# Python の開発ツールと PostgreSQL のパッケージをインストール
RUN pip install --upgrade pip \
&& pip install ipython-sql \
&& pip install psycopg2 \
&& pip install sqlalchemy
# Jupyter アクセス時のパスワードと、Jupyter 実行時のルートディレクトリを設定
CMD jupyter notebook --allow-root --NotebookApp.token="$NOTEBOOK_PASSWORD" /opt/analysis
コンテナの起動
この節のコマンドはターミナルで実行する。
ルートディレクトリで次のコマンドを実行し docker-compose.yml から docker image を作成する。
docker-compose build
次のコマンドで docker インスタンスを起動する。
docker-compose up -d
次のコマンドでインスタンスの起動状態を確認する。
docker-compose ps
以下のように ml_db_1 と ml_jupyter_1 の state が Up となっていれば成功している。
Name Command State Ports
------------------------------------------------------------------------------
ml_db_1 docker-entrypoint.sh postgres Up 0.0.0.0:5432->5432/tcp
ml_jupyter_1 tini -g -- /bin/sh -c jupy ... Up 0.0.0.0:8888->8888/tcp
ブラウザで http://localhost:8888 にアクセスすると、jupyter notebook のログイン画面が表示される。以下 jupyter notebook で作業する。
データの取得
jupyter notebook でアイリスのがく(sepal)と花びら(petal)のデータを取得する。
from sklearn.datasets import load_iris
import pandas as pd
from sklearn.datasets import load_iris
import pandas as pd
ds = load_iris()
df = pd.DataFrame(ds.data, columns = ds.feature_names)
df['species'] = ds.target
df.loc[df['species'] == 0, 'species'] = "setosa"
df.loc[df['species'] == 1, 'species'] = "versicolor"
df.loc[df['species'] == 2, 'species'] = "virginica"
df = df.reset_index()
df = df.rename(columns = {'sepal length (cm)':'sepal_length', 'sepal width (cm)':'sepal_width', 'petal length (cm)':'petal_length', 'petal width (cm)':'petal_width', 'index':'id'})
df['data_version']=1.0
df.head()
以上のコードを実行すると、次のような dataframe が得られる。

初期データなので data_version 1.0 である。これ以後に追加されたデータは ver. 2.0 とする。
次のコマンドで csv ファイルとして保存する。
df.to_csv('./input_data/iris.csv')
PostgreSQL への入力
先ほど取得した csv ファイルを読み込む。
import pandas as pd
iris = pd.read_csv('./input_data/iris.csv', index_col=0)
iris.head()
保存前に次のコマンドで現在時刻を取得しておく。データをいつ保存したのかを明記しておく。
iris['create_timestamp']= pd.datetime.now()
PostgreSQL との接続ドライバーである engine を取得する。
pgconfig は、os パッケージの機能を利用して .env に登録した環境変数から読み込むようにしている。
from sqlalchemy import create_engine
import os
pgconfig = {'host':os.environ['DB_HOST'],
'port': os.environ['DB_PORT'],
'database': os.environ['DB_NAME'],
'user': os.environ['DB_USER'],
'password': os.environ['DB_PASSWORD']
}
engine = create_engine('postgresql+psycopg2://{user}:{password}@{host}:{port}/{database}'.format(**pgconfig))
engine
次の engine が得られていれば成功である。
Engine(postgresql+psycopg2://postgres:***@db:5432/analysis)
次のコードで、取得したデータを PostgreSQL に保存する。
from sqlalchemy import create_engine
# database に登録する column を選ぶ。
# 02_init_table.sql で定義した column 名と一致させること。
columns = ['id',
'data_version',
'sepal_length',
'sepal_width',
'petal_length',
'petal_width',
'create_timestamp']
# if_exists を replace にすると先行データと置換される。
iris[columns].to_sql('iris_input', engine, if_exists='append', index=False)
PostgreSQL からの読み込み
Jupyter notebook に以下のコードを打ち database と接続する。
# SQL の拡張機能を呼び出す
%load_ext sql
# DB 接続に必要な engine を取得
dsl = 'postgres://{user}:{password}@{host}:{port}/{database}'.format(**pgconfig)
# sql に接続
%sql $dsl
以下のコードで接続情報を読み込む。
# PostgreSQL の table を pandas の dataframe として取得することを定義
%config SqlMagic.autopandas = True
# iris_inout table の全 column を取得
df_input = %sql select * from iris_input
df_input.head()
以下のような dataframe が得られていれば成功している。

