この記事は 弁護士ドットコム Advent Calendar 2019 - Qiita の12日目の記事です。
この記事は何か?
まずは自己紹介です!
- 私は弁護士ドットコム株式会社で働くデータサイエンティストです
- 機械学習が好きで、モデルを作ってはデータ分析をしたりしています
- システム開発は素人で、本件まではちゃんと運用まで作ったことはありませんでした
つまりこの記事は、モデルは作れるけどシステム開発は素人なデータサイエンティストが周囲の協力を得ながらなんとか機械学習システムを運用までこぎつけた体験談となります。
N=1です!再現性は不明です!ツッコミは優しく!気楽な読み物コンテンツとして消費してください!!
何を作ったの?
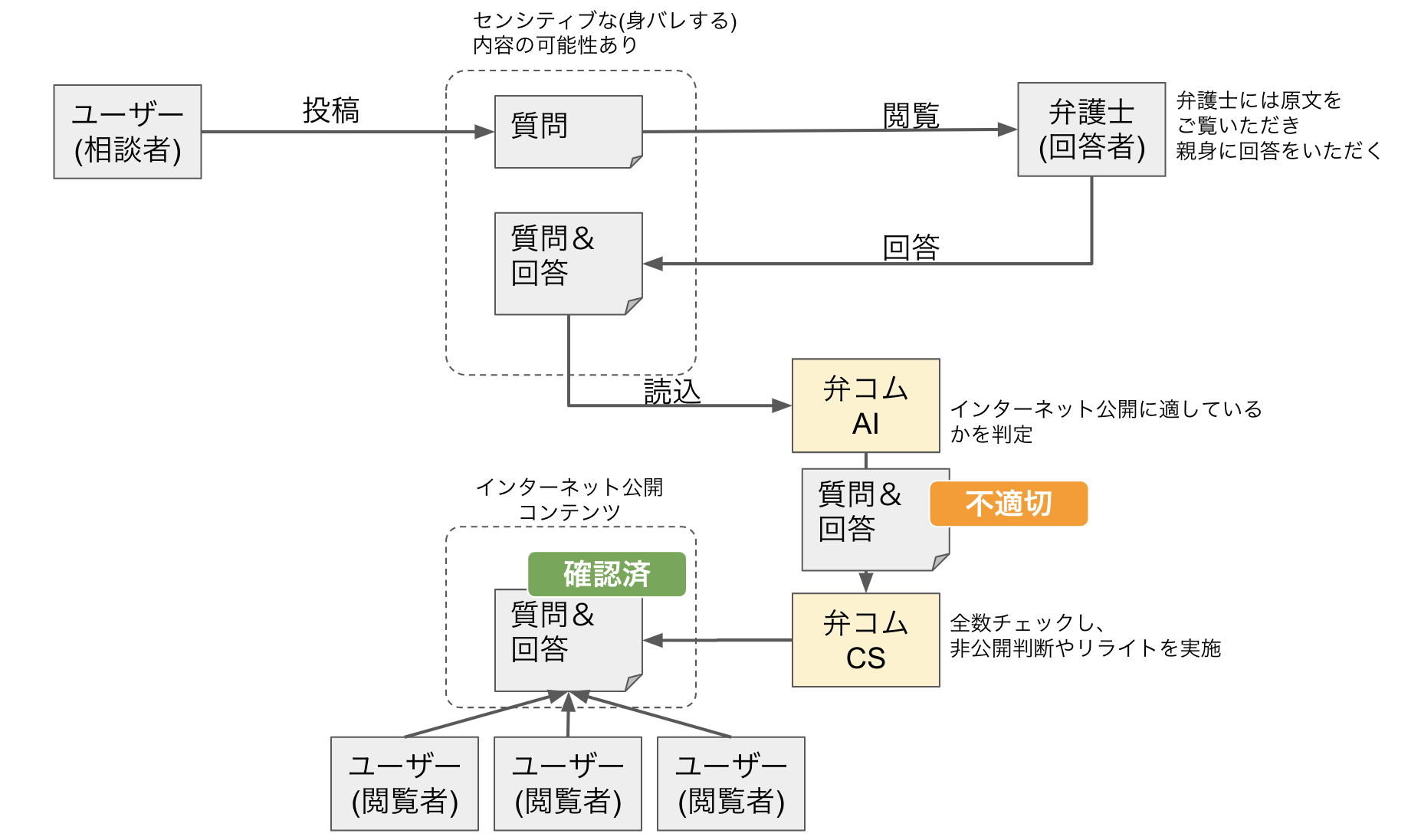
弊社サイト弁護士ドットコムのサービスの一つにみんなの法律相談というものがあります。これは、ユーザーが法律相談を投稿すると弁護士が回答してくれるという弁護士版Yahoo!知恵袋のようなものです。
ユーザーの投稿した法律相談が公開されるまでは、以下のステップを踏みます。
- ユーザーが法律相談を投稿
- 弁護士が回答を行う
- 社内のスタッフが内容を全件目視で確認する
- web上に公開
この「スタッフによる全件目視チェック」がかなりのコストで、機械学習により事前に不適切な投稿にラベルをふることで目視チェック時の負荷を軽減させるシステムを構築しました。
下図中の「弁コムAI」が今回作ったシステム部分になります。1
それでは、データサイエンティストによるノウハウゼロから始める機械学習開発RTA、はーじまーるよー
1. 雑談がネタを生む。ネタが企画を生む。
ネタの方からやって来てくれればモデル作るだけでいいので簡単なのですが、現実はそうではないのです。しかし、いざネタ探しをしようと思っても丁度良く思いつくものでもないわけです。
日頃から雑談しておくとこれが実はネタのストックになってたりするもので。例えばこんな感じの。
同僚「まーた AdSense から怒られメール来てる」
ワイ「え、広告に怒られてんの?なんで?」
同僚「みんなの法律相談ページに広告貼ってるんだけど、『広告の貼られたページに不適切なコンテンツあるぞ💢』って怒られてんの」
