はじめに
3月末に大学でデータ分析系の研究室に配属され、何か手頃なデータで遊んで見たいなぁ〜と思っていたところこんな素晴らしい記事を偶然発見。
**Spotify**は無料(!)で使えるApple Musicのような定額音楽ストリーミングサービスです。
 ↑Spotify の Web Player
↑Spotify の Web Player
前々からSpotifyはかなり使っているのですが、APIの存在はこの記事で初めて知りました。取得できるオーディオ解析のデータの一つ一つもかなり面白そうだったので、これを使う手はない!ということで実際に触って見ました。
今回はSpotifyの曲の情報を取得するAPIを使い、データサイエンティスト一年生かつトラックメイカー四年生の観点から、色々頑張ってみようと思います。
目標
今回の目標は以下の通りです。
- PythonでSpotify APIを叩く
- APIでオーディオの解析情報を取得する
- APIで取得したデータをうまくPandasのデータフレームに突っ込む
- Seaborn等を用いて視覚化する
- Spotifyにある自分の曲についても分析して、オーディオの解析結果を考察する。
準備
実際にデータを取得する前の準備をしていきます。
APIキーの取得
APIキーはSpotify for Developersから発行できます。ログインして「DASHBOARD」に行くとアプリの一覧と管理画面があります。必要な情報を入力すれば、OAuth2認証に必要なClient IDとClient Secretが入手できます。

↑DASHBOARDでAPIキーを発行するところ
チャート(プレイランキング)の入手
Spotifyの**チャート(プレイランキング)も、三年くらい前まではAPI経由でアクセスできたそうです。しかし、現在はAPIのエンドポイントが公開されておりません。その代わりに、Spotifyのデイリーチャートを見れる子サイトSpotify Charts**にCSVをダウンロードできる機能がひっそりとありましたのでこれを使います。ご丁寧にURLまでCSVに記入されています。
 ↑右上に~~ひっそりと~~あるDOWNLOAD TO CSVでCSVをダウンロードできる
↑右上に~~ひっそりと~~あるDOWNLOAD TO CSVでCSVをダウンロードできる
Spotipyの入手
SpotifyのAPIを叩くためのPythonのライブラリです。ドキュメントは**こちら**にあります。pipで普通にインストールできます。
$ pip install spotipy
これで準備は完了です!
データの準備
データの取得と前処理を施していきます。
データの取得
今回はデータサイレンティストっぽく、Jupyter Notebookを用いて分析をしていきたいと思います。対話形式なので、適宜コードを乗せながら説明していきます。
まず、お決まりのPandasをインポートします。Spotipyやjsonもインポートし、OAuth2で通信できる状態にします。
import pandas as pd
import spotipy
from spotipy.oauth2 import SpotifyClientCredentials
import json
client_id = 'xxxxxxxxxxxxxxxxxxxxxxxx'
client_secret = 'xxxxxxxxxxxxxxxxxxxxxxxx'
client_credentials_manager = spotipy.oauth2.SpotifyClientCredentials(client_id, client_secret)
spotify = spotipy.Spotify(client_credentials_manager=client_credentials_manager)
ここのSpotipyを用いた認証作業は、こちらの記事を参考にさせて頂きました。
続いて、先ほどSpotify ChartsでダウンロードしたCSVを、Pandasのデータフレームに読み込みます。元CSVの一行目が不要だったので、予め削除しました。
# top200.csvは予めダウンロードしておいたもの
songs = pd.read_csv("top200.csv", index_col=0)
songs.head(10)

