Fringe81アドベントカレンダー2020の14日目の記事です.
突然ですが、dataflow使ってますか?
GCPをお使いの方なら聞いたことあるかも...という方は多いと思いますが、使ってるよ!という人は少ない?
dataflowはその名の通りよしなにデータを移すことができる実は使い勝手豊富なソリューションです。
非エンジニアの方でもコードを書かずに実行できます❗️
ここではその実力の一端をサクッと紹介したいと思い記しました。
やること
サービスで使うには強力だけど、機能がシンプルな故にデータの出し入が気軽でない(コードを書く必要ある)代表として、NoSQLのdatastoreに手軽にデータを入れる方法を試します。
手軽に扱えてI/O周りの機能も充実しているBigQueryをハブとして使うと便利かなと考えました。
(動作確認テストのため、bqクエリで整合性を担保したデータを作成してdatastoreへ入れるケースを想定)
ザックリとした流れ
bq
-
member
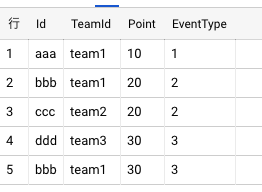
-
team
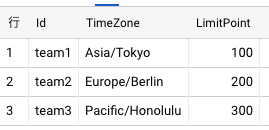
クエリで結合して↓
datastoreエンティティ作成

DAG(dataflow)

実行について(概略)
下記3ステップで実現できました。
-
- BigQueryへデータを作成する
-
- input(Source)をbqクエリとし、output(Sink)をdatastoreとするテンプレート(json)を作成しgcsへ配置
-
- dataflow実行(flextemplate)
ポイント
bqクエリを書くだけでデータ作成
手動で整合性を担保したデータを大量に作ってNoSQLへ取り込むコード書くのは手間がかかるが、
データ作成をbqの強力なクエリで代行できます。
jsonで定義を書くだけで様々なinput(Source)、output(Sink)パターンを設定可能。
今回は近日新規公開された Mercari Dataflow Template を活用させていただきました。
テンプレート(json)
- config_bq2ds.json
{
"sources": [
{
"name": "bigquery",
"module": "bigquery",
"parameters": {
"query": "SELECT m.Id AS MemberId, t.Id AS TeamId, sum(m.Point) AS Point, t.TimeZone AS TimeZone FROM exp_dataflow.member m INNER JOIN exp_dataflow.team t ON m.TeamId = t.id Where Point <= t.LimitPoint GROUP BY MemberId, TeamId, TimeZone;"
}
}
],
"sinks": [
{
"name": "bq2ds",
"module": "datastore",
"input": "bigquery",
"parameters": {
"projectId": "{projectId}",
"kind": "exp_memberTeam"
}
}
]
}
dataflowについて
- 具体的なユースケースはGCPUG勉強会のセッションが大変参考になりました(^人^)