はじめに
はじめまして!!かんちゃんたろうといいます。
元々は制御工学に興味があったのですが、高専ロボコン2019のときに、自動機でタオル回収させるのにとても苦労して、ロボットはこんなことも出来ないのかと絶望した経験からAI×ロボットに興味を持っています。
この記事は、基盤モデル×Robotics Advent Calender 2022の23日目になります。
今回は、"VIMA: General Robot Manipulation with Multimodal Prompts"を解説したいと思います。 プロジェクトページも公開されていますので、この記事を読みながらでも見てみてください。動画がたくさんあって、見ていて楽しいと思います。
VIMAとは?
VIMAとは、テキストと画像を混ぜたマルチモーダルなプロンプトを用いることで、さまざまなロボットタスクを実行できる汎用ロボットエージェントです。ちなみにVIMAは、VisuoMotor Attention modelの略で、読み方はビマではなく、「ブイアイマ」だそうです。
下の図は、4つのタスクに対する、マルチモーダルプロンプトの例となっています。

それぞれのプロンプトについて噛み砕いて言うと、上から順に次のような感じですね。
- この画像の通りに物体置き直して。
- この物体を次のように動かして。
- この物体は○、あの物体は×って名前。じゃあ×を○に入れて。
- この物体をあの中まで運んで。あ、でもそのライン超えたらダメね。
これを見たときは、人が人に仕事などの指示をするのと同じ感じで、ロボットに指示できるのすごい!!と感動しました。
VIMAの何がすごい?
ロボットへのタスク指定は、One-Shot教示や言語命令、視覚ゴールを与えるなどさまざまな方法があります。従来の研究ではこれらは別々のタスクと見なされ、それぞれ専用のモデルを使用することがほとんどでした。
VIMAでは、自然言語処理の分野で大成功を収めているプロンプトベース学習を応用して、テキストと画像を混ぜたマルチモーダルなプロンプトが、さまざまなタスクを表現することが可能であることを示しました。
まとめると、以下の3つが本研究のContributionであると著者らは主張しています。
- 広範囲のマニピュレーションタスクを1つの系列モデリング問題に変換する新しいマルチモーダルプロンプトの定式化
- マルチタスクとZero-Shot汎化が可能なロボットエージェントモデルの作成
- モデルのスケーラビリティと汎化性を評価する大規模ベンチマークの提供
VIMAの概要
6つの基本的なタスク
著者らは、広範囲にわたるロボットマニピュレーションタスクは次の6つの基本的なタスクを組み合わせたものであると考えています。この6つの基本タスクを組み合わせる、つまりマルチモーダルプロンプトの組み合わせによって、全てのマニピュレーションタスクは表現できると主張しているわけですね!
-
Simple object manipulation: 1つの物体をある場所に配置するタスク

