数テラバイト越えあたり or パーティション数大量になったあたりで、ORC ファイルについて詳しくなったけど最初から知っておきたかった事。
がまとまったので書いておくけど、もう一桁増えると更に知っておきたかった事が増える気がする。随時更新。
BigData を扱うデータフォーマット ORC とは
Hive / Spark / Presto 等と言った(以下 Hive 等)のビッグデータ基盤で使えるカラムナデータフォーマットだ。
MySQL では、実際のデータファイルは .idb ファイル等の形式で保存されるが、Hive 等ではフォーマットを複数選ぶことができ、ORC はデファクトスタンダートだ。次点に Perquet1 等がある。
HDFS に収納されて Hive 等 Query 対象となることが多い。
Reference
Primary
- 公式サイト - https://orc.apache.org/
- https://cwiki.apache.org/confluence/display/hive/languagemanual+orc - CWiki
参考情報
Hive等 と HDFS / S3 の関係
多くの環境では Hive / Presto 等複数の手法でデータを Query できるようになっているが、これは MySQL 等と違って Hive / Presto はデータの保存に責任を持っていないから。
データは共有ファイルシステム(多くは HDFS だが、AWS では S3 に保存することもある)に置いて、それに対して SQL を書けるようにしている。
SQL を書くためにはテーブル毎に構造とファイルの位置を知っておくことが必要で、メタストアと呼ばれる。この部分は Hive が管理して、Presto / Spark は必要に応じて Hive メタストアを参照させる。
メタストアには、主に以下の情報が入っている
- テーブルを構成する列(カラム)の一覧
- テーブルを構成するディレクトリの Path と、パーティションがある場合のパーティションの切り方
- パス上に置かれたファイルのフォーマット(今回重要)
ファイルを読み書きするフォーマットが TSV なのか ORC ファイルなのかは CREATE TABLE 時に決まると思っておけばいい。
ORC で CREATE TABLE するには
利用者の視点からすると多くのデータストアで CREATE TABLE すればデフォルトで ORC 形式(ないし社内で一番推奨される形式)になっているはずで、ORC フォーマットであれば適切な圧縮が効く。2。ただし最新バージョンの ORC に統一できているなら圧縮フォーマットとしては ZSTD を明示的に指定した方がよい。3
圧縮フォーマットとしては Snappy を使う事もできるが、基本的に ORC データ読み取りのボトルネックは Disk 読み取りなので、CPU 利用率では有利だが圧縮率の低いフォーマットを使う意味はそれほどない。どちらにせよ、 ORC フォーマット自体に圧縮効果があるため、zlib / snappy はおまけとして考えるのが良い。(= 事前ソートなどでデータ量が減らせる事が多い)
明示的に指定したい場合以下の用になる
CREATE TABLE mydb.mytable
(
-- column definition
)
STORED AS ORC
TBLPROPERTIES ("orc.compress" = "ZLIB")
...
使用しているデータウェアハウスの基盤のデフォルト値を確認する為には、引数無しで CREATE TABLE してから SHOW CREATE TABLE すればよい。
CREATE EXTERNAL TABLE `mydb.mytable`(
...)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'
LOCATION
'viewfs://user/name...'
...
