はじめに
こんにちは、京セラコミュニケーションシステム 川村(@kccs_takahiro-kawamura)です。
みなさん、データ分析をしなければならないがそのために必要なデータをどのように収集するか悩んだことはありませんか?
本記事では、Google Cloudのアーキテクチャである Cloud Run Jobs と BigQuery を活用し、REST APIを用いて定期的にデータを収集する方法について解説します。
本記事は、2022年11月ごろに作成しております。よって、引用している文章などはこの時点での最新となります。ご了承ください。
本記事は、asia-northeast1リージョンを使用します。
本記事の対象者
- データ分析を試したいが、イメージの沸きやすい日本の公開データが見つからない方
- REST APIで取得できるデータを BigQuery へデータを蓄積したいが方法がわからない方
- Cloud Run Jobs を試してみたい方
収集するデータ
今回は、オープンデータを収集対象にします。
オープンデータとは、「政府、独立行政法人、地方公共団体等が保有する公共データを、機械判読に適したデータ形式で、営利目的も含めた二次利用が可能な利用ルールで公開されたデータ」のことを指します。
オープンデータはさまざまなWebサイトで公開されています。本記事では、公共交通オープンデータセンターで公開されているドコモ・バイクシェアのデータを BigQuery へ取り込みます。
REST API形式のオープンデータの取得
今回は、APIでデータの取得ができるため下記のスクリプトを用いてデータを取得したいと思います。
import json
import os
import webbrowser
import urllib3
from google.cloud import bigquery
api_token = os.environ.get('API_TOKEN')
api_name = os.environ.get('API_NAME')
table_id = os.environ.get('TABLE_ID')
api_url = f'https://api.odpt.org/api/v4/gbfs/docomo-cycle-tokyo/{api_name}.json?acl:consumerKey={api_token}'
def get_stations(api_url):
http = urllib3.PoolManager()
response = http.request('GET', api_url)
json_response = json.loads(response.data)
