前回の記事のGA4特化版です。
以下の手順で、GA4のテーブルをGoogle BigQueryからPostgreSQLにコピーします。
- BigQueryからAvro形式でローカルにexportする
- PostgreSQLへのimport用SQL文を生成する
- そのSQL文を動かしてPostgreSQLにimportする
上記手順に対応して、Pythonコードが3種類あります。
必要に応じてPythonコードや、生成されたSQL文をカスタマイズしてご利用ください。
本記事では、Google アナリティクス 4 e コマースウェブ実装向けの BigQuery サンプル データセットのテーブルをPostgreSQLにコピーします。
(1) GA4のテーブルをBigQueryからAvro形式でローカルにexportする
Pythonコードと設定ファイル
import traceback
from pathlib import Path
import configparser
from google.cloud import storage, bigquery
def read_config(config_path):
config = configparser.ConfigParser()
config.read(config_path, encoding="utf-8")
return config
def gs_path_exists(gs_bucket, gs_path):
blob = gs_bucket.blob(gs_path)
return blob.exists()
def from_bq_to_gs(dataset_ref, table_name, bq_client, gs_path):
table_ref = dataset_ref.table(table_name)
job_config = bigquery.ExtractJobConfig(compression="DEFLATE", destination_format="AVRO")
job = bq_client.extract_table(table_ref, gs_path, job_config=job_config)
job.result()
def from_gs_to_local(gs_bucket, gs_path, local_path):
blob = gs_bucket.blob(gs_path)
blob.download_to_filename(local_path)
def main():
config_path = Path.cwd() / "ga4_from_bq_to_avro.ini"
config = read_config(config_path)
bq_client = bigquery.Client()
gs_client = storage.Client()
bq_project = config["BigQuery"]["project"]
bq_dataset = config["BigQuery"]["dataset"]
gs_bucket = gs_client.get_bucket(config["GCS"]["bucket"])
gs_home = bq_dataset
local_home = Path.cwd() / bq_dataset
dataset_ref = bigquery.DatasetReference(bq_project, bq_dataset)
tables = bq_client.list_tables(dataset_ref)
table_list = [table.table_id for table in tables if table.table_id[:7] == "events_"]
table_list.sort(reverse=True)
print(f"eventsテーブル数:{len(table_list)}")
for table_name in table_list:
yyyymm = table_name[7:13]
local_dir = local_home / yyyymm
file_name = f"{table_name}.avro"
local_path = local_dir / file_name
# localファイル存在チェック
if local_path.exists():
print(f"skip:\n local exists: {local_path}")
continue
gs_path = f"{gs_home}/{yyyymm}/{file_name}"
gs_fullpath = f"gs://{gs_bucket.name}/{gs_path}"
# GCSファイル存在チェック
if gs_path_exists(gs_bucket, gs_path):
print(f"skip BigQuery: GCS exists: {gs_path}")
else:
# BigQuery -> GCS
from_bq_to_gs(dataset_ref, table_name, bq_client, gs_fullpath)
# GCS -> local
print(f"download:\n {gs_fullpath}\n -> {local_path}")
local_dir.mkdir(parents=True, exist_ok=True) # ディレクトリがなければ作成
from_gs_to_local(gs_bucket, gs_path, local_path)
print(" ... done.")
if __name__ == "__main__":
try:
main()
except Exception:
print(traceback.format_exc())
設定ファイルの記述例
[BigQuery]
project = bigquery-public-data
dataset = ga4_obfuscated_sample_ecommerce
[GCS]
bucket = your_bucket_name
設定ファイルはPythonコードを動かすディレクトリに置きます。
設定ファイルの[BigQuery]セクションに、GA4のテーブルが入っているGoogle Cloudのプロジェクト名とデータセット名を記述します。
[GCS]セクションに、Avroファイルを格納するCloud Storageのバケット名を記述します。
コード説明
上記のPythonコードで行うことは以下の通りです。
- BigQueryのGA4テーブルをAvro形式でexportします
- まずBigQueryからCloud Storageにexportし、次にCloud Storageからローカルにダウンロードします。
記事執筆時点で、BigQueryからローカルに直接exportできないため、Cloud Storageを経由しています。 - テーブル名が「events_」から始まるテーブルをGA4のテーブルとみなし、まとめてexportします。
- 出力されるファイル名は「テーブル名.avro」で、出力先に同名のファイルが存在するときは処理済とみなし、処理をスキップします。
- Pythonコードを動かしたディレクトリ配下に、設定ファイルに設定したdataset名でサブディレクトリが作成され、その下にダウンロードされます。

(2) Avroファイルから、PostgreSQLへのimport用SQL文を生成する
以下のコードは、前回の記事のコードをGA4のテーブルコピー専用にアレンジしたものです。
Pythonコードと設定ファイル
import datetime
import traceback
import json
import datetime
from pathlib import Path
import glob
import configparser
import textwrap
import fastavro
from collections import deque
from psycopg2.extensions import adapt
DT_UTC_AWARE = datetime.datetime.fromtimestamp(0, datetime.timezone.utc)
class MyException(Exception):
pass
class MyReader(fastavro.reader):
def __init__(self, file):
super().__init__(file)
self.meta = self._header["meta"]
def read_config(config_path):
config = configparser.ConfigParser()
config.read(config_path, encoding="utf-8")
return config
def escape(ss):
return str(adapt(ss.encode("utf-8").decode("latin-1")))
def convert_to_postgres_type(avro_type, default_value, ddl_queue, postgres_record_type_prefix, len_is_serial_of_postgres_record_type):
postgres_type = None
default_str = None
nullable = False
if default_value is None:
default_str = "NULL"
if type(avro_type) is list:
if "null" in avro_type:
nullable = True
avro_type.remove("null")
assert len(avro_type) == 1
avro_type = avro_type[0]
if type(avro_type) is str:
if avro_type == "string":
postgres_type = "VARCHAR"
if default_value is not None:
default_str = escape(default_value)
elif avro_type == "bytes":
postgres_type = "BYTEA"