STORED AS ORC で指定したあるいはデフォルトのフォーマットが ROW FORMAT SERDE 等に指定されている事が解る。
一旦この形式でテーブルを作れば、このテーブルに対する INSERT INTO が常にこのフォーマットになる。
圧縮形式について
再掲:ORC フォーマットであれば適切な圧縮が効く。2。
zlip / snappy の典型的な比較については https://engineering.fb.com/2015/03/17/core-data/even-faster-data-at-the-speed-of-presto-orc/ にある。
要約すると大差ないように見える。
ORC ファイルについて
ORC ファイルはカラムナフォーマットだ。
カラムナフォーマットの概念図はこれが一番解りやすいと思う。
カラムナ一般論から、更に ORC ファイルのフォーマットはこうなっている。
From https://cwiki.apache.org/confluence/display/hive/languagemanual+orc
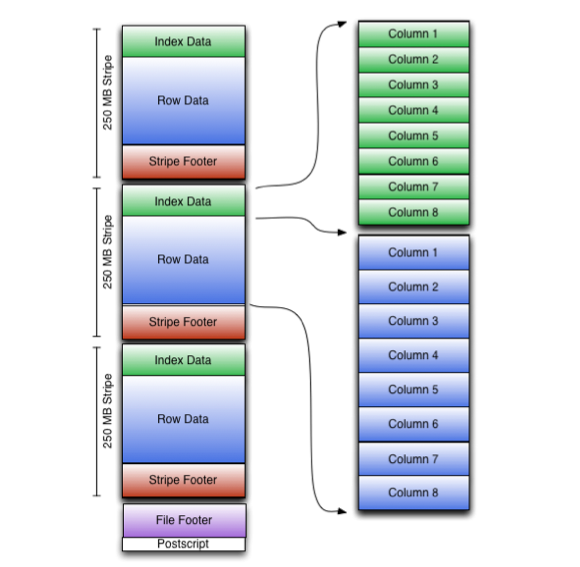
データの分割法
- まず大量の行があったとき『Stripe』と呼ばれる単位に分割される(行単位)
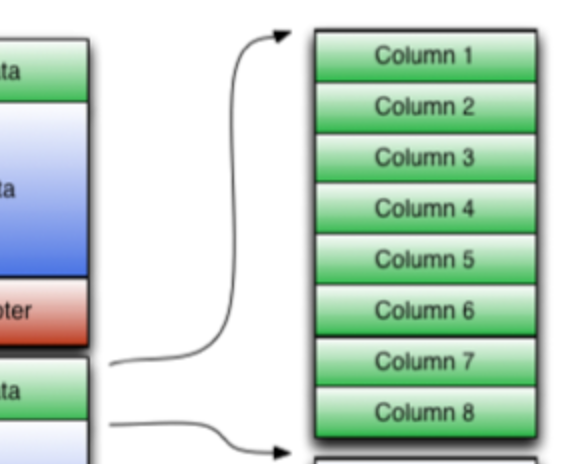
- ストライブに含まれる行を、行単位からカラム単位に分割する
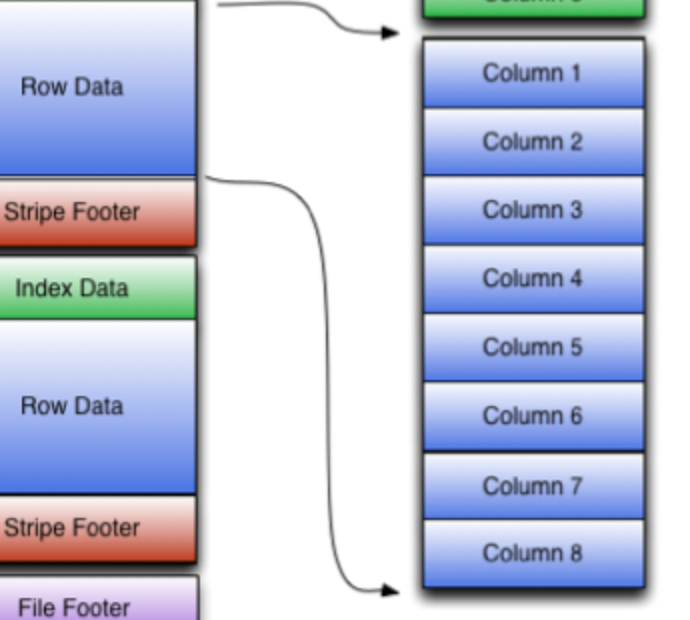
- また、このとき分割した各カラムについて、1万行毎に統計値(最小値 / 最大値)を取得して値を Skip するのに使う。
ORC File Index
この部分は https://orc.apache.org/docs/indexes.html にそのまま書いてある内容。
ORC ファイルは3つのレベルの Index (統計情報) を持っている
- file level - ファイル全体の、各カラムの統計情報(最大・最小値)
- stripe level - ストライプに含まれる、各カラムの統計情報
- row level - 1万行ごとに分割された中での各カラムの統計情報
file level と stripe level の統計値は、共に file footer に置かれる。
そのため、file footer を見るだけでそのファイルのどの Stripe を見るべきか解るようにするのが一番良い。
stripe level を見た後で、必要があれば row level 統計値をみて実際にアクセスするかどうかが決まる。 row level 統計値は各 Stripe に書き込まれているので追加の IO (Disk Seek / RPC) が必要。
列の統計には、値の数と、NULL値があるかどうかが、可能な場合には最小値・最大値・合計値が含まれる。オプションでインデックスにブルーム・フィルタを含めることもできる。
MySQL と異なり、値そのものは入っていないので、必要なのは最小値・最大値だけを元に、『値が入っていそうか? その場所はどこなのか?』が解ること。
