はじめに
待ちに待ったAmazon Bedrock。ついにGAしました。
早速いじって遊んでいる訳ですが、数ステップの簡単な設定でプロンプトの入出力をS3やCloudWatch Logsへ転送する機能があったため手順を紹介します。
手順
Bedrockの利用準備
何はともあれBedrockを有効化する必要があります。
利用開始の手順はこちらの記事が参考になりますので、まずはこちらの準備を終わらせます。
ログ出力先バケットの作成
まずはプロンプトのログを保存するS3バケットを作成します。
今回は適当にbedrock-test-20230929というバケットを作成しました。
設定はデフォルト作成。
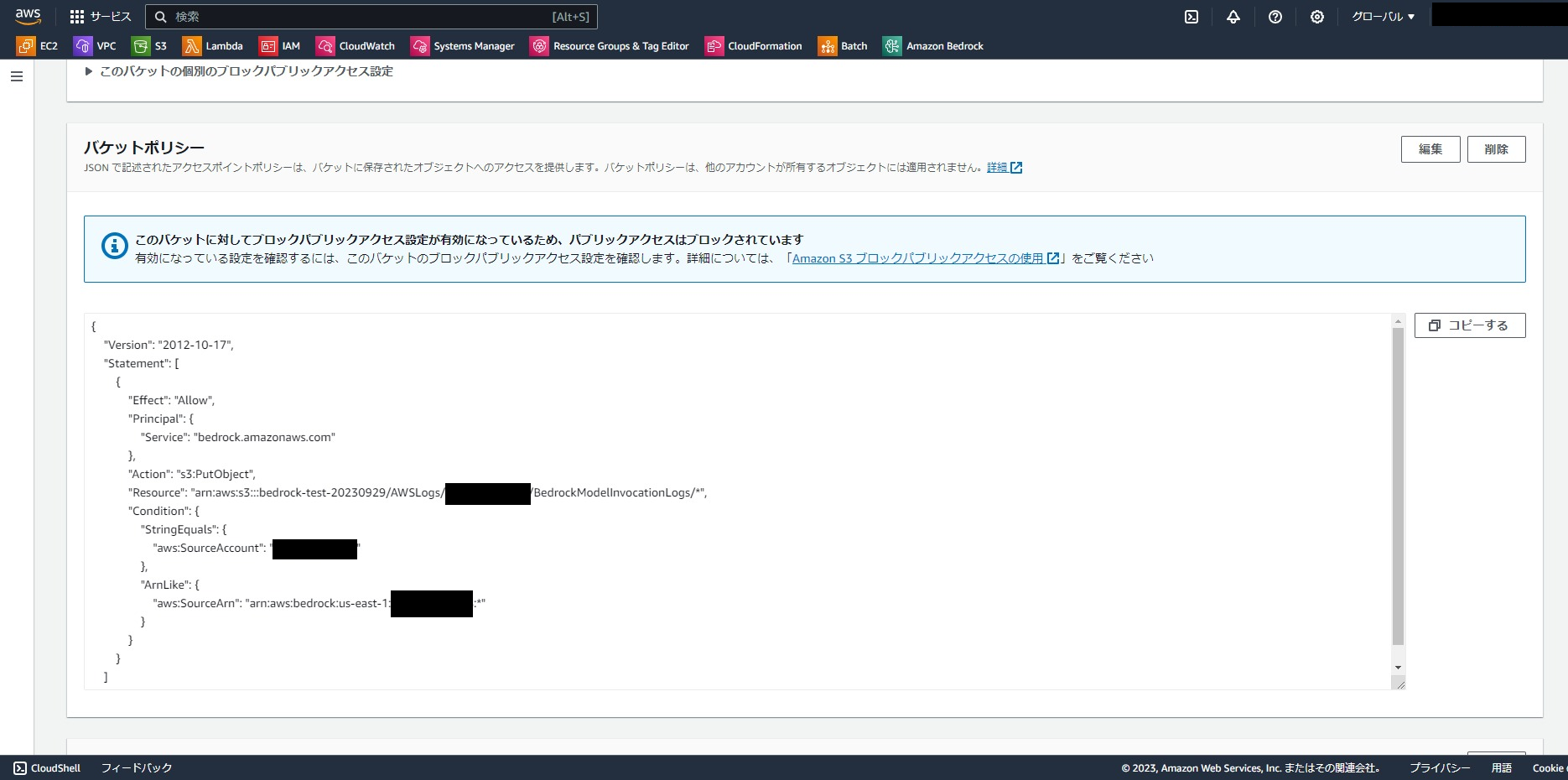
Bedrockがログを出力するためには、作成したバケットのバケットポリシーを編集する必要があります。
ポリシーは以下のような形式です。
※{AccountID}は自身のAWSアカウントのIDに読み替えてください。
※{Region}はBedrockの利用リージョンを指定してください。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "bedrock.amazonaws.com"
},
"Action": [
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::{BucketName}/AWSLogs/{AccountID}/BedrockModelInvocationLogs/*"