if default_value is not None:
pass
elif avro_type == "long":
postgres_type = "BIGINT"
if default_value is not None:
default_str = str(default_value)
elif avro_type == "double":
postgres_type = "DOUBLE PRECISION"
if default_value is not None:
default_str = str(default_value)
elif avro_type == "boolean":
postgres_type = "BOOLEAN"
if default_value is not None:
if default_value:
default_str = "TRUE"
else:
default_str = "FALSE"
elif type(avro_type) is dict:
if "sqlType" in avro_type:
sql_type = avro_type["sqlType"]
if sql_type == "JSON":
postgres_type = "JSON"
if default_value is not None:
default_str = escape(default_value)
elif "logicalType" in avro_type:
logical_type = avro_type["logicalType"]
if logical_type == "decimal":
postgres_type = "NUMERIC"
if default_value is not None:
default_str = str(default_value)
elif logical_type in ("timestamp-millis", "timestamp-micros"):
postgres_type = "TIMESTAMP WITH TIME ZONE"
if default_value is not None:
default_str = escape(default_value.isoformat())
elif logical_type == "date":
postgres_type = "DATE"
if default_value is not None:
default_str = escape(default_value.isoformat())
elif logical_type in ("time-millis", "time-micros"):
postgres_type = "TIME WITH TIME ZONE"
if default_value is not None:
default_str = escape(default_value.isoformat())
elif logical_type in ("local-timestamp-millis", "local-timestamp-micros"):
postgres_type = "TIMESTAMP"
if default_value is not None:
default_str = escape(default_value.isoformat())
else:
avro_child_type = avro_type["type"]
if avro_child_type == "array":
default_value = None
postgres_items_type, _, _ = convert_to_postgres_type(
avro_type["items"], default_value, ddl_queue, postgres_record_type_prefix, len_is_serial_of_postgres_record_type)
if type(postgres_items_type) is str:
postgres_type = {
"array": postgres_items_type + "[]",
"items": postgres_items_type
}
else:
postgres_type = {
"array": postgres_items_type["record"] + "[]",
"items": postgres_items_type
}
elif avro_child_type == "record":
len_is_serial_of_postgres_record_type.append(True)
postgres_record_type = f"{postgres_record_type_prefix}_type_{len(len_is_serial_of_postgres_record_type)}"
postgres_fields_type = make_sql_create_type(
postgres_record_type, avro_type["fields"], ddl_queue, postgres_record_type_prefix, len_is_serial_of_postgres_record_type)
postgres_type = {
"record": postgres_record_type,
"fields": postgres_fields_type
}
return postgres_type, default_str, nullable
def make_sql_create_type(name, avro_fields, ddl_queue, postgres_record_type_prefix, len_is_serial_of_postgres_record_type):
ddl_stmt = ""
postgres_fields_type = []
for field in avro_fields:
default_value = None
postgres_type, _, _ = convert_to_postgres_type(
field["type"], default_value, ddl_queue, postgres_record_type_prefix, len_is_serial_of_postgres_record_type)
postgres_fields_type.append(postgres_type)
if len(ddl_stmt) == 0:
ddl_stmt = f"CREATE TYPE {name} AS (\n "
else:
ddl_stmt += "\n , "
ddl_stmt += field["name"] + ' '
if type(postgres_type) is str:
ddl_stmt += postgres_type
elif "record" in postgres_type:
ddl_stmt += postgres_type["record"]
else:
ddl_stmt += postgres_type["array"]
if 0 < len(ddl_stmt):
ddl_stmt += "\n);\n"
ddl_queue.append(ddl_stmt)
return postgres_fields_type
def make_sql_create_table(name, avro_fields, ddl_queue, postgres_record_type_prefix):
ddl_stmt = ""
postgres_type_list = []
len_is_serial_of_postgres_record_type = []
for field in avro_fields:
if "default" in field:
default_value = field["default"]
else:
default_value = None
postgres_type, default_str, nullable = convert_to_postgres_type(
field["type"], default_value, ddl_queue, postgres_record_type_prefix, len_is_serial_of_postgres_record_type)
postgres_type_list.append(postgres_type)
if len(ddl_stmt) == 0:
ddl_stmt = f" "
else:
ddl_stmt += "\n , "
ddl_stmt += field["name"] + ' '
if type(postgres_type) is str:
ddl_stmt += postgres_type
elif "record" in postgres_type:
ddl_stmt += postgres_type["record"]
else:
ddl_stmt += postgres_type["array"]
if not nullable:
ddl_stmt += " NOT NULL"
if "default" in field:
ddl_stmt += f" DEFAULT {default_str}"
if field["name"] == "event_timestamp":
ddl_stmt += f"\n , eventtimestamp TIMESTAMP WITH TIME ZONE DEFAULT NULL"
if 0 < len(ddl_stmt):
ddl_stmt += "\n)"
ddl_queue.append(ddl_stmt)
return postgres_type_list
def convert_to_postgres_value(avro_type, postgres_type, avro_value, null_if_convert_error):
if avro_value is None:
return "NULL"
try:
value_str = ""
if type(avro_type) is list:
if "null" in avro_type:
avro_type.remove("null")