言い換えれば、頻繁に完全一致検索条件に指定されるものがあれば、そのカラムでデータをソートしてから ORC ファイルを作成する必要がある。(基本的にいずれかの列でデータをソートしておくのは常によいことではある)
時刻の取扱について
複数タイムゾーンに跨がったチームでは)TIMESTAMP は使わない、使うなら TIMESTAMP WITH LOCAL TIME ZONE を使うか(最新バージョン)、ミリ秒を bigint で入れた方が良い。
単一タイムゾーンチームでは)TIMESTAMP を使うデメリットはそんなにない。
Java でいう Instant 相当は TIMESTAMP WITH LOCAL TIME ZONE
https://cwiki.apache.org/confluence/display/Hive/Different+TIMESTAMP+types
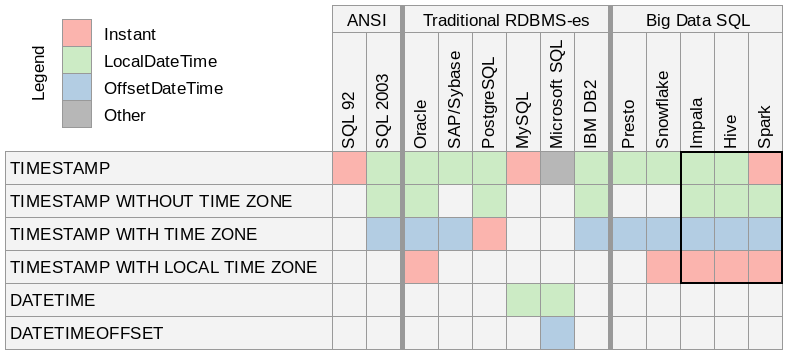
一部資料では ORC は TIMESTAMP WITH LOCAL TIME ZONE 非対応とあるが、ORC-189 で ORC Version 1.6.0 で対応になった。
Timestamp with local time zone is a fixed instant in time, which does change based on the time zone of the reader.—— Types
ORC ファイルを早く Query する為に
そもそもファイルを意識しなくてよいようにする
時間ベースの検索が多いなら、時間ベースでパーティションが切れれば ORC ファイルだろうがなんだろうが、そもそも存在を気にしなくて良いので早い。
適切な統計情報が作られるように Presort する
ウェブサイトの PV と user データがあって、前処理として JOIN して Daily Partition に入れておく、みたいなケースを考える。
-- 20210101 に取れたイベントを JOIN して分析用に入れておく
INSERT OVERWRITE TABLE log_join_user PARTITION(day = '20210101')
AS
SELECT event.timestamp, event.page_url, event.event_id, event.user_id, user.flag_a, user.flag_b
FROM event
INNER JOIN user ON(event.user_id = user.user_id)
WHERE event.day = '20210101'
単純すぎる例だが、分析時の Query の 98% ぐらいが特定ページの PV を求める以下のような Query だとする
SELECT COUNT(*)
FROM log_join_user
WHERE page_url = 'xxx' -- 特定ページについて
AND day BETWEEN '20210101' AND '20210228' -- 1月~2月のPV が欲しい
まず時系列データなので日付に依存するパーティションが切られているのは前提にする。
- 一日毎のデータ量がどれくらいになるか
- 更にパーティションを切った方がいいのか?