ワイ「法律相談だしなあ、そりゃセンシティブな内容もあるだろうけど…」
同僚「社内で全件目視して、問題あれば適切に対応してるけど漏れたんでしょう」
ワイ「ファッ!?全部目視でチェックしてんの!?!?!」
これをきっかけに2点ほど問題点(ネタ)が浮かび上がります。
- 人力チェックで漏れると広告の貼られるページに不適切な内容が表示され、広告配信プラットフォームに怒られる
- そのせいで、(法律相談コンテンツなので)センシティブな内容がweb上に公開されるおそれもある
前者の問題だけなら不適切用語集でも作って辞書マッチでいけそうなものですが、後者の「センシティブな内容」のキャッチアップには限度があります。従来はここを人力でカバーしていたと。
このネタをもとに「自然言語処理を使った機械学習モデルでセンシティブな内容を判定して、法律相談の目視チェック担当者の負荷を軽減する」という企画が生まれました。
この辺の、目前の課題を機械学習のタスクに落とし込むというのが地味ながらもデータサイエンティストの腕の見せ所のひとつだなあと思っています。
2. データがある ≠ 使えるデータがある
「我が社には大量にデータがある!これでAIの波に乗り遅れることはない!」と言いながらセル結合2が駆使され書式もカラムもバラバラな状態で眠っていたExcelファイル群を「ビッグデータ」として示されたことのあるデータ分析者なら、表題を見ただけで首がもげるほど首肯してもらえるかと思いますが、データがあることと、使い物になるデータがあることには天と地ほどの差があります。
さて、今回のデータはチェック済みとはいえ目視から漏れているのもそこそこあり、そのままでは教師データとして使えません。現場の担当者が独自に持っていたNGワード集やググって出てきた不適切表現集などをかき集め辞書を作り、それを交えつつ教師データを新たに作成しました。
そこにデータがあるからといってそのままモデルに突っ込めばいいというわけではなく、タスクに応じて加工、場合によってはデータ自体の調達も必要な作業だということが分かってもらえれば嬉しいです。
Garbage in, garbage out
ゴミみたいなデータを入れてもゴミしか出てこない
この名言を胸に素敵なデータを作りましょう。目的に沿ったキレイなデータはそれだけで価値です。
3. モデルの精度を上げましょう!……精度とは?