assert len(avro_type) == 1
avro_type = avro_type[0]
if type(avro_type) is str:
if avro_type == "string":
value_str = escape(avro_value)
elif avro_type == "long":
value_str = str(avro_value)
elif avro_type == "double":
value_str = str(avro_value)
elif avro_type == "boolean":
if avro_value:
value_str = "TRUE"
else:
value_str = "FALSE"
elif type(avro_type) is dict:
if "sqlType" in avro_type:
sql_type = avro_type["sqlType"]
if sql_type == "JSON":
value_str = escape(avro_value)
elif "logicalType" in avro_type:
logical_type = avro_type["logicalType"]
if logical_type == "decimal":
value_str = str(avro_value)
elif logical_type in ("timestamp-millis", "timestamp-micros"):
value_str = escape(avro_value.isoformat())
elif logical_type == "date":
value_str = escape(avro_value.isoformat())
elif logical_type in ("time-millis", "time-micros"):
value_str = escape(avro_value.isoformat())
elif logical_type in ("local-timestamp-millis", "local-timestamp-micros"):
value_str = escape(avro_value.isoformat())
else:
avro_child_type = avro_type["type"]
if avro_child_type == "array":
avro_items_type = avro_type["items"]
postgres_items_type = postgres_type["items"]
postgres_value_list = []
for val in avro_value:
postgres_value_list.append(convert_to_postgres_value(
avro_items_type, postgres_items_type, val, null_if_convert_error))
value_str = f'ARRAY[{",".join(postgres_value_list)}]::{postgres_type["array"]}'
elif avro_child_type == "record":
avro_fields = avro_type["fields"]
postgres_fields_type = postgres_type["fields"]
postgres_value_list = []
for avro_field, postgres_field_type in zip(avro_fields, postgres_fields_type):
postgres_value_list.append(convert_to_postgres_value(
avro_field["type"], postgres_field_type, avro_value[avro_field["name"]], null_if_convert_error))
value_str = f'ROW({",".join(postgres_value_list)})'
if len(value_str) == 0:
raise MyException(f"Convert Error: type={avro_type}, value={avro_value}")
except Exception as e:
if null_if_convert_error:
return "NULL"
else:
raise e
else:
return value_str
def make_sql_insert(tablename, schema, postgres_type_list, rec, null_if_convert_error=False):
insert_into = []
insert_values = []
fields = schema["fields"]
for field, postgres_type in zip(fields, postgres_type_list):
field_name = field["name"]
insert_into.append(field_name)
insert_values.append(convert_to_postgres_value(field["type"], postgres_type, rec[field_name], null_if_convert_error))
if field_name == "event_timestamp":
insert_into.append("eventtimestamp")
dt = DT_UTC_AWARE + datetime.timedelta(microseconds=rec[field_name])
insert_values.append(escape(dt.isoformat()))
insert_into_str = "\n , ".join(insert_into)
insert_values_str = "\n , ".join(insert_values)
insert_stmt = f"INSERT INTO {tablename} (\n {insert_into_str}\n)\nVALUES (\n {insert_values_str}\n);\n"
return insert_stmt
def main():
config_path = Path.cwd() / "ga4_from_avro_to_sql.ini"
config = read_config(config_path)
local_in_home = Path.cwd() / config["local"]["avro_home"]
local_out_home = Path.cwd() / config["local"]["sql_home"]
avro_list = glob.glob(str(local_in_home) + "/*/events_*.avro")
print(f"Avroファイル数:{len(avro_list)}")
if len(avro_list) == 0:
return
avro_list.sort(reverse=True)
postgres_record_type_prefix = "events"
# DDL
partition_stmt_list = []
local_out_home.mkdir(parents=True, exist_ok=True) # ディレクトリがなければ作成
out_ddl_path = local_out_home / f"{Path(avro_list[0]).stem.lower()}_ddl.sql"
with open(out_ddl_path, "wt", encoding="utf-8") as fo_ddl:
try:
for index, in_path_str in enumerate(avro_list, 1):
in_path = Path(in_path_str)
table_name = in_path.stem.lower()
with open(in_path, "rb") as fi:
reader = MyReader(fi)
schema = json.loads(reader.meta["avro.schema"].decode("utf-8"))
ddl_queue = deque()
make_sql_create_table(table_name, schema["fields"], ddl_queue, postgres_record_type_prefix)
create_table_stmt = ddl_queue.pop()
create_type_stmt = "".join(ddl_queue)
date_from = datetime.datetime.strptime(table_name[7:], "%Y%m%d")
date_to = date_from + datetime.timedelta(days=1)
partition_stmt = f"""
CREATE TABLE {table_name}
PARTITION OF events
FOR VALUES FROM ('{date_from.strftime("%Y%m%d")}') TO ('{date_to.strftime("%Y%m%d")}');\n
"""
partition_stmt_list.append(textwrap.dedent(partition_stmt)[1:-1])
if index == 1:
create_table_stmt0 = create_table_stmt
create_type_stmt0 = create_type_stmt
elif create_table_stmt == create_table_stmt0 and create_type_stmt == create_type_stmt0:
pass
else:
raise MyException(f"Avroファイル間にスキーマの差異が検出されました。処理を中断します。{in_path_str}")
finally:
# トランザクション開始
fo_ddl.write("BEGIN;\n")