],
"Condition": {
"StringEquals": {
"aws:SourceAccount": "{AccountID}"
},
"ArnLike": {
"aws:SourceArn": "arn:aws:bedrock:{Region}:{AccountID}:*"
}
}
}
]
}
ここでResourceに指定されている
arn:aws:s3:::{BucketName}/AWSLogs/{AccountID}/BedrockModelInvocationLogs/*"
ですが、ログ格納パスを変えたければそれに合わせて変更します。
ただし、のちにBedrock側で設定するログ出力先の指定パスに自動で
AWSLogs/{AccountID}/BedrockModelInvocationLogs/{Region}/{yyyy}/{mm}/{dd}/{HH}/
というprefixがついた上でログが保存さるので、それも考慮してResourceを設定する必要があります。
実際の設定はこんな感じです。そのほかの設定はデフォルト。
Bedrockの設定
続いてBedrock側です。Amazon Bedrockを開き「Settings」を選択すると以下のようなページが出ます。
公式のアナウンスにもありますが、今のところS3とCloudWatch Logsにログ出力が可能なようです。
ここではログ出力対象として、Textのみ、S3 Onlyを選択しました。実際には用途に合わせてImage, Embeddingも選択する感じですね。
また、先ほど作成したS3バケット名をS3 bucketに指定します。簡単ですね。

設定した値に間違いがなければ「Save Change」をクリックすれば、完了です。
ポリシーに間違いがあるとpermission errorが出ます。bedrock側で設定したS3パス+/AWSLogs/{AccountID}/BedrockModelInvocationLogs/*への許可がバケットポリシー側で必要なので、間違いないようにしてください。
ログの確認
Bedrockの設定が終わった時点で、以下のようにjsonファイルが出力されていました。中身は空ファイルです。
設定ができているかの確認用ですね。(ファイル名にもアカウントIDが入ってたので黒墨してます)
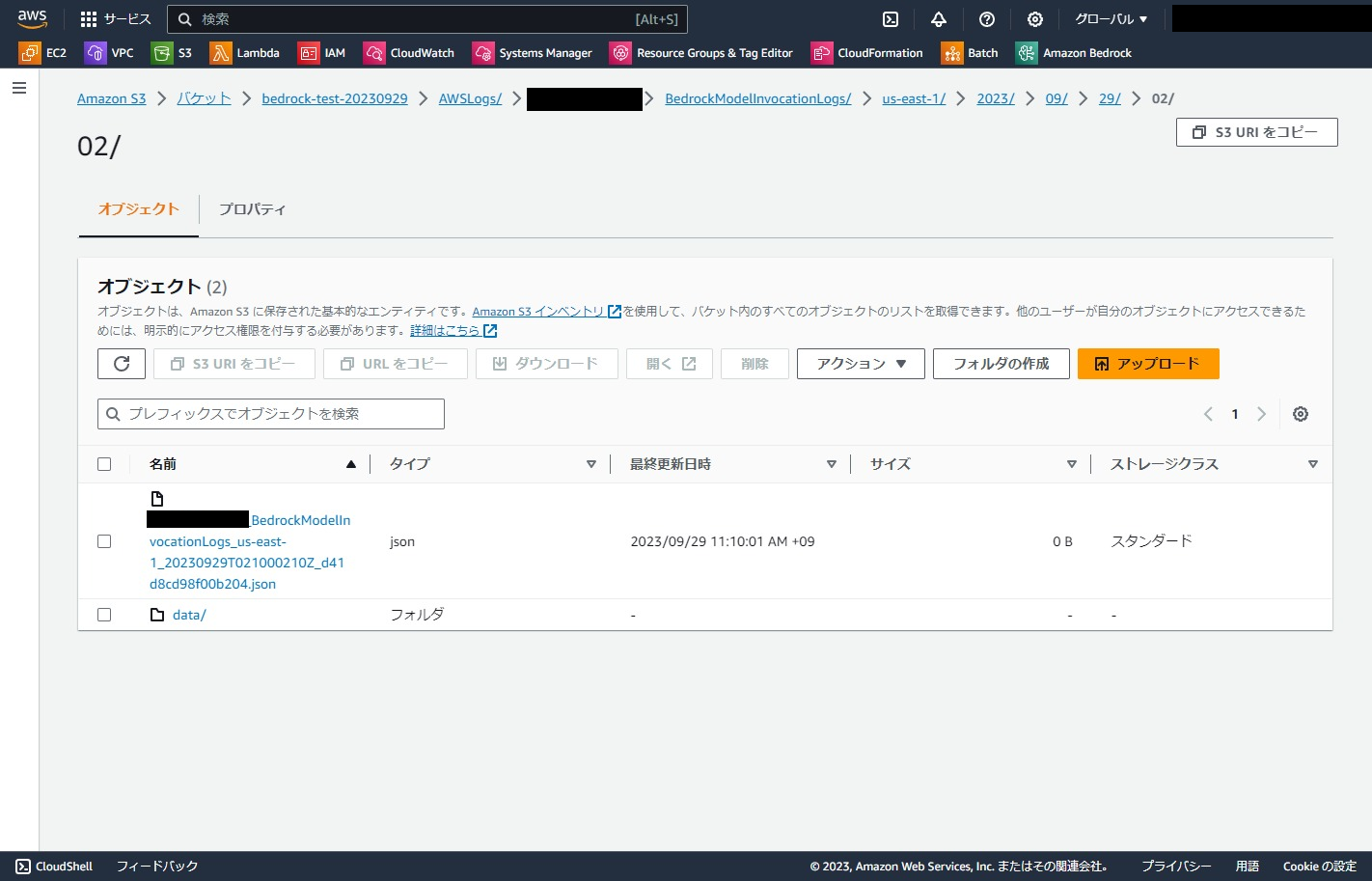
上でも述べましたが、保存されるログは以下のパス形式で保存されます。
AWSLogs/{AccountID}/BedrockModelInvocationLogs/{Region}/{yyyy}/{mm}/{dd}/{HH}/
では実際にログを出していきましょう。
Playgroundsからチャットを利用してみます。モデルはClaude Instant V1です。適当にチャットします。
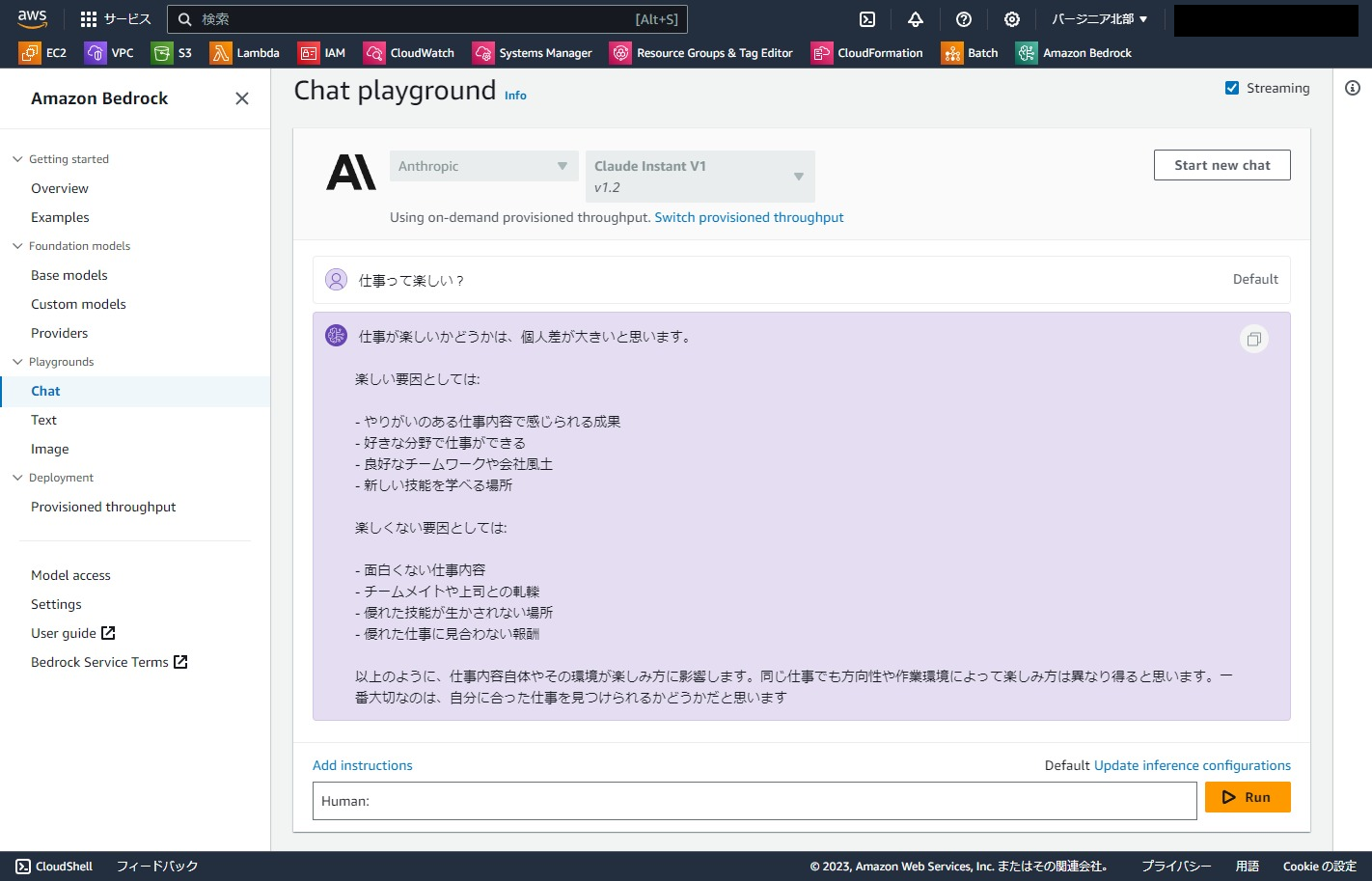