続いて、URLより曲の解析情報を入手します。新たに空のDataFrameを作り、1曲ずつ取得したのちにDataFrameに追加して行く感じで実装します。
song_info = pd.DataFrame()
for url in songs["URL"] :
df = pd.DataFrame.from_dict(spotify.audio_features(url))
song_info = song_info.append(df)
# index振り直し
song_info=song_info.reset_index(drop=True)
song_info.head(10)
途中警告が出ていたので確認したところ、三曲のみデータが取れておらず全ての列がNaN扱いになっておりました。この三曲はとりあえずdropna(how="all")で除外します。
dtypesでDataFrameの型と取れたデータを確認します。
song_info.dtypes
# acousticness float64
# analysis_url object
# danceability float64
# duration_ms float64
# energy float64
# id object
# instrumentalness float64
# key float64
# liveness float64
# loudness float64
# mode float64
# speechiness float64
# tempo float64
# time_signature float64
# track_href object
# type object
# uri object
# valence float64
# 0 object
# dtype: object
今回使用したいカラムは過不足なくfloat64でしたので、select_dtypes()を用いてfloat64型の列のみ残します。
song_info = song_info.select_dtypes(include='float64')
song_info.head(10)

各カラムの属性の対応と説明を表に示しておきます。
| カラム名 | 属性(意味) | 説明 |
|---|---|---|
| acousticness | アコースティック感 | 1に近づくほど生楽器系が多い曲 |
| danceability | ダンスしやすさ | 1に近づくほど盛り上がってダンスしやすい曲 |
| duration_ms | 長さ[ms] | 曲の長さ(ミリ秒単位) |
| energy | エナジー感 | 曲の激しさ。デスメタルなど激しいほど1に近いらしい |
| instrumentalness | インスト感 | 曲のオケの強さ。0.5を超えるといわゆる歌モノではなくインスト曲らしい |
| key | 調性(1) | 曲の12個の調性(C,Db,D,Eb,...,Bb,B)を0~11に表わしたもの |
| liveness | ライブ感 | 曲のライブっぽさ。0.8以上だとだいたいライブ音源らしい |
| loudness | 音圧 | 平均的な曲のdB(音量)、基本的に-60.0dB~0.0dBの間に収まっている |
| mode | 調性(2) | 曲が長調なら1, 単調なら0 |
| speechiness | スピーチ感 | ボーカルが話している感じの強さ。ラップ曲とかだと0.33~0.66の間になるらしい |
| tempo | 曲のテンポ | いわゆるBPM。高いほど曲も早くなる |
| time_signature | 拍子 | 1小節切り変わるのに何拍使うか。4/4拍子なら4になる |
| valence | 曲の明るさ | 1.0に近づくほど明るい曲 |
こんなのどうやって分析しているんだ?と思うようなパラメータばかりです。しかし、実際に曲のレコメンドや自動生成のプレイリストをウリにしているSpotifyの秘密は、このようなバックボーンの曲情報と解析技術に支えられているのでしょう。Spotifyの企業努力に敬意を示すのみです。
データの下処理
今回、テンポを5つのグループに分けたいので、いわゆるビ二ングをします。テンポを20ずつ区切って分割します。また、後の視覚化のために、ランクを取得し、top20の曲にフラグをつけます。
song_info["rank"] = song_info.index + 1
song_info["top_20"]=(song_info["rank"] <= 20).astype(int)
tempo_range = [0.0, 60.0, 80.0, 100.0, 120.0, 140.0, 160.0, 180.0, 200.0, 220.0, 240.0]
song_info["tempo_bin"] = pd.cut(song_info["tempo"], tempo_range, labels = tempo_range[0:-1])
song_info.sample(10)

データ分析
さて、お待ちかねのデータ分析です。手始めにペアプロット図を出してみます。
import seaborn as sns
import matplotlib.pyplot as plt
pp = sns.pairplot(song_info.drop(columns=["tempo_bin","rank"]), hue="top_20")