# DDL
fo_ddl.write(create_type_stmt)
fo_ddl.write(f"CREATE TABLE events (\n{create_table_stmt} PARTITION BY RANGE (event_date);\n")
for partition_stmt in reversed(partition_stmt_list):
fo_ddl.write(partition_stmt)
# トランザクション終了
fo_ddl.write("COMMIT;\n")
local_in_home_str = str(local_in_home.absolute())
local_out_home_str = str(local_out_home.absolute())
# INSERT文
for index, in_path_str in enumerate(avro_list, 1):
in_path = Path(in_path_str)
table_name = in_path.stem.lower()
in_path_parent_str = str(in_path.parent.absolute())
out_dir = Path(in_path_parent_str.replace(local_in_home_str, local_out_home_str))
out_dir.mkdir(parents=True, exist_ok=True) # ディレクトリがなければ作成
out_path = out_dir / f"{table_name}.sql"
with open(in_path, "rb") as fi, open(out_path, "wt", encoding="utf-8") as fo:
reader = MyReader(fi)
schema = json.loads(reader.meta["avro.schema"].decode("utf-8"))
ddl_queue = deque()
postgres_type_list = make_sql_create_table(table_name, schema["fields"], ddl_queue,
postgres_record_type_prefix)
# トランザクション開始
fo.write("BEGIN;\n")
# INSERT文
num = 0
for rec in reader:
num += 1
insert_stmt = make_sql_insert(table_name, schema, postgres_type_list, rec, null_if_convert_error=False)
fo.write(insert_stmt)
print(f"({index}) {table_name}.sql: {num} 行")
# トランザクション終了
fo.write("COMMIT;\n")
if __name__ == "__main__":
try:
main()
except Exception:
print(traceback.format_exc())
設定ファイルの記述例
[local]
avro_home = ga4_obfuscated_sample_ecommerce
sql_home = your_sql_directory
設定ファイルはPythonコードを動かすディレクトリに置きます。
設定ファイルの[local]セクションに、Avroファイルが入っているサブディレクトリ名と、SQLファイルを格納するサブディレクトリ名を記述します。
コード説明
上記のPythonコードで行うことは以下の通りです。
- 各Avroファイルを読んで、PostgreSQLへのimport用SQLファイルを出力します。
- event_date列でレンジパーティショニングされ、PostgreSQLでのテーブル名は「events」になり、BigQueryのテーブル名がPostgreSQLのパーティション名になります。
- Pythonコードを動かしたディレクトリ配下に、設定ファイルに設定したsql_home名でサブディレクトリが作成され、その下に出力されます。
- そのsql_home直下に、DDL文のSQLファイルが出力されます。

- sql_homeのサブディレクトリ配下に、各Avroファイルから生成したINSERT文のSQLファイルが「パーティション名.sql」の名前で出力されます。

- event_timestamp列の内容はタイムスタンプですが、UNIX時間(マイクロ秒)の数値になっていて分かりにくかったので、タイムゾーン付TIMESTAMP型に変換したeventtimestamp列を新規追加してみました。
他にもUNIX時間の列がありますので、Pythonコードをカスタマイズすれば同様の列を追加することが可能です。
生成されたSQL文の内容
DDL
BEGIN;
CREATE TYPE events_type_2 AS (
string_value VARCHAR
, int_value BIGINT
, float_value DOUBLE PRECISION
, double_value DOUBLE PRECISION
);
CREATE TYPE events_type_1 AS (
key VARCHAR
, value events_type_2
);
CREATE TYPE events_type_3 AS (
analytics_storage BIGINT
, ads_storage BIGINT
, uses_transient_token VARCHAR
);
CREATE TYPE events_type_5 AS (
string_value BIGINT
, int_value BIGINT
, float_value BIGINT
, double_value BIGINT
, set_timestamp_micros BIGINT
);
CREATE TYPE events_type_4 AS (
key BIGINT
, value events_type_5
);
CREATE TYPE events_type_6 AS (
revenue DOUBLE PRECISION
, currency VARCHAR
);
CREATE TYPE events_type_8 AS (
browser VARCHAR
, browser_version VARCHAR
);
CREATE TYPE events_type_7 AS (
category VARCHAR
, mobile_brand_name VARCHAR
, mobile_model_name VARCHAR
, mobile_marketing_name VARCHAR
, mobile_os_hardware_model BIGINT
, operating_system VARCHAR
, operating_system_version VARCHAR
, vendor_id BIGINT
, advertising_id BIGINT
, language VARCHAR
, is_limited_ad_tracking VARCHAR
, time_zone_offset_seconds BIGINT
, web_info events_type_8
);
CREATE TYPE events_type_9 AS (
continent VARCHAR
, sub_continent VARCHAR
, country VARCHAR
, region VARCHAR
, city VARCHAR
, metro VARCHAR
);
CREATE TYPE events_type_10 AS (
id VARCHAR
, version VARCHAR
, install_store VARCHAR
, firebase_app_id VARCHAR
, install_source VARCHAR
);
CREATE TYPE events_type_11 AS (
medium VARCHAR
, name VARCHAR
, source VARCHAR
);
CREATE TYPE events_type_12 AS (
hostname VARCHAR
);
CREATE TYPE events_type_13 AS (
total_item_quantity BIGINT
, purchase_revenue_in_usd DOUBLE PRECISION
, purchase_revenue DOUBLE PRECISION
, refund_value_in_usd DOUBLE PRECISION
, refund_value DOUBLE PRECISION
, shipping_value_in_usd DOUBLE PRECISION
, shipping_value DOUBLE PRECISION
, tax_value_in_usd DOUBLE PRECISION
, tax_value DOUBLE PRECISION
, unique_items BIGINT
, transaction_id VARCHAR
);
CREATE TYPE events_type_14 AS (
item_id VARCHAR
, item_name VARCHAR
, item_brand VARCHAR
, item_variant VARCHAR
, item_category VARCHAR
, item_category2 VARCHAR
, item_category3 VARCHAR
, item_category4 VARCHAR
, item_category5 VARCHAR
, price_in_usd DOUBLE PRECISION
, price DOUBLE PRECISION
, quantity BIGINT
, item_revenue_in_usd DOUBLE PRECISION
, item_revenue DOUBLE PRECISION
, item_refund_in_usd DOUBLE PRECISION
, item_refund DOUBLE PRECISION
, coupon VARCHAR
, affiliation VARCHAR
, location_id VARCHAR