K-means 法
Dataframe から分析対象の特徴量(アイリスのサイズデータ)を抽出する。
df_src = df_input[['sepal_length', 'sepal_width', 'petal_length', 'petal_width']]
df_src.head()
sklearn ライブラリで K-mean 法を実施する。
n_cluster でクラスタ数を決める。今回は 3 クラスタに分割する。
from sklearn.cluster import KMeans
kms = KMeans(n_clusters=3, random_state=1)
clusters = kms.fit_predict(df_src)
clusters
次のように、0,1,2 にクラスタリングしていれば成功している。
array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 2, 2, 2, 2, 0, 2, 2, 2,
2, 2, 2, 0, 0, 2, 2, 2, 2, 0, 2, 0, 2, 0, 2, 2, 0, 0, 2, 2, 2, 2,
2, 0, 2, 2, 2, 2, 0, 2, 2, 2, 0, 2, 2, 2, 0, 2, 2, 0], dtype=int32)
主成分分析(PCA)により、4特徴量を2次元に圧縮する。
from sklearn.decomposition import PCA
pca = PCA(n_components=2, random_state=1)
pca_values = pca.fit_transform(df_src)
2次元データとクラスタリング結果を df_plot にまとめ、 seanborn を使って散布図にプロットする。
%matplotlib inline
import seaborn as sns
df_plot = df_pca.assign(cluster_id=clusters)
sns.lmplot(x='pca1', y='pca2', data=df_plot, hue='cluster_id',markers=['o','s','+'], fit_reg=False)
次のように描画できていれば成功している。

Fit_reg を True にすると線形回帰が実施される。今回は関係ないため False に設定している。
エルボー法
k-mean 法ではクラスタ数が多すぎると過学習が生じる。適切なクラスタ数を決めるために、エルボー法が用いられることがある。
次のコードで、クラスタ数 1~10 における距離の総和をdist_sums というリストにまとめる。
# エルボー法のコード
from sklearn.cluster import KMeans
dist_sums = []
for cluster_cnt in range(1,10):
kms = KMeans(n_clusters=cluster_cnt,random_state=1)
kms.fit_predict(df_pca)
dist_sums.append(kms.inertia_)
次のコードで可視化する。
# 結果の可視化
%matplotlib inline
import matplotlib.pyplot as plt
plt.plot(range(1,10), dist_sums)
plt.xlabel('Num Cluster')
plt.ylabel('Distance')
次のような描画が成功していれば成功している。
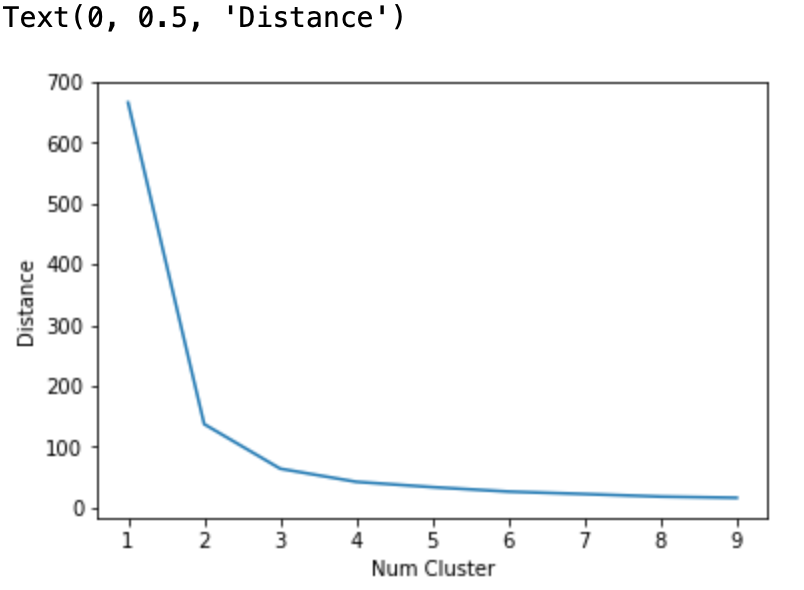
距離の総和の減少速度が急激に小さくなるクラスタ数4以上では過学習が生じていると考えられる。今回はクラスター数3が適切であった。
分析データの保存
分析結果に id と data_version を加える。
df_save_target = df_plot.assign(id=df_input[['id']], data_version=df_input[['data_version']])
分析結果を PostgreSQL へ保存する。
df_save_target[['id','data_version','pca1','pca2','cluster_id']].to_sql('iris_cluster',engine, if_exists='append', index=False)
データベース Table の管理コマンド
Jupyter notebook でデータベースを管理できる。
- iris_cluster の先頭10サンプルにおける pca1、pca2 を取得
%sql select pca1,pca2 from iris_cluster limit 10;
- numeric 型の test column を追加。デフォルト値は NULL
%sql ALTER TABLE iris_input ADD test numeric NULL;
- timestamp 型の test2 column を追加。デフォルト値は現在時刻
%sql ALTER TABLE iris_input ADD test2 TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP;
- iris_input の sepal_length が 3 未満のサンプルを取得
%sql SELECT * FROM iris_input WHERE 3 > sepal_width limit 10;
参考
参考:データ収集からWebアプリ開発まで実践で学ぶ機械学習活用ガイド の chapter 4