はじめに
こんにちは、京セラコミュニケーションシステム 西田(@kccs_hiromi-nishida)です。
Excelファイルで作成された表形式のデータをそのままBigQueryに取り込みたいと思ったとき、毎回手作業でCSVファイルに変換したり、CSVファイルを手作業でBigQueryに取り込むのは面倒ですよね。
できればシームレスに一連の処理を実行したい!
今回、ExcelファイルをCloud Storageにアップロードし、Cloud FunctionsでCSVファイルに変換してBigQueryに連携するという一連の処理を作成してみたので、ご紹介します。
本記事は2023年3月ごろに作成しております。よって、引用している文章などはこの時点での最新となります。ご了承ください。
この記事の対象者
- ExcelファイルをCSVファイルに変換しBigQueryに連携してみたい方
- Cloud Functionsによる自動化に興味のある方
処理の構成

ExcelファイルをCloud Storageにアップロードすると、それをトリガーとしてCloud Functionsが実行され、ExcelファイルをCSVファイルに変換します。
そのCSVファイルをBigQueryの外部テーブルとして登録しておくという流れになります。
前提
Google Cloudの利用開始がまだの方は以下サイトより利用登録を行うことができます。
[参照]公式サイト・ドキュメント
無料トライアルと無料枠
上記サイトの「無料で開始」ボタンから登録が可能
Google Cloud の無料プログラム
Google Cloudの無料プログラムの詳細を確認できます
バケットの作成
使用画像について
画像はGoogle Cloud - Cloud Storage画面をキャプチャしたものとなります
Excelファイルをアップロードするバケットと変換したCSVを配置するバケットをそれぞれCloud Storageに作成します。
Google Cloudにアクセスしてハンバーガーメニューを開き、Cloud Storage ⇒ バケットを選択します。

画面上部の[作成]を選択してください。

バケットの名前を入力し、[続行]を選択してください。

ロケーションタイプは今回Regionとし、asia-northeast1を選択しました。
[続行]を選択してください。

後の項目はとくに変更の必要はないので、[続行]を選択していき、最後[作成]を選択してください。バケットが作成されました。

同じ手順でもう1つ、CSVファイルを配置するバケットを作成しておきます。

アップロードするExcelファイルについて
今回、以下のルールでExcelファイルが作成されている前提で変換処理を作成します。
- アップロードするExcelのデータは表形式であること
- シート名が同じであること
今回は観光庁より公表されている宿泊旅行統計調査1から、各都道府県ごとの年間のべ宿泊者数と宿泊者の居住地(県内か県外)をピックアップしてサンプルを作成しました。
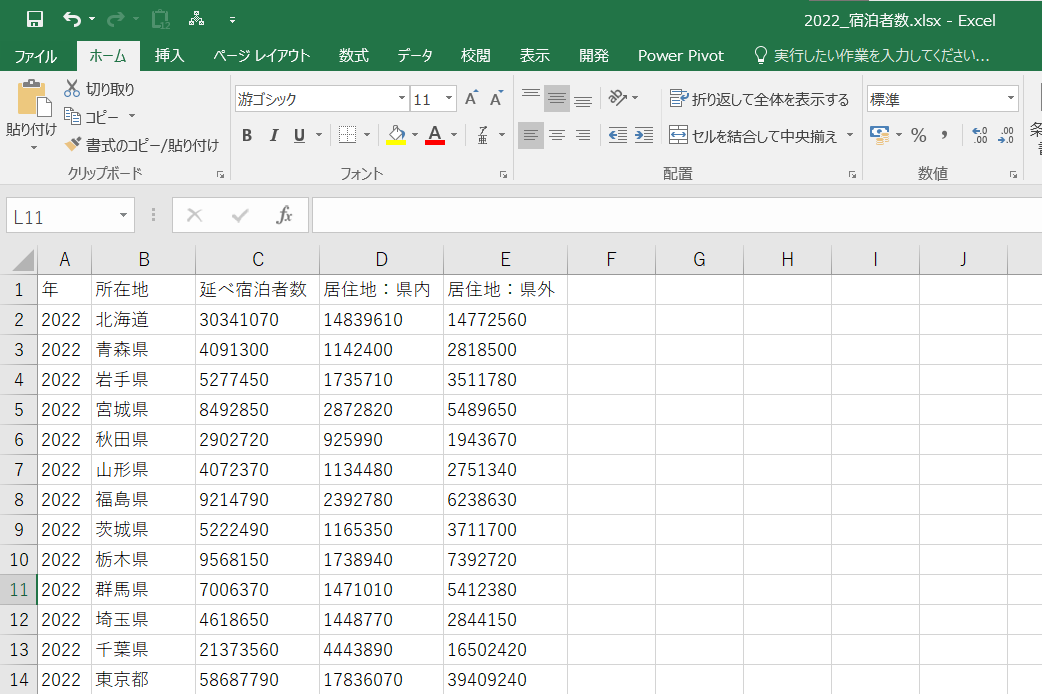
このレイアウトのExcelファイルを2022年、2021年、2020年の3ファイル準備しました。
(シート名はすべて"データ連携"で統一)
このように同じレイアウト・同じシート名で作成されたExcelファイルを、Cloud Functionsで1ファイルのCSVファイルに変換する処理を作成します!
Cloud Functionsの作成
では、Cloud StorageへのアップロードをトリガーにCSVファイル変換処理を行うCloud Functionsを作成していきましょう。
今回はCloud Functionsの第1世代+Pythonで開発します。
使用画像について
画像はGoogle Cloud - Cloud Functions画面をキャプチャしたものとなります
イベントの作成
サーバレス → Cloud Functionsを選択します。