, item_list_id VARCHAR
, item_list_name VARCHAR
, item_list_index VARCHAR
, promotion_id VARCHAR
, promotion_name VARCHAR
, creative_name VARCHAR
, creative_slot VARCHAR
);
CREATE TABLE events (
event_date VARCHAR DEFAULT NULL
, event_timestamp BIGINT DEFAULT NULL
, eventtimestamp TIMESTAMP WITH TIME ZONE DEFAULT NULL
, event_name VARCHAR DEFAULT NULL
, event_params events_type_1[] NOT NULL
, event_previous_timestamp BIGINT DEFAULT NULL
, event_value_in_usd DOUBLE PRECISION DEFAULT NULL
, event_bundle_sequence_id BIGINT DEFAULT NULL
, event_server_timestamp_offset BIGINT DEFAULT NULL
, user_id VARCHAR DEFAULT NULL
, user_pseudo_id VARCHAR DEFAULT NULL
, privacy_info events_type_3 DEFAULT NULL
, user_properties events_type_4[] NOT NULL
, user_first_touch_timestamp BIGINT DEFAULT NULL
, user_ltv events_type_6 DEFAULT NULL
, device events_type_7 DEFAULT NULL
, geo events_type_9 DEFAULT NULL
, app_info events_type_10 DEFAULT NULL
, traffic_source events_type_11 DEFAULT NULL
, stream_id BIGINT DEFAULT NULL
, platform VARCHAR DEFAULT NULL
, event_dimensions events_type_12 DEFAULT NULL
, ecommerce events_type_13 DEFAULT NULL
, items events_type_14[] NOT NULL
) PARTITION BY RANGE (event_date);
CREATE TABLE events_20201101
PARTITION OF events
FOR VALUES FROM ('20201101') TO ('20201102');
(中略)
CREATE TABLE events_20210131
PARTITION OF events
FOR VALUES FROM ('20210131') TO ('20210201');
COMMIT;
INSERT文
BEGIN;
INSERT INTO events_20210131 (
event_date
, event_timestamp
, eventtimestamp
, event_name
, event_params
, event_previous_timestamp
, event_value_in_usd
, event_bundle_sequence_id
, event_server_timestamp_offset
, user_id
, user_pseudo_id
, privacy_info
, user_properties
, user_first_touch_timestamp
, user_ltv
, device
, geo
, app_info
, traffic_source
, stream_id
, platform
, event_dimensions
, ecommerce
, items
)
VALUES (
'20210131'
, 1612069510766593
, '2021-01-31T05:05:10.766593+00:00'
, 'page_view'
, ARRAY[ROW('gclid',ROW(NULL,NULL,NULL,NULL)),ROW('gclsrc',ROW(NULL,NULL,NULL,NULL)),ROW('debug_mode',ROW(NULL,1,NULL,NULL)),ROW('ga_session_number',ROW(NULL,1,NULL,NULL)),ROW('all_data',ROW(NULL,NULL,NULL,NULL)),ROW('page_location',ROW('https://shop.googlemerchandisestore.com/',NULL,NULL,NULL)),ROW('entrances',ROW(NULL,1,NULL,NULL)),ROW('session_engaged',ROW('0',NULL,NULL,NULL)),ROW('ga_session_id',ROW(NULL,661084800,NULL,NULL)),ROW('clean_event',ROW('gtm.js',NULL,NULL,NULL)),ROW('engaged_session_event',ROW(NULL,1,NULL,NULL)),ROW('page_title',ROW('Home',NULL,NULL,NULL))]::events_type_1[]
, NULL
, NULL
, 6595101026
, NULL
, NULL
, '1026454.4271112504'
, ROW(NULL,NULL,'No')
, ARRAY[]::events_type_4[]
, 1612069510766593
, ROW(0.0,'USD')
, ROW('mobile','Apple','iPhone','<Other>',NULL,'Web','<Other>',NULL,NULL,'en-us','No',NULL,ROW('Safari','13.1'))
, ROW('Americas','Northern America','United States','California','San Carlos','(not set)')
, NULL
, ROW('organic','(organic)','google')
, 2100450278
, 'WEB'
, NULL
, ROW(NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL)
, ARRAY[]::events_type_14[]
);
(中略)
COMMIT;
(3) 生成されたSQL文を動かしてPostgreSQLにimportする
Pythonコードと設定ファイル
import traceback
from pathlib import Path
import glob
import configparser
import psycopg2
class MyException(Exception):
pass
def read_config(config_path):
config = configparser.ConfigParser()
config.read(config_path, encoding="utf-8")
return config
def main():
config_path = Path.cwd() / "ga4_from_sql_to_postgres.ini"
config = read_config(config_path)
local_in_home = Path.cwd() / config["local"]["sql_home"]
ddl_list = glob.glob(str(local_in_home) + "/events_*_ddl.sql")
print(f"DDLファイル数:{len(ddl_list)}")
if len(ddl_list) != 1:
raise MyException(f"DDLファイルは1つでなければなりません。処理を中断します。")
sql_list = glob.glob(str(local_in_home) + "/*/events_*.sql")
print(f"INSERTファイル数:{len(sql_list)}")
sql_list.sort(reverse=True)
host = config["postgresql"]["host"]
port = config["postgresql"]["port"]
dbname = config["postgresql"]["dbname"]
user = config["postgresql"]["user"]
password = config["postgresql"]["password"]
with psycopg2.connect(f"host={host} port={port} dbname={dbname} user={user} password={password}") as conn:
with conn.cursor() as cur:
print(f"DDLを実行します")
with open(ddl_list[0], "rt", encoding="utf-8") as fi:
sql = fi.read()
cur.execute(sql)
print(" ... done.")
print(f"INSERT文を実行します")
for index, in_path_str in enumerate(sql_list, 1):
in_path = Path(in_path_str)
print(f"({index}) パーティション: {in_path.stem}:\n {in_path_str} ... ", end="")
with open(in_path, "rt", encoding="utf-8") as fi:
sql = fi.read()
cur.execute(sql)
print("done.")