-
Visual goal reaching: 画像の通りに物体を再配置するタスクなど

-
Novel concept grounding: 初めて聞く名前や性質を物体と結びつける(接地する)タスク

-
One-shot video imitation: ビデオ中のある物体の運動軌道を再現するタスク

-
Visual constraint satisfaction: 安全制約に違反しないように物体を慎重に扱うタスク
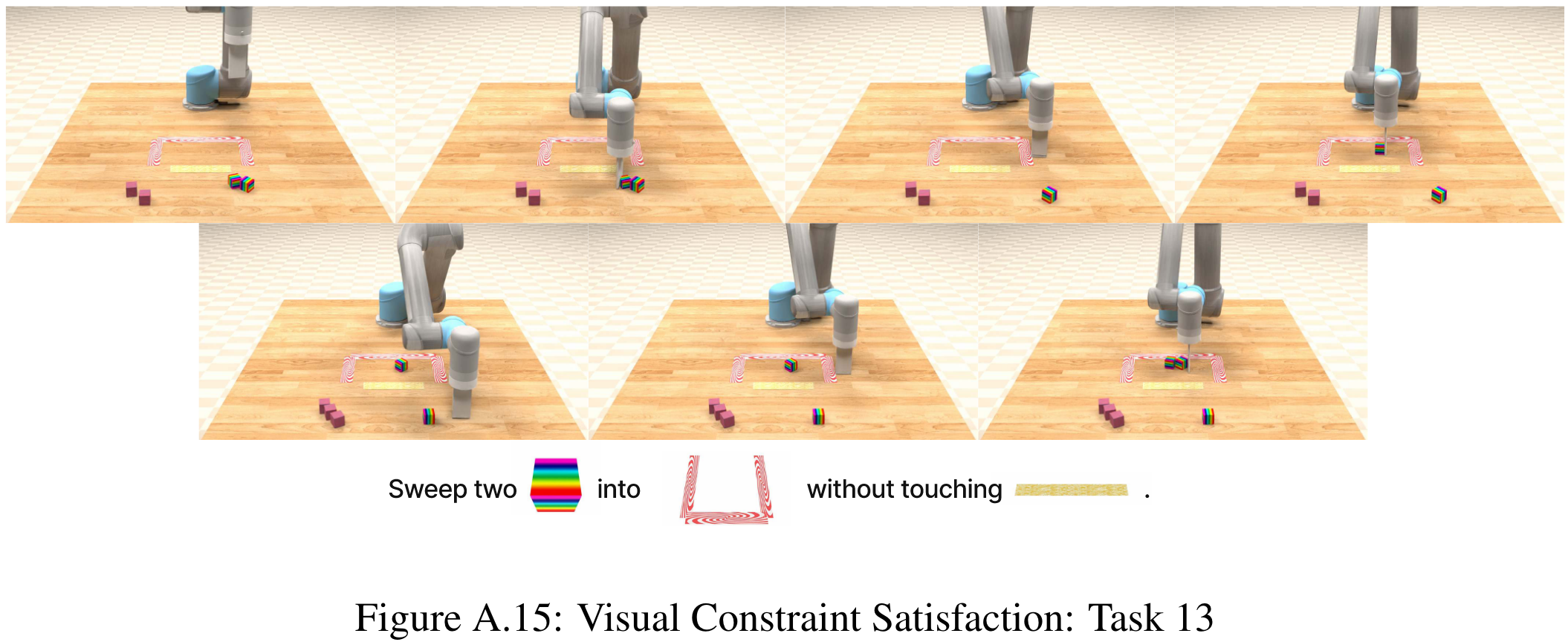
-
Visual reasoning: 同じ質感の物体を全て同じ容器に入れたり、物体を動かした後に元通りに戻すタスク

VIMA-Bench: マルチモーダルロボット学習のためのベンチマーク
本研究では、マルチモーダルロボット学習のための新たなベンチマークとして、VIMA-Benchを作成しています。VIMA-Benchは、先ほどの6つの基本タスクを組み合わせた17個のメタタスクとプロンプトのテンプレートが用意されています。様々な形やテクスチャを持つ物体を組み合わせることで、数千通りもの個別のタスクを作成することができます。
データセットの作成
VIMA-Benchのシミュレータは、その特性によって、完全な物体位置やロボットの運動軌道が分かるので、簡単に模倣学習のためのデータセットを作成することができます。
Zero-Shot汎化の評価指標
VIMA-Benchでは、Zero-Shot汎化の評価指標を新たに提案しています。具体的には以下のL1, L2, L3, L4の評価レベルを設計しています。
- Placement generalization: テーブル上の物体の位置変化に対する汎化
- Combinatorial generalization: 新しく種類とテクスチャを組み合わせた物体に対する汎化
- Novel object generalization: 学習時にない物体に対する汎化
- Novel task generalization: 学習時にないメタタスクに対する汎化
この評価指標は、皆さんが注目しているであろうRT-1でも参考にされています。るっとさんの連ツイでも言及されていますね。
プロンプトのトークン化
VIMAに入力するプロンプトは、テキスト、物体画像、シーン画像の3つで構成されています。それぞれのデータ形式は次のように処理してトークン化します。
テキスト
まずテキストは、事前学習したT5 tokenizerを使用することで、単語を埋め込んで単語トークンを作成します。VIMAのモデル構造を解説する時にも出てきますが、T5は、Text-to-Text Transfer Transformerの略でGoogleが2019年に発表したモデルです。T5 tokenizerはT5に入力するトークン列を作成するためのモデルとなります。
シーン画像
VIMAは、object-centric表現を採用します。つまり、シーン画像をそのまま入力するわけではなく、物体の領域をバウンディングボックスで切り出す必要があります。ここではMask R-CNNを使用して、物体画像とバウンディングボックスを取得し、物体画像はViT、バウンティングボックスはMLPによってそれぞれトークン化します。
なお、物体画像の切り出しに対する頑健性を高めるため、学習データはバウンディングボックスのサイズをランダムに少し変更して切り出したものを用意するオブジェクト拡張を行って作成されています。
物体画像
物体画像の場合は、そのままViTでトークン化します。ただし、シーン画像の場合と整合性をとるため、ダミーのバウンディングボックスを設定して、MLPでダミーのトークンを作成します。
モデル構造
いよいよVIMAのモデル構造をみていきましょう。このモデルは大まかに、下のMultimodal PromptとInteractionと書いてある境目で左右に分けることができます。左側はエンコーダ、右側はデコーダです。つまり、VIMAはエンコーダ・デコーダモデルとなります。