クラス間の関係の分析
まず、変数同士の関係の分析をしてみましょう。
変数の量がかなり多く見辛いのですが、パッとみただけでも相関のありそうなクラスがいくつかあることがわかります。特にloudness、valence、energyはそれぞれ正の相関がありそうです。実際にヒートマップで相関係数の強さをみてみましょう。
colormap = plt.cm.RdBu
plt.figure(figsize=(14,12))
plt.title('Correlation', y=1.05, size=15)
sns.heatmap(song_info.drop(columns=["rank", "tempo"]).astype(float).corr(), linewidths=0.1,cmap=colormap, vmax=1.0, square=True, annot=True)
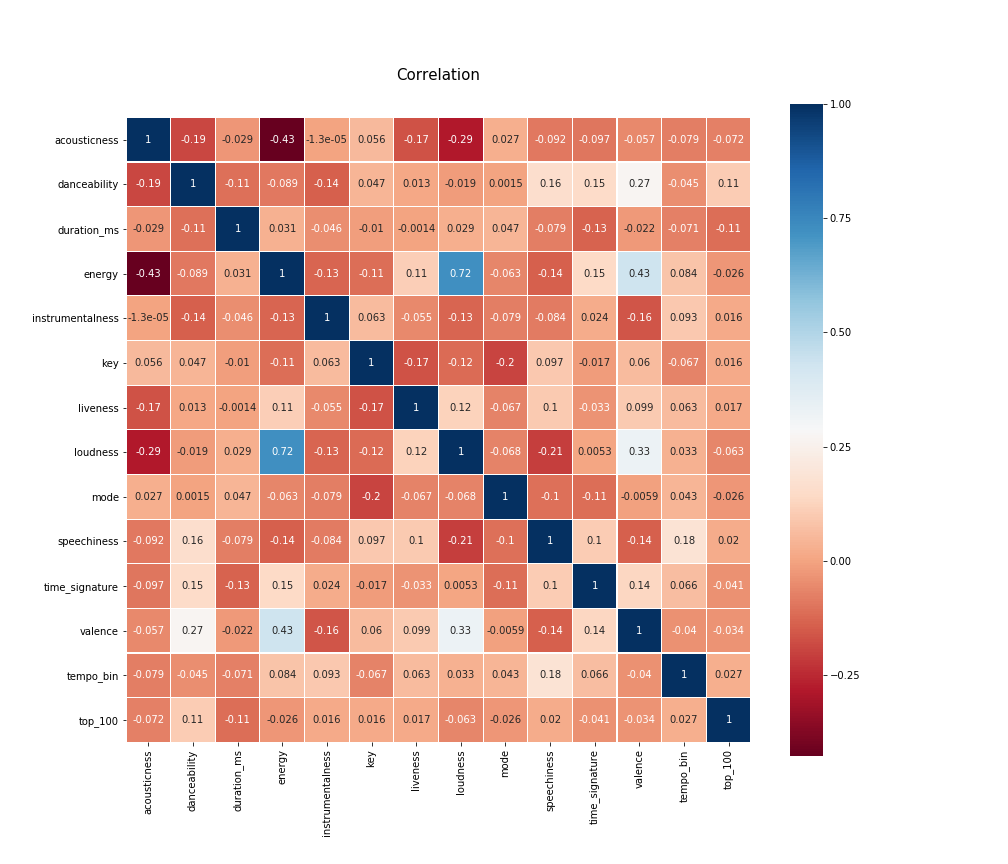
先ほど述べたloudness、valence、energyは確かにそれぞれのクラス同士に弱い正の相関があることがわかります。
結果、以下のクラス同士に弱〜中程度の相関がありそうだということがわかりました。
-
正の相関
-
danceabilityとvalence(0.27) -
energyとloudness(0.72) -
energyとvalence(0.43) -
loudnessとvalence(0.33)
-
-
負の相関
-
acousticnessとenergy(-0.43) -
acousticnessとloudness(-0.29) -
keyとmode(-0.2) -
loudnessとspeechness(-0.21)
-
これらのパラメータはどれも納得いくものが多いです。騒々しい曲ほど踊りやすいですし、また元気になるというのはかなり納得できます。また、アコースティック感がつよい生楽器系の曲は、どちらかというとデスメタルのようにヘドバンしながら聞くよりゆったりと鼻歌でも歌いながら聴きたいですよね。
また、音量の平均を示すloudnessが小さいほど、ボーカルの"喋ってる感"を示すspeechnessが上がるのも納得できます。ラップや落語のようにボーカルの発声が主体となると、その分音量差が大きくなる(発声していない時は無音に近くなる)ので、この結果も納得できます。
どちらかといとこれらのパラメータの計算に、loudness等の明確な解析結果が使われている可能性が高いですが、結果自体はかなり納得のいくものになっています。
クラスの分布の分析
次に、ヒストグラムを表示してみます。
song_info.hist(figsize=(12,12))