関数の作成を選択します。

作成画面で画像のように入力・選択します。
- トリガーのタイプ:Cloud Storage
- Event type:選択したバケット内のファイル(最終処理/作成)
- バケット:先ほど作成したExcelファイルをアップロードするバケット
上記を指定することで、指定したバケットにファイルが新規作成もしくは上書きされたことをトリガーに処理を実行するプログラムを作成できます。

保存を選択し、[次へ]を選択してください。
コードの作成
続いてコードを作成します。
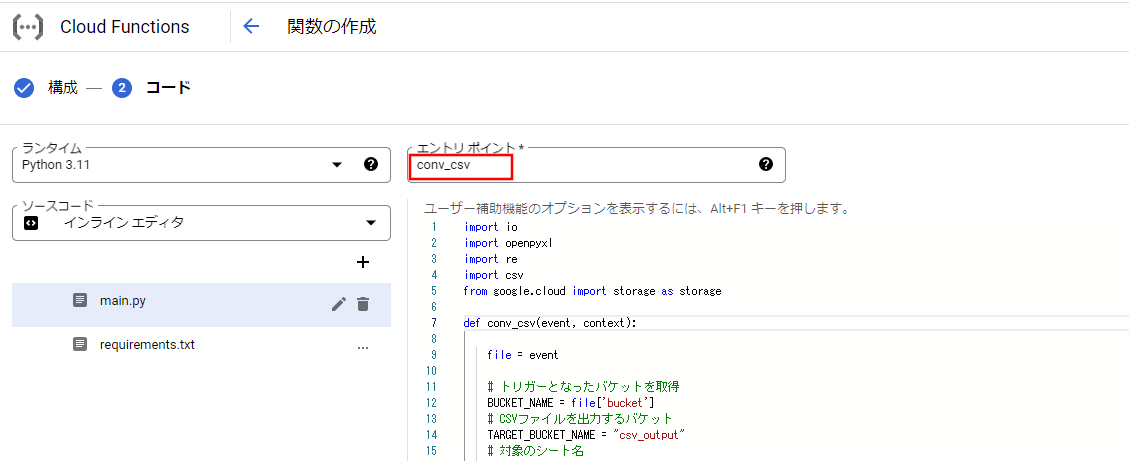
ランタイムは今回、Python 3.11を選択しました。
まず、必要なライブラリを定義します。requirements.txtを選択し、以下を貼り付けます。
openpyxl==3.*
google-cloud-storage

次に処理をmain.pyに記述します。
以下のコードを貼り付け、エントリポイントを[conv_csv]に変更し、デプロイを選択してください。
※長いので折りたたんでいます。クリックすると展開します。
プログラムコード
import io
import openpyxl
import re
import csv
from google.cloud import storage as storage
def conv_csv(event, context):
file = event
# トリガーとなったバケットを取得
BUCKET_NAME = file['bucket']
# CSVファイルを出力するバケット
TARGET_BUCKET_NAME = "csv_output"
# 対象のシート名
TARGET_SHEET_NAME = "データ連携"
OUT_NAME = 'merge.csv'
client = storage.Client()
# バケットの取得
bucket = client.get_bucket(BUCKET_NAME)
# バケット内のオブジェクト一覧を取得
blobs = client.list_blobs(BUCKET_NAME)
# 取得対象行(ヘッダーは不要なので2行目から)
start_row = 2
pattern = r".*\.(xlsx|xls)$"
si = io.StringIO()
writer = csv.writer(si, quoting=csv.QUOTE_ALL)
for blob in blobs:
# .xlsx,.xlsファイルだけを処理対象とする
if re.match(pattern, blob.name, re.IGNORECASE):
buffer = io.BytesIO()
blob.download_to_file(buffer)
wb = openpyxl.load_workbook(buffer)
if TARGET_SHEET_NAME in wb.sheetnames:
targetSheet = wb[TARGET_SHEET_NAME]
# 対象シートの最大行数・最大列数を取得
max_column = targetSheet.max_column
max_row = targetSheet.max_row
# 開始行~最大行までループしながら1~最大列数分の値を取得して書き込み
for r in range(start_row, max_row+1):
row_data = []
for c in range(1, max_column+1):
row_data.append(targetSheet.cell(row=r, column=c).value)
writer.writerow(row_data)
wb.close()
# CSVアップロード対象のバケットにCSVファイルをアップロード
bucket = client.get_bucket(TARGET_BUCKET_NAME)
blob = bucket.blob(OUT_NAME)
blob.upload_from_string(data=si.getvalue(), content_type='text/csv')
client.close()
si.close()
return "OK"
デプロイが成功すると、以下のように緑色のチェックマークがつきます。