if __name__ == "__main__":
try:
main()
except Exception:
print(traceback.format_exc())
設定ファイルの記述例
[local]
sql_home = your_sql_directory
[postgresql]
host = 127.0.0.1
port = 5432
dbname = yourdb
user = you
password = secret
設定ファイルはPythonコードを動かすディレクトリに置きます。
設定ファイルの[local]セクションに、SQLファイルが入っているサブディレクトリ名を記述します。
[postgresql]セクションに、PostgreSQLの接続情報を記述します。
コード説明
上記のPythonコードで行うことは以下の通りです。
- 各SQLファイルを読んで、PostgreSQLで実行してテーブルをimportします。
- import前にSQL文を確認し、必要に応じてをカスタマイズすると良いでしょう。
PostgreSQLのデータをざっくり確認
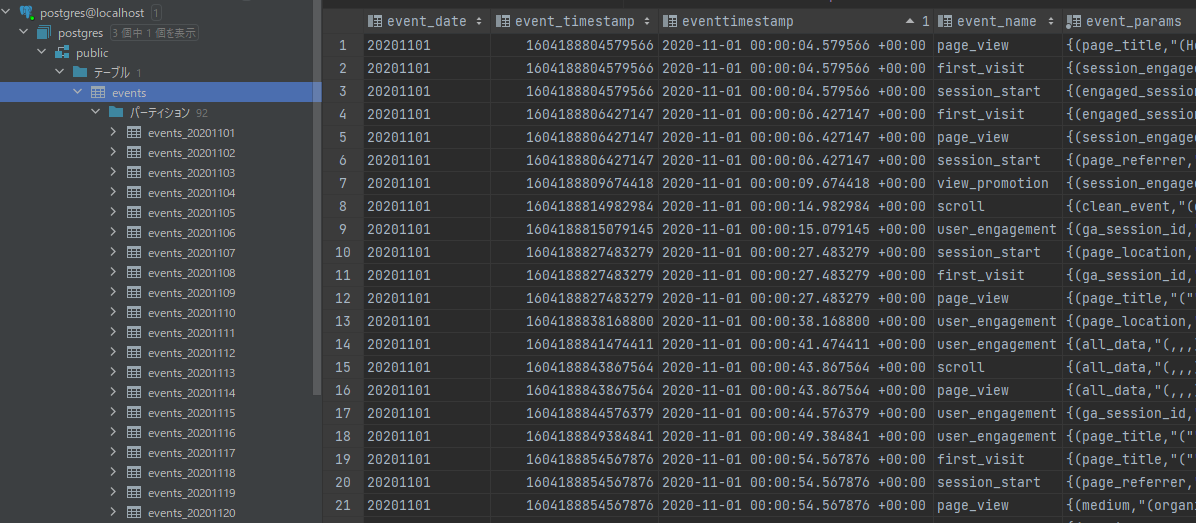
以下の画像は、PostgreSQLに生成されたeventsテーブルをDataGripで確認しているところです。
Pythonコードで追加したeventtimestamp列でソートし、データの先頭と末尾を見てみました。
パーティションが生成されていることや、日時データがUTCであること等が確認できます。
先頭
末尾
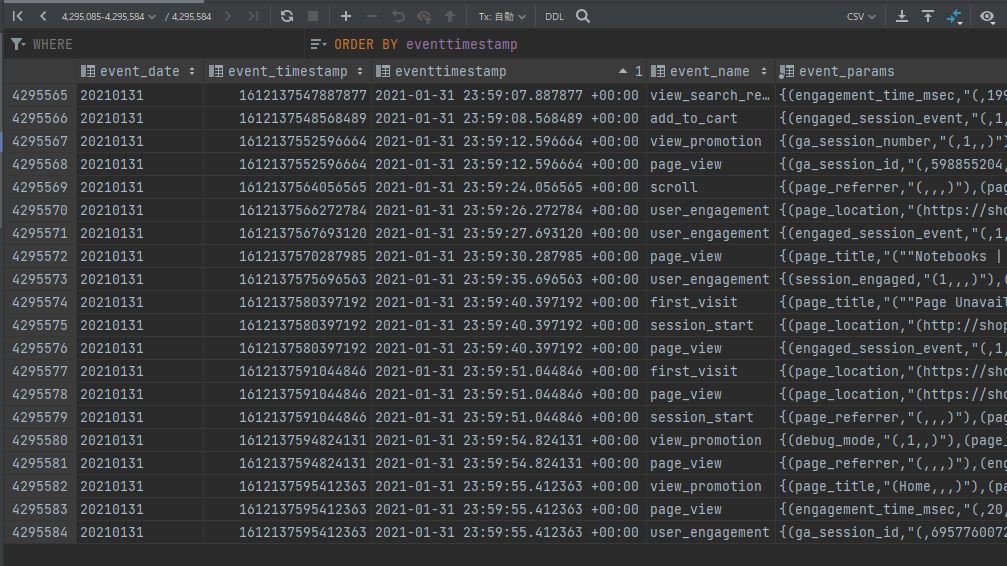