stations = json_response['data']['stations']
client = bigquery.Client()
errors = client.insert_rows_json(table_id, stations)
if errors == []:
print("Success")
else:
print(errors)
return
def main():
get_stations(api_url)
if __name__ == '__main__':
main()
API_NAMEにはstation_informationとstation_statusを指定します。。
station_informationは、自転車置き場のマスタデータです。APIで取得した内容は下記のようになります。
{
"ttl": 60,
"data": {
"stations": [
{
"lat": 35.693799,
"lon": 139.753281,
"name": "A1-01.千代田区役所",
"capacity": 8,
"region_id": "1",
"station_id": "00010001"
},
{
"lat": 35.701073,
"lon": 139.747525,
"name": "A1-03.東京区政会館(メトロA5出口)",
"capacity": 6,
"region_id": "1",
"station_id": "00010003"
},
~省略~
]
},
"version": "2.3",
"last_updated": 1666221183
}
一方、station_statusは自転車置き場の状態を表すデータです。APIで取得した内容は下記のようになります。
{
"ttl": 60,
"data": {
"stations": [
{
"is_renting": true,
"station_id": "00010001",
"is_installed": true,
"is_returning": false,
"last_reported": 1666225443,
"num_bikes_available": 7,
"num_docks_available": 0
},
{
"is_renting": false,
"station_id": "00010138",
"is_installed": true,
"is_returning": true,
"last_reported": 1666225443,
"num_bikes_available": 0,
"num_docks_available": 6