ようやくモデル開発です。モデル作るのが仕事と言いつつ、モデル作るまでが長いのなんの!
なんやかんやあって(このなんやかんやの部分もいずれ記事にしたい)モデルが完成するのですが、当然性能を向上させるためにチューニングが必要になってきます。
さて、これを読んでいるかもしれないデータサイエンティスト諸君よ、震えて眠れ。我々の業界ではない人たちが言う「精度を上げましょう!」の「精度」は precision ではない!(どーん!)3
どこで刷り込まれたか、「モデルの精度を改善云々」という文脈がかなりの頻度で発生するのですがモデルの性能評価の指標には実は様々な種類があります。一例を示します。
- 正解率(accuracy): 正解を正解、不正解を不正解と正しく予測できた割合
- 精度(precision, 適合率とも): 正解と予測したもののうち、実際に正解だったもの
- 再現率(recall):実際に正解であるもののうち、正解であると予測できたもの
流石に「精度」と言われただけでprecisionを採用するというギャグみたいなことは起こりませんが、どの評価指標でモデルの性能を評価するかは悩みどころです。
今回は「なるべくチェック漏れが出ないように(間違って不適切と予測してもいいから)多めにアラートをあげておく」ことが重要になります。アラートが上がってれば担当者は「これ見なきゃいけないやつだ」と意識付けられますからね。
というわけで、なるべく recall がよくなるようにチューニングを施しました。
評価指標に何を採用するかはドメインや文脈にかなり依存すると思っています。タスクやプロジェクトに応じて柔軟に考えたいですね。
4. アーキテクチャぜんぜんわからない
吾輩はデータサイエンティストである。運用経験はまだない。
渾身のモデルができあがる。現場の担当者にもサンプルで作ったデータを見てもらい、「これかなり当たってますね!すごい!」とお褒めの言葉をもらう。
しかし、実装されなければ意味がないのである。機械学習システムにおいてモデル開発なんてごく一部だって有名な論文も言ってる。

実装、運用が必要になります。未経験領域です。早速周囲の頼れるエンジニアたちに泣きつきます。
社内でも機械学習モデルを噛ませたワークフロー運用のノウハウはなかったので、ひたすらググって出てきた他社事例を参考に案を練ってはエンジニアにレビューしてもらうという感じでした。
結果、業務の性質上、1日1回夜間にバッチでデータを更新しておけば問題ないという要件定義が出来たので、それに合わせてワークフローを組みます。(このへんのアーキテクチャ作成話もいずれは記事にしたいです)
インフラ構築やAPI開発を優秀極まりない同僚エンジニアに託し、バッチジョブのコンテナをせっせこ作っていました。Docker、こんなに便利だったんだなお前…
- バッチでいいのかリアルタイムに推論するのか
- データはどこに置くのか
- インフラのスペックは?(今回は不要でしたが画像処理系だとGPUゴリゴリのスペックが要求されたり)
- ワークフローはどう組むべきか
- 言語やライブラリの環境をコンテナ化してバッチ処理を書く
などなどバッチ処理一つ書くのにも運用上考えることがたくさんあり、ものすごい勉強になりました。
エンジニアいつもこんなことやってんの…すご…となり改めて尊敬と感謝しかないですね。みなさんも周りのエンジニアを労いましょう。
あとがき
コードが1行も出てこないこんなポエムを最後まで読んでくれたあなたは神ですね。ありがとうございます。
この体験談は本質的にはコミュニケーションの体験談です。AI開発においても、要件定義、評価指標の選定、運用システムの実装など周囲と認識をあわせたりしながら進めていく必要性があります。
そのような仕事において、具体的にどのようなコミュニケーションが発生して課題解決を行うことができたのか、その過程を知る一つの機会としてこの記事が何かの参考になればと書きました。
楽しんでいただけたなら幸いです。