テーブルの件数は約400万件です。
event_params列は配列型ですし、まぁまぁ大きいですね。
BigQueryとPostgreSQLで同じSELECT文を実行して、同じ結果が返ることをざっくり確認する
前回の記事と同様のSELECT文を、本記事でも動かしてみます。
ただし、PostgreSQLのレンジパーティションを活かしたいので、WHERE句にevent_date列での条件を追加しています。
以下、UNNEST関数を使ったクエリーを2つ試します。
FROM句のテーブル名だけ、BigQuery用とPostgreSQL用で修正する必要があります。
クエリーその1
WITH
foo AS (
SELECT
event_date,
event_timestamp,
event_name,
event_params
FROM
public.events
WHERE
event_date = '20210131'
AND
event_timestamp IN (1612125113370459, 1612125041889438)
)
SELECT
event_date,
event_timestamp,
event_name,
event_param.key,
(event_param.value).string_value,
(event_param.value).int_value,
(event_param.value).float_value,
(event_param.value).double_value
FROM
foo
CROSS JOIN
UNNEST(event_params) AS event_param
ORDER BY
event_timestamp,
event_name,
key
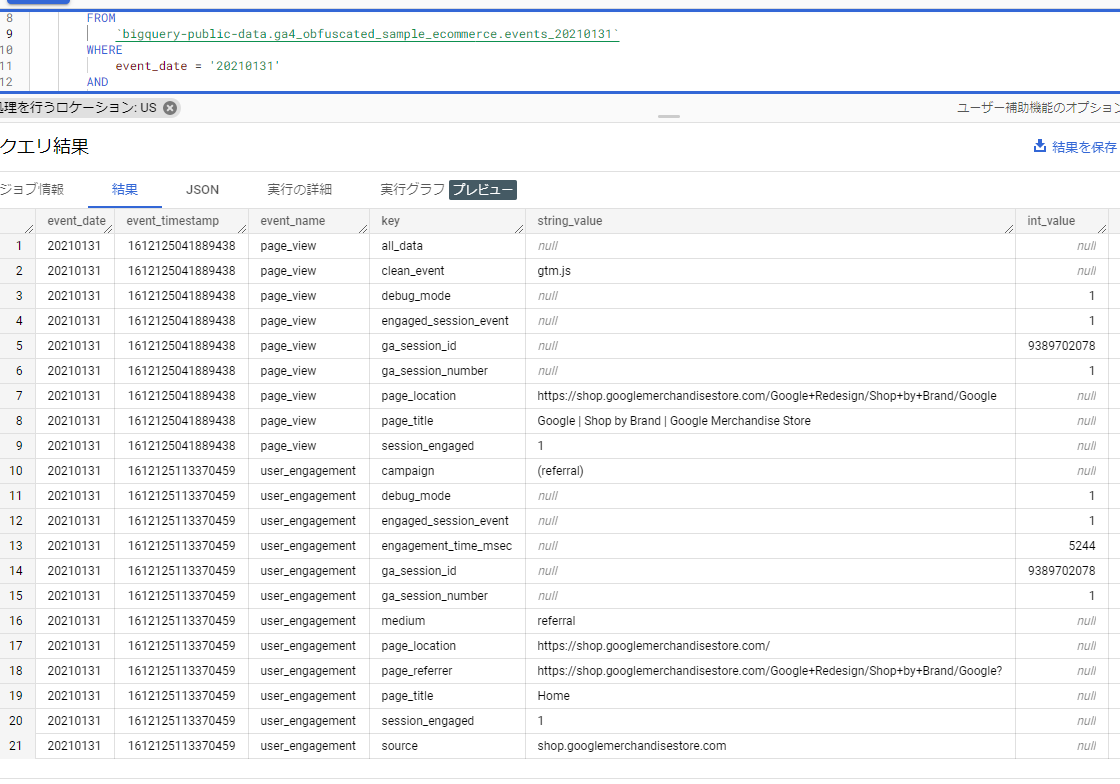
BigQueryの結果:
PostgreSQLの結果:
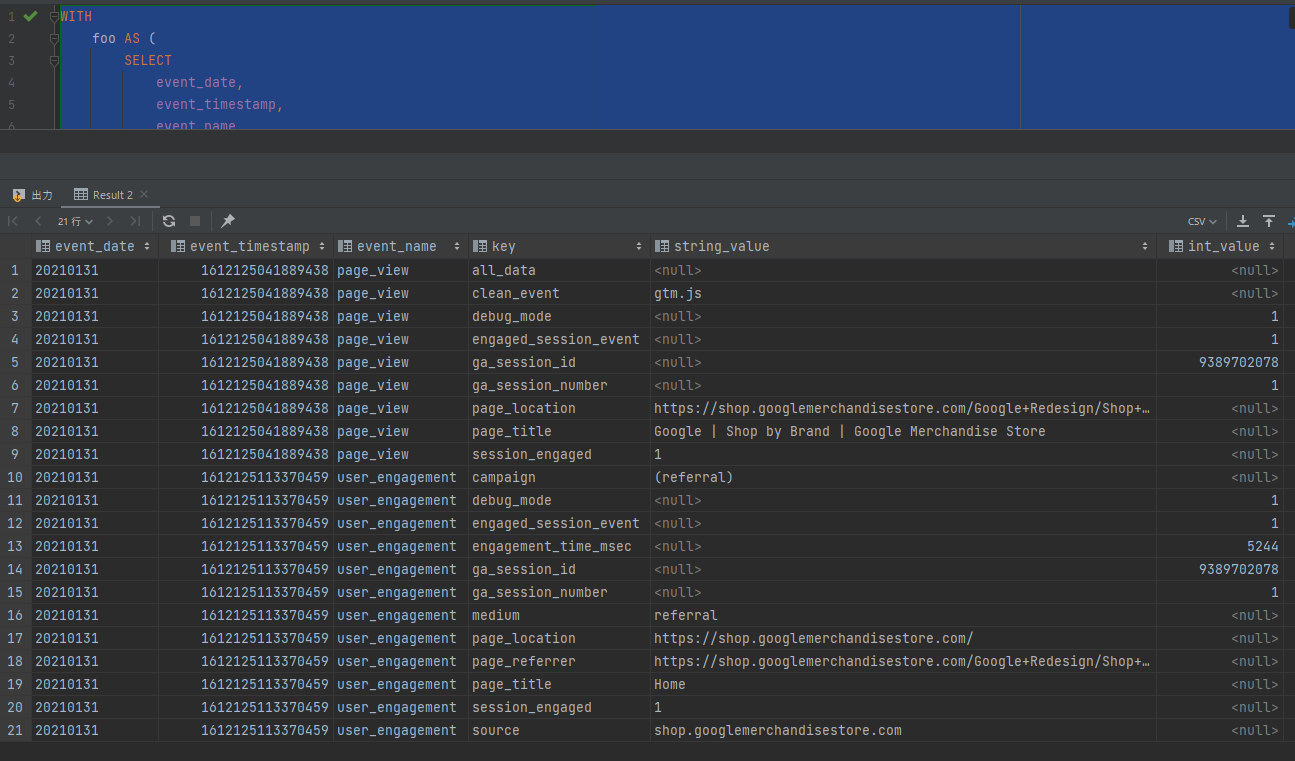
両方とも21件、同じデータが返りました。
クエリーその2
SELECT
event_date,
event_timestamp,
event_name,
(SELECT
(value).int_value
FROM
UNNEST(event_params)
WHERE
key = 'ga_session_id'
) AS ga_session_id,
(SELECT
(value).string_value
FROM
UNNEST(event_params)
WHERE
key = 'page_title'
) AS page_title
FROM
public.events
WHERE
event_date = '20210131'
AND
event_timestamp IN (1612125113370459, 1612125041889438)
ORDER BY
event_timestamp,
event_name
BigQueryの結果:
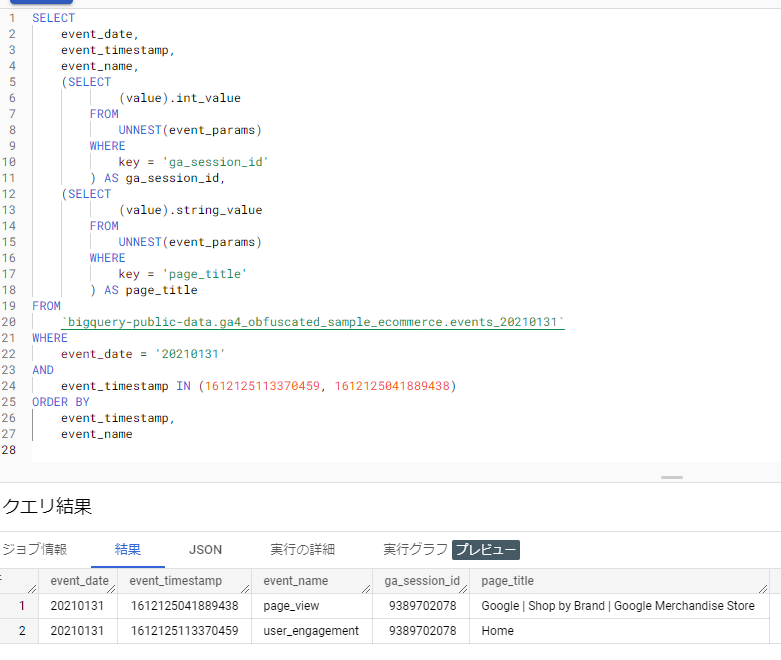
PostgreSQLの結果:
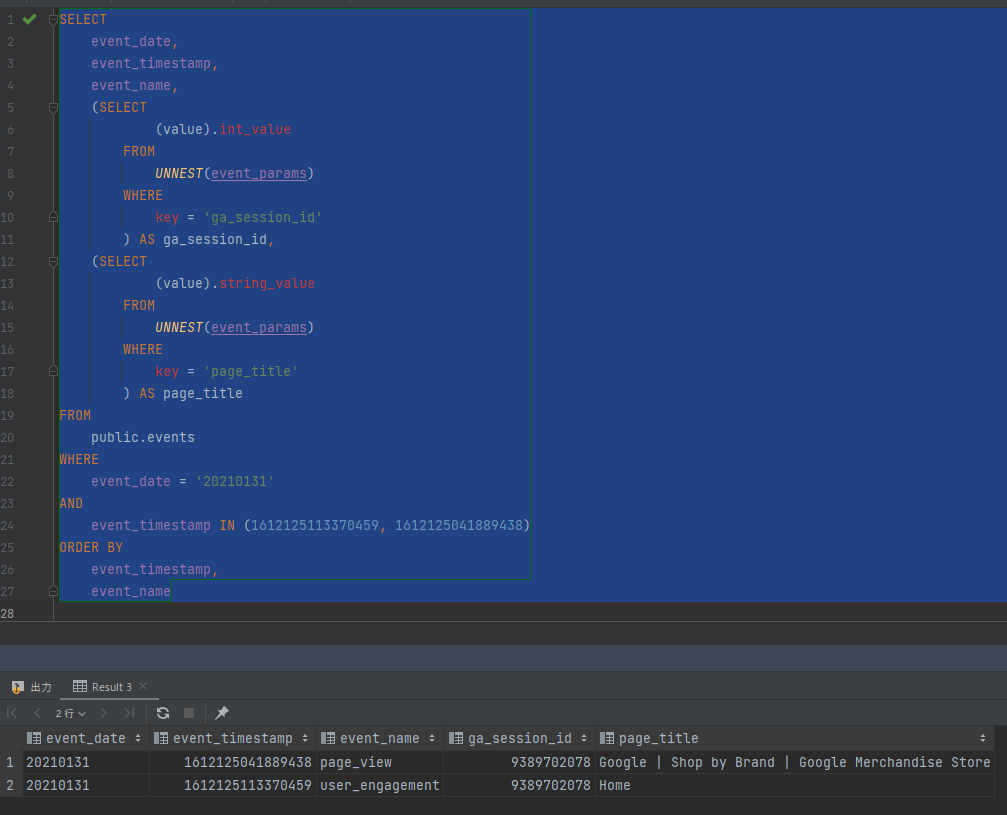
両方とも2件、同じデータが返りました。
2つのクエリーで、BigQueryとPostgreSQLが同じ結果を返すことを、ざっくり確認できました。