},
~省略~
]
},
"version": "2.3",
"last_updated": 1666225443
}
station_informationはマスタデータのため頻繁な取り込みは必要ありませんが、station_statusはトランザクションデータのためデータ分析として活用するためには頻繁に取り込む必要があります。
定期的なデータの取り込みジョブを作成
station_statusを定期的に BigQuery へ取り込むためにこのスクリプトをバッチにします。今回は、Google Cloudの Cloud Run Jobs を使用します。
Cloud Run Jobs を使用するためには先ほどのスクリプトをコンテナイメージにする必要があります。
下記の手順を実行することで、コンテナイメージを作成しContainer Registryにアップロードします。
- jobsディレクトリを作成し、そのディレクトリに移動します。
- 上記スクリプトを
main.pyとして保存します。 -
Procfileを下記の内容で作成します。web: python3 main.py -
requirements.txtを下記の内容で作成します。urllib3 == 1.26.12 google-cloud-bigquery == 3.3.5 - コンテナイメージを作成しレジストリにアップロードします。
gcloud builds submit --pack image=gcr.io/[PROJECT_ID]/[JOB_NAME]
無事に成功するとコマンドラインにSTATUS: SUCCESSという標準出力があり、Container RegistryにJOB_NAMEで指定したフォルダーができています。
続いて、Google CloudのコンソールでCloud Runを開きます。ジョブ に切り替え、[ジョブを作成]を選択しフォームに必要事項を入力します。
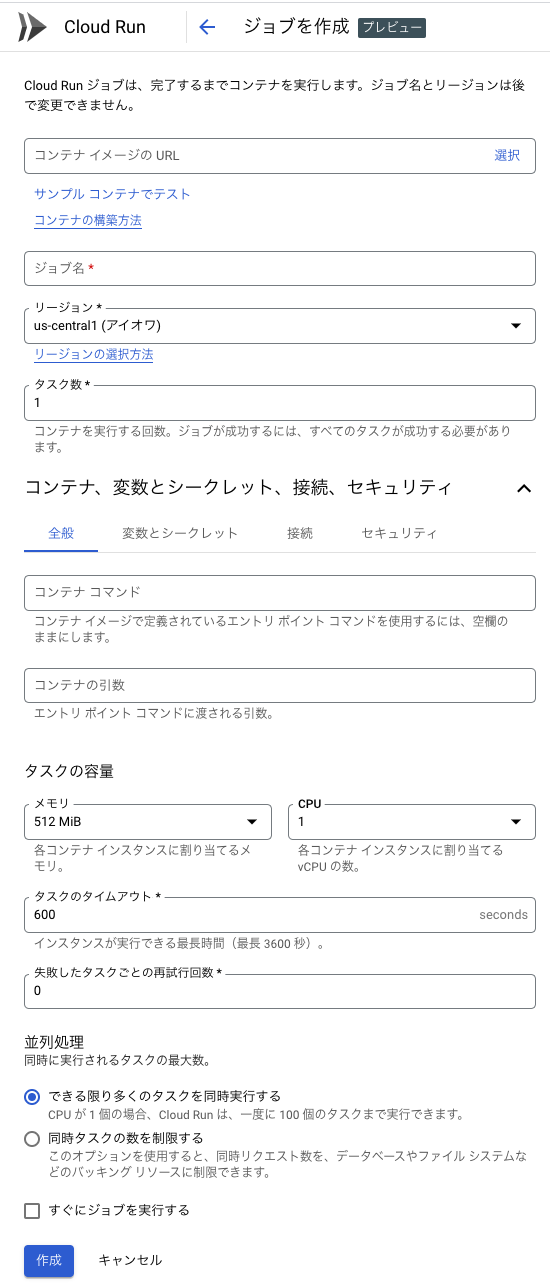
サービスアカウントには、データを挿入するテーブルに対して書き込み権限が必要です。
BigQuery のテーブルは、下記のとおりに作成します。パーティショニングは 取り込み時間による分割 でパーティショニングタイプは 1時間ごと を指定します。
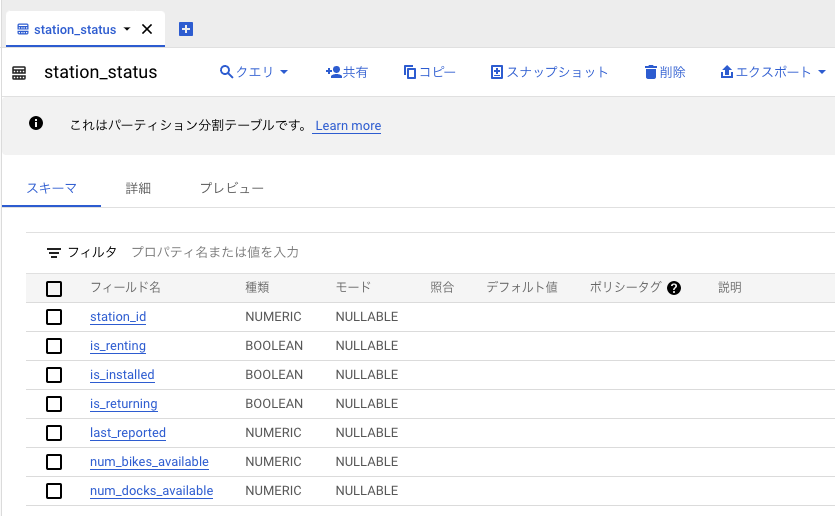
ジョブを作成した後は、ジョブを実行し処理が成功することを確認してください。
ジョブの実行スケジュールを設定
上記で作成したジョブに実行スケジュールを設定します。実行スケジュールは、 Cloud Scheduler を使用します。