はい、ログが出力されました。成功です。
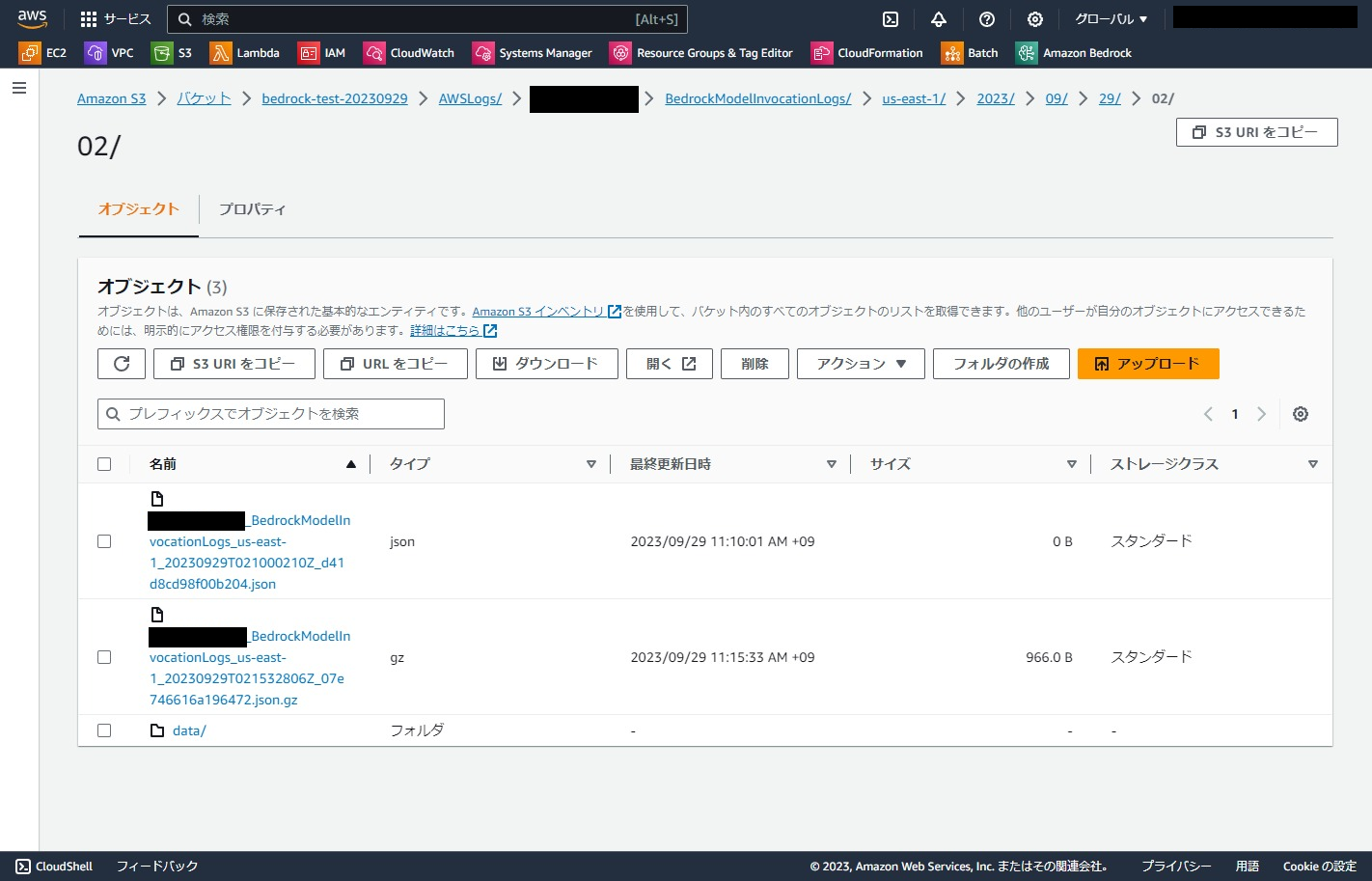
1回のリクエストに対して1ファイル出力されます。
実際のログはこんな感じです。(AccountIDはマスクしています)
{"Records":[{
"schemaType":"ModelInvocationLog",
"schemaVersion":"1.0",
"timestamp":"2023-09-29T02:14:27Z",
"accountId":"000000000000",
"region":"us-east-1",
"requestId":"3569241f-77fe-4842-b1d3-f45f7abb96f6",
"operation":"InvokeModelWithResponseStream",
"modelId":"anthropic.claude-instant-v1",
"input":{
"inputContentType":"application/json",
"inputBodyJson":{
"prompt":"\n\nHuman: 仕事って楽しい?\n\nAssistant:",
"max_tokens_to_sample":300,
"temperature":1,
"top_k":250,
"top_p":0.999,
"stop_sequences":["\n\nHuman:"],