まず、エンコーダ側について見ていきます。エンコーダでは、入力したマルチモーダルプロンプトをエンコードすることになります。使用するモデルは、先ほどプロンプトのトークン化で出てきたT5になります。ここでは、事前学習したT5を使用して、学習時にもパラメータは固定します。パラメータを固定することはfreezeさせると言いますので、frozen pre-trained T5を使用すると言い換えれます。マルチモーダルプロンプトから、先ほどの方法でトークン列を作成し、frozen pre-trained T5に入力することでエンコードします。
次にデコーダ側について見ていきます。デコーダは、最終的に行動トークンを出力することになるので、デコーダ全体がロボットのコントローラとなります。マニピュレーションタスクが複雑になると、プロンプトだけではなく、過去の行動軌跡を参照して、今からどのように行動するか決定する必要があります。そのため、Cross-Attention層を使用することで、プロンプトと、過去の行動軌跡との関係に注目して、次の行動トークンを決定します。なお、一度に得られる行動トークンは6つで、それぞれハンドのxy座標、ハンドの角度(クォータニオン)に変換されます。
過去の行動軌跡のトークン列(History Tokens)は、先ほどのプロンプトのトークン化で説明した、シーン画像と物体画像のトークン化方法によって作成します。一方で、行動は、MLPを使用してトークン化します。
モデル構造としては非常にシンプルですね。(これがTransformerの実力か...)
ただ、行動トークンがなぜ7個じゃないのか不思議ですね。z座標どうするの??
データセット
VIMAを学習させるためのデータセットには、それぞれのメタタスクにつき5万個、合計65万個の行動軌跡とプロンプトが含まれています。メタタスクは全部で17個ですが、そのうちの4つは、Zero-Shot汎化のテストベットに使用することになります。
学習
VIMAでは、T5 tokenizerとT5、Mask R-CNN以外は全て同時に学習させます。Mask R-CNNだけは、先にファインチューニングしたものを使用することになります。VIMAは、模倣学習としてbehavioral cloning (BC) に従って、予測行動の負の対数尤度を最小化するようにモデルを学習させます。目的関数はこれだけなので、非常にシンプルですね。
学習のテクニックとしては、Transformerのベストプラクティスとなっている、AdamW optimizerやlearning rate warm-up, cosine annealingなどを使用しているようです。
実験結果
それでは、VIMAのZero-Shot汎化の性能について見ていきましょう。
ここでは、ベースラインとしてGato, Flamingo, Decision Transformer (DT) の3つと比較されています。
それぞれのモデルについて一言でまとめると、Gatoはデコーダのみのモデル、Flamingoは視覚-言語モデル、DTは強化学習問題をTransformerでモデル化したものになります。ここでは、詳しい説明は省きます(というか自分が知りません!!)。
Gatoは本アドカレの9日目に解説されています!!!
スケーラビリティ
まず、3つのベースラインとVIMAでのスケーラビリティについて見ていきます。具体的には、モデルサイズとデータセットサイズのスケーラビリティですね。なおVIMAのモデルサイズは、エンコーダであるT5-Baseは省いて計算しています。