を決めたい。
それを決めるために
そもそもどれくらいの IOPS をこのために使って良いのかを確認する。
ファイル数
Batch ではシーケンシャルリードの Bandwidth が、Adhock 分析では Bandwidth と共に利用できる IOPS や RPC / sec も問題になる。
といっても社内向け分析で秒間1Query もない、みたいな環境だったら Bandwidth 重視でも良いかも。
データ分析基盤の Total IOPS (HDFS を構成するディスク数 x 各 Disk の IOPS) ぐらいはざっくり見積もって置いた方がよい。
例)対象データが 10,000 ファイルに分割して収納されていた場合、Index とは関係無く、100 IOPS HDD が合計 20 台搭載された HDFS クラスタでは、各 ORC File を少なくとも 1 バイト Fetch するのに 5 秒かかる。(10,000 IO / 2,000IOPS;各レイヤーのキャッシュを考えない場合)
Small ファイルは悪、と言われる所以は namenode の負担以外にここらへんにある。
2つのファイルの ORC Index を取得する為必要な IO は、1 ORC ファイルに対して単純2倍になる。
IOPS に余裕があるなら、並列処理の余裕を出すためにあえて細かいファイルを作るのもあり。
まぁここら辺は多分何種類か作ってみるしかない。
ちなみに Query Engine によっては単一 ORC ファイルの異なる Stripe を分散して読むことに対応している、がもちろん不要なアクセスが減らせるならそれに越したことは無い。
(一方で、あまりにまとめた結果この並列化が聞かなくなるとパフォーマンスは下がってしまう)
ファイル数が決まれば
ファイルをどの程度に分割したら良いか(どの程度並列 IOPS を出すべきか?)が決まれば、この数のファイルが作られて、かつファイル内では整列されているようにデータを出力すればよい。
16 ファイルに分割して、ファイル内では page_url 順にソートしたいのであれば。
INSERT OVERWRITE TABLE log_join_user PARTITION(day = '20210101')
AS
SELECT event.timestamp, event.page_url, event.event_id, event.user_id, user.flag_a, user.flag_b
FROM event
INNER JOIN user ON(event.user_id = user.user_id)
WHERE event.day = '20210101'
DISTRIBUTE BY FLOOR(RAND() * 16)
SORT BY page_url
また、たまに UU を取得しない、等といった場合は同じファイルについては特定ユーザー群しか存在しないようにするのも有効で、
INSERT OVERWRITE TABLE log_join_user PARTITION(day = '20210101')
AS
SELECT event.timestamp, event.page_url, event.event_id, event.user_id, user.flag_a, user.flag_b
FROM event
INNER JOIN user ON(event.user_id = user.user_id)
WHERE event.day = '20210101'
DISTRIBUTE BY user_id % 4
SORT BY page_url
素朴にやると hash を適用することになるが、問い合わせ対応などのときに、user_id でも検索することがあって、int / UUID 等で統計値による Index が使いたい場合は以下。
INSERT OVERWRITE TABLE log_join_user PARTITION(day = '20210101')
AS
SELECT event.timestamp, event.page_url, event.event_id, event.user_id, user.flag_a, user.flag_b
FROM event
INNER JOIN user ON(event.user_id = user.user_id)
WHERE event.day = '20210101'
DISTRIBUTE BY FLOOR(16 * CAST(CONV(SUBSTR(user_id, 1, 2), '16', '10') AS bigint) / 256) -- user_id は UUID 形式
SORT BY page_url
これで、 UUID の範囲に応じた Reducer に配送されて、その中でソートが実行される事になる。
例: User_ID = '00...' ~ '0f...' が特定 reducer へ送られて、その中で page_url ソートがかかる。
-
https://github.com/apache/parquet-format
Parquetとは、Hadoopエコシステムの各種プロジェクトで利用可能なオープンソースのファイルフォーマットです。
↩ -
If it is blank, the compression codec is ZLIB, the default one!
↩ ↩2—— hadoop - How to check if ZLIB compression is enabled in hive tables? - Stack Overflow
-
https://forum.huawei.com/enterprise/en/hive-orc-and-parquet-formats-use-zstd-compression-algorithm-by-default/thread/714175-893 この記事時点では ORC を更新しないといけないが、時間の問題。 ↩