動作確認をしてみよう
デプロイが成功したら、動作確認してみましょう。
Excelファイルアップロード用のバケットにExcelファイルをアップロードします。

Cloud Functionsが実行され、正常に完了しています。

CSVファイルを配置するバケットを確認すると、CSVファイルが作成されています。

BigQueryへ連携してみよう
では次に、CSVファイルをBigQueryに連携してみましょう。
今回はCloud Storage上のCSVファイルから外部テーブルを作成してBigQueryで参照できるようにします。
私の考える外部テーブルのメリット・デメリットは以下です。
【メリット】
・データソースを直接参照するため、最新のデータをクエリすることができる
・BigQuery側でのデータ更新処理が不要になる
・BigQuery以外のデータストレージ上のデータをBigQueryから参照できる
【デメリット】
・パフォーマンスは内部テーブルからのクエリ実行より低くなる
・データ変更の制限(クエリ実行中に元データを変更すると予期しない動作が起きる場合も)
詳しい制限内容に関しては公式ドキュメントを参照してください。
外部テーブルを作成する
使用画像について
特別な記載のない限り、画像はGoogle Cloud - BigQuery画面をキャプチャしたものとなります
Google Cloudにアクセスしてハンバーガーメニューを開き、BigQuery ⇒ SQLワークスペースを選択します。

データセットを作成するプロジェクトを選択 ⇒ データセットを作成を選択します。

データセットIDを入力し、データのロケーションにはasia-northeast1を選択し、[データセットを作成]を選択してください。
※作成したCloud Storageのバケットのロケーションと合わせておいてください

作成したデータセットにテーブルを作成する
作成したデータセットを選択 ⇒ テーブルを作成を選択します。

テーブルの作成元にはGoogle Cloud Storageを選択してください。
選択すると、バケットからファイルを選択するための参照ボタンが表示されるので、[参照]ボタンを選択します。

バケットを選択 ⇒ CSVファイルを選択して、画面下部の[選択]ボタンを押下してください。


テーブル名を入力し、テーブルタイプは[外部テーブル]を選択してください。

スキーマは[テキストとして編集]をONにすると、入力できる状態になるので、

以下のスキーマ定義を貼り付けて、[テーブルを作成]ボタンを選択してください。
※折りたたんでいます。クリックすると展開します。
スキーマ定義
[
{
"mode": "NULLABLE",
"name": "year",
"type": "STRING",
"description": "年"
},
{
"mode": "NULLABLE",
"name": "area",
"type": "STRING",
"description": "都道府県"
},
{
"mode": "NULLABLE",
"name": "total_guest_number",
"type": "INTEGER",
"description": "延べ宿泊者数"
},
{
"mode": "NULLABLE",
"name": "residence_inside",
"type": "INTEGER",
"description": "居住地:県内"
},
{
"mode": "NULLABLE",
"name": "residence_outside",
"type": "INTEGER",
"description": "居住地:県外"
}
]
テーブルが作成されました。

データを確認しよう
最後にデータを確認しましょう。
先ほど作成したテーブルを選択し、クエリを選択します。

今回はデータ量も少ないので、全項目取得するSQLを画像のように入力し、実行を選択します。
CSVのデータがきちんと表示されていますね!

今回はデータ量が少ないので問題ないのですが、データ量が多いとクエリの実行料金が発生します。
BigQueryの料金体系に関しては以下の記事にまとめています。
また、BigQueryのデータをスプレッドシートで簡単に参照したり、分析できます。
こちらも以下の記事にまとめているので、興味のある方はぜひご覧ください!
まとめ
いかがでしたか?
ExcelをCSVデータに変換し、BigQueryに連携するという一連の処理の作成は意外と簡単にできるな、と思って頂けたのではないでしょうか。
表形式データのExcelがあれば、ぜひ一度チャレンジしてみてくださいね!