Google CloudのコンソールでCloud Schedulerを開きます。[ジョブを作成]を選択しフォームに必要事項を入力します。
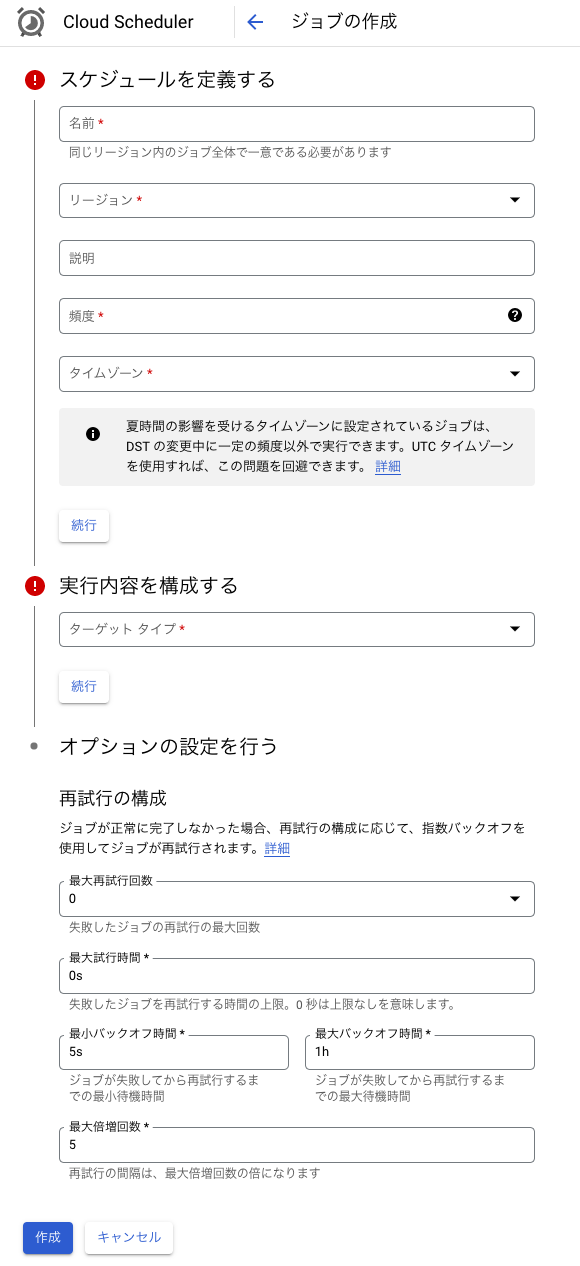
今回は、1時間ごとにデータを取り込みたいため 頻度 を0 * * * *とします。
ターゲットタイプは、HTTPを指定します。HTTPを指定すると下記のフォームが追加されるためこちらも必要事項を入力します。
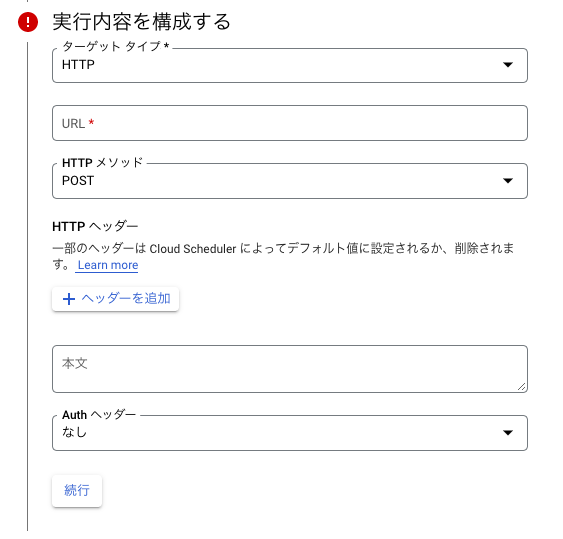
URL は、https://asia-northeast1-run.googleapis.com/apis/run.googleapis.com/v1/namespaces/[PROJECT-ID]/jobs/[JOB-NAME]:runを指定します。
HTTPメソッド は、POSTを指定します。
Authヘッダー は、OAuthトークンを追加を選択します。さらに、サービスアカウント と 範囲 が追加されるため サービスアカウント のみ追加入力します。
サービスアカウント は、トリガーするCloud RunジョブのCloud Run起動元ロール、またはプロジェクトのCloud Run管理者、編集者、オーナーのロールを持つサービス アカウントを選択します。
すべて項目の入力が完了したら[作成]を選択します。
スケジュールジョブが作成できたら 操作 から[ジョブを構成実行する]を選択し無事に処理が成功することを確認してください。

ジョブが無事に成功している場合は、Cloud Run Jobs の履歴が下記のようになります。
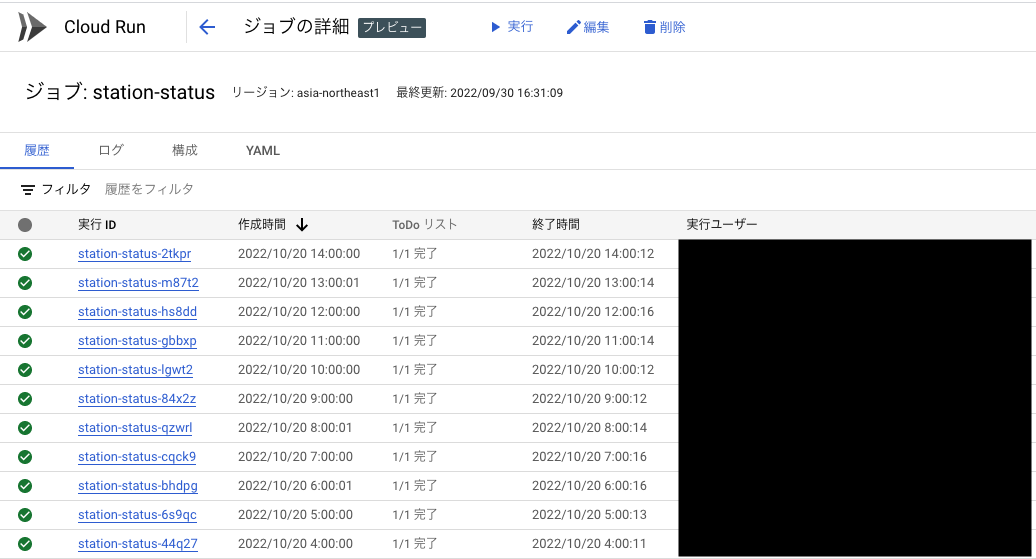
BigQuery のテーブルにもデータが追加されています。
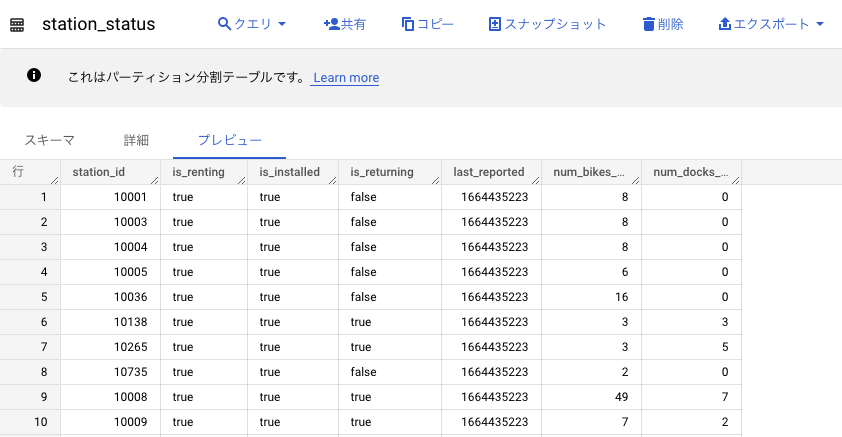
以上で、オープンデータを定期的に BigQuery へ取り込むことができるようになりました。
最後に
本記事では、オープンデータをREST API経由で取得し BigQuery に取り込むバッチ、 Cloud Run Jobs を用いて実現しました。
Cloud Run Jobs は、HTTPのエンドポイントを持っていますがWebフレームワークを用いて実装する必要がないため、比較的簡単に開発でき、開発にかかる時間が短くなると思います。
ただし、 Cloud Run Jobs は、本記事の執筆時点でプレビュー版の機能となっていますので利用する際はその旨に注意してください。
次回は、蓄積されたデータを用いてデータ活用した結果をデータポータルで可視化したいと思います。