モデルサイズ
VIMAはZero-Shot汎化の全てのレベルにおいて、ベースラインを大きく上回っています。GatoやFlamingoはモデルサイズを大きくすると性能が向上しますが、VIMAは、全てのモデルサイズにおいて、一貫して優れた性能を達成しています。
データセットサイズ
L1およびL2レベルのZero-Shot汎化において、VIMAはわずか1%のデータがあれば、10倍以上のデータで学習したベースラインと同等の性能を達成することがわかります。特にL4レベルに関しては、全データで学習したベースラインよりも優れています。最後に、VIMAは10%のデータがあれば、全データで学習したベースラインの性能を大幅に上回ることがわかりました。
VIMAのサンプル効率が良い理由は、その他のベースラインは直接画像を入力している一方で、VIMAはobject-centric表現を採用しているからだと著者らは言っています。
その検証も含めて、Ablation studiesが行われました。
Ablation studies
ここでは、画像のトークン化方法による違いと、ロボットコントローラ(デコーダ)のプロンプトの条件付け方法による違いについて見ていきます。
画像のトークン化
VIMAでは、Mask R-CNNによって物体画像とバウンディングボックスを取得したものをViTでトークン化します。この方法を変えた場合の性能の変化について見ていきます。
下の図が検証した種類で、それぞれ以下の方法でトークン化します。
- 左上:VIMAで採用した方法
- 左中:Mask-RCNNによる物体画像切り取りではなく、シミュレーション上のground truth物体画像をViTでトークン化
- 左下:Perceiverを使用して、物体画像から固定長のトークン列を作成
- 右上:シーン画像をパッチに分割してViTでトークン化(Gato方式)
- 右中:Perceiverを使用して、シーン画像から固定長のトークン列を作成(Flamingo方式)
- 右下:シーン画像をViTでトークン化(DT方式)

下の図が結果になります。まず、VIMAで採用した方法は物体拡張を用いて切り出した物体画像で学習させたため、ground truth物体画像の場合と比べて性能の悪化は、わずかに止めることができています。次にベースラインの方式でトークン化した場合は、object-centric表現に比べて、性能が悪化しています。また、固定数のトークン列にするPerceiverは、object-centric表現でも性能が悪化しています。
以上より、object-centric表現でトークン列を可変長にすることは、タスク達成において必要な情報のみを十分に保持するために必要であることが確認できました。
(生画像だとタスク達成において不必要な情報もトークンに保持されるだろうし、固定長トークン列だと容量足らなくなるしって感じなので、結果としては当たり前な感じになりました。)

プロンプトの条件付け
VIMAでは、T5によってエンコードされたプロンプトトークンと過去の行動軌跡のトークンでCross-Attentionをすることで、出力する行動トークンに条件付けしています。これを変更した場合にどうなるか検証します。具体的には、プロンプトと過去の行動軌跡を1つの大きなトークン系列として、GPTのようなデコーダのみのTransformerを使用した場合で検証します。
下の図は、デコーダのみを変更した場合の結果になります。GPTは、大きなモデルであれば同等の性能を発揮しますが、小さなモデルの場合では、Cross-Attentionを使用したモデルが優位な結果を残しました。

この結果は、他の研究でも同様の傾向が確認されており、よく調整された小さなサイズのエンコーダ・デコーダアーキテクチャはZero-Shot汎化において、GPT-3を上回ることができるということを示唆しています。
まとめ
VIMAは、人にとって直感的なマルチモーダルプロンプトによって様々なマニピュレーションタスクを行えることを示しました。特に、Gato, Flamingo, DTなどとは違い、object-centric表現にしたデータをTransformerに入力することで、Zero-Shot汎化において非常に優れた性能を発揮することや、Cross-Attentionを使用することでモデルサイズを小さくしても問題ないことを示したことが個人的に称賛すべき点かなと思いました。
なんでも脳死で、end-to-endで生画像から学習させたり、モデルサイズを大きくしたりするのは、少なくともロボティクス界隈ではダメだということですね。mendyさんのアドカレ14日目でも述べられていた通り、自分が行動した結果の画像を予測するようなピクセルレベルの世界モデルがロボットに本当に必要なのか、どのように世界をモデル化するのが良いのか考えていく必要がありますね。
VIMAは、コード、学習済みモデル、データセット、シミュレーションベンチマーク全てがオープンソースとなっていますので、遊んでみるといいかもしれませんね。