instrumentalnessの偏りから、top200に入るような曲は全てボーカル曲であることがわかります。今回自分が特に気になったのがtempoとkeyの分布であり、それぞれヒストグラムを表示してみます。
key_fact = sns.factorplot(x="key", data=song_info, kind="count",
palette="BuPu", size=6, aspect=1.5)
tempo_fact = sns.factorplot(x="tempo_bin", data=song_info, kind="count",
palette="BuPu", size=6, aspect=1.5)
まずKeyについてみてみます。
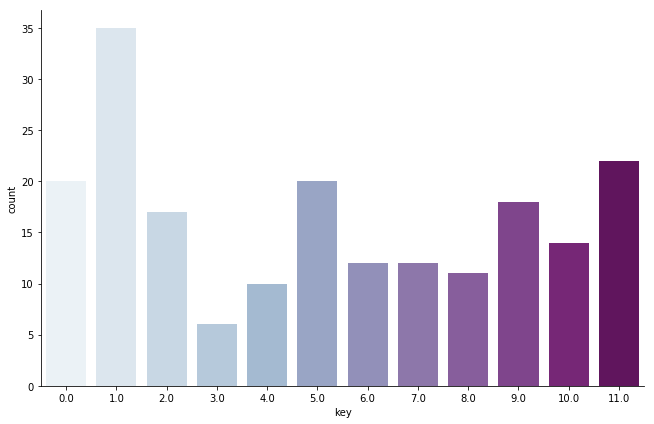
曲のキーの最頻値は1.0(=Db)であり、時点で11.0(B), 5.0(F), 0.0(C)...と続いていきます。Dbキー(メジャー)は鍵盤で表すと黒鍵がかなり多くなるキーですのでかなり意外な結果でした。
FとCは白鍵の多いキーですが、やはりボーカルの音域の関係でしょうか...
次にtempoについてみてみます。
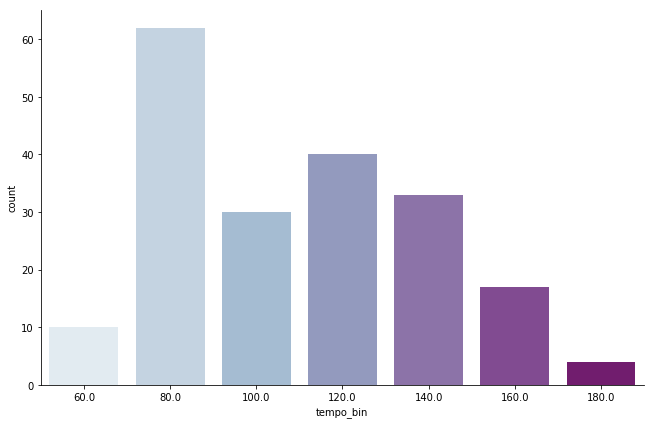
ひと昔前のいわゆるZEDDやAviciiなどのビッグルームハウス系はBPM120~130が主流でした。しかし、最近の流行はHiphopなどにインスパイアされたtrap系のトラックですので、BPM80(倍取りで160とする文化もあります)くらいが最頻値となるのも納得できます。
そもそもこれはデイリーランキングですので、リリースの日付にもかなり左右されますが...
最後に今回のランキングで一位だった**DrakeのIn My Feeling**のリンクを貼っておきます。
自分の曲の分析(おまけ)
検索APIを用いてアーティスト名で自分の曲を取得します。自分以外にこの名前で音楽活動をしておる人はいないはずですので、これで全て取得できる算段です。
IDを取得後、同じようにデータの準備をしていきます。
res=spotify.search("Capchii", limit=30, offset=0, type='track',market=None)
my_song = pd.DataFrame.from_dict(res["tracks"]["items"])
my_song = pd.DataFrame(my_song["id"])
my_song_info = pd.DataFrame()
for url in my_song["id"] :
df = pd.DataFrame.from_dict(spotify.audio_features(url))
my_song_info = my_song_info.append(df)
my_song_info=my_song_info.reset_index(drop=True)
my_song_info = my_song_info.drop(columns=["analysis_url","id","track_href","type","uri"])
my_song_info["tempo_bin"]=pd.cut(my_song_info["tempo"],tempo_range,labels=tempo_range[0:-1])
my_song_info["tempo_bin"]=my_song_info["tempo_bin"].astype("float")
my_song_info["top_20"]=-1
my_song_info.head(10)