"anthropic_version":"bedrock-2023-05-31"
},
"inputTokenCount":19
},
"output":{
"outputContentType":"application/json",
"outputBodyJson":[
{"completion":" "},
{"completion":"仕事が楽しいかどうかは、個人差が大"},
{"completion":"きいと思います。\n\n楽しい要因としては:\n\n- "},
{"completion":"やりがいのある仕事内容で感じられる成果\n-"},
{"completion":" 好きな分野で仕事ができる\n- 良"},
{"completion":"好なチームワークや会社風土\n-"},
{"completion":" 新しい技能を学べる場所\n\n楽しくない要因としては"},
{"completion":":\n\n- 面白くない仕事内容\n- チームメイトや上"},
{"completion":"司との軋轢\n- 優れた技"},
{"completion":"能が生かされない場所\n- 優れた仕事に見"},
{"completion":"合わない報酬\n\n以上のように、仕"},
{"completion":"事内容自体やその環境が楽しみ方に影響"},
{"completion":"します。同じ仕事でも方向性や作業環"},
{"completion":"境によって楽しみ方は異なり得ると思います。一"},
{"completion":"番大切なのは、自分に合った仕事を見つけられ"},
{"completion":"るかどうかだと"},
{"completion":"思います","stop_reason":"max_tokens"}
],
"outputTokenCount":300
}
}]}
見たまんまで分かりやすいと思います。
input, outputも必要最低限は情報がそろっていそうです。TokenCountがあるのもよいですね。
個人的にはどのIAMユーザが実行したものかわかるとうれしいですが、今のところログとしては出力されないようです。今後に期待です。
なお、実行ユーザについてはCloudTrailを確認すればリクエストIDと、S3出力ログの"requestId"が一致するものがあるので、誰がどこから実行したのかの紐付けは可能です。
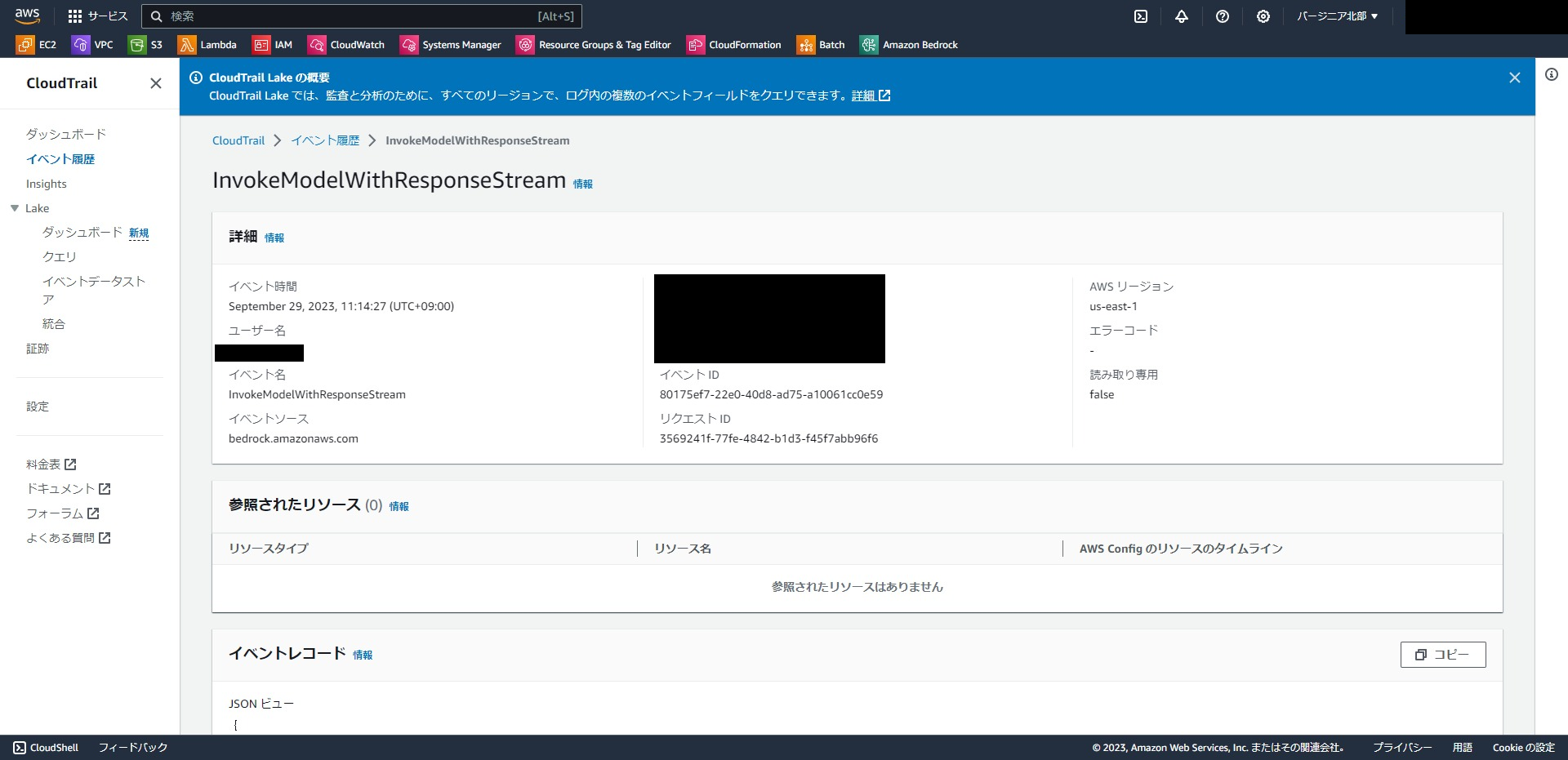
まとめ
ということでものの数分でBedrockのプロンプトログをS3に転送することができました。
実際の運用では、プロンプトの入力を監査目的や利用実態の調査、精度改善などのために記録しておきたいというニーズは結構あると思います。
こういったロギングの設定を数ステップで実現できるのはBedrockの強みと言っていいのではないかと思いました。S3に置きさえすれば、あとの料理は如何様にもって感じなので大変うれしい機能です。
この機能はまだプレビューとのことなので、今後のアップデートも楽しみですね。