まず、ヒストグラムを表示してみます。

自分の曲はEDM系の曲が多いので、acousticnessが低く、energyが高いのが見て取れます。また、歌モノの曲をほとんど作ってないので、instrumentalnessも高いのが特徴です。
自分の曲に対する自分の主観から見ても、これらのパラメータがある程度正確であることがわかります。
次に、key, tempoの分布を見て見ます。
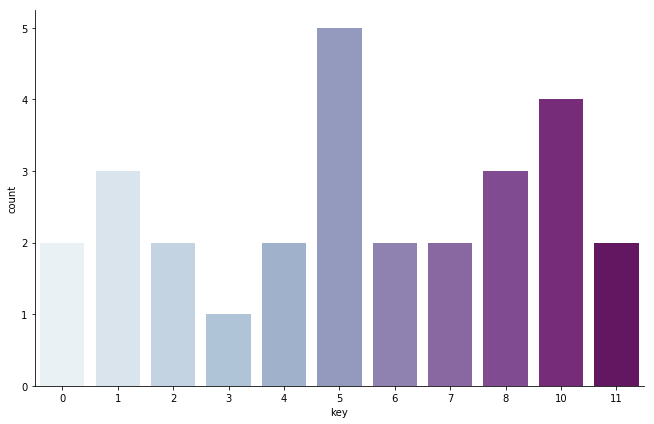
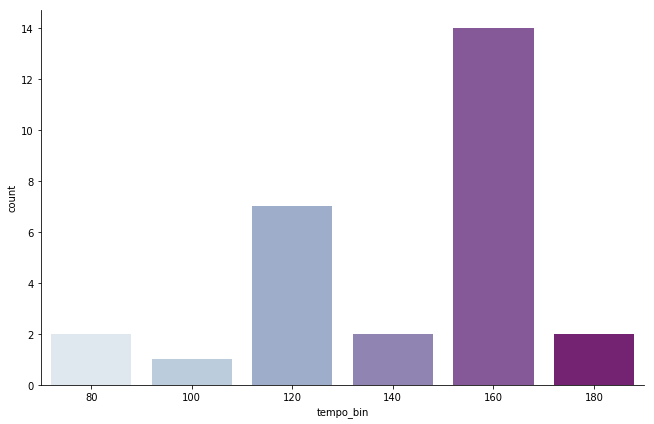
keyは5(=F)が多く、これは自分の手癖と一致しています。keyの検知がある程度正確であることがわかります。(下属調のA#も多くなっています)
また、tempoについて、自分の作っている曲はジャンル的にBPMも170前後のものが圧倒的に多く、これも解析結果と一致しています。
自分の曲でBPM170前後でかつKey=Fの曲のリンクを載せておきます。
最後に、自分の曲とtop200の曲、top20の曲を色分けしてペアプロットを出してみます。

valenceが結構1よりになっているので、自分の持ち味であるポップさが数値にも現れたかなーと内心喜んでおります。
まとめ
今回はSpotifyの曲の情報を取得するAPIを使い、データサイエンティスト一年生かつトラックメイカー四年生の観点から、色々とデータ分析もどきをしてみました。
今後の目標としては以下の通りです。
- データ分析の手法をたくさん学ぶ
- 卒論を頑張る
諸々の作曲の進捗を頑張る
卒論を書き終わりマスターに進む4月ごろに、もう一度この記事を書き直して見たいと思います。
最後までお付き合いいただき、ありがとうございました!